
Programma
Leadership nell'intelligenza artificiale (AI)
6 h
L’AI spiegabile indica un insieme di processi e metodi volti a fornire una spiegazione chiara e comprensibile agli esseri umani per le decisioni generate da modelli di IA e machine learning.
Integrando uno strato di spiegabilità in questi modelli, Data Scientist e professionisti del Machine Learning possono creare sistemi più affidabili e trasparenti a supporto di un’ampia gamma di stakeholder, come sviluppatori, autorità di regolamentazione e utenti finali.
Ecco alcuni principi di AI spiegabile che possono contribuire a creare fiducia:
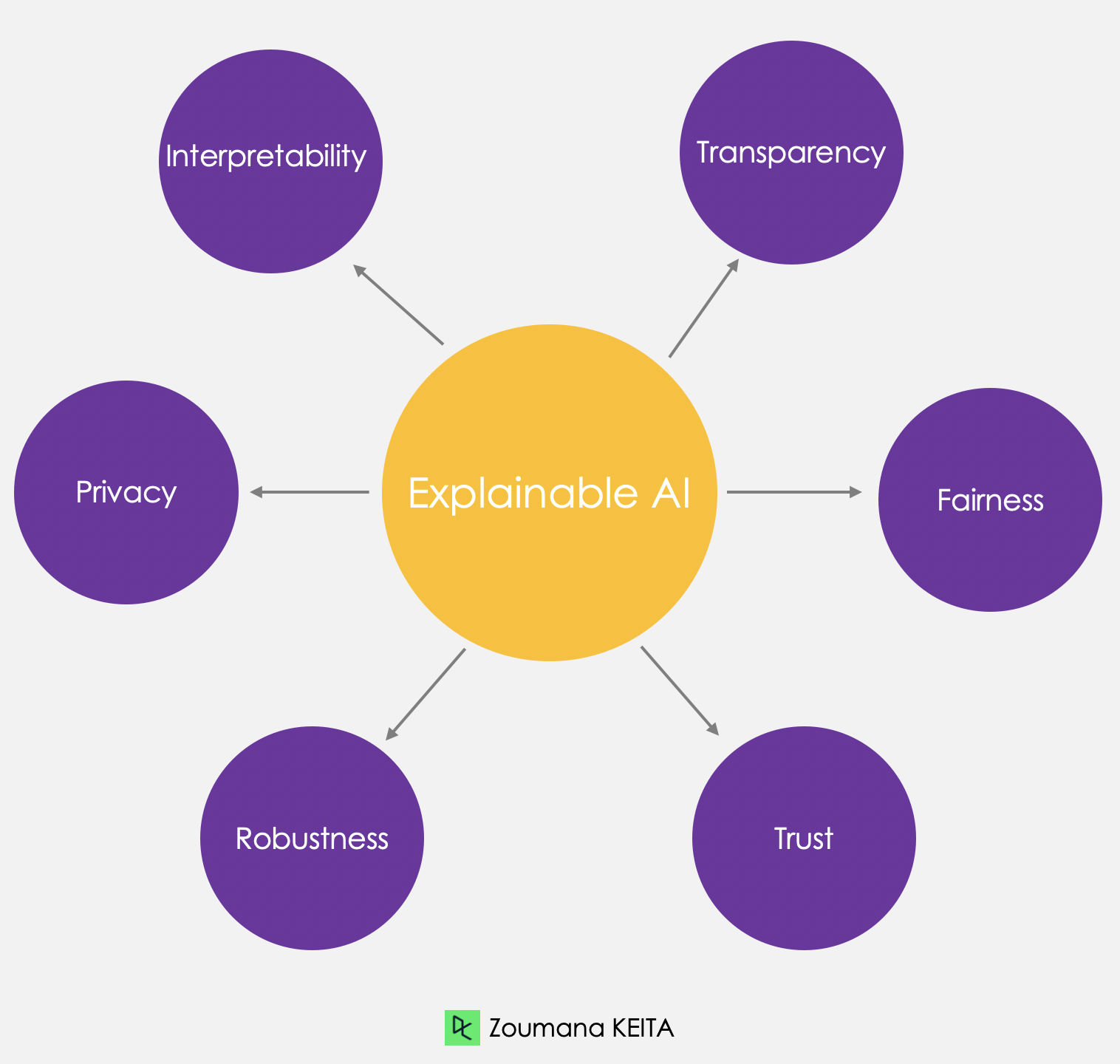
L’implementazione dell’AI spiegabile offre diversi vantaggi. Per chi prende decisioni e per gli altri stakeholder, fornisce una chiara comprensione della logica alla base delle decisioni guidate dall’IA, permettendo scelte più informate. Aiuta inoltre a individuare potenziali bias o errori nei modelli, portando a risultati più accurati ed equi.
Esistono due ampie categorie di spiegabilità dei modelli: metodi specifici per modello e metodi agnostici al modello. In questa sezione capiremo la differenza tra i due, con un’attenzione particolare ai metodi agnostici.
Entrambe le tecniche possono offrire spunti preziosi sul funzionamento interno dei modelli di machine learning, garantendo al contempo che i modelli siano efficaci e responsabili.
Per illustrare meglio questi strumenti, useremo il dataset sul diabete di Kaggle. Prima costruiremo un semplice classificatore e poi implementeremo la spiegabilità. Il codice sorgente completo è disponibile in questo workbook DataLab.
È stato costruito un classificatore Random Forest per prevedere gli esiti relativi al diabete utilizzando il dataset. Il codice è suddiviso in vari passaggi: (1) importare le librerie rilevanti, (2) creare i dataset di training e testing, (3) costruire il modello e (4) riportare le metriche di performance tramite il classification report.
# Load useful libraries
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
# Separate Features and Target Variables
X = diabetes_data.drop(columns='Outcome')
y = diabetes_data['Outcome']
# Create Train & Test Data
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3,
stratify =y,
random_state = 13)
# Build the model
rf_clf = RandomForestClassifier(max_features=2, n_estimators =100 ,bootstrap = True)
rf_clf.fit(X_train, y_train)
# Make prediction on the testing data
y_pred = rf_clf.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))L’ultima istruzione di print genera il seguente report:
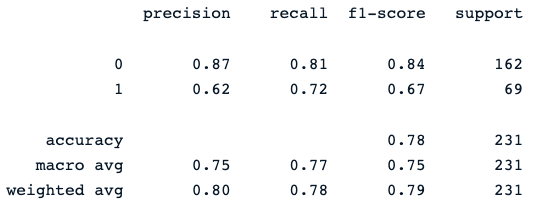
Il classificatore Random Forest offre prestazioni discrete nel prevedere gli esiti relativi al diabete, con un evidente margine di miglioramento usando modelli diversi.
Ora possiamo integrare lo strato di spiegabilità in questo modello per fornire maggiori informazioni sulle sue previsioni. La prossima sezione si concentrerà sulle due ampie categorie di spiegabilità dei modelli: metodi specifici per modello e metodi agnostici al modello.
Il nostro articolo Classification in Machine Learning: An Introduction ti aiuta a conoscere la classificazione nel machine learning, spiegando cos’è, come viene usata e alcuni esempi di algoritmi di classificazione.
Questi metodi possono essere applicati a qualsiasi modello di machine learning, indipendentemente dalla sua struttura o dal tipo. Si concentrano sull’analisi della coppia input-output delle feature. In questa sezione introdurremo e discuteremo LIME e SHAP, due modelli surrogati ampiamente utilizzati.
Sta per SHapley Additive exPlanations. Questo metodo mira a spiegare la previsione di un’istanza/osservazione calcolando il contributo di ciascuna feature alla previsione e può essere installato con il seguente comando pip.
!pip install shapDopo l’installazione:
import shap
import matplotlib.pyplot as plt
# load JS visualization code to notebook
shap.initjs()
# Create the explainer
explainer = shap.TreeExplainer(rf_clf)
shap_values = explainer.shap_values(X_test)SHAP offre una serie di strumenti di visualizzazione per migliorare l’interpretabilità del modello; nella prossima sezione ne discuteremo due: (1) importanza delle variabili con il summary plot, (2) summary plot di un target specifico e (3) dependence plot.
In questo grafico, le feature sono ordinate in base ai loro valori SHAP medi, mostrando in alto le più importanti e in basso le meno importanti, utilizzando la funzione summary_plot(). Questo aiuta a comprendere l’impatto di ciascuna feature sulle previsioni del modello.
print("Variable Importance Plot - Global Interpretation")
figure = plt.figure()
shap.summary_plot(shap_values, X_test)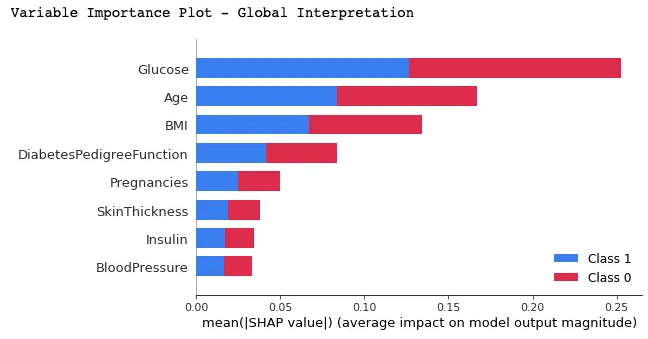
Di seguito l’interpretazione che si può trarre dal grafico sopra:
Questo approccio può fornire una panoramica più granulare dell’impatto di ciascuna feature su un risultato specifico (etichetta).
Nell’esempio seguente, shap_values[1] è usato per rappresentare i valori SHAP per le istanze classificate come etichetta 1 (affette da diabete).
shap.summary_plot(shap_values[1], X_test)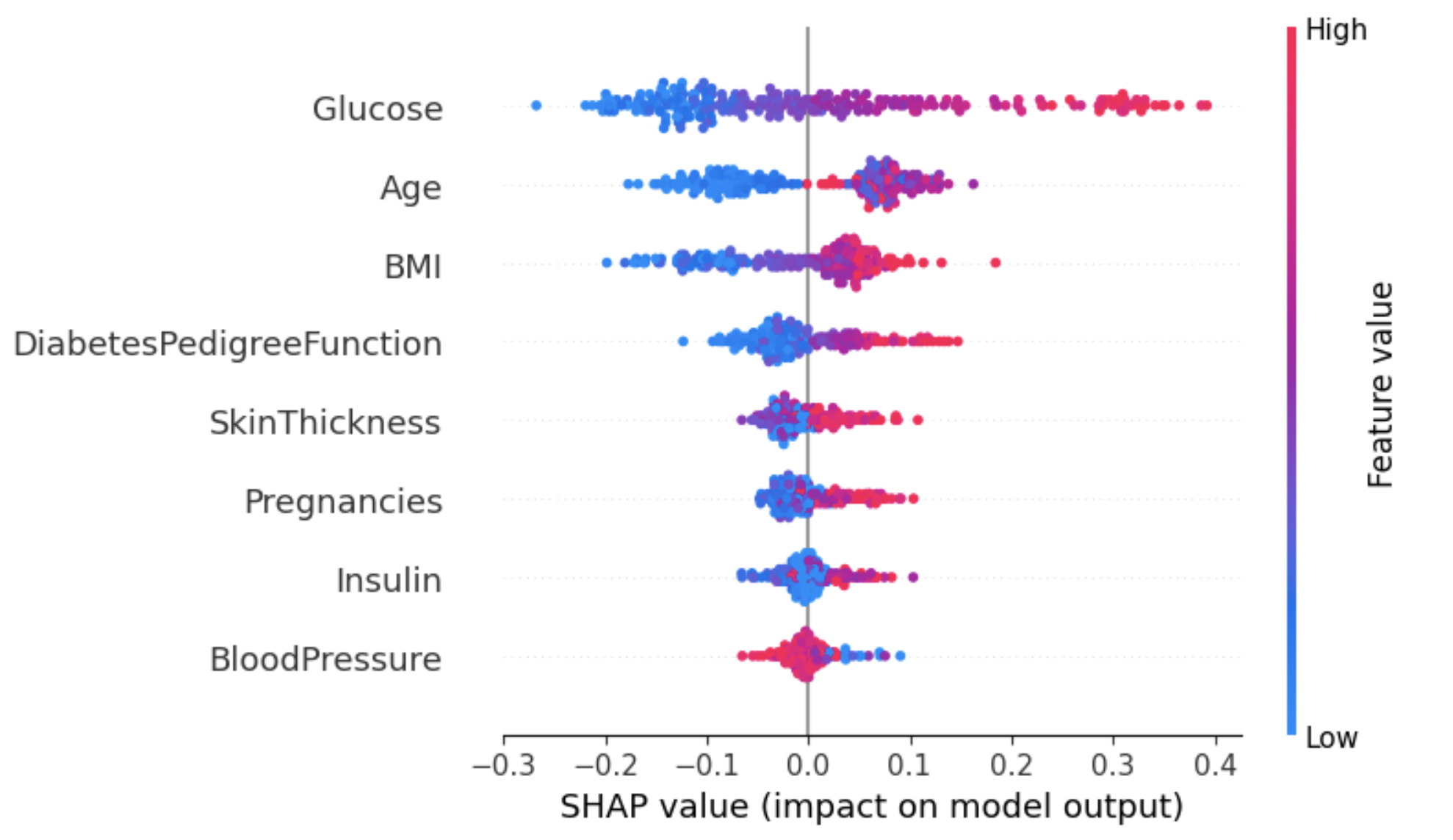
Dal grafico sopra:
Un modo per affrontare questa ambiguità per l’attributo Age è usare il dependence plot per ottenere ulteriori informazioni.
A differenza dei summary plot, i dependence plot mostrano la relazione tra una specifica feature e l’esito previsto per ciascuna istanza nei dati. Questa analisi è svolta per vari motivi e non si limita a ottenere informazioni più granulari e a convalidare l’importanza della feature analizzata confermando o mettendo in discussione i risultati dei summary plot o di altre misure globali di importanza delle feature.
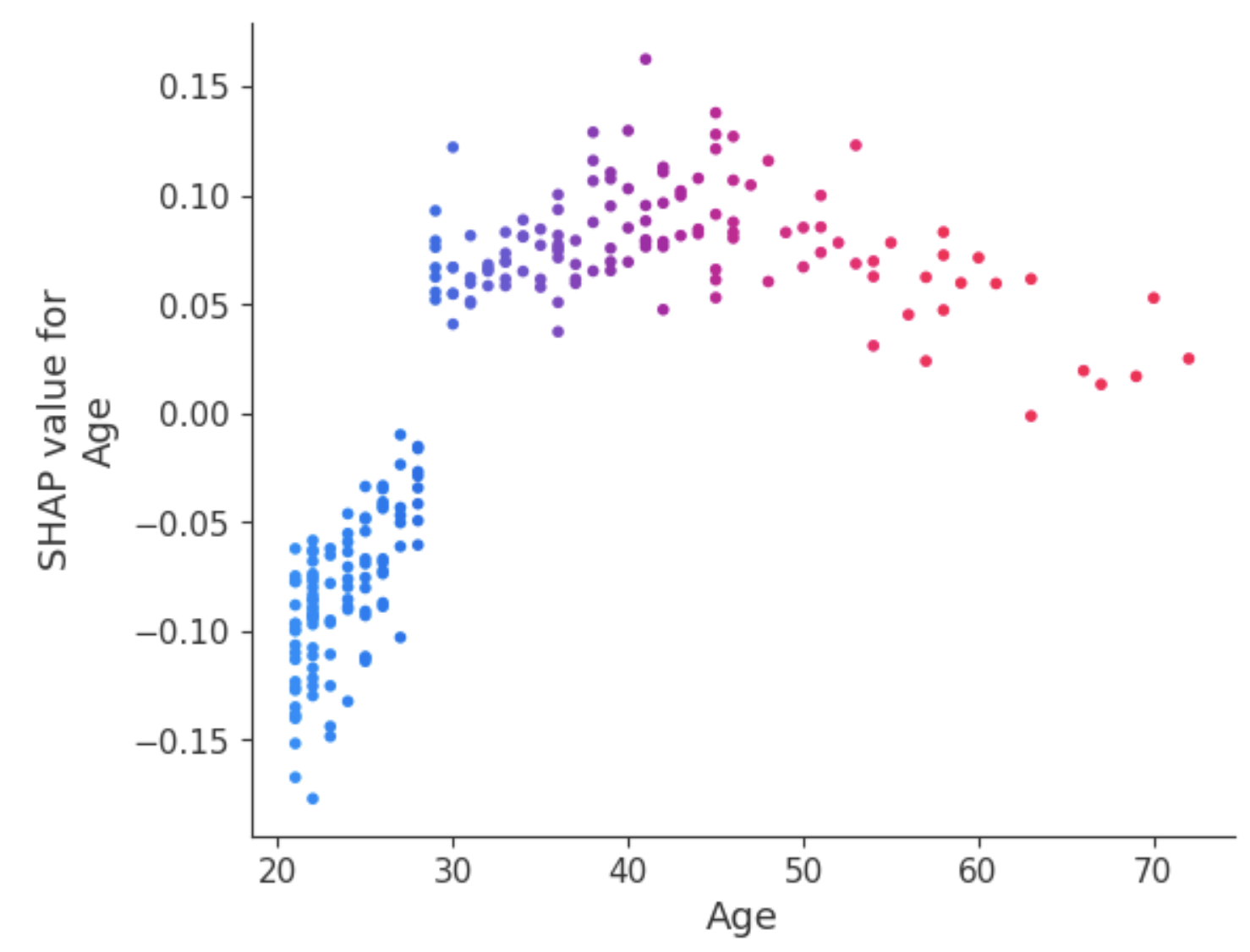
Il dependence plot mostra che i pazienti sotto i 30 anni hanno un rischio minore di essere diagnosticati con diabete. Al contrario, le persone sopra i 30 anni hanno una probabilità più alta di ricevere una diagnosi di diabete.
Local Interpretable Model-agnostic Explanations (LIME). Invece di fornire una comprensione globale del modello sull’intero dataset, LIME si concentra sullo spiegare la previsione del modello per singole istanze.
LIME può essere configurato in due passaggi principali: (1) importare il modulo lime e (2) addestrare l’explainer usando i dati di training e i target. In questa fase, la modalità è impostata su classification, in linea con il compito svolto.
# Import the LimeTabularExplainer module
from lime.lime_tabular import LimeTabularExplainer
# Get the class names
class_names = ['Has diabetes', 'No diabetes']
# Get the feature names
feature_names = list(X_train.columns)
# Fit the Explainer on the training data set using the LimeTabularExplainer
explainer = LimeTabularExplainer(X_train.values, feature_names =
feature_names,
class_names = class_names,
mode = 'classification')Il seguente snippet genera e visualizza una spiegazione LIME per l’ottava istanza nei dati di test usando il classificatore Random Forest e presenta il contributo finale delle feature in formato tabellare.
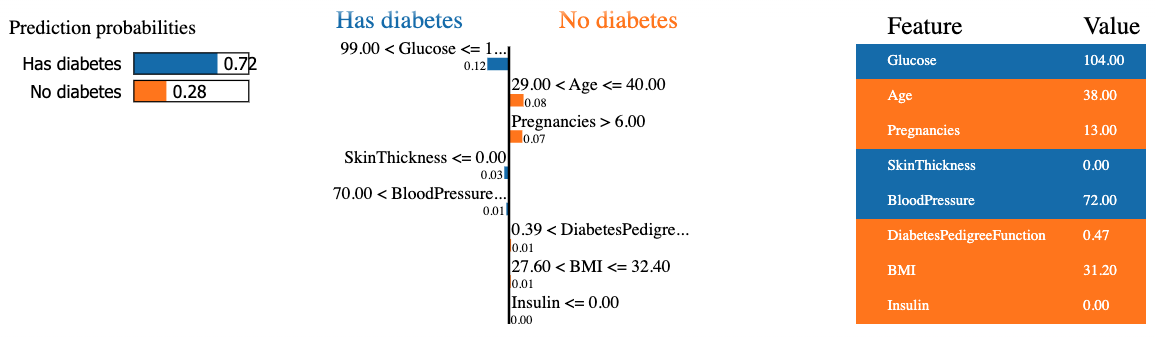
Il risultato contiene tre informazioni principali da sinistra a destra: (1) le previsioni del modello, (2) i contributi delle feature e (3) il valore effettivo di ciascuna feature.
Si osserva che l’ottavo paziente è previsto come affetto da diabete con una confidenza del 72%. Le ragioni che hanno portato il modello a questa decisione sono:
Questi valori possono essere verificati dalla tabella a destra.
A differenza dei metodi agnostici al modello, questi metodi possono essere applicati solo a una categoria limitata di modelli. Alcuni di questi includono regressione lineare, alberi decisionali e interpretabilità delle reti neurali. Diverse tecniche come DeepLIFT, Grad-CAM o Integrated Gradients possono essere sfruttate per spiegare i modelli di deep learning.
Quando si usa un modello ad albero decisionale, è possibile generare un albero grafico con la funzione plot_tree di scikit-learn per spiegare, dall’alto verso il basso, il processo decisionale del modello; un’illustrazione è riportata di seguito.
L’articolo Deep Learning - A Tutorial for Data Scientists risponde alle domande più frequenti sul deep learning ed esplora vari aspetti del deep learning con esempi reali.
Alleniamo un classificatore ad albero decisionale con iperparametri specifici come max_depth e min_samples_leaf prima di generare l’albero grafico.
from sklearn.tree import DecisionTreeClassifier, plot_tree
dt_clf = DecisionTreeClassifier(max_depth = 3, min_samples_leaf = 2)
dt_clf.fit(X_train, y_train)
# Predict on the test data and evaluate the model
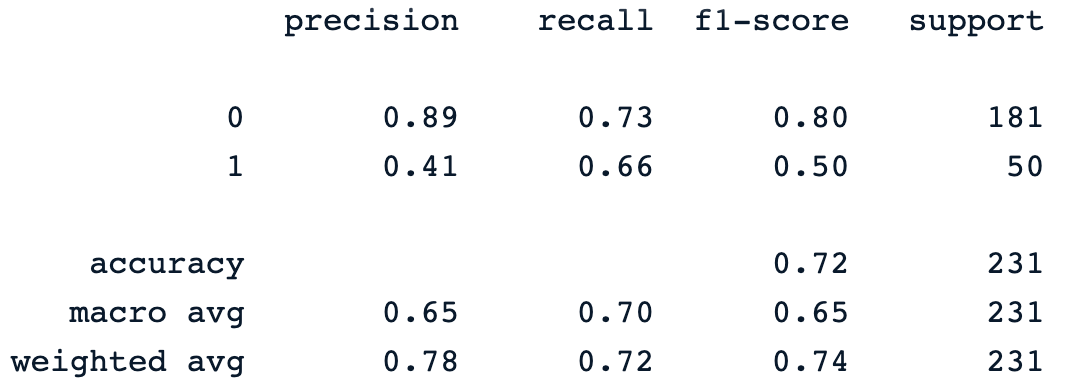
y_pred = dt_clf.predict(X_test)
print(classification_report(y_pred, y_test))La precedente istruzione di print genera il seguente report di classificazione del modello.
E il processo decisionale del modello può essere visualizzato con il codice seguente:
fig = plt.figure(figsize=(25,20))
_ = plot_tree(dt_clf,
feature_names = feature_names,
class_names = class_names,
filled=True)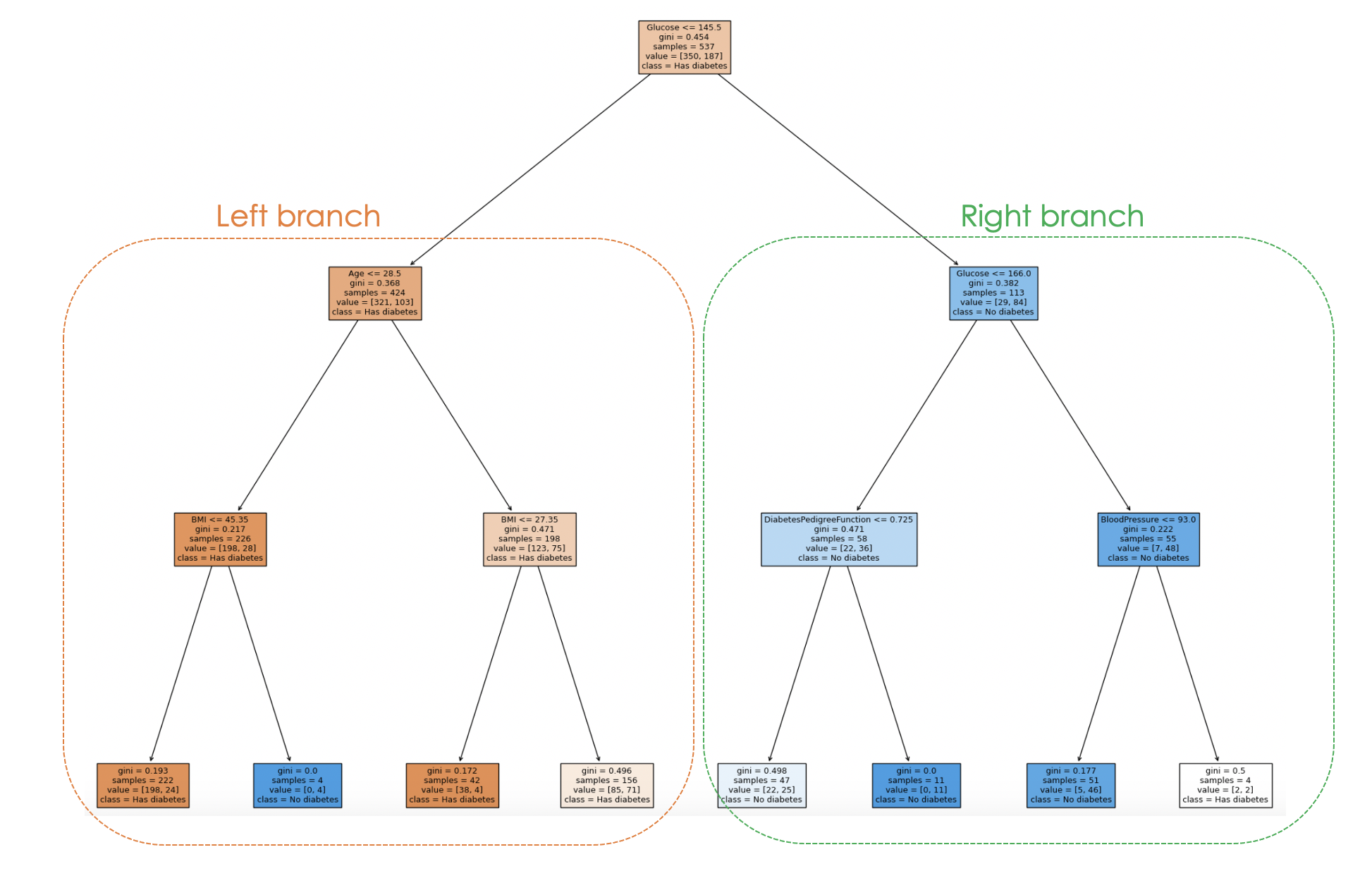
Esaminando la struttura dell’albero, è possibile seguire il processo decisionale per ciascun campione, ottenendo informazioni sul comportamento e sull’interpretabilità del modello.
Nel grafico sopra, ogni nodo rappresenta una decisione o uno split basato sul valore di una specifica feature. Per ogni nodo interno, il grafico mostra la feature usata per lo split, il valore del criterio di split, l’impurità di Gini e il numero di campioni che raggiungono quel nodo.
Nei nodi foglia, sono mostrati la classe maggioritaria e il numero di campioni. Inoltre, i colori nei nodi rappresentano la classe prevalente, con l’intensità del colore che indica la proporzione della classe dominante all’interno di quel nodo. Ad esempio, i nodi arancioni sul ramo sinistro corrispondono all’etichetta diabete, mentre quelli blu corrispondono a non diabete.
Con il continuo avanzamento dell’IA e la crescente sofisticazione, comprendere e interpretare gli algoritmi per capire come producono i risultati diventa sempre più impegnativo, spingendo i ricercatori a esplorare nuovi approcci e a migliorare quelli esistenti.
Molti modelli di AI spiegabile richiedono di semplificare il modello sottostante, comportando una perdita di performance predittiva. Inoltre, i metodi di spiegabilità attuali potrebbero non coprire tutti gli aspetti del processo decisionale, limitando il beneficio della spiegazione, soprattutto con modelli più complessi.
Nuovi filoni di ricerca si concentrano sul miglioramento delle tecniche di AI spiegabile sviluppando algoritmi più efficaci per affrontare questioni etiche e creando spiegazioni facili da usare.
Infine, con la ricerca in corso, è probabile che avremo metodi più sofisticati che promuovano trasparenza, affidabilità ed equità.
Questo articolo ha fornito una buona panoramica di che cos’è l’AI spiegabile e di alcuni principi che contribuiscono a creare fiducia e possono offrire a Data Scientist e altri stakeholder le competenze necessarie per costruire modelli affidabili per decisioni operative.
Abbiamo inoltre trattato metodi agnostici al modello e specifici per modello, con particolare attenzione ai primi tramite LIME e SHAP. Sono state inoltre evidenziate sfide, limitazioni e alcune aree di ricerca legate all’AI spiegabile.
Per saperne di più sull’etica alla base di queste tecnologie, dai un’occhiata al nostro corso Introduction to Data Ethics, che copre i principi dell’etica dei dati, la sua relazione con l’etica dell’IA e le sue caratteristiche nelle diverse fasi del ciclo di vita dei dati.
Scopri di più sull’IA!
Programma
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

