
Tracks
Lãnh đạo trong lĩnh vực Trí tuệ Nhân tạo (AI)
6 giờ
AI có thể giải thích đề cập đến tập hợp các quy trình và phương pháp nhằm cung cấp những giải thích rõ ràng, con người có thể hiểu được cho các quyết định do các mô hình AI và học máy tạo ra.
Bằng cách tích hợp một lớp giải thích vào các mô hình này, các Nhà khoa học Dữ liệu và người làm Học máy có thể tạo ra những hệ thống đáng tin cậy và minh bạch hơn để hỗ trợ nhiều bên liên quan như nhà phát triển, cơ quan quản lý và người dùng cuối.
Dưới đây là một số nguyên tắc của XAI có thể góp phần xây dựng niềm tin:
Có nhiều lợi ích khi triển khai XAI. Đối với nhà ra quyết định và các bên liên quan khác, XAI mang lại hiểu biết rõ ràng về lý do đằng sau các quyết định do AI dẫn dắt, giúp họ đưa ra lựa chọn sáng suốt hơn. Nó cũng giúp xác định các thiên lệch hoặc sai sót tiềm ẩn trong mô hình, dẫn đến kết quả chính xác và công bằng hơn.
Có hai nhóm phương pháp diễn giải mô hình: phương pháp đặc thù mô hình và phương pháp độc lập mô hình. Trong phần này, chúng ta sẽ hiểu sự khác biệt giữa hai nhóm, với trọng tâm vào các phương pháp độc lập mô hình.
Cả hai kỹ thuật đều có thể mang lại những hiểu biết giá trị về cách thức hoạt động bên trong của các mô hình học máy đồng thời đảm bảo mô hình hiệu quả và có trách nhiệm.
Để minh họa rõ hơn các công cụ này, chúng ta sẽ sử dụng bộ dữ liệu tiểu đường từ Kaggle. Trước tiên, chúng ta sẽ xây dựng một bộ phân loại đơn giản rồi triển khai phần diễn giải. Toàn bộ mã nguồn có trong DataLab workbook này.
Một bộ phân loại Rừng ngẫu nhiên được xây dựng để dự đoán kết cục tiểu đường bằng bộ dữ liệu này. Mã được chia thành các bước: (1) nhập các thư viện liên quan, (2) tạo tập huấn luyện và kiểm tra, (3) xây dựng mô hình, và (4) báo cáo chỉ số hiệu năng qua classification report.
# Load useful libraries
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
# Separate Features and Target Variables
X = diabetes_data.drop(columns='Outcome')
y = diabetes_data['Outcome']
# Create Train & Test Data
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3,
stratify =y,
random_state = 13)
# Build the model
rf_clf = RandomForestClassifier(max_features=2, n_estimators =100 ,bootstrap = True)
rf_clf.fit(X_train, y_train)
# Make prediction on the testing data
y_pred = rf_clf.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))Lệnh in cuối tạo ra báo cáo sau:
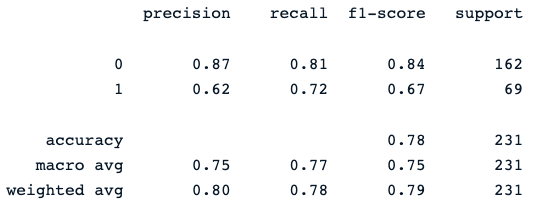
Bộ phân loại rừng ngẫu nhiên cho hiệu năng khá trong việc dự đoán kết cục tiểu đường, với dư địa rõ ràng để cải thiện bằng các mô hình khác.
Giờ đây, chúng ta có thể tích hợp lớp giải thích vào mô hình này để cung cấp nhiều thông tin chi tiết hơn về dự đoán của nó. Phần tiếp theo sẽ tập trung vào hai nhóm phương pháp diễn giải mô hình: phương pháp đặc thù mô hình và phương pháp độc lập mô hình.
Bài viết Phân loại trong Học máy: Phần giới thiệu sẽ giúp bạn tìm hiểu về phân loại trong học máy, bao gồm khái niệm, cách ứng dụng và một số thuật toán ví dụ.
Các phương pháp này có thể áp dụng cho bất kỳ mô hình học máy nào, bất kể cấu trúc hay loại mô hình. Chúng tập trung phân tích cặp đầu vào-đầu ra của đặc trưng. Phần này sẽ giới thiệu và thảo luận về LIME và SHAP, hai mô hình thay thế được dùng rộng rãi.
SHAP là viết tắt của SHapley Additive exPlanations. Phương pháp này nhằm giải thích dự đoán của từng điểm dữ liệu bằng cách tính đóng góp của từng đặc trưng vào dự đoán, và có thể cài đặt bằng lệnh pip sau.
!pip install shapSau khi cài đặt:
import shap
import matplotlib.pyplot as plt
# load JS visualization code to notebook
shap.initjs()
# Create the explainer
explainer = shap.TreeExplainer(rf_clf)
shap_values = explainer.shap_values(X_test)SHAP cung cấp nhiều công cụ trực quan để tăng khả năng diễn giải mô hình, và phần tiếp theo sẽ thảo luận hai trong số đó: (1) tầm quan trọng biến với summary plot, (2) summary plot cho một nhãn cụ thể, và (3) dependence plot.
Trong biểu đồ này, các đặc trưng được xếp hạng theo giá trị SHAP trung bình, hiển thị các đặc trưng quan trọng nhất ở trên cùng và ít quan trọng nhất ở dưới cùng bằng hàm summary_plot(). Điều này giúp hiểu tác động của từng đặc trưng lên dự đoán của mô hình.
print("Variable Importance Plot - Global Interpretation")
figure = plt.figure()
shap.summary_plot(shap_values, X_test)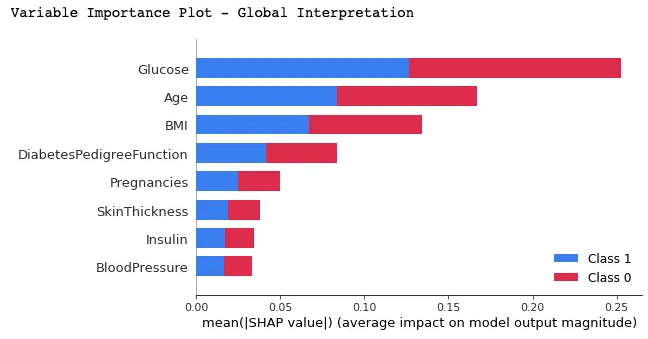
Diễn giải có thể rút ra từ đồ thị trên:
Cách tiếp cận này mang lại cái nhìn chi tiết hơn về tác động của từng đặc trưng lên một kết quả (nhãn) cụ thể.
Trong ví dụ dưới đây, shap_values[1] được dùng để biểu diễn giá trị SHAP cho các điểm được phân loại là nhãn 1 (mắc tiểu đường).
shap.summary_plot(shap_values[1], X_test)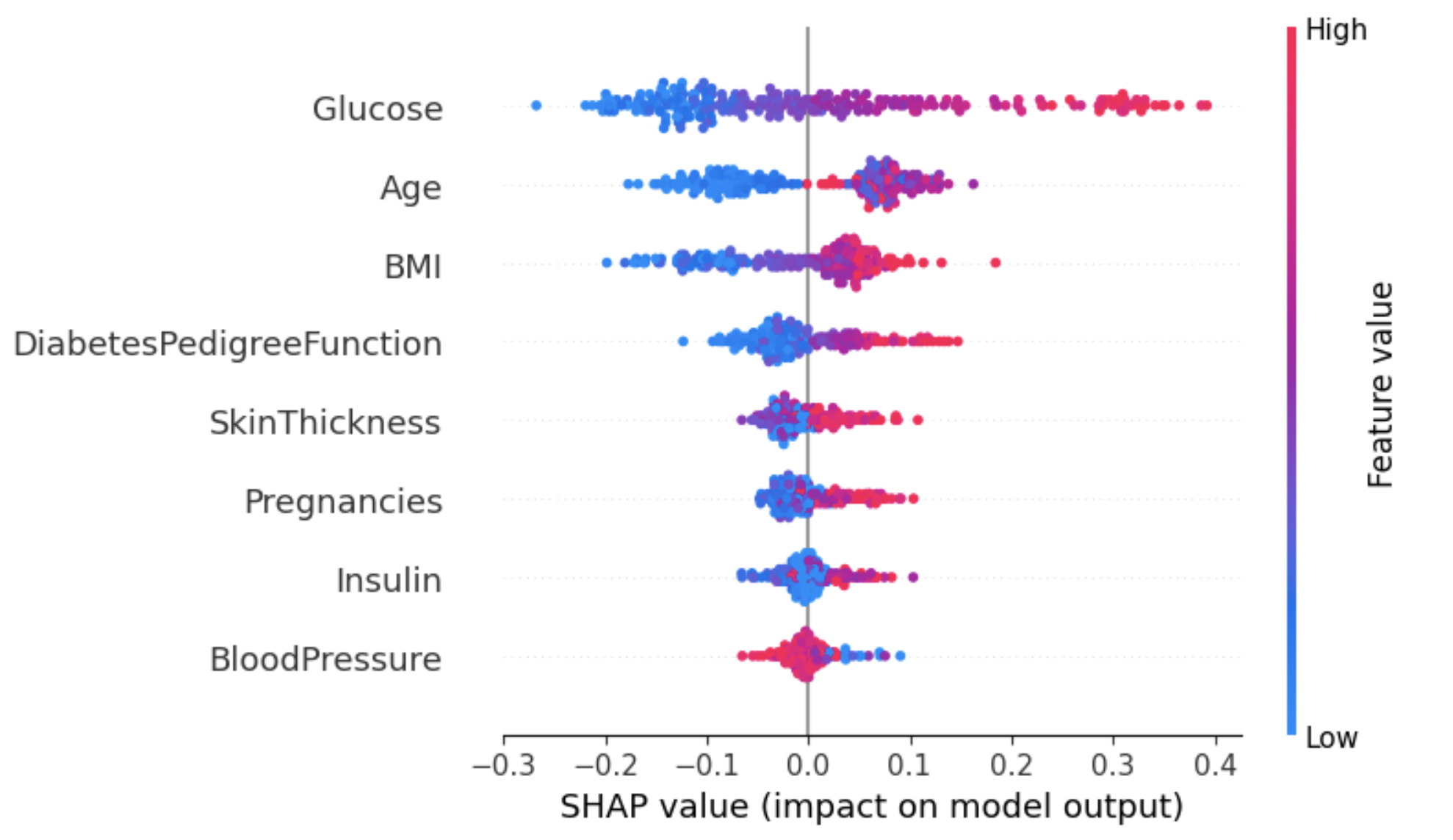
Từ đồ thị trên:
Một cách xử lý sự mơ hồ này đối với thuộc tính Age là dùng dependence plot để có thêm thông tin.
Khác với summary plot, dependence plot cho thấy mối quan hệ giữa một đặc trưng cụ thể và kết quả dự đoán cho mỗi điểm dữ liệu. Phân tích này được thực hiện vì nhiều lý do, không chỉ để có thông tin chi tiết hơn mà còn để xác thực tầm quan trọng của đặc trưng đang phân tích bằng cách khẳng định hoặc thách thức các phát hiện từ summary plot hay các thước đo tầm quan trọng toàn cục khác.
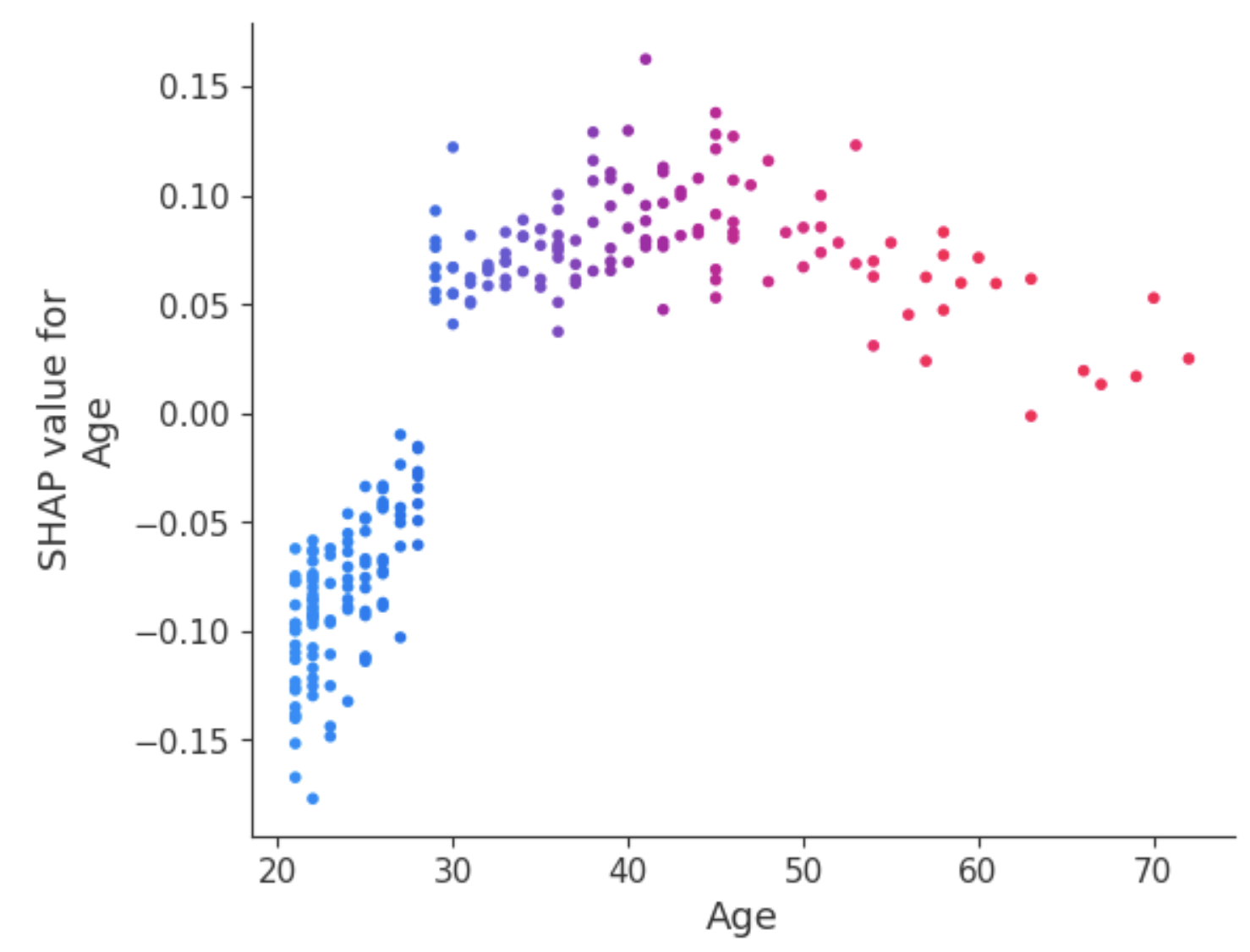
Dependence plot cho thấy bệnh nhân dưới 30 tuổi có nguy cơ bị chẩn đoán mắc tiểu đường thấp hơn. Ngược lại, những người trên 30 tuổi có khả năng nhận chẩn đoán tiểu đường cao hơn.
Local Interpretable Model-agnostic Explanations (viết tắt LIME). Thay vì cung cấp hiểu biết toàn cục về mô hình trên toàn bộ dữ liệu, LIME tập trung giải thích dự đoán của mô hình cho từng điểm riêng lẻ.
Trình giải thích LIME có thể được thiết lập với hai bước chính: (1) nhập mô-đun lime, và (2) fit explainer bằng dữ liệu huấn luyện và nhãn mục tiêu. Trong giai đoạn này, chế độ được đặt là classification, tương ứng với tác vụ đang thực hiện.
# Import the LimeTabularExplainer module
from lime.lime_tabular import LimeTabularExplainer
# Get the class names
class_names = ['Has diabetes', 'No diabetes']
# Get the feature names
feature_names = list(X_train.columns)
# Fit the Explainer on the training data set using the LimeTabularExplainer
explainer = LimeTabularExplainer(X_train.values, feature_names =
feature_names,
class_names = class_names,
mode = 'classification')Đoạn mã dưới đây tạo và hiển thị lời giải thích LIME cho điểm dữ liệu thứ 8 trong tập kiểm tra bằng bộ phân loại rừng ngẫu nhiên, trình bày đóng góp cuối cùng của đặc trưng ở dạng bảng.
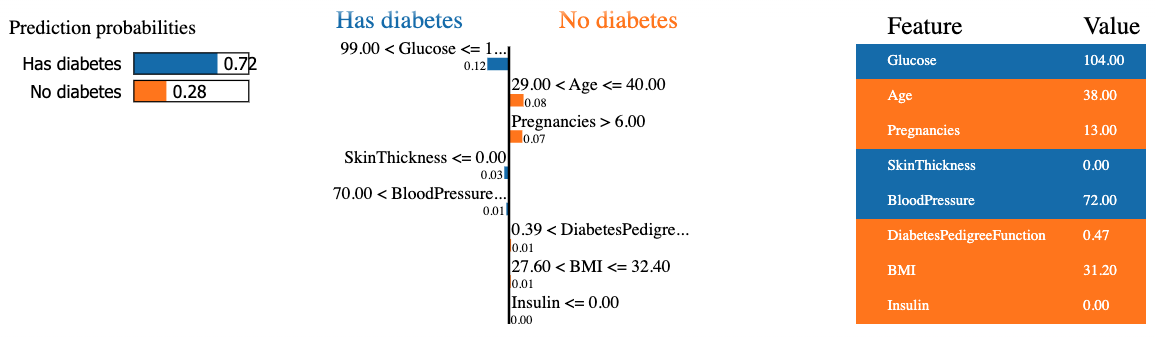
Kết quả gồm ba phần thông tin chính từ trái sang phải: (1) dự đoán của mô hình, (2) đóng góp của các đặc trưng, và (3) giá trị thực tế của từng đặc trưng.
Ta thấy bệnh nhân thứ tám được dự đoán mắc tiểu đường với độ tin cậy 72%. Các lý do dẫn mô hình đến quyết định này là:
Những giá trị này có thể được kiểm chứng từ bảng bên phải.
Trái với phương pháp độc lập mô hình, các phương pháp này chỉ có thể áp dụng cho một nhóm mô hình giới hạn. Một số mô hình đó gồm hồi quy tuyến tính, cây quyết định và khả năng diễn giải mạng nơ-ron. Các kỹ thuật khác nhau như DeepLIFT, Grad-CAM hoặc Integrated Gradients có thể được tận dụng để giải thích các mô hình học sâu.
Khi dùng mô hình cây quyết định, có thể tạo đồ thị cây với hàm plot_tree từ scikit-learn để giải thích quy trình ra quyết định của mô hình từ trên xuống dưới, như minh họa dưới đây.
Bài viết Deep Learning - Hướng dẫn cho Nhà khoa học Dữ liệu sẽ trả lời những câu hỏi thường gặp nhất về học sâu và khám phá các khía cạnh khác nhau của học sâu với ví dụ thực tế.
Hãy huấn luyện một bộ phân loại cây quyết định với các siêu tham số cụ thể như max_depth và min_samples_leaf trước khi tạo đồ thị cây.
from sklearn.tree import DecisionTreeClassifier, plot_tree
dt_clf = DecisionTreeClassifier(max_depth = 3, min_samples_leaf = 2)
dt_clf.fit(X_train, y_train)
# Predict on the test data and evaluate the model
y_pred = dt_clf.predict(X_test)
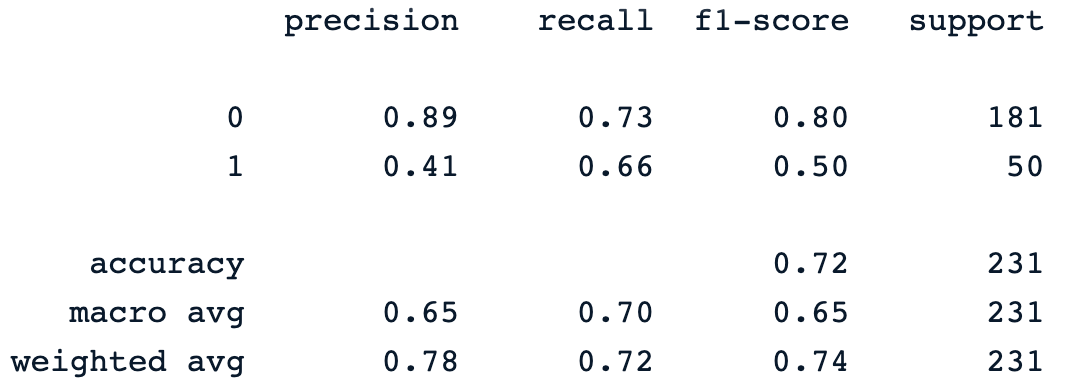
print(classification_report(y_pred, y_test))Lệnh in trước đó tạo ra báo cáo phân loại của mô hình như sau.
Và quy trình ra quyết định của mô hình có thể được trực quan hóa từ đoạn mã dưới đây:
fig = plt.figure(figsize=(25,20))
_ = plot_tree(dt_clf,
feature_names = feature_names,
class_names = class_names,
filled=True)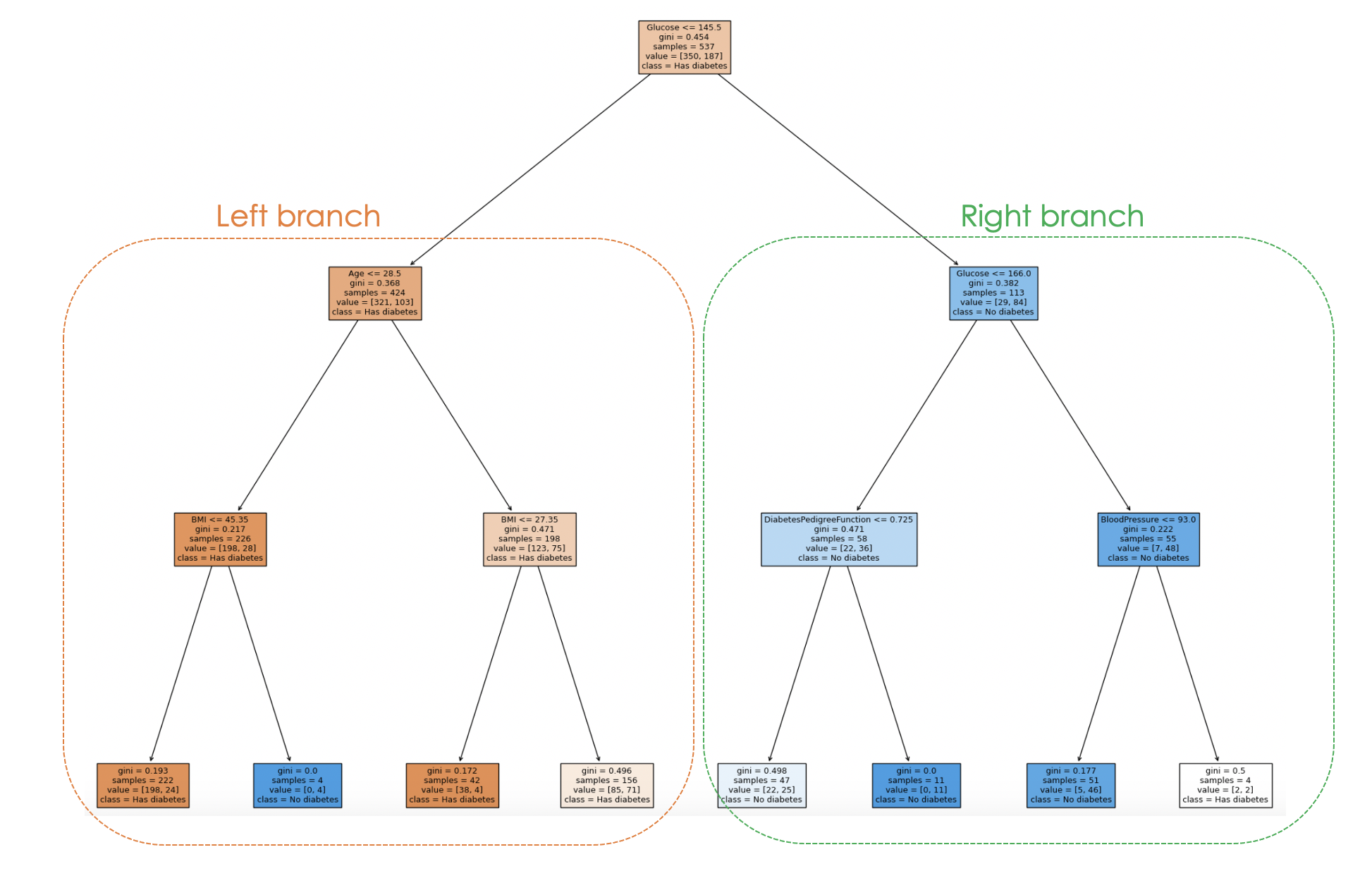
Bằng cách quan sát cấu trúc cây, ta có thể lần theo quy trình ra quyết định cho từng mẫu, cung cấp hiểu biết về hành vi và khả năng diễn giải của mô hình.
Trong biểu đồ trên, mỗi nút biểu thị một quyết định hoặc phép chia dựa trên giá trị đặc trưng cụ thể. Với mỗi nút nội bộ, biểu đồ hiển thị đặc trưng dùng để chia, ngưỡng chia, độ thuần Gini, và số lượng mẫu đi đến nút đó.
Ở các nút lá, lớp chiếm đa số và số mẫu được hiển thị. Ngoài ra, màu sắc ở các nút biểu diễn lớp chiếm đa số, với cường độ màu cho biết tỷ lệ của lớp trội trong nút đó. Ví dụ, các nút màu cam ở nhánh trái tương ứng nhãn tiểu đường, còn nút màu xanh tương ứng không mắc tiểu đường.
Khi công nghệ AI tiếp tục tiến bộ và trở nên tinh vi hơn, việc hiểu và diễn giải các thuật toán để biết chúng tạo ra kết quả như thế nào ngày càng khó khăn, thúc đẩy các nhà nghiên cứu tiếp tục khám phá phương pháp mới và cải thiện những phương pháp hiện có.
Nhiều mô hình XAI đòi hỏi đơn giản hóa mô hình nền tảng, dẫn đến mất mát hiệu năng dự đoán. Bên cạnh đó, các phương pháp giải thích hiện tại có thể không bao quát mọi khía cạnh của quy trình ra quyết định, hạn chế lợi ích của lời giải thích, đặc biệt khi làm việc với các mô hình phức tạp hơn.
Các phương pháp nghiên cứu mới tập trung nâng cao các kỹ thuật XAI bằng cách phát triển thuật toán hiệu quả hơn để giải quyết vấn đề đạo đức đồng thời tạo ra lời giải thích thân thiện với người dùng.
Cuối cùng, với nghiên cứu đang diễn ra, nhiều khả năng chúng ta sẽ có các phương pháp tinh vi hơn nhằm thúc đẩy minh bạch, độ tin cậy và công bằng.
Bài viết này đã cung cấp cái nhìn tổng quan tốt về XAI là gì và một số nguyên tắc góp phần xây dựng niềm tin, có thể trang bị cho Nhà khoa học Dữ liệu và các bên liên quan khác những kỹ năng phù hợp để xây dựng các mô hình đáng tin cậy giúp đưa ra quyết định có thể hành động.
Chúng tôi cũng đã đề cập đến phương pháp độc lập mô hình và đặc thù mô hình, với trọng tâm vào phương pháp đầu tiên thông qua LIME và SHAP. Ngoài ra, các thách thức, hạn chế và một số hướng nghiên cứu về XAI cũng đã được nêu bật.
Để tìm hiểu thêm về khía cạnh đạo đức phía sau công nghệ này, hãy xem khóa học Introduction to Data Ethics của chúng tôi, bao gồm các nguyên tắc đạo đức dữ liệu, mối liên hệ với đạo đức AI và các đặc điểm của nó xuyên suốt các giai đoạn khác nhau của vòng đời dữ liệu.
Tìm hiểu thêm về AI!
Tracks
Courses
Courses
blogs
Matt Crabtree
10 phút