Muitos setores e organizações estão usando inteligência artificial e modelos de aprendizado de máquina para tomar decisões informadas. No entanto, à medida que essas tecnologias continuam avançando e se tornando mais complexas, os seres humanos são desafiados a entender e reconstituir o processo de tomada de decisão dessas soluções de IA. Esse desafio pode ser enfrentado com o uso de IA explicável (XAI, na sigla em inglês).
Aqui, exploraremos o que é IA explicável, destacaremos sua importância e ilustraremos seus objetivos e benefícios. Na segunda parte, apresentaremos uma visão geral e a implementação em Python de dois modelos substitutos populares, LIME e SHAP, que podem ajudar a interpretar modelos de aprendizado de máquina.
O que é IA explicável (XAI)?
A IA explicável refere-se a um conjunto de processos e métodos que visam fornecer uma explicação clara e compreensível para os seres humanos sobre as decisões geradas pela IA e pelos modelos de aprendizado de máquina.
Ao integrar uma camada de explicabilidade a esses modelos, os cientistas de dados e os profissionais de aprendizado de máquina podem criar sistemas mais confiáveis e transparentes para ajudar uma ampla gama de partes interessadas, como desenvolvedores, reguladores e usuários finais.
Criando confiança por meio de IA explicável
Aqui estão alguns princípios de IA explicáveis que podem contribuir para criar confiança:
- Transparência. Garantir que as partes interessadas entendam o processo de tomada de decisão dos modelos.
- Equidade. Garantir que as decisões dos modelos sejam justas para todos, inclusive para pessoas de grupos protegidos (raça, religião, gênero, deficiência, etnia).
- Confiança. Avaliação do nível de confiança dos usuários humanos que usam o sistema de IA.
- Robustez. Ser resiliente a mudanças nos dados de entrada ou nos parâmetros do modelo, mantendo um desempenho consistente e confiável mesmo quando confrontado com incertezas ou situações inesperadas.
- Privacidade. Garantir a proteção de informações confidenciais do usuário.
- Interpretabilidade. Fornecer explicações compreensíveis para suas previsões e resultados.
Há vários benefícios na implementação da IA explicável. Para os tomadores de decisão e outras partes interessadas, ele oferece uma compreensão clara da lógica por trás das decisões baseadas em IA, permitindo que eles façam escolhas mais bem informadas. Isso também ajuda a identificar possíveis vieses ou erros nos modelos, levando a resultados mais precisos e justos.
Exemplos de IA explicáveis
Há duas categorias amplas de explicabilidade de modelos: métodos específicos de modelos e métodos agnósticos de modelos. Nesta seção, entenderemos a diferença entre ambos, com foco específico nos métodos agnósticos de modelo.
Ambas as técnicas podem oferecer insights valiosos sobre o funcionamento interno dos modelos de aprendizado de máquina e, ao mesmo tempo, garantir que os modelos sejam eficazes e responsáveis.
Para ilustrar melhor essas ferramentas, usaremos o conjunto de dados de diabetes do Kaggle. Primeiro, criaremos um classificador simples e, em seguida, implementaremos a explicabilidade. O código-fonte completo está disponível no DataCamp Workspace.
Criar classificador
Um classificador Random Forest foi criado para prever os resultados do diabetes usando o conjunto de dados do diabetes. O código é dividido em várias etapas: (1) importar bibliotecas relevantes, (2) criar conjuntos de dados de treinamento e teste, (3) criar o modelo e (4) informar as métricas de desempenho por meio do relatório de classificação.
# Load useful libraries
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
# Separate Features and Target Variables
X = diabetes_data.drop(columns='Outcome')
y = diabetes_data['Outcome']
# Create Train & Test Data
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3,
stratify =y,
random_state = 13)
# Build the model
rf_clf = RandomForestClassifier(max_features=2, n_estimators =100 ,bootstrap = True)
rf_clf.fit(X_train, y_train)
# Make prediction on the testing data
y_pred = rf_clf.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))A última instrução de impressão gera o seguinte relatório:
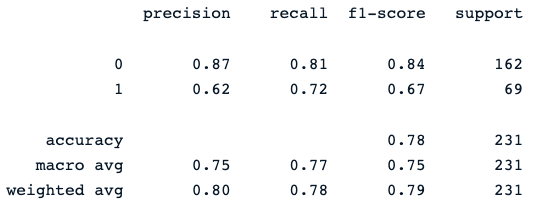
O classificador de floresta aleatória oferece um desempenho decente na previsão dos resultados do diabetes, com espaço óbvio para melhorias usando modelos diferentes.
Agora, podemos integrar a camada de explicabilidade a esse modelo para fornecer mais informações sobre suas previsões. A próxima seção se concentrará nas duas grandes categorias de explicabilidade do modelo: métodos específicos do modelo e métodos agnósticos do modelo.
Nosso Classificação em aprendizado de máquina: Uma introdução O artigo ajuda você a aprender sobre classificação no aprendizado de máquina, analisando o que é, como é usada e alguns exemplos de algoritmos de classificação.
Métodos agnósticos de modelo
Esses métodos podem ser aplicados a qualquer modelo de aprendizado de máquina, independentemente de sua estrutura ou tipo. Eles se concentram na análise do par de entrada e saída dos recursos. Esta seção apresentará e discutirá o LIME e o SHAP, dois modelos substitutos amplamente usados.
SHAP
Significa SHapley AdditiveexPlanations. Esse método tem como objetivo explicar a previsão de uma instância/observação calculando a contribuição de cada recurso para a previsão, e pode ser instalado usando o seguinte comando pip.
!pip install shapApós a instalação:
- A biblioteca principal do shap é importada.
- A classe TreeExplainer é usada para explicar modelos baseados em árvores, juntamente com o initjs.
- A função shape.initjs() inicializa o código JavaScript necessário para exibir as visualizações do SHAP em um ambiente de notebook jupyter.
- Por fim, após instanciar a classe TreeExplainer com o classificador de floresta aleatória, os valores de forma são computados para cada recurso de cada instância no conjunto de dados de teste.
import shap
import matplotlib.pyplot as plt
# load JS visualization code to notebook
shap.initjs()
# Create the explainer
explainer = shap.TreeExplainer(rf_clf)
shap_values = explainer.shap_values(X_test)O SHAP oferece uma série de ferramentas de visualização para melhorar a interpretabilidade do modelo, e a próxima seção discutirá duas delas: (1) importância da variável com o gráfico de resumo, (2) gráfico de resumo de um alvo específico e (3) gráfico de dependência.
Importância da variável com gráfico de resumo
Nesse gráfico, os recursos são classificados por seus valores médios de SHAP, mostrando os recursos mais importantes na parte superior e os menos importantes na parte inferior, usando a função summary_plot(). Isso ajuda a entender o impacto de cada recurso nas previsões do modelo.
print("Variable Importance Plot - Global Interpretation")
figure = plt.figure()
shap.summary_plot(shap_values, X_test)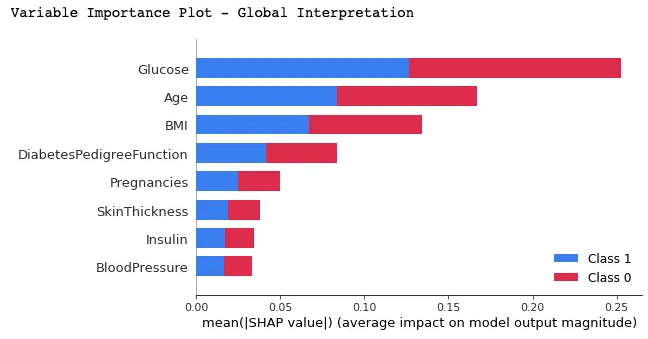
Abaixo está a interpretação que pode ser feita a partir do gráfico acima:
- Podemos observar que as cores vermelha e azul ocupam metade dos retângulos horizontais de cada classe. Isso significa que cada recurso tem um impacto igual na classificação dos casos de diabetes (rótulo=1) e não diabetes (rótulo=0).
- No entanto, a glicose, a idade e o IMC são os três primeiros recursos com maior poder de previsão.
- Por outro lado, Pregnancies, SkinThicknes, Insulin e BloodPressure não contribuem tanto quanto os três primeiros recursos.
Gráfico de resumo em um rótulo específico
O uso dessa abordagem pode fornecer uma visão geral mais detalhada do impacto de cada recurso em um resultado específico (rótulo).
No exemplo abaixo, shap_values[1] é usado para representar os valores SHAP para instâncias classificadas como rótulo 1 (com diabetes).
shap.summary_plot(shap_values[1], X_test)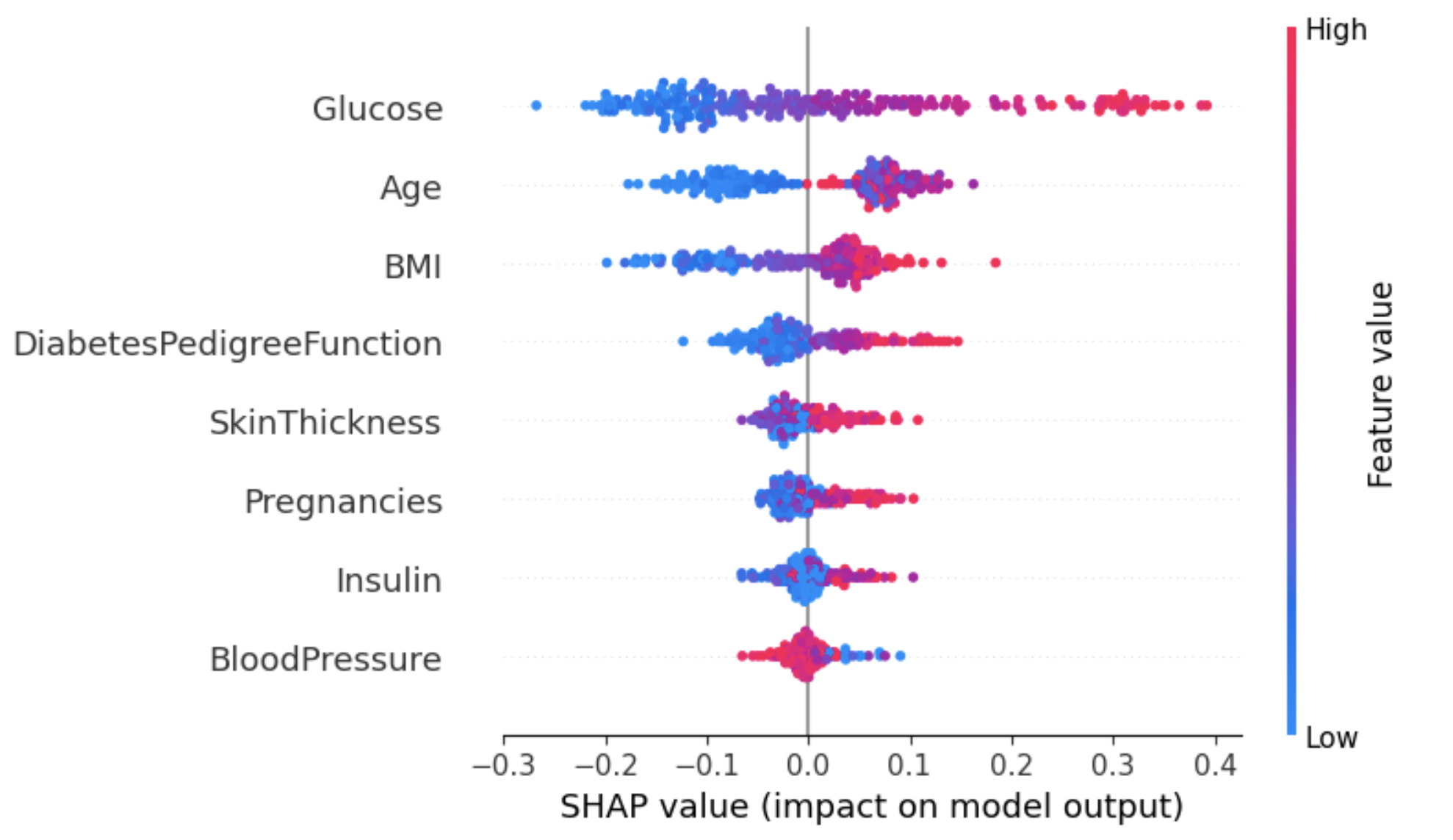
Do gráfico acima:
- O eixo Y representa os recursos classificados por seus valores médios absolutos de SHAP, semelhante ao gráfico da imagem 2.
- O eixo X representa os valores de SHAP. Os valores positivos de um determinado recurso aproximam a previsão do modelo do rótulo que está sendo examinado (rótulo=1). Por outro lado, os valores negativos empurram para a classe oposta (rótulo=0).
- Um indivíduo com um nível alto de glicose (pontos vermelhos) provavelmente será diagnosticado com diabetes (resultado positivo), enquanto um nível baixo de glicose leva a não ser diagnosticado com diabetes.
- Da mesma forma, pacientes idosos têm maior probabilidade de serem diagnosticados com diabetes. No entanto, o modelo parece incerto quanto ao diagnóstico de pacientes mais jovens.
Uma maneira de lidar com essa ambiguidade do atributo Idade é usar o gráfico de dependência para obter mais informações.
Gráfico de dependência
Diferentemente dos gráficos de resumo, os gráficos de dependência mostram a relação entre um recurso específico e o resultado previsto para cada instância dos dados. Essa análise é realizada por vários motivos e não se limita à obtenção de informações mais detalhadas e à validação da importância do recurso que está sendo analisado, confirmando ou contestando os resultados dos gráficos de resumo ou outras medidas globais de importância do recurso.
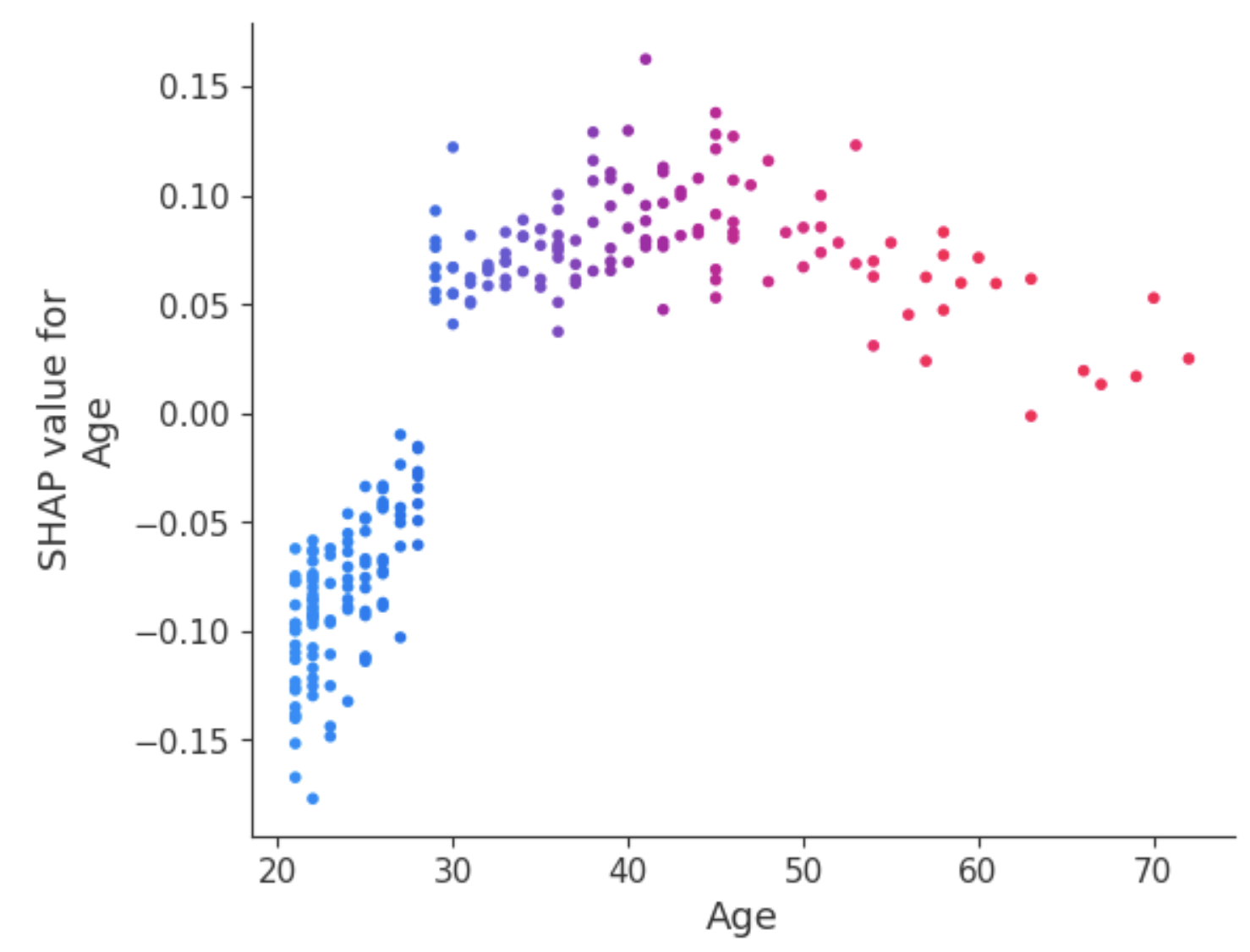
O gráfico de dependência revela que os pacientes com menos de 30 anos têm um risco menor de serem diagnosticados com diabetes. Em contrapartida, indivíduos com mais de 30 anos têm maior probabilidade de receber um diagnóstico de diabetes.
LIME
Local Interpretable Model-agnostic Explanations (LIME, abreviação de Local Interpretable Model-agnostic Explanations). Em vez de fornecer uma compreensão global do modelo em todo o conjunto de dados, o LIME se concentra em explicar a previsão do modelo para instâncias individuais.
O LIME explainer pode ser configurado em duas etapas principais: (1) importar o módulo lime e (2) ajustar o explicador usando os dados de treinamento e os alvos. Durante essa fase, o modo é definido como classificação, o que corresponde à tarefa que está sendo executada.
# Import the LimeTabularExplainer module
from lime.lime_tabular import LimeTabularExplainer
# Get the class names
class_names = ['Has diabetes', 'No diabetes']
# Get the feature names
feature_names = list(X_train.columns)
# Fit the Explainer on the training data set using the LimeTabularExplainer
explainer = LimeTabularExplainer(X_train.values, feature_names =
feature_names,
class_names = class_names,
mode = 'classification')O trecho de código abaixo gera e exibe uma explicação LIME para a 8ª instância nos dados de teste usando o classificador de floresta aleatória e apresentando a contribuição final do recurso em um formato tabular.
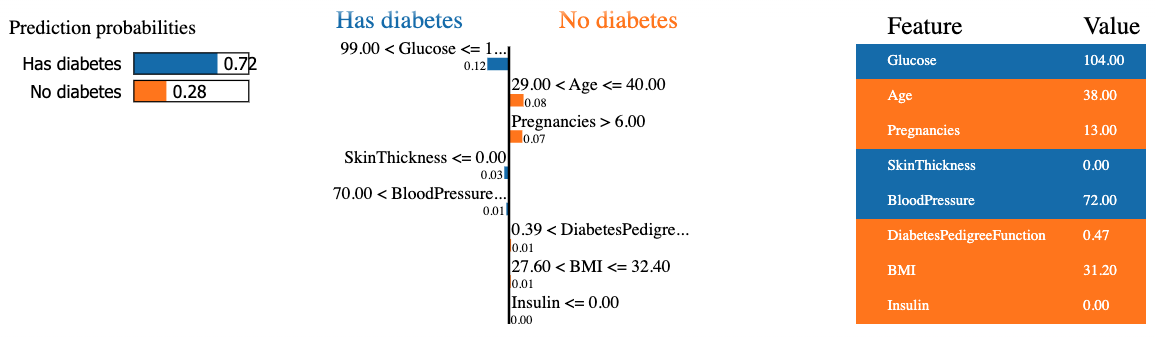
O resultado contém três informações principais, da esquerda para a direita: (1) as previsões do modelo, (2) as contribuições dos recursos e (3) o valor real de cada recurso.
Podemos observar que a previsão é de que o oitavo paciente tenha diabetes com 72% de confiança. Os motivos que levaram o modelo a tomar essa decisão são os seguintes:
- O nível de glicose do paciente é superior a 99.
- A pressão arterial é superior a 70.
Esses valores podem ser verificados na tabela à direita.
Métodos específicos do modelo
Ao contrário dos métodos agnósticos de modelo, esses métodos só podem ser aplicados a uma categoria limitada de modelos. Alguns desses modelos incluem regressão linear, árvores de decisão e interpretabilidade de redes neurais. Diferentes técnicas, como DeepLIFT, Grad-CAM ou Integrated Gradients, podem ser aproveitadas para explicar os modelos de aprendizagem profunda.
Ao usar um modelo de árvore de decisão, uma árvore gráfica pode ser gerada com a função plot_tree do scikit-learn para explicar o processo de tomada de decisão do modelo de cima para baixo, e uma ilustração é dada abaixo.
O artigo Aprendizagem profunda - um tutorial para cientistas de dados responderá às perguntas mais frequentes sobre aprendizagem profunda e explorará vários aspectos da aprendizagem profunda com exemplos reais.
Vamos treinar um classificador de árvore de decisão com hiperparâmetros específicos, como max_depth e min_samples_leaf, antes de gerar a árvore gráfica.
from sklearn.tree import DecisionTreeClassifier, plot_tree
dt_clf = DecisionTreeClassifier(max_depth = 3, min_samples_leaf = 2)
dt_clf.fit(X_train, y_train)
# Predict on the test data and evaluate the model
y_pred = dt_clf.predict(X_test)
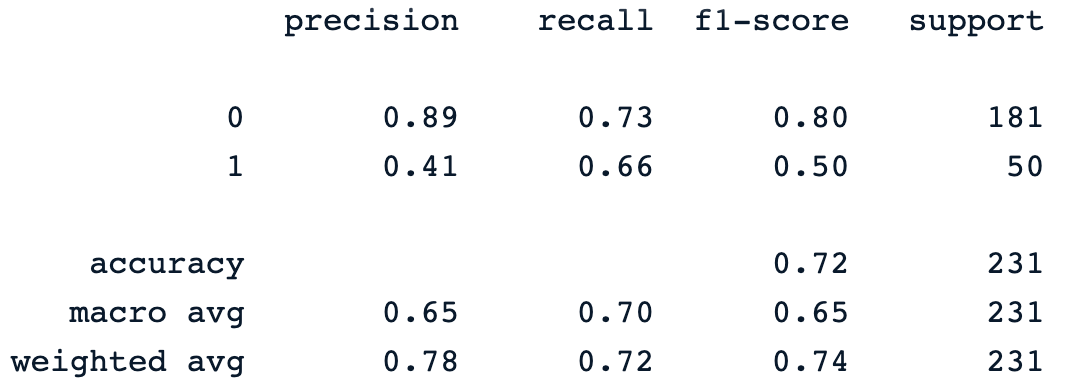
print(classification_report(y_pred, y_test))A instrução de impressão anterior gera o seguinte relatório de classificação do modelo.
E o processo de tomada de decisão do modelo pode ser visualizado no código abaixo:
fig = plt.figure(figsize=(25,20))
_ = plot_tree(dt_clf,
feature_names = feature_names,
class_names = class_names,
filled=True)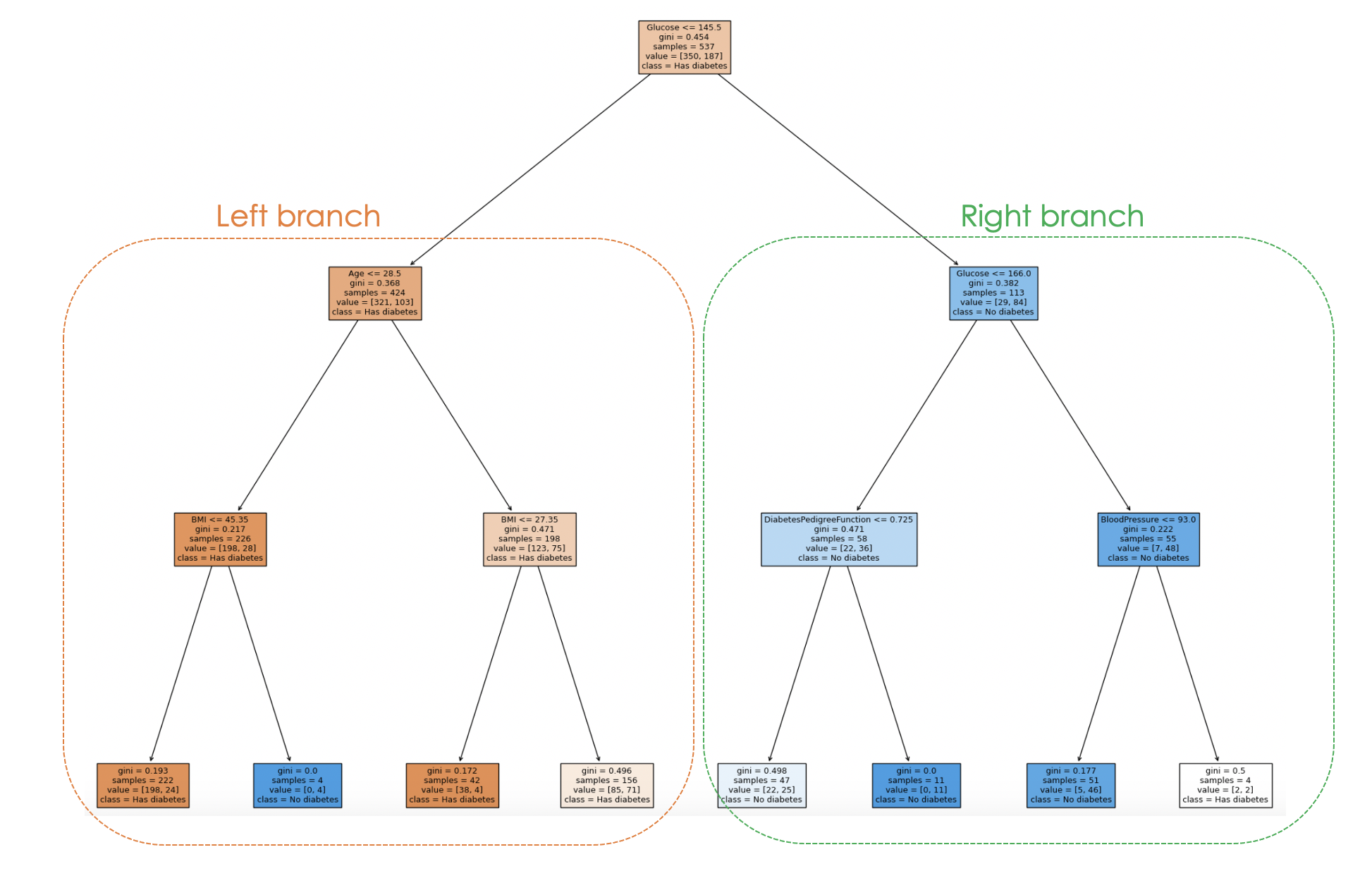
Ao examinar a estrutura da árvore, é possível rastrear o processo de tomada de decisão para cada amostra, fornecendo informações sobre o comportamento e a interpretabilidade do modelo.
No gráfico acima, cada nó representa uma decisão ou divisão com base em um valor de recurso específico. Para cada nó interno, o gráfico mostra o recurso usado para a divisão, o valor do critério de divisão, a impureza de Gini e o número de amostras que chegam a esse nó.
Nos nós das folhas, são exibidos a classe majoritária e o número de amostras. Além disso, as cores nos nós representam a classe majoritária, com a intensidade da cor indicando a proporção da classe dominante dentro desse nó. Por exemplo, os nós laranja no ramo esquerdo correspondem ao rótulo de diabetes, enquanto o azul corresponde a nenhum diabetes.
Desafios da XAI e perspectivas futuras
Como a tecnologia de IA continua avançando e se tornando mais sofisticada, a compreensão e a interpretação dos algoritmos para discernir como eles produzem resultados estão se tornando cada vez mais desafiadoras, permitindo que os pesquisadores continuem explorando novas abordagens e aprimorando as existentes.
Muitos modelos de IA explicáveis exigem a simplificação do modelo subjacente, o que leva a uma perda de desempenho preditivo. Além disso, os métodos atuais de explicabilidade podem não abranger todos os aspectos do processo de tomada de decisão, o que pode limitar o benefício da explicação, especialmente ao lidar com modelos mais complexos.
Novos métodos de pesquisa estão se concentrando em aprimorar as técnicas de IA explicáveis, desenvolvendo algoritmos mais eficazes para tratar de questões éticas e, ao mesmo tempo, criar explicações fáceis de usar.
Por fim, com a pesquisa em andamento, é mais provável que tenhamos métodos mais sofisticados que promovam a transparência, a confiabilidade e a justiça.
Conclusão
Este artigo forneceu uma boa visão geral do que é IA explicável e alguns princípios que contribuem para criar confiança e podem fornecer aos cientistas de dados e a outras partes interessadas conjuntos de habilidades relevantes para criar modelos confiáveis que ajudem a tomar decisões acionáveis.
Também abordamos métodos específicos de modelos e agnósticos de modelos, com foco especial no primeiro, usando LIME e SHAP. Além disso, foram destacados os desafios, as limitações e algumas áreas de pesquisa sobre IA explicável.
Para saber mais sobre a ética por trás dessa tecnologia, confira nosso curso Introdução à ética de dados, que aborda os princípios da ética de dados, sua relação com a ética de IA e suas características nos diferentes estágios do ciclo de vida dos dados.

