
Lernpfad
Künstliche Intelligenz (KI) Leadership
6 Std.
Erklärbare KI bezieht sich auf eine Reihe von Prozessen und Methoden, die darauf abzielen, die von KI und maschinellen Lernmodellen generierten Entscheidungen klar und für den Menschen verständlich zu erklären.
Durch die Integration einer Erklärungsebene in diese Modelle können Datenwissenschaftler und Praktiker des maschinellen Lernens vertrauenswürdigere und transparentere Systeme schaffen, die einer Vielzahl von Interessengruppen wie Entwicklern, Regulierungsbehörden und Endnutzern helfen.
Hier sind einige erklärbare KI-Prinzipien, die zur Vertrauensbildung beitragen können:
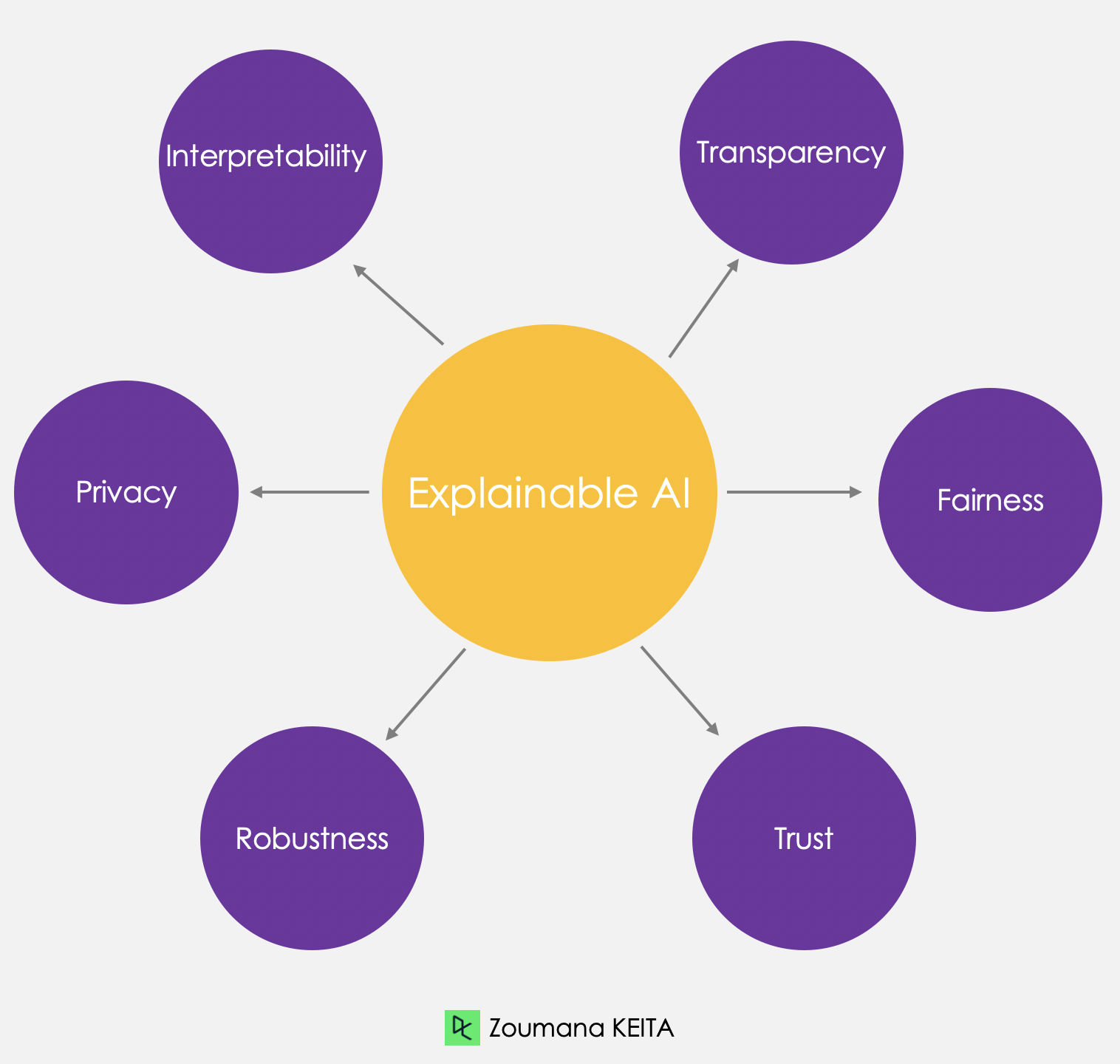
Die Einführung von erklärbarer KI hat mehrere Vorteile. Entscheidungsträgern und anderen Stakeholdern bietet es ein klares Verständnis der Gründe für KI-gesteuerte Entscheidungen, damit sie besser informierte Entscheidungen treffen können. Es hilft auch, mögliche Verzerrungen oder Fehler in den Modellen zu erkennen, was zu genaueren und gerechteren Ergebnissen führt.
Es gibt zwei große Kategorien der Modellerklärbarkeit: modellspezifische Methoden und modellagnostische Methoden. In diesem Abschnitt werden wir den Unterschied zwischen beiden verstehen, wobei wir uns besonders auf die modellagnostischen Methoden konzentrieren.
Beide Techniken können wertvolle Einblicke in das Innenleben von maschinellen Lernmodellen bieten und gleichzeitig sicherstellen, dass die Modelle effektiv und verantwortungsbewusst sind.
Um diese Tools besser zu veranschaulichen, werden wir den Diabetes-Datensatz von Kaggle verwenden. Zuerst werden wir einen einfachen Klassifikator bauen und dann die Erklärbarkeit implementieren. Der vollständige Quellcode ist in dieser DataLab-Arbeitsmappe verfügbar.
Ein Random-Forest-Klassifikator wird erstellt, um mit Hilfe des Diabetes-Datensatzes Diabetes-Ergebnisse vorherzusagen. Der Code ist in mehrere Schritte unterteilt: (1) Importieren relevanter Bibliotheken, (2) Erstellen von Trainings- und Testdatensätzen, (3) Erstellen des Modells und (4) Berichten der Leistungskennzahlen über den Klassifizierungsbericht.
# Load useful libraries
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
# Separate Features and Target Variables
X = diabetes_data.drop(columns='Outcome')
y = diabetes_data['Outcome']
# Create Train & Test Data
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3,
stratify =y,
random_state = 13)
# Build the model
rf_clf = RandomForestClassifier(max_features=2, n_estimators =100 ,bootstrap = True)
rf_clf.fit(X_train, y_train)
# Make prediction on the testing data
y_pred = rf_clf.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))Die letzte Druckanweisung erzeugt den folgenden Bericht:
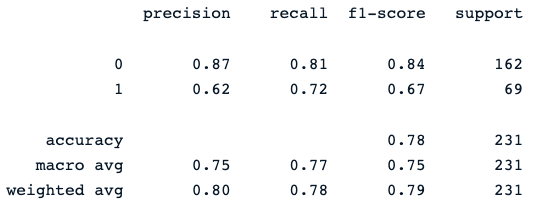
Der Random-Forest-Klassifikator liefert eine ordentliche Leistung bei der Vorhersage von Diabetes-Ergebnissen, wobei offensichtlich Raum für Verbesserungen mit anderen Modellen besteht.
Jetzt können wir die Erklärbarkeitsebene in dieses Modell integrieren, um mehr Einblicke in seine Vorhersagen zu erhalten. Im nächsten Abschnitt geht es um die zwei großen Kategorien der Modellerklärbarkeit: modellspezifische Methoden und modellagnostische Methoden.
Unsere Klassifizierung beim maschinellen Lernen: Eine Einführung Artikel hilft dir dabei, etwas über die Klassifizierung beim maschinellen Lernen zu lernen, indem er erklärt, was sie ist, wie sie verwendet wird und einige Beispiele für Klassifizierungsalgorithmen zeigt.
Diese Methoden können auf jedes maschinelle Lernmodell angewendet werden, unabhängig von dessen Struktur oder Typ. Sie konzentrieren sich auf die Analyse des Input-Output-Paares der Merkmale. In diesem Abschnitt werden LIME und SHAP, zwei weit verbreitete Surrogatmodelle, vorgestellt und diskutiert.
Es steht für SHapley AdditiveexPlanations. Diese Methode zielt darauf ab, die Vorhersage einer Instanz/Beobachtung zu erklären, indem sie den Beitrag jedes Merkmals zur Vorhersage berechnet, und sie kann mit dem folgenden pip-Befehl installiert werden.
!pip install shapNach der Installation:
import shap
import matplotlib.pyplot as plt
# load JS visualization code to notebook
shap.initjs()
# Create the explainer
explainer = shap.TreeExplainer(rf_clf)
shap_values = explainer.shap_values(X_test)SHAP bietet eine Reihe von Visualisierungswerkzeugen, um die Interpretierbarkeit von Modellen zu verbessern. Zwei davon werden im nächsten Abschnitt besprochen: (1) Variablenbedeutung mit dem Summary Plot, (2) Summary Plot eines bestimmten Ziels und (3) Dependency Plot.
In dieser Darstellung werden die Merkmale nach ihren durchschnittlichen SHAP-Werten geordnet, wobei die wichtigsten Merkmale ganz oben und die unwichtigsten ganz unten stehen. Das hilft dabei, die Auswirkungen der einzelnen Merkmale auf die Vorhersagen des Modells zu verstehen.
print("Variable Importance Plot - Global Interpretation")
figure = plt.figure()
shap.summary_plot(shap_values, X_test)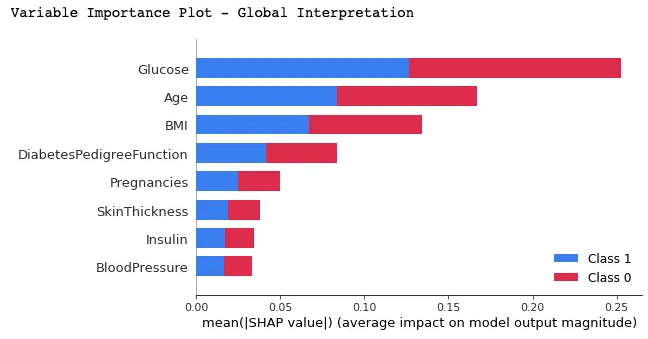
Im Folgenden findest du die Interpretation, die du aus der obigen Grafik ziehen kannst:
Dieser Ansatz kann einen detaillierteren Überblick über die Auswirkungen der einzelnen Merkmale auf ein bestimmtes Ergebnis (Label) geben.
Im folgenden Beispiel wird shap_values[1] verwendet, um die SHAP-Werte für Instanzen mit dem Label 1 (Diabetes) darzustellen.
shap.summary_plot(shap_values[1], X_test)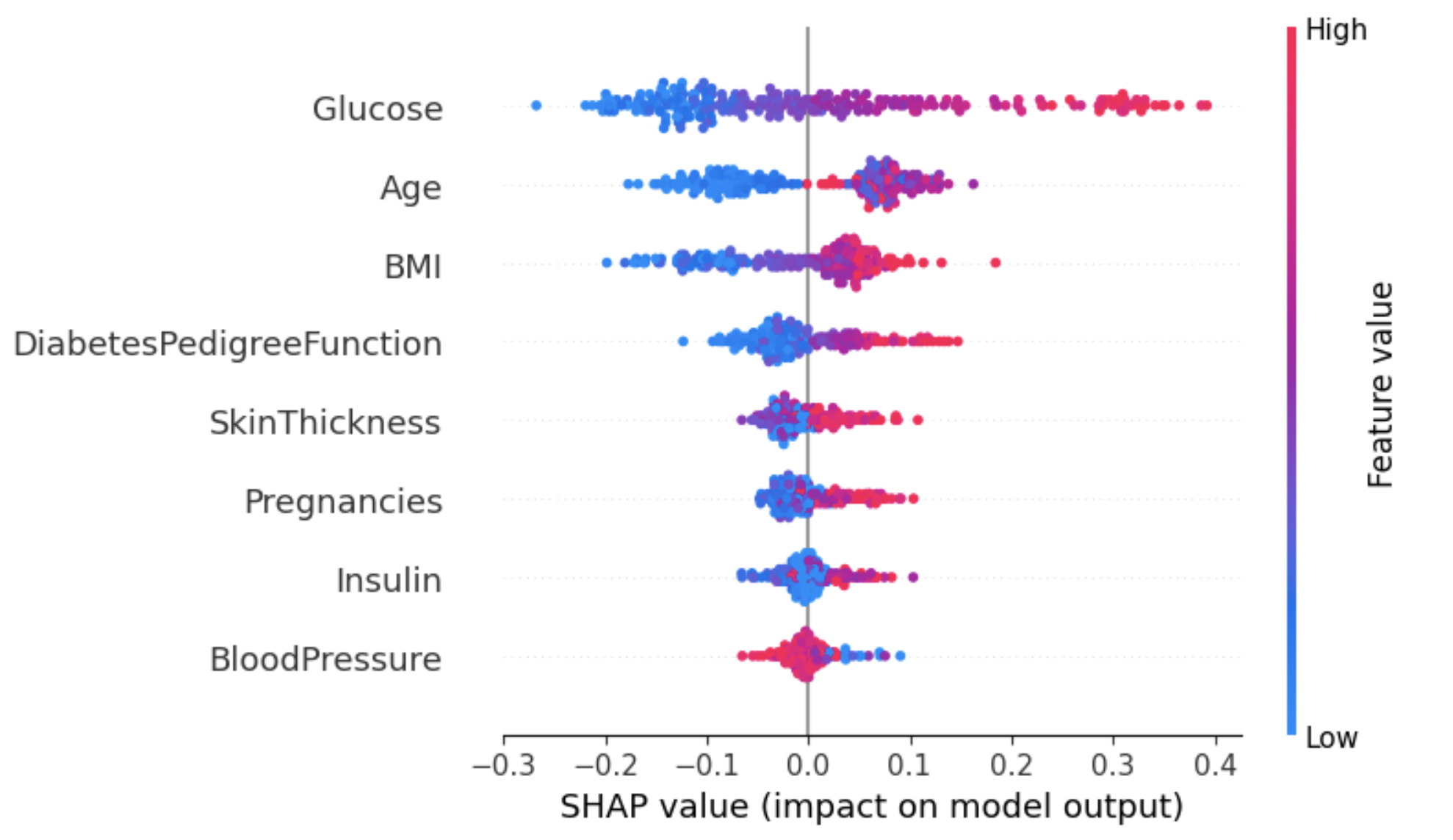
Aus der obigen Grafik:
Eine Möglichkeit, mit dieser Mehrdeutigkeit für das Attribut Alter umzugehen, ist die Verwendung des Abhängigkeitsdiagramms, um mehr Erkenntnisse zu gewinnen.
Im Gegensatz zu zusammenfassenden Diagrammen zeigen Abhängigkeitsdiagramme die Beziehung zwischen einem bestimmten Merkmal und dem vorhergesagten Ergebnis für jede Instanz innerhalb der Daten. Diese Analyse wird aus verschiedenen Gründen durchgeführt und ist nicht darauf beschränkt, detailliertere Informationen zu erhalten und die Bedeutung des analysierten Merkmals zu validieren, indem die Ergebnisse der zusammenfassenden Diagramme oder anderer globaler Merkmalsbedeutungsmaße bestätigt oder in Frage gestellt werden.
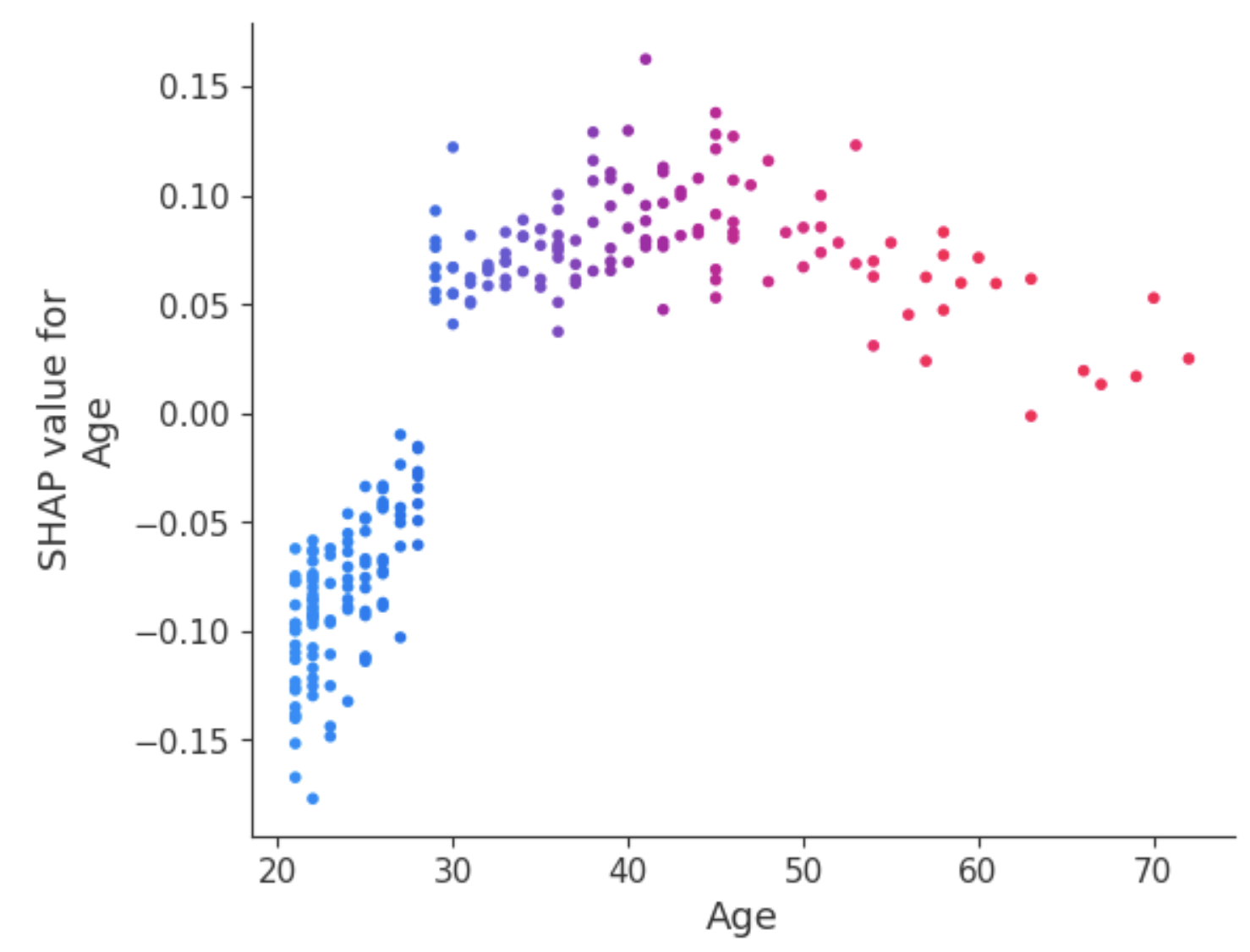
Das Abhängigkeitsdiagramm zeigt, dass Patienten unter 30 Jahren ein geringeres Risiko haben, an Diabetes zu erkranken. Im Gegensatz dazu ist die Wahrscheinlichkeit, eine Diabetesdiagnose zu erhalten, bei Personen über 30 höher.
Lokale interpretierbare modellagnostische Erklärungen (kurz: LIME). Anstatt ein globales Verständnis des Modells für den gesamten Datensatz zu liefern, konzentriert sich LIME darauf, die Vorhersage des Modells für einzelne Instanzen zu erklären.
LIME explainer kann in zwei Hauptschritten eingerichtet werden: (1) importiere das Kalk-Modul und (2) passe den Erklärer mit den Trainingsdaten und den Zielen an. In dieser Phase wird der Modus auf Klassifizierung eingestellt, was der durchgeführten Aufgabe entspricht.
# Import the LimeTabularExplainer module
from lime.lime_tabular import LimeTabularExplainer
# Get the class names
class_names = ['Has diabetes', 'No diabetes']
# Get the feature names
feature_names = list(X_train.columns)
# Fit the Explainer on the training data set using the LimeTabularExplainer
explainer = LimeTabularExplainer(X_train.values, feature_names =
feature_names,
class_names = class_names,
mode = 'classification')Das folgende Codeschnipsel generiert eine LIME-Erklärung für die 8. Instanz in den Testdaten und zeigt sie an, indem es den Random-Forest-Klassifikator verwendet und den endgültigen Beitrag der Merkmale in Tabellenform darstellt.
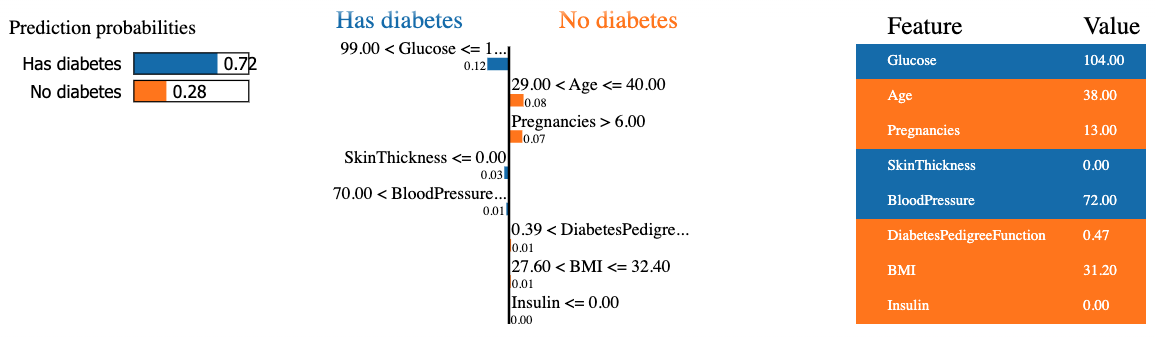
Das Ergebnis enthält drei Hauptinformationen von links nach rechts: (1) die Vorhersagen des Modells, (2) die Beiträge der Merkmale und (3) den tatsächlichen Wert für jedes Merkmal.
Wir können feststellen, dass der achte Patient mit einer Wahrscheinlichkeit von 72 % Diabetes hat. Die Gründe, die das Modell zu dieser Entscheidung veranlasst haben, sind:
Diese Werte können in der Tabelle rechts überprüft werden.
Im Gegensatz zu modellagnostischen Methoden können diese Methoden nur auf eine begrenzte Kategorie von Modellen angewendet werden. Zu diesen Modellen gehören lineare Regression, Entscheidungsbäume und die Interpretierbarkeit neuronaler Netze. Verschiedene Techniken wie DeepLIFT, Grad-CAM oder Integrated Gradients können genutzt werden, um Deep-Learning-Modelle zu erklären.
Wenn du ein Entscheidungsbaummodell verwendest, kannst du mit der Funktion plot_tree von scikit-learn einen grafischen Baum erstellen, um den Entscheidungsprozess des Modells von oben nach unten zu erklären (siehe unten).
Der Artikel Deep Learning - A Tutorial for Data Scientists beantwortet die am häufigsten gestellten Fragen zum Thema Deep Learning und beleuchtet verschiedene Aspekte des Deep Learning anhand von Beispielen aus der Praxis.
Wir trainieren einen Entscheidungsbaum-Klassifikator mit bestimmten Hyperparametern wie max_depth und min_samples_leaf, bevor wir den grafischen Baum erstellen.
from sklearn.tree import DecisionTreeClassifier, plot_tree
dt_clf = DecisionTreeClassifier(max_depth = 3, min_samples_leaf = 2)
dt_clf.fit(X_train, y_train)
# Predict on the test data and evaluate the model
y_pred = dt_clf.predict(X_test)
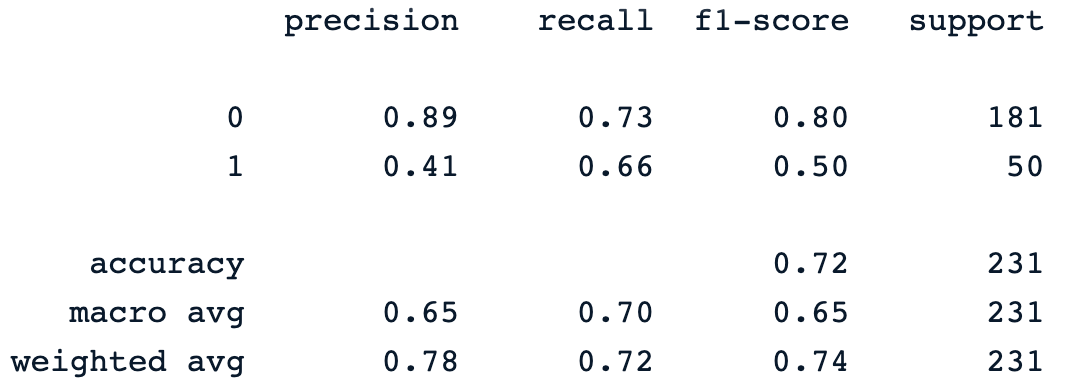
print(classification_report(y_pred, y_test))Die vorherige Druckanweisung erzeugt den folgenden Klassifizierungsbericht des Modells.
Der Entscheidungsfindungsprozess des Modells kann anhand des folgenden Codes veranschaulicht werden:
fig = plt.figure(figsize=(25,20))
_ = plot_tree(dt_clf,
feature_names = feature_names,
class_names = class_names,
filled=True)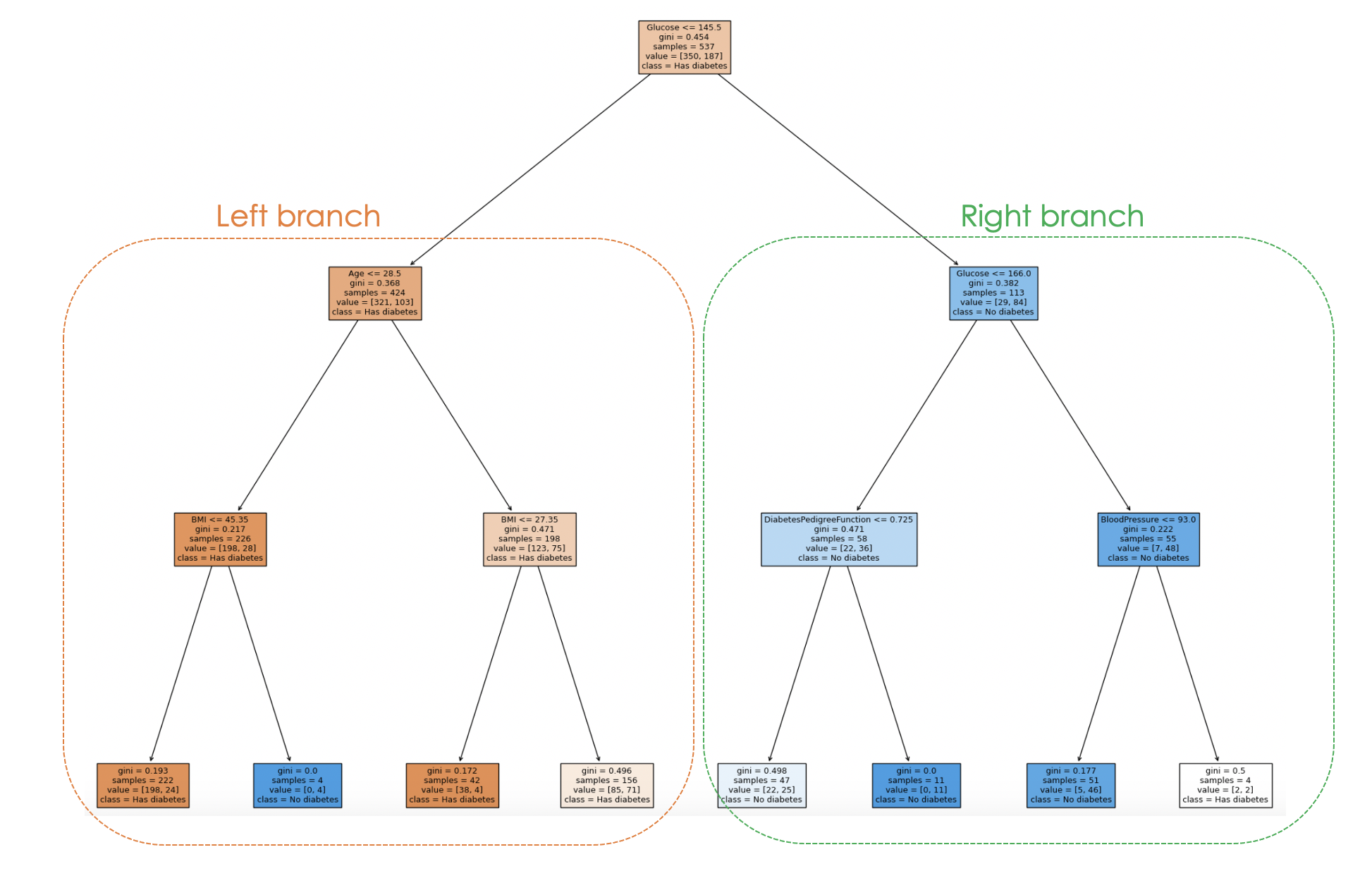
Durch die Untersuchung der Baumstruktur kann man den Entscheidungsprozess für jede Probe nachvollziehen und erhält so Einblicke in das Verhalten und die Interpretierbarkeit des Modells.
In der obigen Grafik stellt jeder Knoten eine Entscheidung oder Aufteilung auf der Grundlage eines bestimmten Merkmalswertes dar. Für jeden internen Knotenpunkt zeigt die Grafik das für die Aufteilung verwendete Merkmal, den Wert des Aufteilungskriteriums, die Gini-Verunreinigung und die Anzahl der Proben, die diesen Knotenpunkt erreichen.
In den Blattknoten werden die Mehrheitsklasse und die Anzahl der Proben angezeigt. Außerdem stellen die Farben in den Knoten die Mehrheitsklasse dar, wobei die Intensität der Farbe den Anteil der dominanten Klasse in diesem Knoten angibt. Zum Beispiel entsprechen die orangefarbenen Knoten auf dem linken Zweig dem Diabetes-Label, während die blauen Knoten keinem Diabetes entsprechen.
Da die KI-Technologie immer weiter fortschreitet und immer ausgefeilter wird, wird es immer schwieriger, die Algorithmen zu verstehen und zu interpretieren, um herauszufinden, wie sie zu Ergebnissen führen, was es den Forschern ermöglicht, weiterhin neue Ansätze zu erforschen und bestehende zu verbessern.
Viele erklärbare KI-Modelle erfordern eine Vereinfachung des zugrunde liegenden Modells, was zu einem Verlust an Vorhersagekraft führt. Außerdem decken aktuelle Erklärungsmethoden möglicherweise nicht alle Aspekte des Entscheidungsprozesses ab, was den Nutzen der Erklärung einschränken kann, vor allem wenn es um komplexere Modelle geht.
Neue Forschungsmethoden konzentrieren sich auf die Verbesserung erklärungsbedürftiger KI-Techniken durch die Entwicklung effektiverer Algorithmen, die ethische Fragen behandeln und gleichzeitig benutzerfreundliche Erklärungen erstellen.
Und schließlich werden wir mit der laufenden Forschung wahrscheinlich immer ausgefeiltere Methoden haben, die Transparenz, Vertrauenswürdigkeit und Fairness fördern.
Dieser Artikel hat einen guten Überblick darüber gegeben, was erklärbare KI ist und welche Prinzipien zum Aufbau von Vertrauen beitragen und Data Scientists und anderen Akteuren relevante Fähigkeiten vermitteln können, um vertrauenswürdige Modelle zu erstellen, die dabei helfen, umsetzbare Entscheidungen zu treffen.
Wir haben auch modellagnostische und modellspezifische Methoden behandelt, wobei der Schwerpunkt auf der ersten Methode mit LIME und SHAP lag. Außerdem wurden die Herausforderungen, Grenzen und einige Forschungsbereiche der erklärbaren KI aufgezeigt.
Wenn du mehr über die ethischen Aspekte solcher Technologien erfahren möchtest, besuche unseren Kurs "Einführung in die Datenethik ", in dem die Grundsätze der Datenethik, ihre Beziehung zur KI-Ethik und ihre Merkmale in den verschiedenen Phasen des Datenlebenszyklus behandelt werden.
Erfahre mehr über AI!
Lernpfad
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Zoumana Keita
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Derrick Mwiti
Tutorial
Matt Crabtree
