
Cursus
Intelligence artificielle (IA) Leadership
6 h
L'IA explicable désigne un ensemble de processus et de méthodes visant à fournir une explication claire et compréhensible par l'homme des décisions générées par l'IA et les modèles d'apprentissage automatique.
En intégrant une couche d'explicabilité dans ces modèles, les scientifiques des données et les praticiens de l'apprentissage automatique peuvent créer des systèmes plus fiables et plus transparents pour aider un large éventail de parties prenantes telles que les développeurs, les régulateurs et les utilisateurs finaux.
Voici quelques principes d'IA explicables qui peuvent contribuer à instaurer la confiance :
La mise en œuvre de l'IA explicable présente plusieurs avantages. Pour les décideurs et les autres parties prenantes, il offre une compréhension claire de la logique qui sous-tend les décisions basées sur l'IA, ce qui leur permet de faire des choix plus éclairés. Elle permet également d'identifier les éventuels biais ou erreurs dans les modèles, ce qui permet d'obtenir des résultats plus précis et plus équitables.
Il existe deux grandes catégories d'explicabilité des modèles : les méthodes spécifiques aux modèles et les méthodes diagnostiques. Dans cette section, nous allons comprendre la différence entre les deux, en nous concentrant plus particulièrement sur les méthodes agnostiques.
Ces deux techniques permettent d'obtenir des informations précieuses sur le fonctionnement interne des modèles d'apprentissage automatique, tout en garantissant l'efficacité et la fiabilité des modèles.
Pour mieux illustrer ces outils, nous utiliserons l'ensemble de données sur le diabète de Kaggle. Dans un premier temps, nous construirons un classificateur simple, puis nous mettrons en œuvre l'explicabilité. Le code source complet est disponible dans ce classeur DataLab.
Un classificateur Random Forest est construit pour prédire les résultats du diabète à l'aide de l'ensemble de données sur le diabète. Le code est divisé en plusieurs étapes : (1) importer les bibliothèques pertinentes, (2) créer des ensembles de données d'entraînement et de test, (3) construire le modèle, et (4) présenter les mesures de performance dans le rapport de classification.
# Load useful libraries
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
# Separate Features and Target Variables
X = diabetes_data.drop(columns='Outcome')
y = diabetes_data['Outcome']
# Create Train & Test Data
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3,
stratify =y,
random_state = 13)
# Build the model
rf_clf = RandomForestClassifier(max_features=2, n_estimators =100 ,bootstrap = True)
rf_clf.fit(X_train, y_train)
# Make prediction on the testing data
y_pred = rf_clf.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))La dernière instruction d'impression génère le rapport suivant :
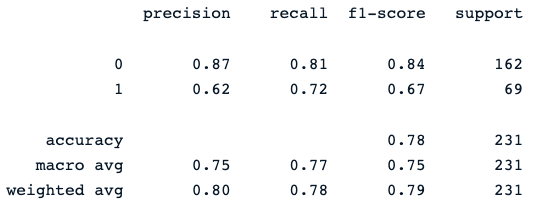
Le classificateur de la forêt aléatoire fournit une performance décente dans la prédiction des résultats du diabète, avec une marge d'amélioration évidente en utilisant différents modèles.
Nous pouvons maintenant intégrer la couche d'explicabilité dans ce modèle afin de mieux comprendre ses prédictions. La section suivante se concentre sur les deux grandes catégories d'explicabilité des modèles : les méthodes spécifiques aux modèles et les méthodes agnostiques.
Notre Classification dans l'apprentissage automatique : Introduction L'article vous aide à vous familiariser avec la classification dans l'apprentissage automatique, en examinant ce qu'elle est, comment elle est utilisée et quelques exemples d'algorithmes de classification.
Ces méthodes peuvent être appliquées à n'importe quel modèle d'apprentissage automatique, indépendamment de sa structure ou de son type. Ils se concentrent sur l'analyse de la paire entrée-sortie des caractéristiques. Cette section présente et analyse LIME et SHAP, deux modèles de substitution largement utilisés.
Il s'agit de SHapley AdditiveexPlanations. Cette méthode vise à expliquer la prédiction d'une instance/observation en calculant la contribution de chaque caractéristique à la prédiction. Elle peut être installée à l'aide de la commande pip suivante.
!pip install shapAprès l'installation :
import shap
import matplotlib.pyplot as plt
# load JS visualization code to notebook
shap.initjs()
# Create the explainer
explainer = shap.TreeExplainer(rf_clf)
shap_values = explainer.shap_values(X_test)SHAP offre une gamme d'outils de visualisation pour améliorer l'interprétabilité des modèles, et la section suivante aborde deux d'entre eux : (1) importance de la variable avec le graphique de synthèse, (2) graphique de synthèse d'une cible spécifique, et (3) graphique de dépendance.
Dans ce graphique, les caractéristiques sont classées en fonction de leur valeur SHAP moyenne, les plus importantes étant placées en haut et les moins importantes en bas, à l'aide de la fonction summary_plot(). Cela permet de comprendre l'impact de chaque caractéristique sur les prédictions du modèle.
print("Variable Importance Plot - Global Interpretation")
figure = plt.figure()
shap.summary_plot(shap_values, X_test)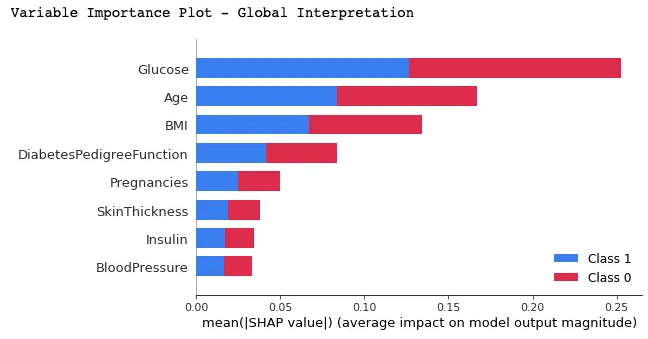
Vous trouverez ci-dessous l'interprétation que l'on peut faire du graphique ci-dessus :
Cette approche permet d'obtenir une vue d'ensemble plus granulaire de l'impact de chaque caractéristique sur un résultat spécifique (étiquette).
Dans l'exemple ci-dessous, shap_values[1] est utilisé pour représenter les valeurs SHAP des instances classées sous l'étiquette 1 (diabétiques).
shap.summary_plot(shap_values[1], X_test)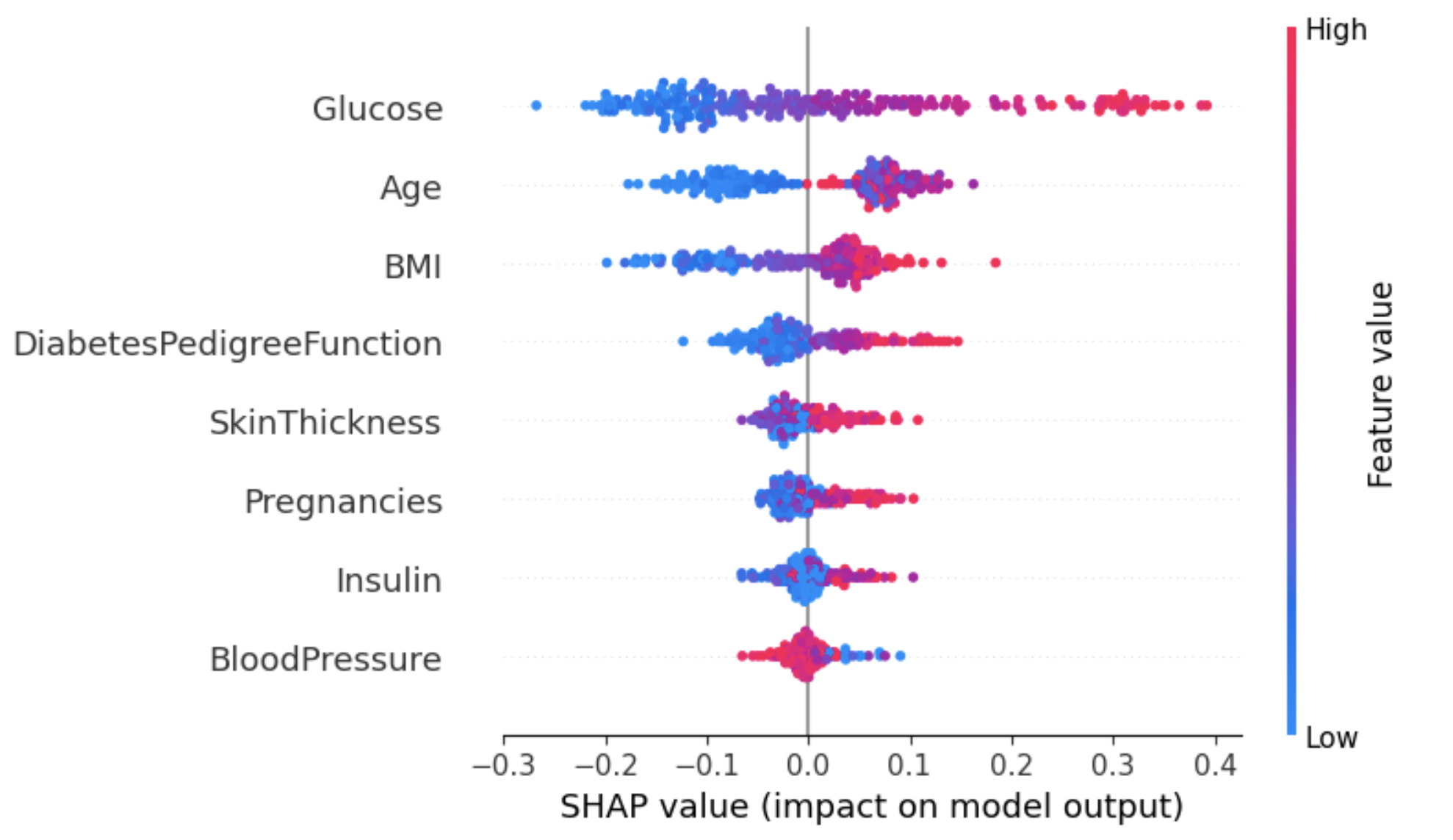
Extrait du graphique ci-dessus :
L'une des façons de traiter cette ambiguïté pour l'attribut Age est d'utiliser le graphique de dépendance pour obtenir plus d'informations.
Contrairement aux diagrammes de synthèse, les diagrammes de dépendance montrent la relation entre une caractéristique spécifique et le résultat prédit pour chaque cas dans les données. Cette analyse est effectuée pour de multiples raisons et ne se limite pas à l'obtention d'informations plus granulaires et à la validation de l'importance de l'élément analysé en confirmant ou en remettant en question les résultats des diagrammes de synthèse ou d'autres mesures globales de l'importance de l'élément.
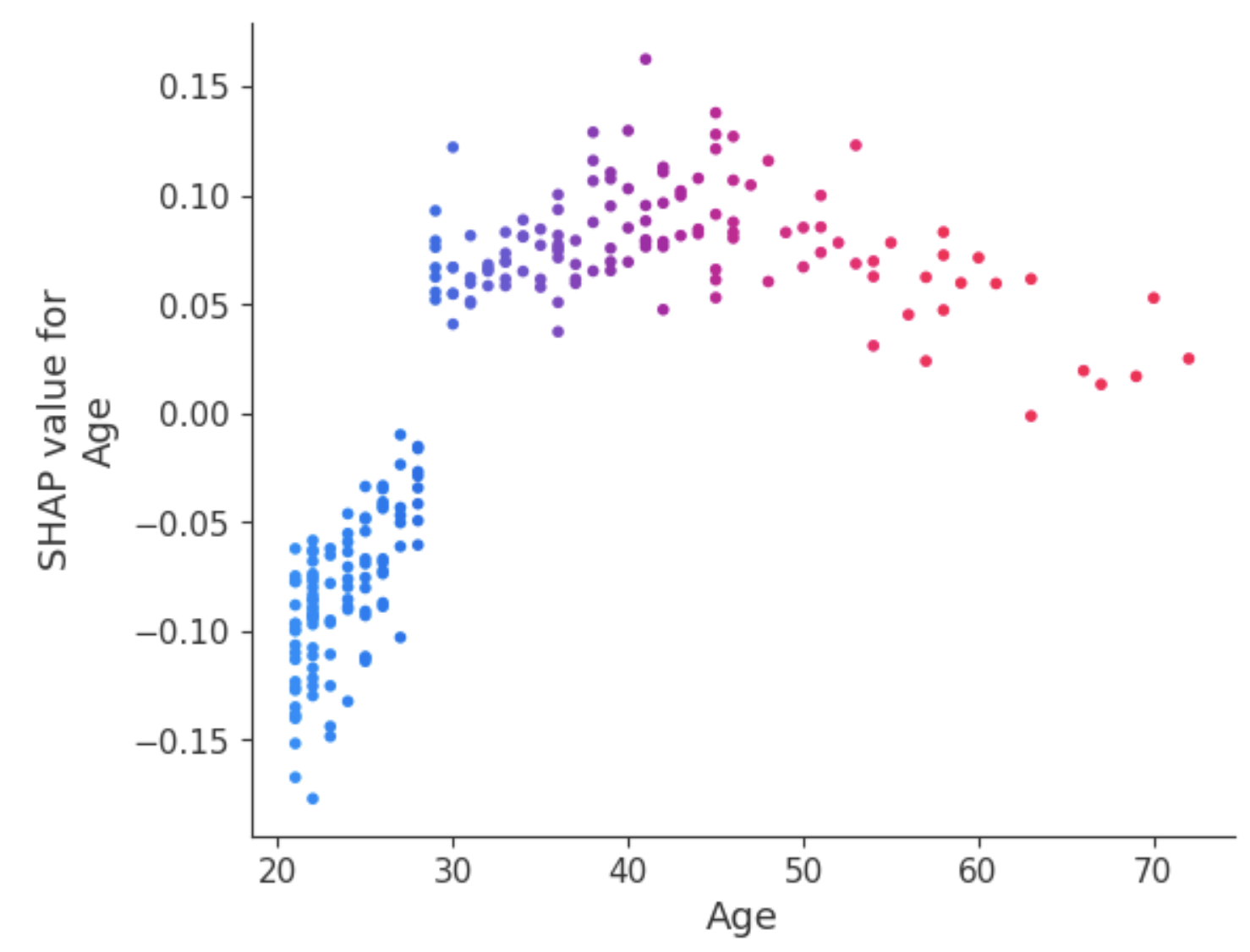
Le graphique de dépendance révèle que les patients de moins de 30 ans ont un risque plus faible d'être diagnostiqués comme diabétiques. En revanche, les personnes de plus de 30 ans sont plus susceptibles de recevoir un diagnostic de diabète.
Explications locales interprétables du modèle diagnostic (LIME en abrégé). Au lieu de fournir une compréhension globale du modèle sur l'ensemble des données, LIME se concentre sur l'explication de la prédiction du modèle pour des instances individuelles.
LIME explainer peut être mis en place en deux étapes principales : (1) importer le module lime, et (2) adapter l'explicateur à l'aide des données d'apprentissage et des cibles. Pendant cette phase, le mode est réglé sur la classification, qui correspond à la tâche en cours.
# Import the LimeTabularExplainer module
from lime.lime_tabular import LimeTabularExplainer
# Get the class names
class_names = ['Has diabetes', 'No diabetes']
# Get the feature names
feature_names = list(X_train.columns)
# Fit the Explainer on the training data set using the LimeTabularExplainer
explainer = LimeTabularExplainer(X_train.values, feature_names =
feature_names,
class_names = class_names,
mode = 'classification')L'extrait de code ci-dessous génère et affiche une explication LIME pour la 8e instance des données de test en utilisant le classificateur de la forêt aléatoire et en présentant la contribution finale des caractéristiques sous forme de tableau.
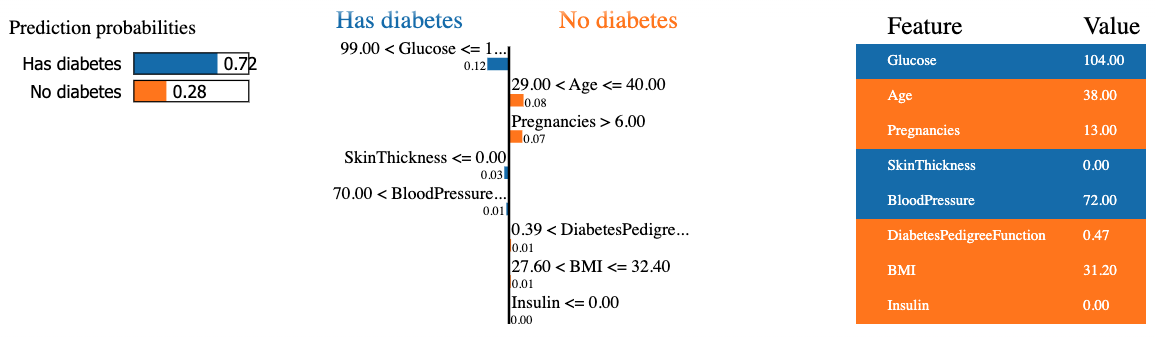
Le résultat contient trois informations principales, de gauche à droite : (1) les prédictions du modèle, (2) les contributions des caractéristiques et (3) la valeur réelle de chaque caractéristique.
Nous pouvons observer que l'on peut prédire que le huitième patient est diabétique avec un taux de confiance de 72 %. Les raisons qui ont conduit le modèle à prendre cette décision sont les suivantes :
Ces valeurs peuvent être vérifiées dans le tableau ci-contre.
Contrairement aux méthodes agnostiques, ces méthodes ne peuvent être appliquées qu'à une catégorie limitée de modèles. Parmi ces modèles figurent la régression linéaire, les arbres de décision et l'interprétabilité des réseaux neuronaux. Différentes techniques telles que DeepLIFT, Grad-CAM ou Integrated Gradients peuvent être utilisées pour expliquer les modèles d'apprentissage profond.
Lorsque vous utilisez un modèle d'arbre de décision, un arbre graphique peut être généré avec la fonction plot_tree de scikit-learn pour expliquer le processus de prise de décision du modèle de haut en bas, et une illustration est donnée ci-dessous.
L'article Deep Learning - A Tutorial for Data Scientists répondra aux questions les plus fréquemment posées sur le deep learning et explorera divers aspects du deep learning à l'aide d'exemples concrets.
Entraînons un arbre de décision avec des hyperparamètres spécifiques tels que max_depth et min_samples_leaf avant de générer l'arbre graphique.
from sklearn.tree import DecisionTreeClassifier, plot_tree
dt_clf = DecisionTreeClassifier(max_depth = 3, min_samples_leaf = 2)
dt_clf.fit(X_train, y_train)
# Predict on the test data and evaluate the model
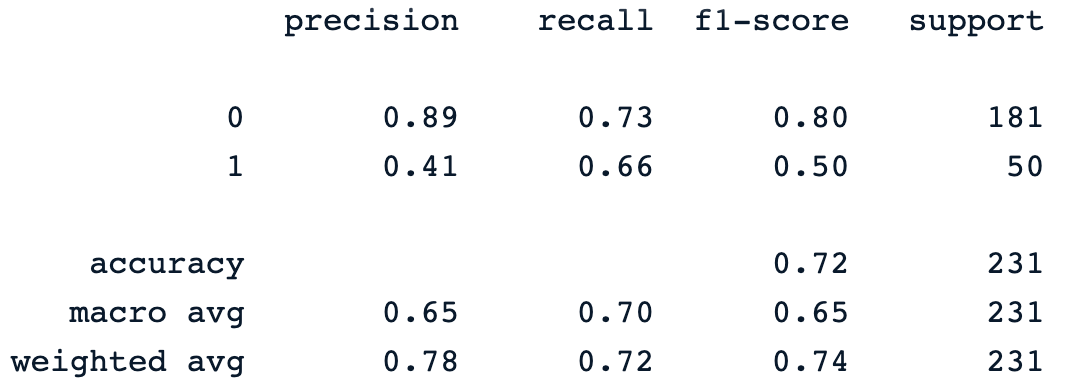
y_pred = dt_clf.predict(X_test)
print(classification_report(y_pred, y_test))L'instruction d'impression précédente génère le rapport de classification suivant du modèle.
Le processus de prise de décision du modèle peut être visualisé dans le code ci-dessous :
fig = plt.figure(figsize=(25,20))
_ = plot_tree(dt_clf,
feature_names = feature_names,
class_names = class_names,
filled=True)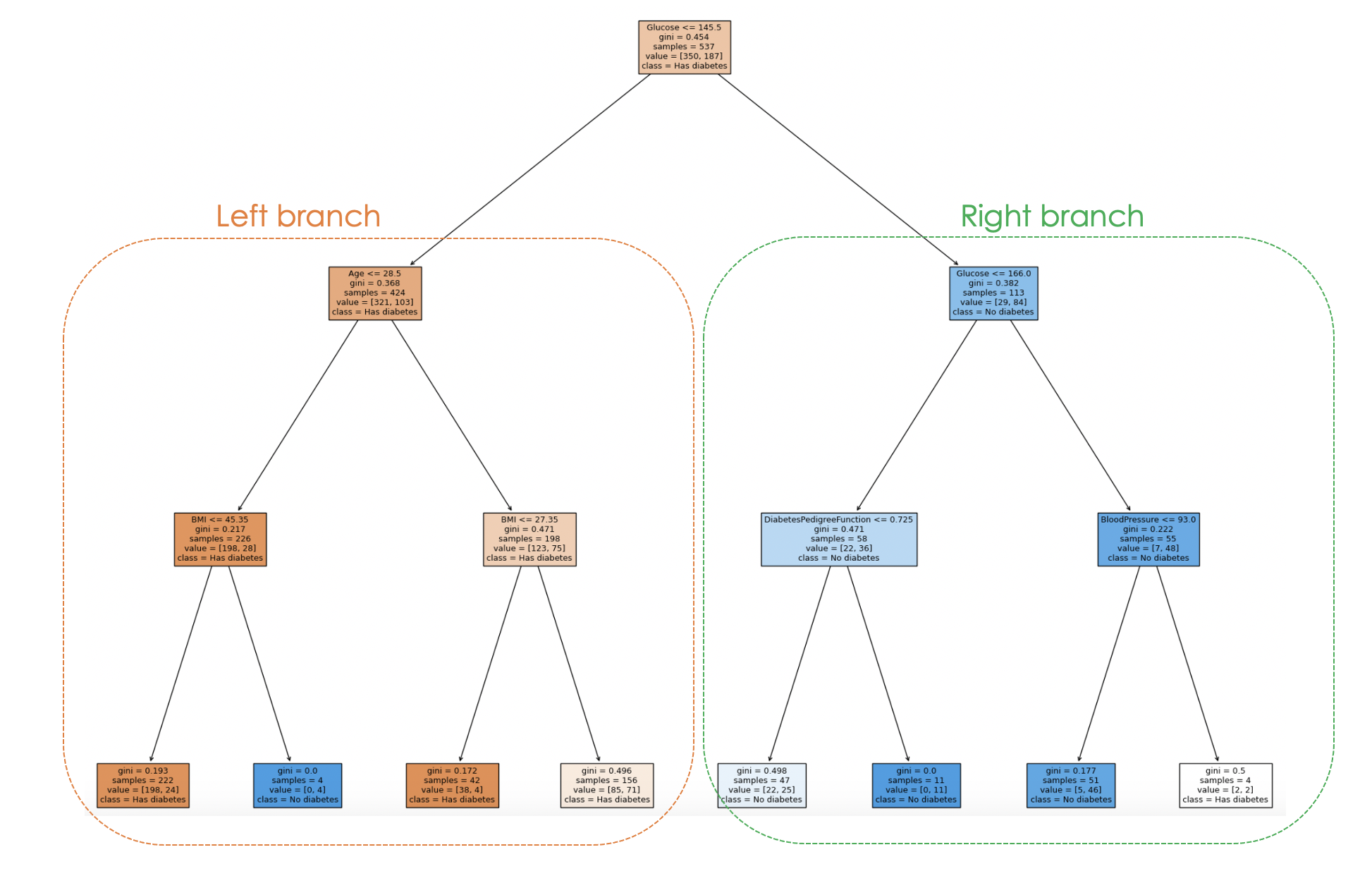
En examinant l'arborescence, on peut retracer le processus de décision pour chaque échantillon, ce qui permet de mieux comprendre le comportement et l'interprétabilité du modèle.
Dans le graphique ci-dessus, chaque nœud représente une décision ou une division basée sur une valeur de caractéristique spécifique. Pour chaque nœud interne, le graphique indique la caractéristique utilisée pour la division, la valeur du critère de division, l'impureté de Gini et le nombre d'échantillons atteignant ce nœud.
Dans les nœuds feuilles, la classe majoritaire et le nombre d'échantillons sont affichés. En outre, les couleurs des nœuds représentent la classe majoritaire, l'intensité de la couleur indiquant la proportion de la classe dominante dans ce nœud. Par exemple, les nœuds orange de la branche gauche correspondent à l'étiquette "diabète", tandis que les nœuds bleus correspondent à l'absence de diabète.
À mesure que la technologie de l'IA progresse et devient plus sophistiquée, il devient de plus en plus difficile de comprendre et d'interpréter les algorithmes pour déterminer comment ils produisent des résultats, ce qui permet aux chercheurs de continuer à explorer de nouvelles approches et à améliorer celles qui existent déjà.
De nombreux modèles d'IA explicables nécessitent une simplification du modèle sous-jacent, ce qui entraîne une perte de performance prédictive. En outre, les méthodes actuelles d'explicabilité peuvent ne pas couvrir tous les aspects du processus décisionnel, ce qui peut limiter le bénéfice de l'explication, en particulier lorsqu'il s'agit de modèles plus complexes.
De nouvelles méthodes de recherche se concentrent sur l'amélioration des techniques d'IA explicables en développant des algorithmes plus efficaces pour traiter les questions éthiques tout en créant des explications conviviales.
Enfin, grâce aux recherches en cours, nous avons plus de chances de disposer de méthodes plus sophistiquées qui favorisent la transparence, la fiabilité et l'équité.
Cet article a donné un bon aperçu de ce qu'est l'IA explicable et de certains principes qui contribuent à instaurer la confiance et peuvent fournir aux Data Scientists et aux autres parties prenantes des compétences pertinentes pour construire des modèles dignes de confiance qui aident à prendre des décisions exploitables.
Nous avons également abordé les méthodes diagnostiques et spécifiques à un modèle, en nous concentrant plus particulièrement sur la première en utilisant LIME et SHAP. En outre, les défis, les limites et certains domaines de recherche ont été mis en évidence en ce qui concerne l'IA explicable.
Pour en savoir plus sur l'éthique qui sous-tend ces technologies, consultez notre cours Introduction à l'éthique des données, qui couvre les principes de l'éthique des données, sa relation avec l'éthique de l'IA et ses caractéristiques à travers les différentes étapes du cycle de vie des données.
En savoir plus sur l'IA !
Cursus
Cours
Cours
blog
blog
Kurtis Pykes
9 min
blog
Lynn Heidmann
blog
Kurtis Pykes
15 min
Tutoriel
Tutoriel
Samuel Shaibu


