
Leerpad
Leiderschap op het gebied van kunstmatige intelligentie (AI)
6 Hr
Explainable AI verwijst naar een set processen en methoden die tot doel hebben een duidelijke, voor mensen begrijpelijke uitleg te geven voor de beslissingen die door AI- en machinelearningmodellen worden gegenereerd.
Door een uitlegbaarheidslaag in deze modellen te integreren, kunnen Data Scientists en machinelearningpraktijkmensen betrouwbaardere en transparantere systemen bouwen die een breed scala aan stakeholders ondersteunen, zoals ontwikkelaars, toezichthouders en eindgebruikers.
Hier zijn enkele XAI-principes die kunnen bijdragen aan het opbouwen van vertrouwen:
Het implementeren van explainable AI heeft verschillende voordelen. Voor besluitvormers en andere stakeholders biedt het een helder inzicht in de redenering achter door AI aangestuurde beslissingen, waardoor ze beter geïnformeerde keuzes kunnen maken. Het helpt ook om mogelijke biases of fouten in de modellen te identificeren, wat leidt tot nauwkeurigere en eerlijkere uitkomsten.
Er zijn grofweg twee categorieën modeluitlegbaarheid: modelspecifieke methoden en model-agnostische methoden. In deze sectie bespreken we het verschil tussen beide, met specifieke focus op de model-agnostische methoden.
Beide technieken kunnen waardevolle inzichten bieden in het interne functioneren van machinelearningmodellen, terwijl ze ervoor zorgen dat de modellen effectief en verantwoord zijn.
Om deze tools beter te illustreren, gebruiken we de diabetesdataset van Kaggle. Eerst bouwen we een eenvoudige classifier en vervolgens implementeren we de uitlegbaarheid. De volledige broncode is beschikbaar in deze DataLab-workbook.
Er wordt een Random Forest-classifier gebouwd om diabetesuitkomsten te voorspellen met de diabetesdataset. De code is opgedeeld in meerdere stappen: (1) relevante libraries importeren, (2) trainings- en testdatasets maken, (3) het model bouwen en (4) de prestatiestatistieken rapporteren via het classificatierapport.
# Load useful libraries
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
# Separate Features and Target Variables
X = diabetes_data.drop(columns='Outcome')
y = diabetes_data['Outcome']
# Create Train & Test Data
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3,
stratify =y,
random_state = 13)
# Build the model
rf_clf = RandomForestClassifier(max_features=2, n_estimators =100 ,bootstrap = True)
rf_clf.fit(X_train, y_train)
# Make prediction on the testing data
y_pred = rf_clf.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))De laatste print-opdracht genereert het volgende rapport:
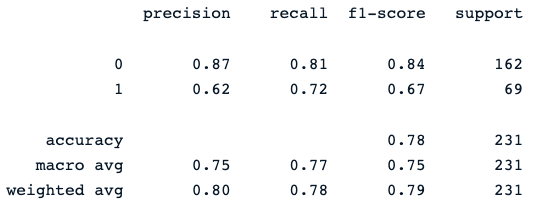
De random forest-classifier levert een behoorlijke prestatie bij het voorspellen van diabetesuitkomsten, met duidelijk ruimte voor verbetering met andere modellen.
Nu kunnen we de uitlegbaarheidslaag in dit model integreren om meer inzicht te geven in de voorspellingen. De volgende sectie richt zich op de twee brede categorieën van modeluitlegbaarheid: modelspecifieke methoden en model-agnostische methoden.
Ons artikel Classificatie in machine learning: een introductie helpt je meer te leren over classificatie in machine learning: wat het is, hoe het wordt gebruikt en enkele voorbeelden van classificatie-algoritmen.
Deze methoden zijn toepasbaar op elk machinelearningmodel, ongeacht de structuur of het type. Ze richten zich op het analyseren van de input-outputkoppeling van features. In deze sectie introduceren en bespreken we LIME en SHAP, twee veelgebruikte surrogaatmodellen.
Dit staat voor SHapley Additive exPlanations. Deze methode wil de voorspelling van een instantie/observatie uitleggen door de bijdrage van elke feature aan de voorspelling te berekenen. Je kunt het installeren met de volgende pip-opdracht.
!pip install shapNa de installatie:
import shap
import matplotlib.pyplot as plt
# load JS visualization code to notebook
shap.initjs()
# Create the explainer
explainer = shap.TreeExplainer(rf_clf)
shap_values = explainer.shap_values(X_test)SHAP biedt een reeks visualisatietools om de uitlegbaarheid van modellen te vergroten. In de volgende sectie bespreken we er drie: (1) variabelebelang met de summary-plot, (2) summary-plot voor een specifiek target en (3) de afhankelijkheidsplot.
In deze plot worden features gerangschikt op hun gemiddelde SHAP-waarden: de belangrijkste bovenaan en de minst belangrijke onderaan, met behulp van de functie summary_plot(). Dit helpt om de impact van elke feature op de voorspellingen van het model te begrijpen.
print("Variable Importance Plot - Global Interpretation")
figure = plt.figure()
shap.summary_plot(shap_values, X_test)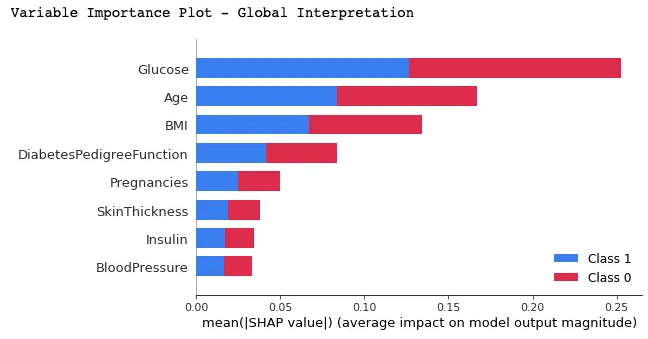
Dit kun je uit de bovenstaande grafiek afleiden:
Met deze aanpak krijg je een meer gedetailleerd beeld van de impact van elke feature op een specifieke uitkomst (label).
In het onderstaande voorbeeld wordt shap_values[1] gebruikt om de SHAP-waarden te tonen voor instanties die als label 1 (diabetes) zijn geclassificeerd.
shap.summary_plot(shap_values[1], X_test)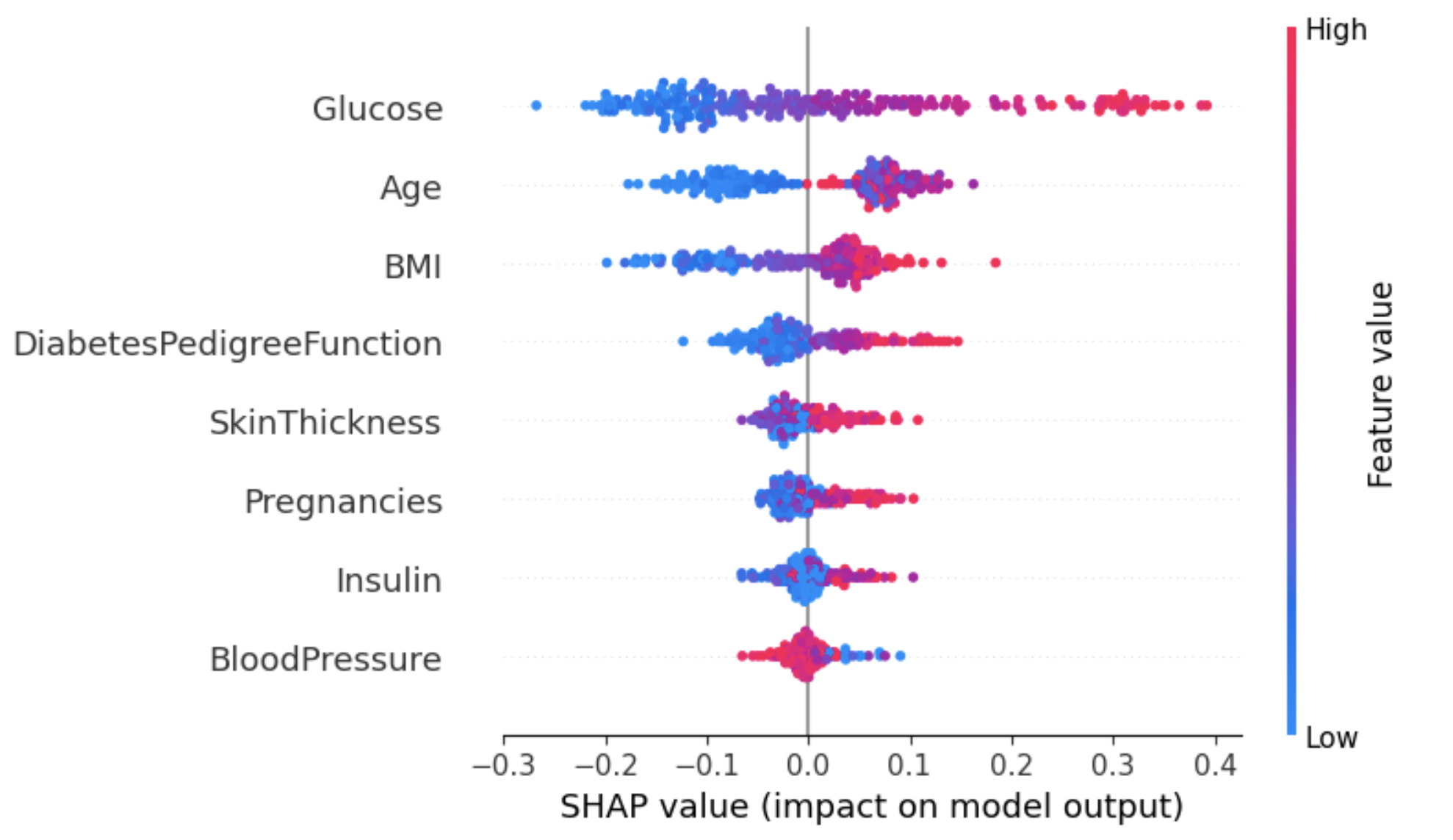
Uit de bovenstaande grafiek:
Een manier om met deze ambiguïteit voor de feature Age om te gaan, is de afhankelijkheidsplot te gebruiken voor meer inzicht.
In tegenstelling tot summary-plots laten afhankelijkheidsplots de relatie zien tussen een specifieke feature en de voorspelde uitkomst voor elke instantie in de data. Deze analyse wordt om meerdere redenen uitgevoerd en is niet beperkt tot het verkrijgen van meer detail; ze helpt ook het belang van de geanalyseerde feature te valideren door de bevindingen uit de summary-plots of andere globale feature-importance-maatstaven te bevestigen of te betwisten.
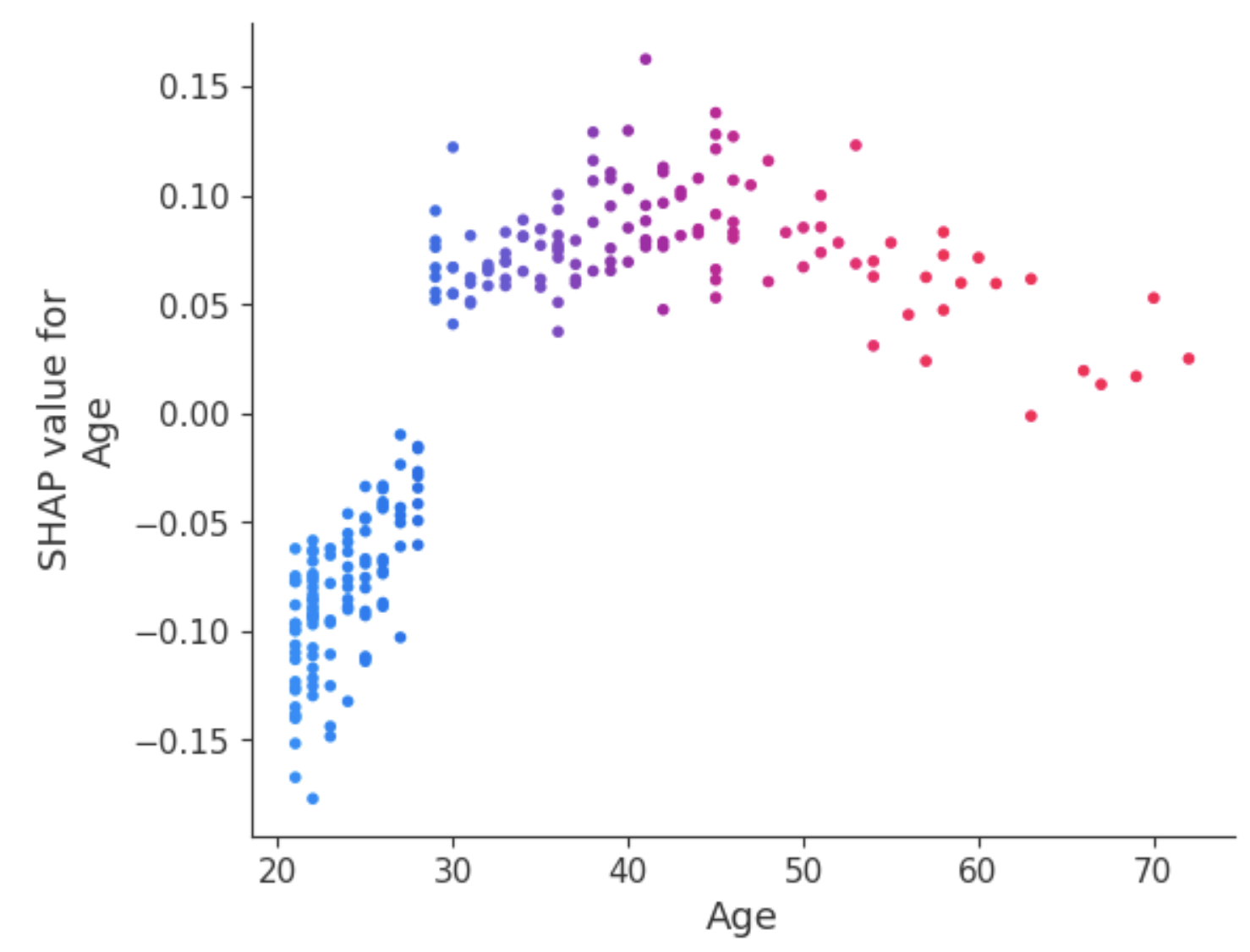
De afhankelijkheidsplot laat zien dat patiënten jonger dan 30 een lager risico hebben op een diabetesdiagnose. Daarentegen hebben mensen ouder dan 30 een grotere kans op een diabetesdiagnose.
Local Interpretable Model-agnostic Explanations (kortweg LIME). In plaats van een globaal begrip van het model op de volledige dataset te geven, richt LIME zich op het uitleggen van de voorspelling van het model voor individuele instanties.
De LIME-explainer kun je in twee hoofdstappen opzetten: (1) de lime-module importeren en (2) de explainer fitten met de trainingsdata en de targets. In deze fase wordt de modus ingesteld op classification, wat overeenkomt met de uitgevoerde taak.
# Import the LimeTabularExplainer module
from lime.lime_tabular import LimeTabularExplainer
# Get the class names
class_names = ['Has diabetes', 'No diabetes']
# Get the feature names
feature_names = list(X_train.columns)
# Fit the Explainer on the training data set using the LimeTabularExplainer
explainer = LimeTabularExplainer(X_train.values, feature_names =
feature_names,
class_names = class_names,
mode = 'classification')De onderstaande code genereert en toont een LIME-uitleg voor de 8e instantie in de testdata met behulp van de random forest-classifier, waarbij de uiteindelijke featurebijdrage in tabelvorm wordt gepresenteerd.
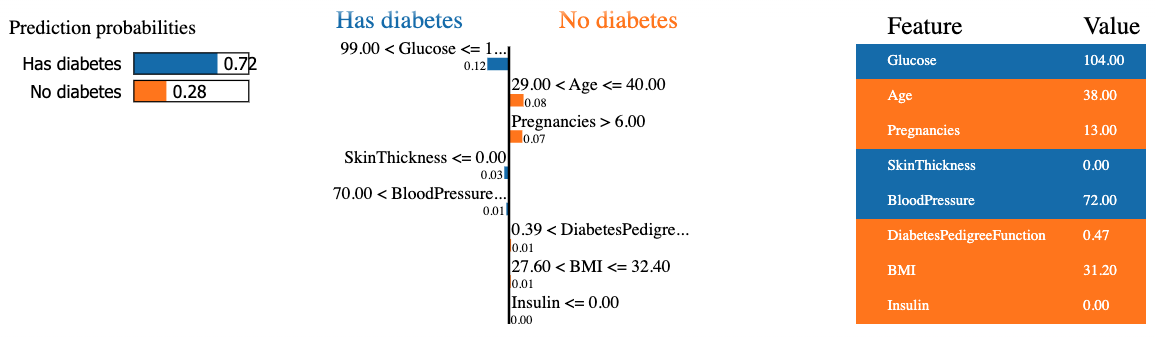
Het resultaat bevat van links naar rechts drie hoofdonderdelen: (1) de voorspellingen van het model, (2) de bijdragen van features en (3) de werkelijke waarde per feature.
We zien dat voor de achtste patiënt wordt voorspeld dat hij/zij diabetes heeft, met 72% zekerheid. De redenen die het model tot deze beslissing brachten, zijn:
Die waarden zijn te verifiëren in de tabel rechts.
In tegenstelling tot model-agnostische methoden zijn deze alleen toepasbaar op een beperkte categorie modellen. Enkele daarvan zijn lineaire regressie, beslissingsbomen en uitlegbaarheid voor neurale netwerken. Verschillende technieken, zoals DeepLIFT, Grad-CAM of Integrated Gradients, kunnen worden gebruikt om deep-learningmodellen uit te leggen.
Bij gebruik van een beslissingsboommodel kan met de functie plot_tree uit scikit-learn een grafische boom worden gegenereerd om het beslisproces van het model van boven naar beneden uit te leggen; hieronder staat een illustratie.
Het artikel Deep Learning - A Tutorial for Data Scientists beantwoordt de meest gestelde vragen over deep learning en verkent verschillende aspecten met praktijkvoorbeelden.
Laten we een decision tree-classifier trainen met specifieke hyperparameters zoals max_depth en min_samples_leaf voordat we de grafische boom genereren.
from sklearn.tree import DecisionTreeClassifier, plot_tree
dt_clf = DecisionTreeClassifier(max_depth = 3, min_samples_leaf = 2)
dt_clf.fit(X_train, y_train)
# Predict on the test data and evaluate the model
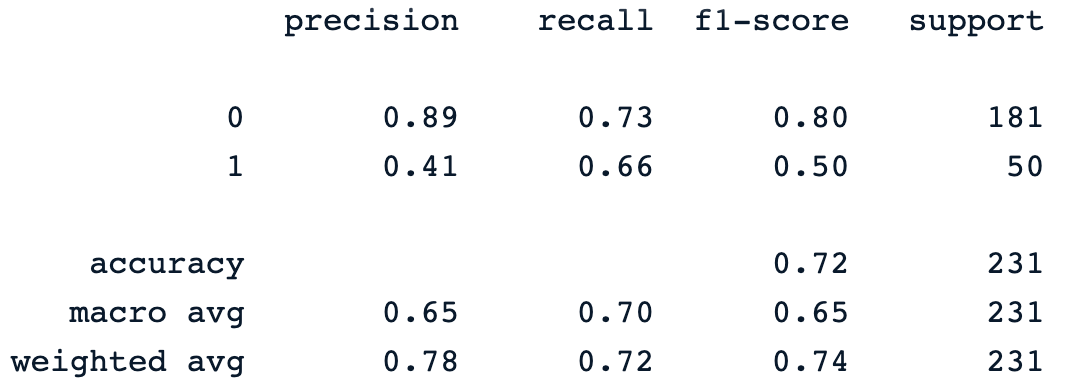
y_pred = dt_clf.predict(X_test)
print(classification_report(y_pred, y_test))De vorige print-opdracht genereert het volgende classificatierapport van het model.
En het beslisproces van het model kan met onderstaande code worden gevisualiseerd:
fig = plt.figure(figsize=(25,20))
_ = plot_tree(dt_clf,
feature_names = feature_names,
class_names = class_names,
filled=True)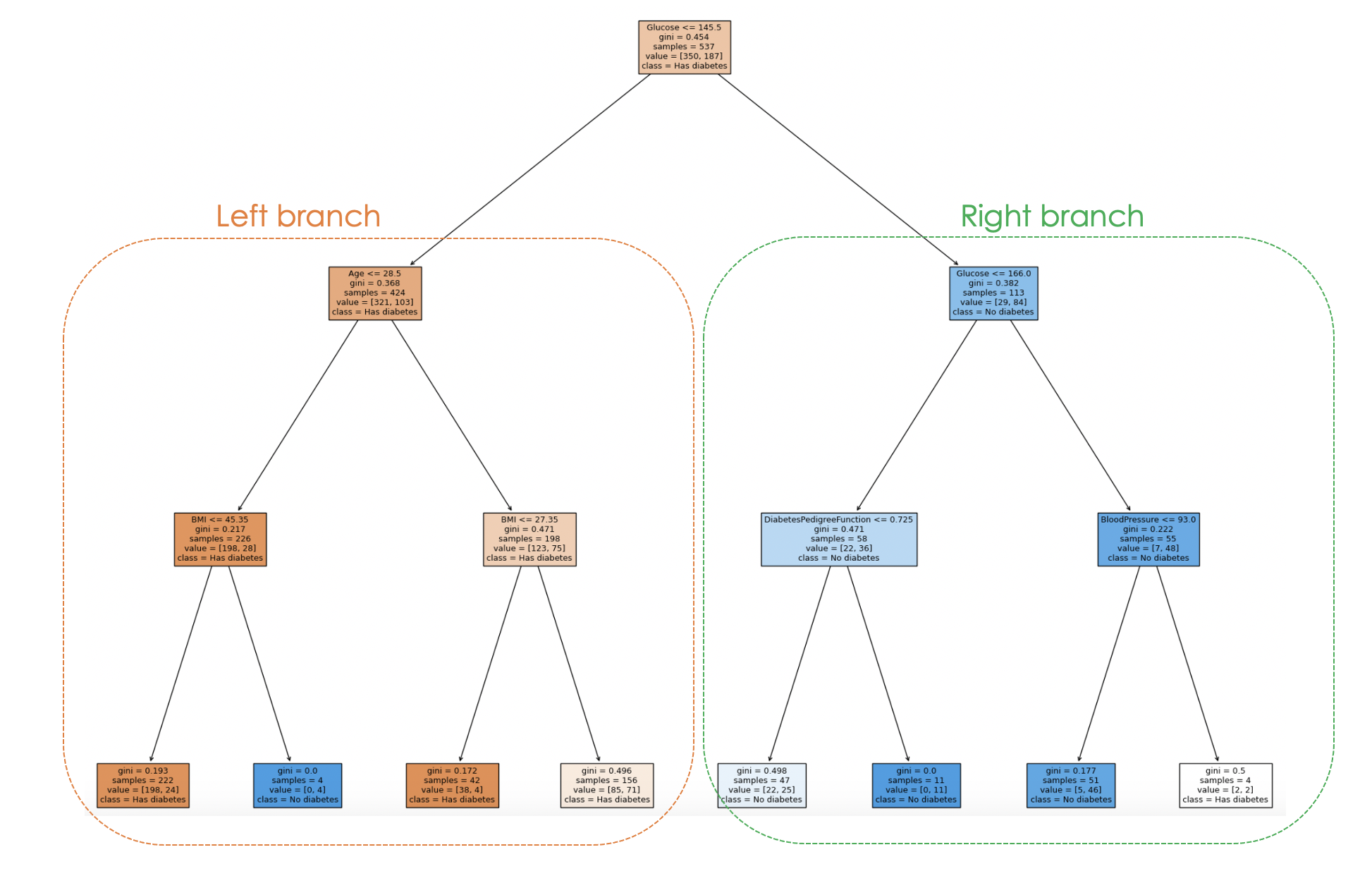
Door de boomstructuur te bekijken, kun je het beslisproces voor elke sample volgen, wat inzicht geeft in het gedrag en de uitlegbaarheid van het model.
In de bovenstaande plot staat elk knooppunt voor een beslissing of splitsing op basis van een specifieke featurewaarde. Voor elk intern knooppunt toont de plot de gebruikte feature voor de splitsing, de grenswaarde, de Gini-onzuiverheid en het aantal samples dat dat knooppunt bereikt.
In de bladknooppunten worden de meerderheidsklasse en het aantal samples weergegeven. Ook geven de kleuren in de knooppunten de meerderheidsklasse aan, waarbij de kleurintensiteit de proportie van de dominante klasse binnen dat knooppunt weergeeft. Zo komen de oranje knooppunten op de linker tak overeen met het diabeteslabel, terwijl de blauwe knooppunten overeenkomen met geen diabetes.
Naarmate AI-technologie blijft vooruitgaan en verfijnder wordt, wordt het steeds uitdagender om de algoritmen te begrijpen en te interpreteren om te achterhalen hoe ze uitkomsten produceren. Daardoor blijven onderzoekers nieuwe benaderingen verkennen en bestaande verbeteren.
Veel explainable-AI-modellen vereisen vereenvoudiging van het onderliggende model, wat leidt tot verlies aan voorspellende prestaties. Daarnaast dekken huidige uitlegbaarheidsmethoden mogelijk niet alle aspecten van het beslisproces, wat het nut van de uitleg kan beperken, vooral bij complexere modellen.
Nieuw onderzoek richt zich op het verbeteren van XAI-technieken door effectievere algoritmen te ontwikkelen die ethische kwesties aanpakken en tegelijkertijd gebruiksvriendelijke uitleg bieden.
Tot slot is de kans groot dat we dankzij lopend onderzoek meer geavanceerde methoden zullen krijgen die transparantie, betrouwbaarheid en eerlijkheid bevorderen.
Dit artikel gaf een goed overzicht van wat explainable AI is en enkele principes die bijdragen aan het opbouwen van vertrouwen en Data Scientists en andere stakeholders relevante vaardigheden kunnen bieden om betrouwbare modellen te bouwen die helpen bij actiegerichte beslissingen.
We behandelden ook model-agnostische en modelspecifieke methoden, met speciale focus op de eerste, met LIME en SHAP. Bovendien zijn de uitdagingen, beperkingen en enkele onderzoeksgebieden rond explainable AI belicht.
Wil je meer weten over de ethiek achter dit soort technologie? Bekijk dan onze cursus Introduction to Data Ethics, die de principes van data-ethiek behandelt, de relatie met AI-ethiek en de kenmerken in de verschillende fasen van de datalevenscyclus.
Leer meer over AI!
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
