
Kursus
Konsep Large Language Models (LLM)
2 Hr
104.1K
Model Bahasa adalah jenis algoritma pembelajaran mesin yang dirancang untuk memprediksi kata berikutnya dalam sebuah kalimat, dengan melihat bagian sebelumnya. Model ini berbasis arsitektur Transformers, yang dijelaskan secara mendalam dalam artikel kami tentang Cara kerja Transformers.
Model bahasa pra-latih, seperti GPT (Generative Pre-trained Transformer), dilatih pada sejumlah besar data teks. Hal ini memungkinkan LLM memahami prinsip-prinsip dasar penggunaan kata dan penyusunannya dalam bahasa alami.

Gambar oleh Penulis. Input dan output LLM.
Bagian terpentingnya adalah model-model ini bukan hanya unggul dalam memahami bahasa alami, tetapi juga mahir menghasilkan teks menyerupai manusia berdasarkan masukan yang diterima.
Dan bagian terbaik dari semuanya?
Model-model ini sudah tersedia untuk khalayak luas melalui API. Jika Anda ingin mempelajari cara memanfaatkan LLM paling kuat dari OpenAI, Anda dapat mempelajarinya melalui lembar contekan tentang OpenAI API.
Fine-tuning adalah proses mengambil model yang telah dilatih sebelumnya lalu melatihnya lebih lanjut pada dataset khusus domain.
Kebanyakan model LLM saat ini memiliki performa global yang sangat baik, tetapi kurang pada masalah yang sangat berorientasi tugas. Proses fine-tuning menawarkan keuntungan besar, termasuk menurunkan biaya komputasi dan kemampuan memanfaatkan model tercanggih tanpa perlu membangunnya dari nol.
Transformers menyediakan akses ke koleksi besar model pra-latih yang cocok untuk berbagai tugas. Fine-tuning model-model ini adalah langkah krusial untuk meningkatkan kemampuan model dalam melakukan tugas tertentu, seperti analisis sentimen, tanya jawab, atau peringkasan dokumen, dengan akurasi lebih tinggi.
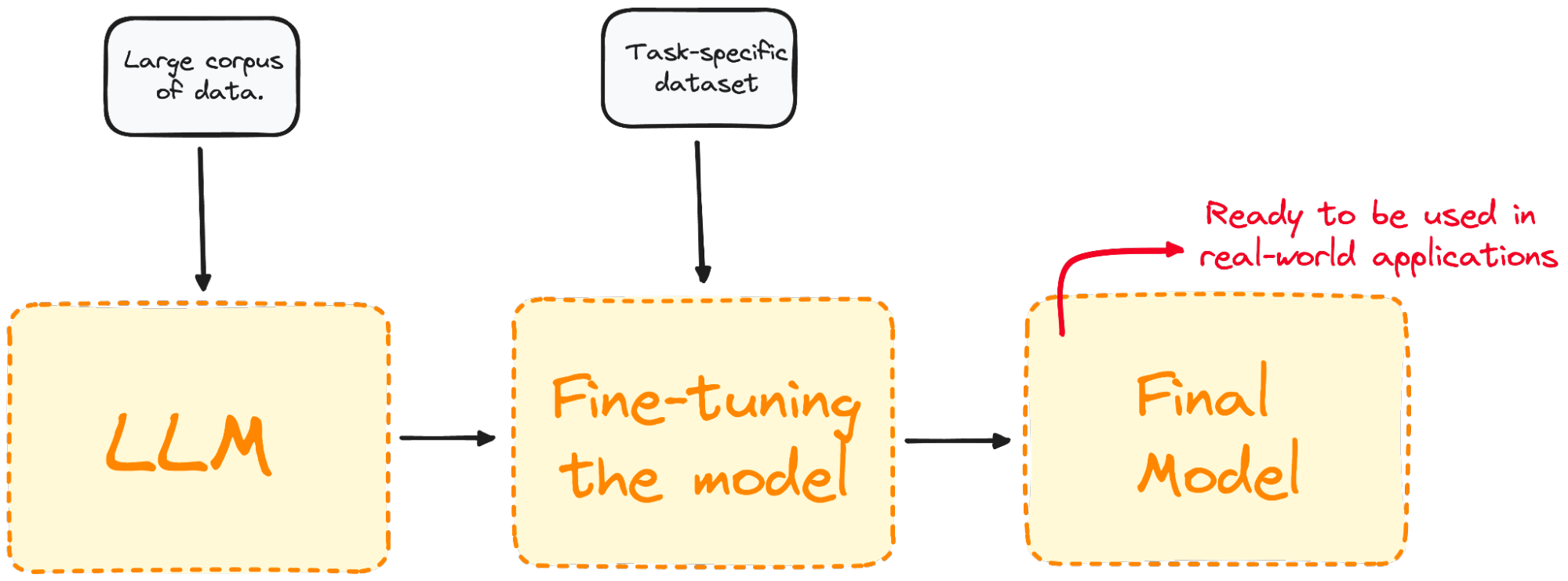
Gambar oleh Penulis. Memvisualisasikan proses Fine-Tuning.
Fine-tuning menyesuaikan model agar memiliki performa lebih baik untuk tugas spesifik, sehingga lebih efektif dan serbaguna dalam aplikasi dunia nyata. Proses ini penting untuk menyesuaikan model yang ada dengan tugas atau domain tertentu.
Apakah perlu melakukan fine-tuning bergantung pada tujuan Anda, yang biasanya bervariasi berdasarkan domain atau tugas yang dihadapi.
Fine-tuning dapat dilakukan dengan beberapa pendekatan, terutama bergantung pada fokus utama dan tujuan spesifiknya.
Pendekatan fine-tuning yang paling sederhana dan umum. Model dilatih lebih lanjut pada dataset berlabel yang spesifik untuk tugas target yang akan dilakukan, seperti klasifikasi teks atau pengenalan entitas bernama.
Sebagai contoh, kita akan melatih model pada dataset yang berisi sampel teks berlabel sentimennya untuk analisis sentimen.
Ada beberapa kasus di mana mengumpulkan dataset berlabel besar tidak praktis. Few-shot learning mencoba mengatasi hal ini dengan memberikan beberapa contoh (atau shot) tugas yang dibutuhkan di awal prompt masukan. Ini membantu model memiliki konteks tugas yang lebih baik tanpa proses fine-tuning yang ekstensif.
Meskipun semua teknik fine-tuning merupakan bentuk transfer learning, kategori ini secara khusus ditujukan agar model dapat melakukan tugas yang berbeda dari tugas awal saat model dilatih. Gagasannya adalah memanfaatkan pengetahuan yang diperoleh model dari dataset besar dan umum, lalu menerapkannya pada tugas yang lebih spesifik atau terkait.
Jenis fine-tuning ini berupaya menyesuaikan model agar memahami dan menghasilkan teks yang spesifik untuk suatu domain atau industri tertentu. Model di-fine-tune pada dataset yang terdiri atas teks dari domain target untuk meningkatkan konteks dan pengetahuan terkait tugas spesifik domain.
Sebagai contoh, untuk membuat chatbot untuk aplikasi medis, model akan dilatih dengan rekam medis, agar kemampuan pemahaman bahasanya beradaptasi dengan bidang kesehatan.
Jalankan dan edit kode dari tutorial ini secara online.
Jalankan kodeKita sudah tahu bahwa fine-tuning adalah proses mengambil model pra-latih dan memperbarui parameternya dengan melatih pada dataset yang spesifik untuk tugas Anda. Jadi, mari kita contohkan konsep ini dengan melakukan fine-tuning pada model nyata.
Bayangkan kita bekerja dengan GPT-2, tetapi kita mendapati model ini cukup buruk dalam menyimpulkan sentimen tweet.
Pertanyaan alami yang muncul: Bisakah kita melakukan sesuatu untuk meningkatkan performanya?
Kita dapat memanfaatkan fine-tuning dengan melatih model GPT-2 pra-latih dari Hugging Face menggunakan dataset yang berisi tweet dan sentimennya masing-masing agar performanya meningkat. Berikut contoh dasar fine-tuning model untuk klasifikasi sekuens:
Untuk melakukan fine-tuning, kita selalu perlu menentukan model pra-latih. Dalam kasus kita, kita akan melakukan fine-tuning sederhana menggunakan GPT-2.
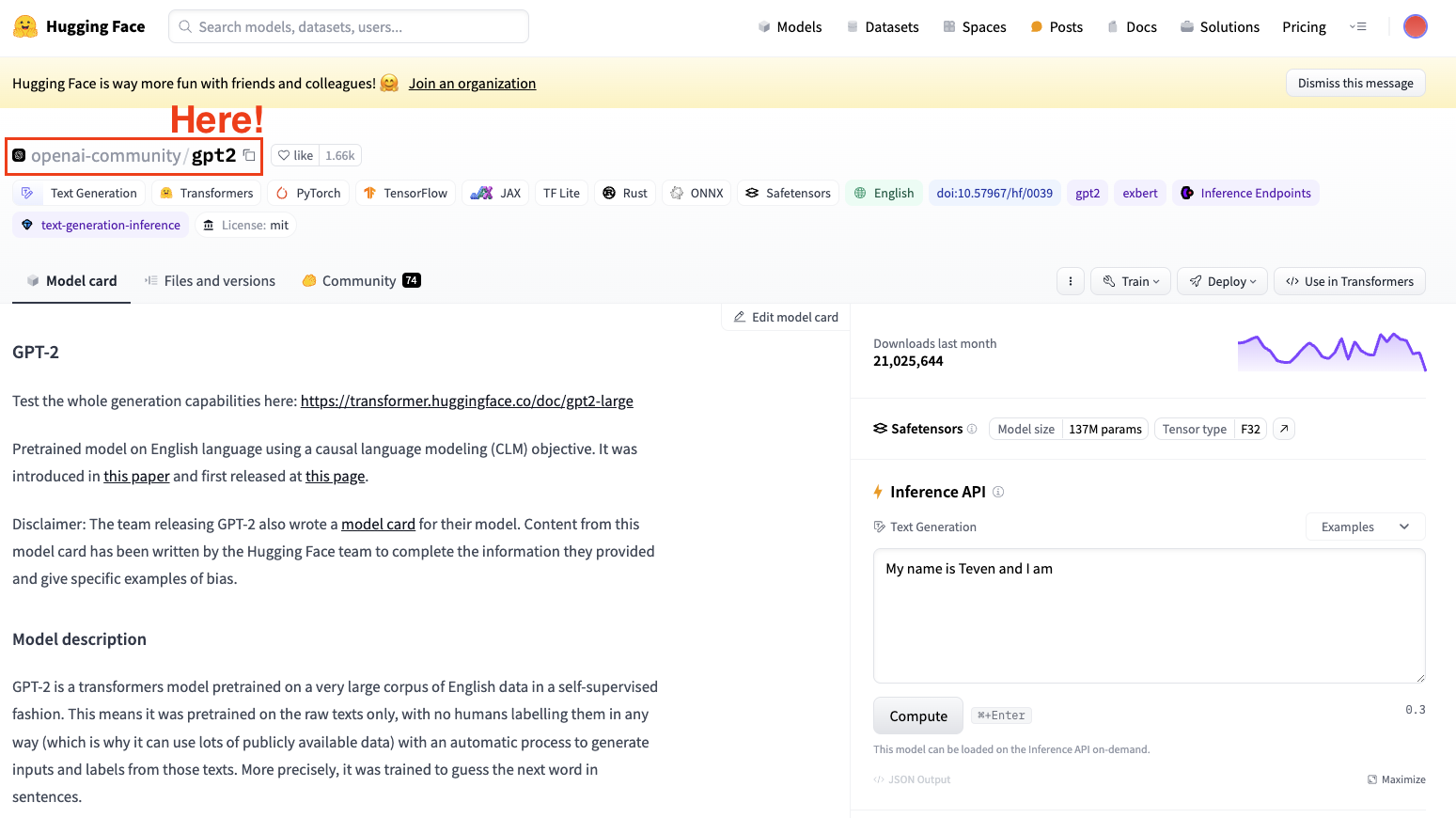
Tangkapan layar Hugging Face Datasets Hub. Memilih model GPT2 dari OpenAI.
Selalu ingat untuk memilih arsitektur model yang sesuai dengan tugas Anda.
Sekarang kita sudah memiliki model, kita memerlukan data berkualitas baik untuk dikerjakan, dan inilah tepatnya peran pustaka datasets.
Dalam kasus saya, saya akan menggunakan pustaka datasets dari Hugging Face untuk mengimpor dataset yang berisi tweet yang dipilah berdasarkan sentimennya (Positif, Netral, atau Negatif).
from datasets import load_dataset
dataset = load_dataset("mteb/tweet_sentiment_extraction")
df = pd.DataFrame(dataset['train'])
Jika kita periksa dataset yang baru diunduh, ini adalah dataset yang berisi subset untuk pelatihan dan subset untuk pengujian. Jika kita konversi subset pelatihan menjadi dataframe, tampilannya sebagai berikut.

Dataset yang akan digunakan.
Kini setelah kita memiliki dataset, kita memerlukan tokenizer untuk menyiapkannya agar dapat diproses oleh model.
Karena LLM bekerja dengan token, kita memerlukan tokenizer untuk memroses dataset. Untuk memproses dataset Anda dalam satu langkah, gunakan metode map pada Datasets untuk menerapkan fungsi prapemrosesan ke seluruh dataset.
Inilah mengapa langkah kedua adalah memuat Tokenizer pra-latih dan melakukan tokenisasi pada dataset agar dapat digunakan untuk fine-tuning.
from transformers import GPT2Tokenizer
# Loading the dataset to train our model
dataset = load_dataset("mteb/tweet_sentiment_extraction")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)BONUS: Untuk mengurangi kebutuhan pemrosesan, kita dapat membuat subset yang lebih kecil dari keseluruhan dataset untuk melakukan fine-tuning pada model kita. Set pelatihan akan digunakan untuk fine-tuning, sedangkan set pengujian akan digunakan untuk evaluasi.
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))Mulailah dengan memuat model Anda dan tentukan jumlah label yang diharapkan. Dari kartu dataset sentimen Tweet, Anda tahu ada tiga label:
from transformers import GPT2ForSequenceClassification
model = GPT2ForSequenceClassification.from_pretrained("gpt2", num_labels=3)Transformers menyediakan kelas Trainer yang dioptimalkan untuk pelatihan. Namun, metode ini tidak menyertakan cara mengevaluasi model. Itulah mengapa, sebelum memulai pelatihan, kita perlu memberikan kepada Trainer sebuah fungsi untuk mengevaluasi performa model.
import evaluate
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)Langkah terakhir kita adalah menyiapkan argumen pelatihan dan memulai proses pelatihan. Pustaka Transformers memiliki kelas Trainer, yang mendukung beragam opsi pelatihan dan fitur seperti logging, akumulasi gradien, dan presisi campuran. Kita terlebih dahulu mendefinisikan argumen pelatihan beserta strategi evaluasi. Setelah semuanya didefinisikan, kita dapat dengan mudah melatih model hanya dengan perintah train().
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="test_trainer",
#evaluation_strategy="epoch",
per_device_train_batch_size=1, # Reduce batch size here
per_device_eval_batch_size=1, # Optionally, reduce for evaluation as well
gradient_accumulation_steps=4
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
Setelah pelatihan, evaluasilah performa model pada set validasi atau set uji. Sekali lagi, kelas trainer sudah memiliki metode evaluate yang menangani hal ini.
import evaluate
trainer.evaluate()
Ini adalah langkah-langkah paling dasar untuk melakukan fine-tuning pada LLM apa pun. Ingat bahwa fine-tuning LLM sangat menuntut komputasi, dan komputer lokal Anda mungkin tidak cukup kuat untuk melakukannya.
Anda dapat mempelajari cara melakukan fine-tuning LLM yang lebih kuat langsung di antarmuka OpenAI dengan mengikuti tutorial tentang Cara Melakukan Fine-Tune GPT 3.5.
Untuk memastikan fine-tuning berhasil, pertimbangkan praktik terbaik berikut:
Kualitas dataset fine-tuning Anda sangat memengaruhi performa model. Kita semua tahu ungkapan:
“Garbage In, Garbage Out”
Jadi, pastikan selalu data bersih, relevan, dan cukup besar.
Fine-tuning biasanya merupakan proses panjang yang perlu diiterasi. Selalu eksplorasi berbagai pengaturan untuk laju pembelajaran, ukuran batch, dan jumlah epoch pelatihan untuk menemukan setelan terbaik bagi proyek Anda.
Penyesuaian yang tepat adalah kunci agar model belajar secara efisien dan beradaptasi dengan baik pada data yang belum pernah dilihat, sekaligus menghindari jebakan overfitting.
Secara berkala pantau kemajuan model selama pelatihan untuk menilai efektivitasnya dan menerapkan modifikasi yang diperlukan. Ini melibatkan evaluasi performa model menggunakan dataset validasi yang terpisah sepanjang periode pelatihan.
Evaluasi semacam ini krusial untuk menentukan performa model pada tugas yang dikerjakan dan potensi overfitting terhadap dataset pelatihan. Berdasarkan hasil dari fase validasi, penyesuaian dapat dilakukan sesuai kebutuhan untuk mengoptimalkan performa.
Fine-tuning terkadang dapat menghasilkan keluaran yang kurang optimal. Waspadai jebakan berikut:
Menggunakan dataset kecil untuk pelatihan atau memperpanjang jumlah epoch secara berlebihan dapat menimbulkan overfitting. Biasanya ditandai dengan akurasi tinggi pada dataset pelatihan, tetapi gagal menggeneralisasi ke data baru.
Sebaliknya, pelatihan yang tidak memadai atau laju pembelajaran rendah dapat menyebabkan underfitting, di mana model gagal mempelajari tugas dengan baik.
Dalam proses fine-tuning untuk tugas tertentu, ada risiko model kehilangan pengetahuan luas yang awalnya diperoleh. Masalah ini, yang disebut catastrophic forgetting, dapat mengurangi kemampuan model untuk berkinerja baik di berbagai tugas pemrosesan bahasa alami.
Selalu pastikan bahwa dataset pelatihan dan validasi terpisah dan tidak ada tumpang tindih, karena hal ini dapat memberikan metrik performa yang menyesatkan.
RAG menggabungkan kekuatan model berbasis penelusuran dan model generatif. Dalam RAG, komponen retriever menelusuri basis data atau basis pengetahuan besar untuk menemukan informasi relevan berdasarkan kueri masukan. Informasi yang diambil ini kemudian digunakan oleh model generatif untuk menghasilkan respons yang lebih akurat dan kontekstual. Manfaat utama RAG meliputi:
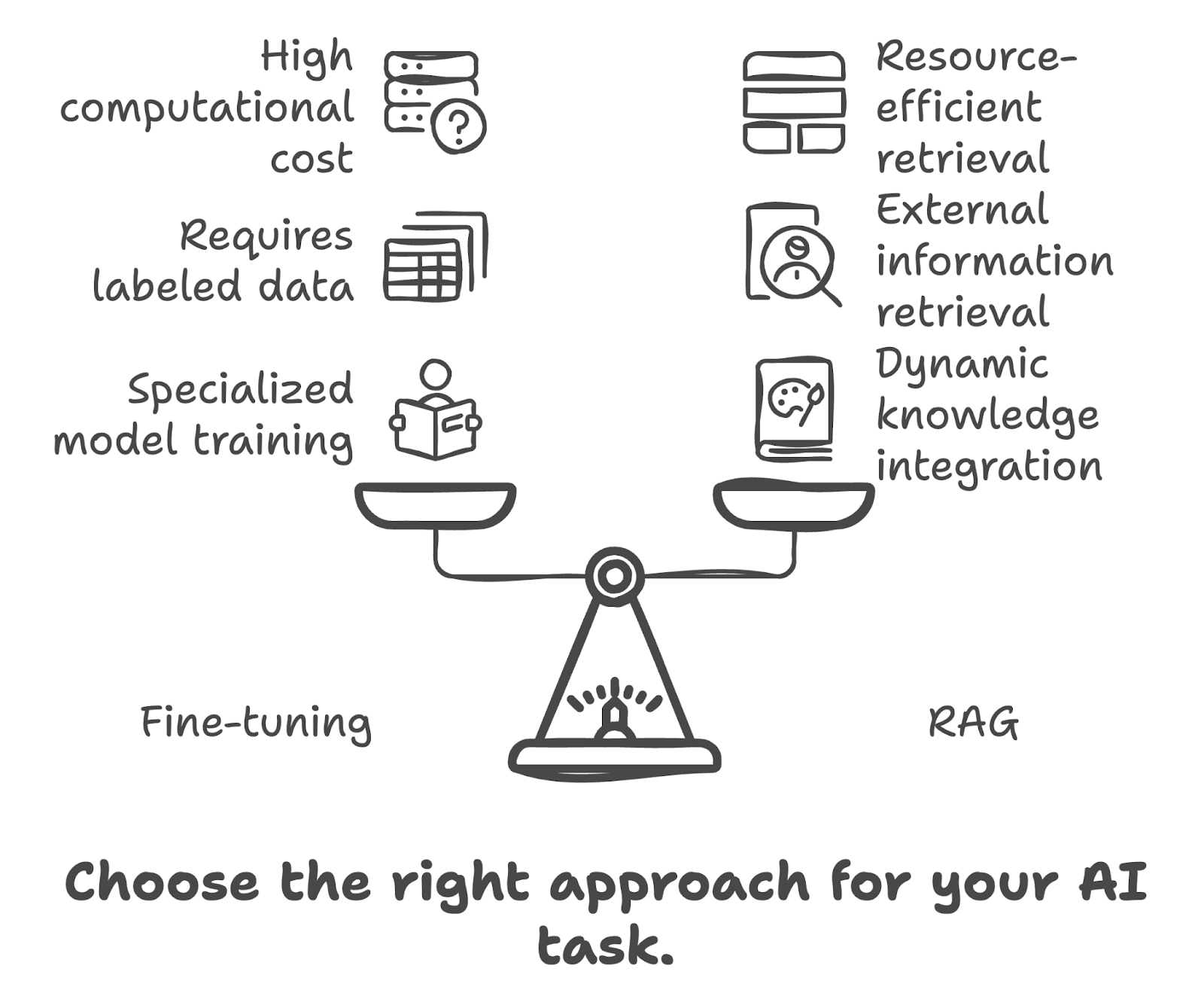
Saat memutuskan apakah akan menggunakan fine-tuning atau RAG, pertimbangkan faktor-faktor berikut:
Memulai perjalanan fine-tuning model bahasa besar membuka berbagai kemungkinan untuk aplikasi AI.
Dengan memahami dan menerapkan konsep, praktik, dan kehati-hatian yang diuraikan, Anda dapat secara efektif menyesuaikan model-model kuat ini untuk memenuhi kebutuhan spesifik, sekaligus membuka potensi penuhnya.
Untuk terus belajar tentang fine-tuning, saya sangat menganjurkan Anda melakukan fine-tuning yang lebih lanjut. Anda dapat mulai dengan kursus Konsep LLM dari DataCamp, yang membahas banyak metodologi pelatihan utama dan riset terbaru. Sumber baik lainnya yang bisa diikuti:
Mulai Perjalanan AI Anda Hari Ini!
Kursus
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
David Woods
13 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
