
Program
Yapay Zeka (AI) Liderliği
6 sa
Açıklanabilir yapay zekâ, yapay zekâ ve makine öğrenimi modellerinin ürettiği kararlar için açık ve insanlar tarafından anlaşılabilir açıklamalar sunmayı amaçlayan süreçler ve yöntemlerin bir bütününü ifade eder.
Bu modellere bir açıklanabilirlik katmanı entegre ederek, Veri Bilimcileri ve Makine Öğrenimi uygulayıcıları; geliştiriciler, düzenleyiciler ve son kullanıcılar gibi geniş bir paydaş kitlesine yardımcı olacak, daha güvenilir ve şeffaf sistemler oluşturabilir.
Güven oluşturmaya katkıda bulunabilecek bazı açıklanabilir yapay zekâ ilkeleri şunlardır:
Açıklanabilir yapay zekâyı uygulamanın çeşitli faydaları vardır. Karar vericiler ve diğer paydaşlar için, yapay zekâ destekli kararların arkasındaki gerekçeyi net şekilde anlatarak daha bilinçli tercihler yapmalarını sağlar. Ayrıca modellerdeki olası önyargı veya hataları belirlemeye yardımcı olarak daha doğru ve adil sonuçlara yol açar.
Model açıklanabilirliğinin iki geniş kategorisi vardır: modele özgü yöntemler ve modelden bağımsız yöntemler. Bu bölümde özellikle modelden bağımsız yöntemlere odaklanarak aralarındaki farkı anlayacağız.
Her iki teknik de modellerin etkili ve hesap verebilir olmasını sağlarken, makine öğrenimi modellerinin iç işleyişine dair değerli içgörüler sunabilir.
Bu araçları daha iyi göstermek için Kaggle’daki diabet veri setini kullanacağız. Önce basit bir sınıflandırıcı kuracak, ardından açıklanabilirliği uygulayacağız. Tam kaynak kodu bu DataLab çalışma kitabında mevcuttur.
Diabet sonuçlarını tahmin etmek için diabet veri setiyle bir Random Forest sınıflandırıcısı kurulur. Kod birkaç adıma ayrılmıştır: (1) ilgili kütüphaneleri içe aktarma, (2) eğitim ve test veri setlerini oluşturma, (3) modeli kurma ve (4) sınıflandırma raporu ile performans metriklerini bildirme.
# Load useful libraries
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
# Separate Features and Target Variables
X = diabetes_data.drop(columns='Outcome')
y = diabetes_data['Outcome']
# Create Train & Test Data
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3,
stratify =y,
random_state = 13)
# Build the model
rf_clf = RandomForestClassifier(max_features=2, n_estimators =100 ,bootstrap = True)
rf_clf.fit(X_train, y_train)
# Make prediction on the testing data
y_pred = rf_clf.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))Son yazdırma ifadesi aşağıdaki raporu üretir:
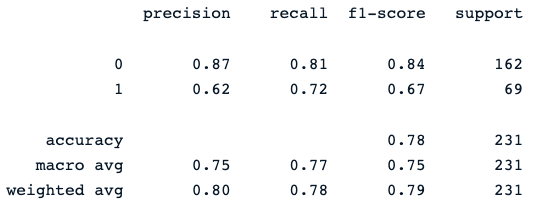
Rastgele orman sınıflandırıcısı, farklı modellerle iyileştirme payı olmakla birlikte, diabet sonuçlarını tahmin etmede makul bir performans sunmaktadır.
Şimdi, tahminlere daha fazla içgörü sağlamak için bu modele açıklanabilirlik katmanını entegre edebiliriz. Sonraki bölüm, model açıklanabilirliğinin iki geniş kategorisine odaklanacaktır: modele özgü yöntemler ve modelden bağımsız yöntemler.
Makine Öğreniminde Sınıflandırma: Bir Giriş makalemiz, sınıflandırmanın ne olduğunu, nasıl kullanıldığını ve bazı sınıflandırma algoritmalarına örnekleri ele alarak konuya hâkim olmanıza yardımcı olur.
Bu yöntemler, yapısı veya türü ne olursa olsun herhangi bir makine öğrenimi modeline uygulanabilir. Özelliklerin girdi-çıktı eşlerini analiz etmeye odaklanırlar. Bu bölümde yaygın olarak kullanılan iki vekil model olan LIME ve SHAP tanıtılıp tartışılacaktır.
SHapley Additive exPlanations ifadesinin kısaltmasıdır. Bu yöntem, bir örnek/gözlemin tahminini, her bir özelliğin tahmine yaptığı katkıyı hesaplayarak açıklamayı amaçlar ve aşağıdaki pip komutuyla kurulabilir.
!pip install shapKurulumdan sonra:
import shap
import matplotlib.pyplot as plt
# load JS visualization code to notebook
shap.initjs()
# Create the explainer
explainer = shap.TreeExplainer(rf_clf)
shap_values = explainer.shap_values(X_test)SHAP, modelin yorumlanabilirliğini artırmak için bir dizi görselleştirme aracı sunar ve bir sonraki bölümde bunlardan ikisi tartışılacaktır: (1) özet grafikle değişken önemi, (2) belirli bir hedef için özet grafik ve (3) bağımlılık grafiği.
Bu grafikte, özellikler ortalama SHAP değerlerine göre sıralanır; en önemli özellikler üstte, en az önemli olanlar altta gösterilir ve summary_plot() işlevi kullanılır. Bu, her bir özelliğin modelin tahminleri üzerindeki etkisini anlamaya yardımcı olur.
print("Variable Importance Plot - Global Interpretation")
figure = plt.figure()
shap.summary_plot(shap_values, X_test)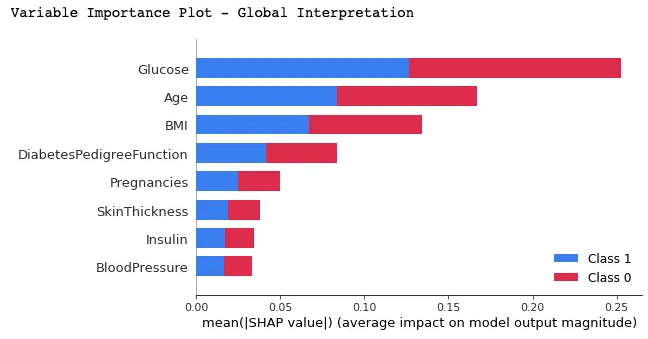
Yukarıdaki grafikten şu yorumlar yapılabilir:
Bu yaklaşım, her bir özelliğin belirli bir sonuç (etiket) üzerindeki etkisinin daha ayrıntılı bir görünümünü sağlayabilir.
Aşağıdaki örnekte, shap_values[1] diabeti olan (etiket 1) olarak sınıflandırılan örnekler için SHAP değerlerini temsil etmek üzere kullanılır.
shap.summary_plot(shap_values[1], X_test)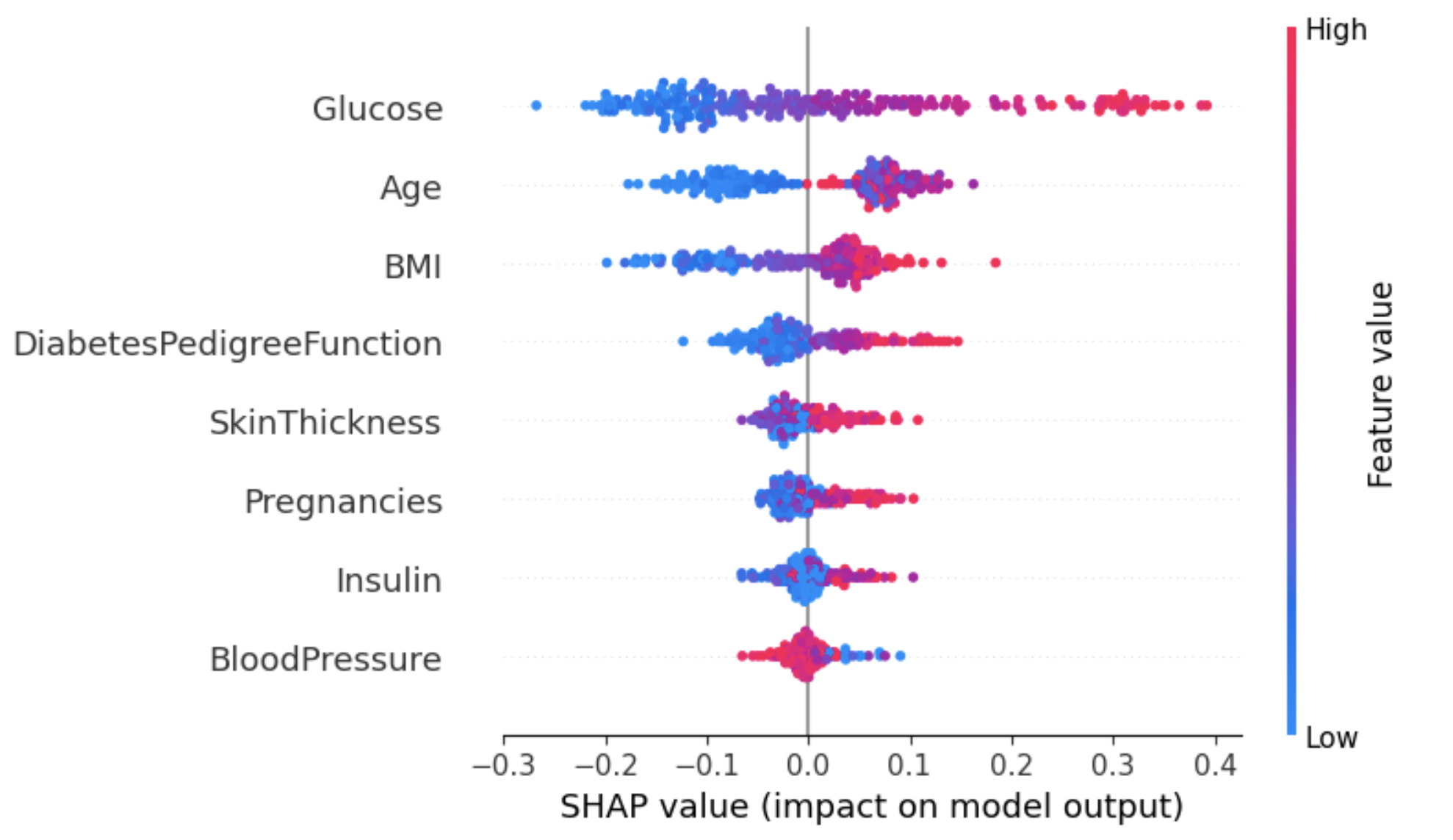
Yukarıdaki grafikten:
Age niteliğindeki bu belirsizlikle başa çıkmanın bir yolu, daha fazla içgörü kazanmak için bağımlılık grafiğini kullanmaktır.
Özet grafiklerden farklı olarak bağımlılık grafikleri, belirli bir özelliğin veri içindeki her bir örnek için öngörülen sonuçla ilişkisini gösterir. Bu analiz, daha ayrıntılı bilgi edinmenin yanı sıra, özet grafiklerden veya diğer küresel özellik önemi ölçümlerinden elde edilen bulguları doğrulayıp sorgulayarak incelenen özelliğin önemini teyit etmek gibi çeşitli amaçlarla yapılır.
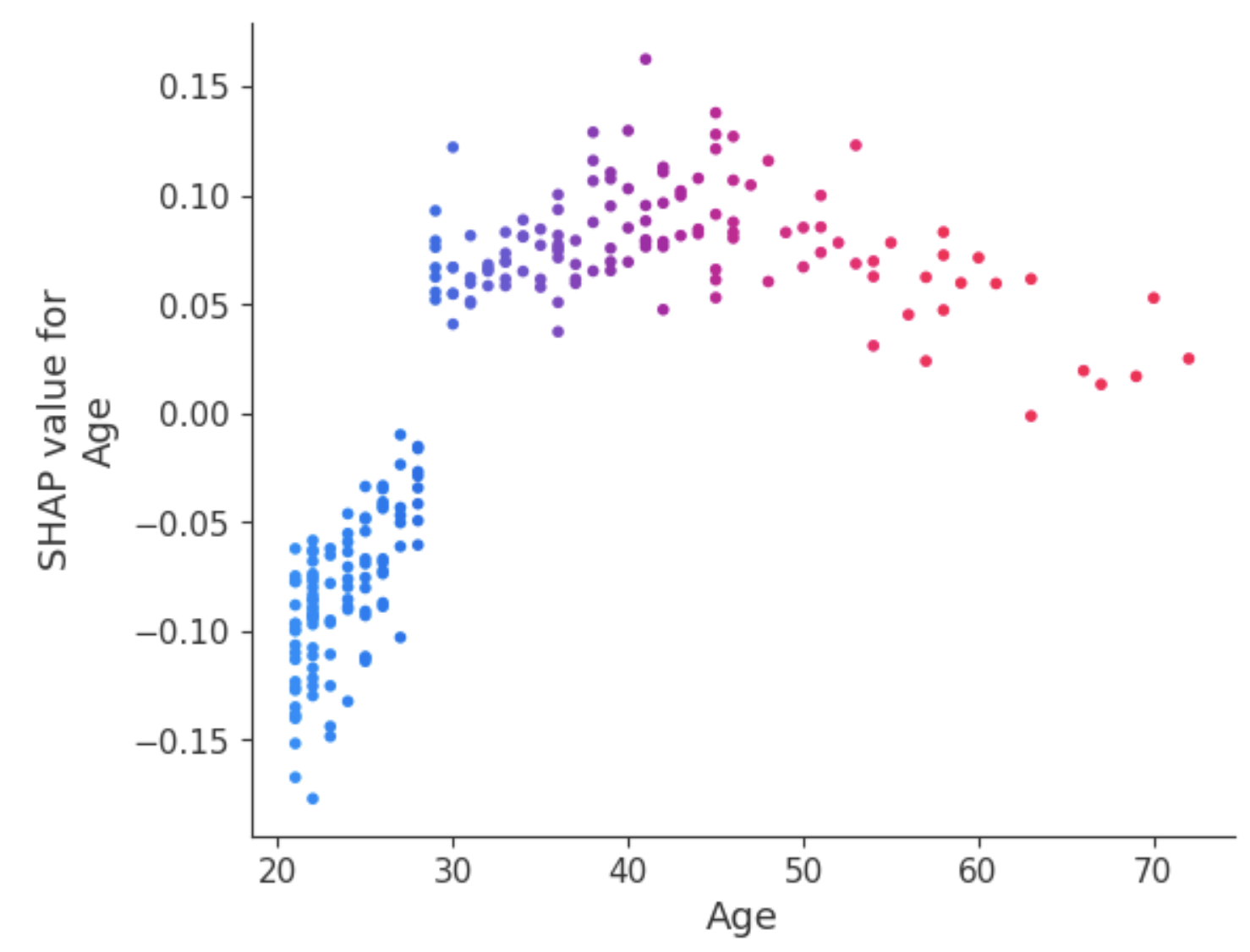
Bağımlılık grafiği, 30 yaşın altındaki hastaların diabet tanısı alma riskinin daha düşük olduğunu ortaya koyuyor. Buna karşılık, 30 yaşın üzerindeki bireylerin diabet tanısı alma olasılığı daha yüksektir.
Yerel Yorumlanabilir Modelden Bağımsız Açıklamalar (kısaca LIME). Modelin tüm veri kümesi üzerindeki küresel anlayışını sunmak yerine LIME, modelin tekil örnekler için yaptığı tahminleri açıklamaya odaklanır.
LIME açıklayıcıyı iki ana adımda kurabilirsiniz: (1) lime modülünü içe aktarma ve (2) açıklayıcıyı eğitim verileri ve hedeflerle eğitme. Bu aşamada, yürütülen göreve karşılık gelecek şekilde kip classification olarak ayarlanır.
# Import the LimeTabularExplainer module
from lime.lime_tabular import LimeTabularExplainer
# Get the class names
class_names = ['Has diabetes', 'No diabetes']
# Get the feature names
feature_names = list(X_train.columns)
# Fit the Explainer on the training data set using the LimeTabularExplainer
explainer = LimeTabularExplainer(X_train.values, feature_names =
feature_names,
class_names = class_names,
mode = 'classification')Aşağıdaki kod parçacığı, test verilerindeki 8. örnek için rastgele orman sınıflandırıcısını kullanarak bir LIME açıklaması üretir ve son özellik katkılarını tablo biçiminde sunar.
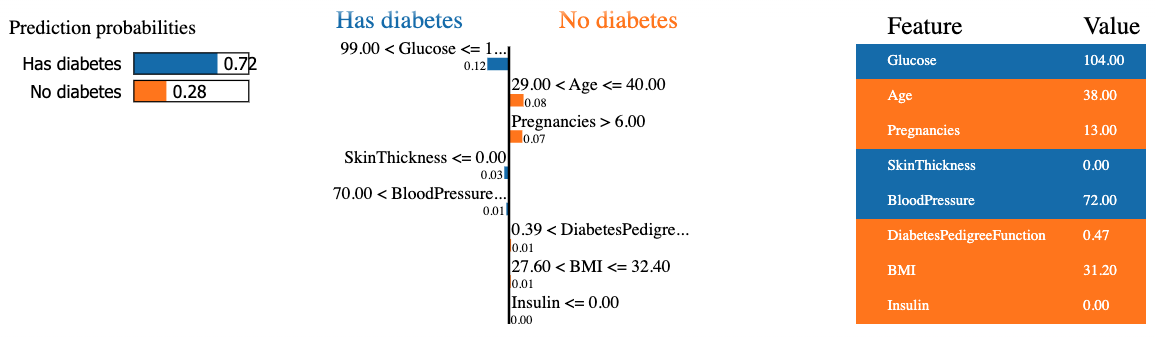
Sonuç, soldan sağa üç ana bilgiyi içerir: (1) modelin tahminleri, (2) özellik katkıları ve (3) her özellik için gerçek değer.
Sekizinci hastanın %72 güvenle diabet olduğu tahmin ediliyor. Modeli bu karara götüren nedenler şunlardır:
Bu değerler sağdaki tablodan doğrulanabilir.
Modelden bağımsız yöntemlerin aksine, bu yöntemler yalnızca sınırlı bir model kategorisine uygulanabilir. Bu modeller arasında doğrusal regresyon, karar ağaçları ve sinir ağlarının yorumlanabilirliği bulunur. DeepLIFT, Grad-CAM veya Integrated Gradients gibi farklı teknikler derin öğrenme modellerini açıklamak için kullanılabilir.
Bir karar ağacı modeli kullanılırken, scikit-learn’ün plot_tree işleviyle modelin yukarıdan aşağıya karar verme sürecini açıklayan grafik bir ağaç üretilebilir; aşağıda bir örnek verilmiştir.
Derin Öğrenme - Veri Bilimcileri için Bir Eğitim makalesi, derin öğrenmeyle ilgili en sık sorulan soruları yanıtlar ve derin öğrenmenin çeşitli yönlerini gerçek hayat örnekleriyle inceler.
Grafik ağacı oluşturmadan önce max_depth ve min_samples_leaf gibi belirli hiperparametrelerle bir karar ağacı sınıflandırıcısı eğitelim.
from sklearn.tree import DecisionTreeClassifier, plot_tree
dt_clf = DecisionTreeClassifier(max_depth = 3, min_samples_leaf = 2)
dt_clf.fit(X_train, y_train)
# Predict on the test data and evaluate the model
y_pred = dt_clf.predict(X_test)
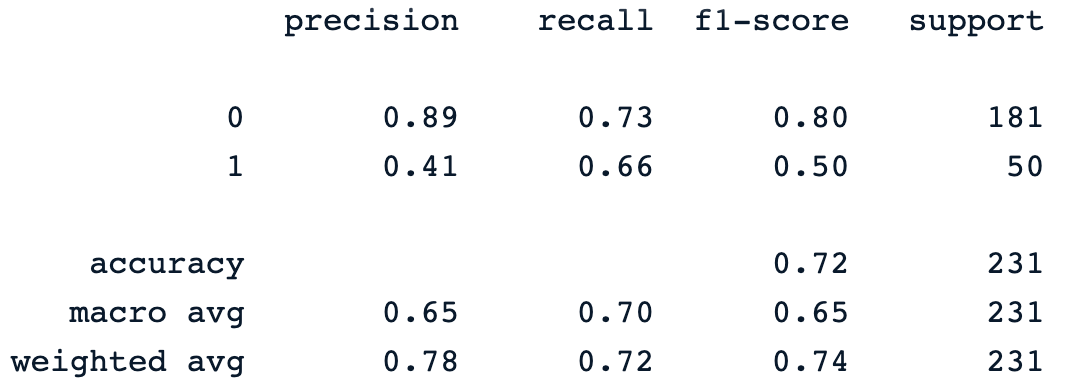
print(classification_report(y_pred, y_test))Önceki yazdırma ifadesi modelin aşağıdaki sınıflandırma raporunu üretir.
Ve modelin karar verme süreci aşağıdaki koddan görselleştirilebilir:
fig = plt.figure(figsize=(25,20))
_ = plot_tree(dt_clf,
feature_names = feature_names,
class_names = class_names,
filled=True)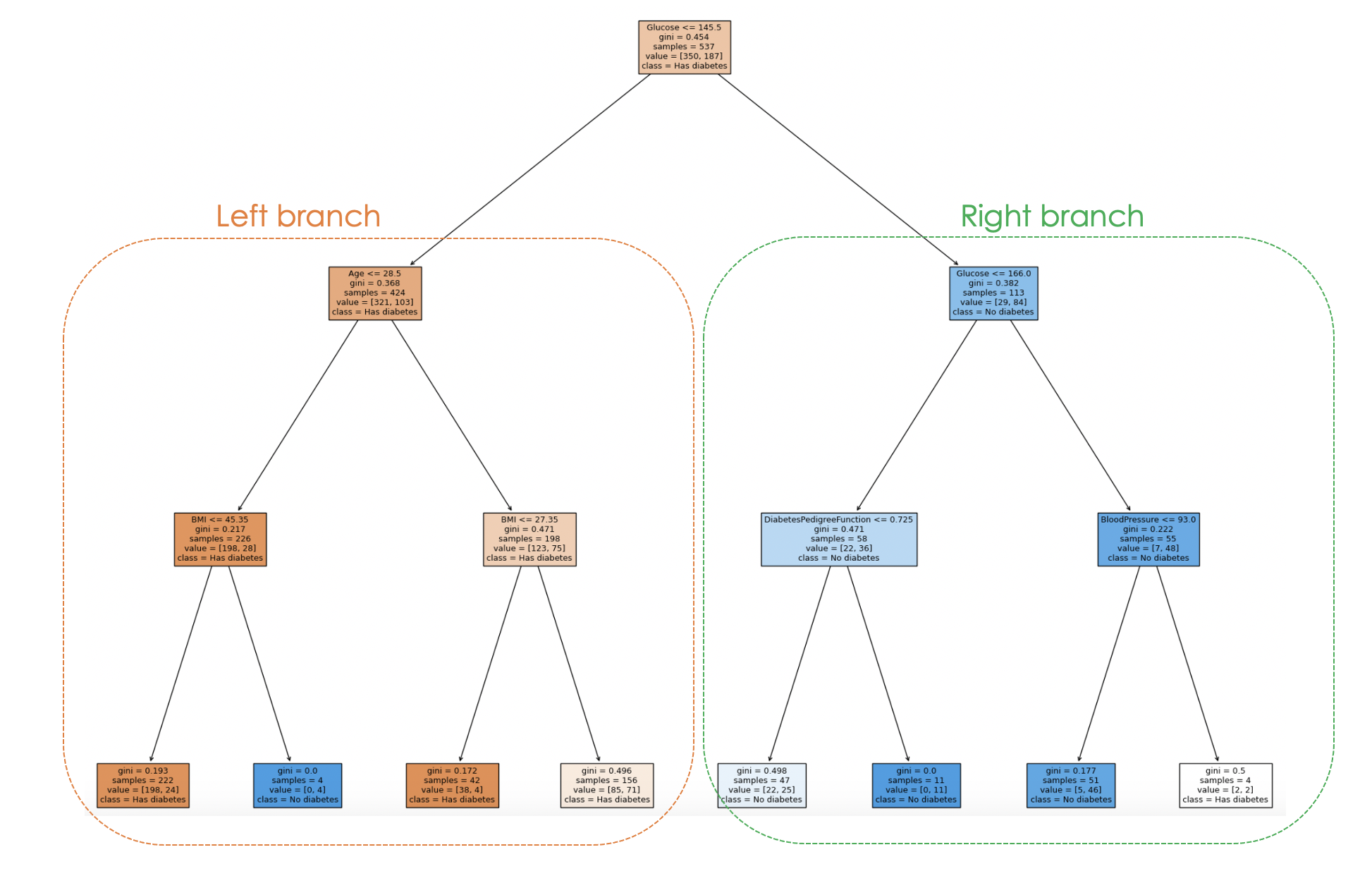
Ağaç yapısı incelenerek, her bir örnek için karar verme süreci izlenebilir ve bu da modelin davranışı ve yorumlanabilirliği hakkında içgörü sağlar.
Yukarıdaki grafikte her düğüm, belirli bir özellik değerine dayalı bir karar ya da bölünmeyi temsil eder. Her iç düğüm için grafikte bölünmede kullanılan özellik, bölünme ölçütü değeri, Gini safsızlığı ve o düğüme ulaşan örnek sayısı gösterilir.
Yaprak düğümlerde, çoğunluk sınıfı ve örnek sayısı görüntülenir. Ayrıca düğümlerdeki renkler çoğunluk sınıfını temsil eder; rengin yoğunluğu, o düğümde baskın sınıfın oranını gösterir. Örneğin, sol daldaki turuncu düğümler diabet etiketine, mavi olan ise diabet olmamasına karşılık gelir.
Yapay zekâ teknolojisi gelişip daha sofistike hale geldikçe, algoritmaların sonuçları nasıl ürettiğini anlamak ve yorumlamak giderek zorlaşıyor; bu da araştırmacıların yeni yaklaşımları keşfetmeye ve mevcut olanları iyileştirmeye devam etmesine olanak tanıyor.
Birçok açıklanabilir yapay zekâ modeli, altta yatan modeli basitleştirmeyi gerektirir ve bu da kestirim performansında kayba yol açabilir. Ayrıca mevcut açıklanabilirlik yöntemleri, karar verme sürecinin tüm yönlerini kapsamayabilir; bu da özellikle daha karmaşık modellerle çalışırken açıklamanın faydasını sınırlayabilir.
Yeni araştırma yöntemleri, etik sorunları ele alacak daha etkili algoritmalar geliştirerek ve kullanıcı dostu açıklamalar oluşturarak açıklanabilir yapay zekâ tekniklerini geliştirmeye odaklanıyor.
Sonuç olarak, devam eden araştırmalarla şeffaflığı, güvenilirliği ve adaleti destekleyen daha gelişmiş yöntemlere sahip olma olasılığımız daha yüksek.
Bu makale, açıklanabilir yapay zekânın ne olduğuna ve güven inşasına katkıda bulunan bazı ilkelere iyi bir genel bakış sundu; Veri Bilimcilerine ve diğer paydaşlara, uygulanabilir kararlar almaya yardımcı olacak güvenilir modeller kurmaları için ilgili yetkinlikler sağlayabilir.
Ayrıca LIME ve SHAP kullanarak özellikle birincisine odaklanıp, modelden bağımsız ve modele özgü yöntemleri ele aldık. Ek olarak, açıklanabilir yapay zekâ ile ilgili zorluklar, sınırlamalar ve bazı araştırma alanları vurgulandı.
Bu tür bir teknolojinin arkasındaki etik hakkında daha fazla bilgi edinmek için, veri etiği ilkelerini, yapay zekâ etiği ile ilişkisini ve veri yaşam döngüsünün farklı aşamalarındaki özelliklerini kapsayan Veri Etiğine Giriş kursumuza göz atın.
Yapay zekâ hakkında daha fazla bilgi edinin!
Program
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
