
Courses
Các khái niệm về Large Language Models (LLMs)
2 giờ
104.1K
Mô hình ngôn ngữ là một loại thuật toán học máy được thiết kế để dự đoán từ tiếp theo trong một câu, dựa trên các đoạn trước đó. Nó dựa trên kiến trúc Transformers, được giải thích chi tiết trong bài viết của chúng tôi về Cách Transformers hoạt động.
Các mô hình ngôn ngữ huấn luyện sẵn, như GPT (Generative Pre-trained Transformer), được huấn luyện trên lượng dữ liệu văn bản khổng lồ. Điều này giúp LLM nắm bắt được các nguyên tắc cơ bản chi phối việc sử dụng từ và sắp xếp của chúng trong ngôn ngữ tự nhiên.

Hình do Tác giả thực hiện. Đầu vào và đầu ra của LLM.
Điều quan trọng nhất là các mô hình này không chỉ giỏi hiểu ngôn ngữ tự nhiên mà còn giỏi tạo ra văn bản giống con người dựa trên đầu vào nhận được.
Và điều tuyệt vời nhất?
Những mô hình này đã sẵn sàng cho số đông thông qua API. Nếu bạn muốn học cách tận dụng các LLM mạnh nhất của OpenAI, bạn có thể làm theo cheat sheet về API của OpenAI.
Fine-tuning là quá trình lấy một mô hình đã huấn luyện sẵn và tiếp tục huấn luyện nó trên một tập dữ liệu theo lĩnh vực.
Hầu hết các LLM hiện nay có hiệu suất tổng quát rất tốt nhưng lại chưa tốt ở các bài toán định hướng tác vụ cụ thể. Quy trình fine-tuning mang lại nhiều lợi thế đáng kể, bao gồm giảm chi phí tính toán và khả năng tận dụng các mô hình hiện đại mà không cần xây dựng từ đầu.
Transformers cung cấp một bộ sưu tập lớn các mô hình huấn luyện sẵn phù hợp cho nhiều tác vụ. Fine-tuning các mô hình này là bước quan trọng để cải thiện khả năng thực hiện các tác vụ cụ thể như phân tích cảm xúc, trả lời câu hỏi hoặc tóm tắt tài liệu với độ chính xác cao hơn.
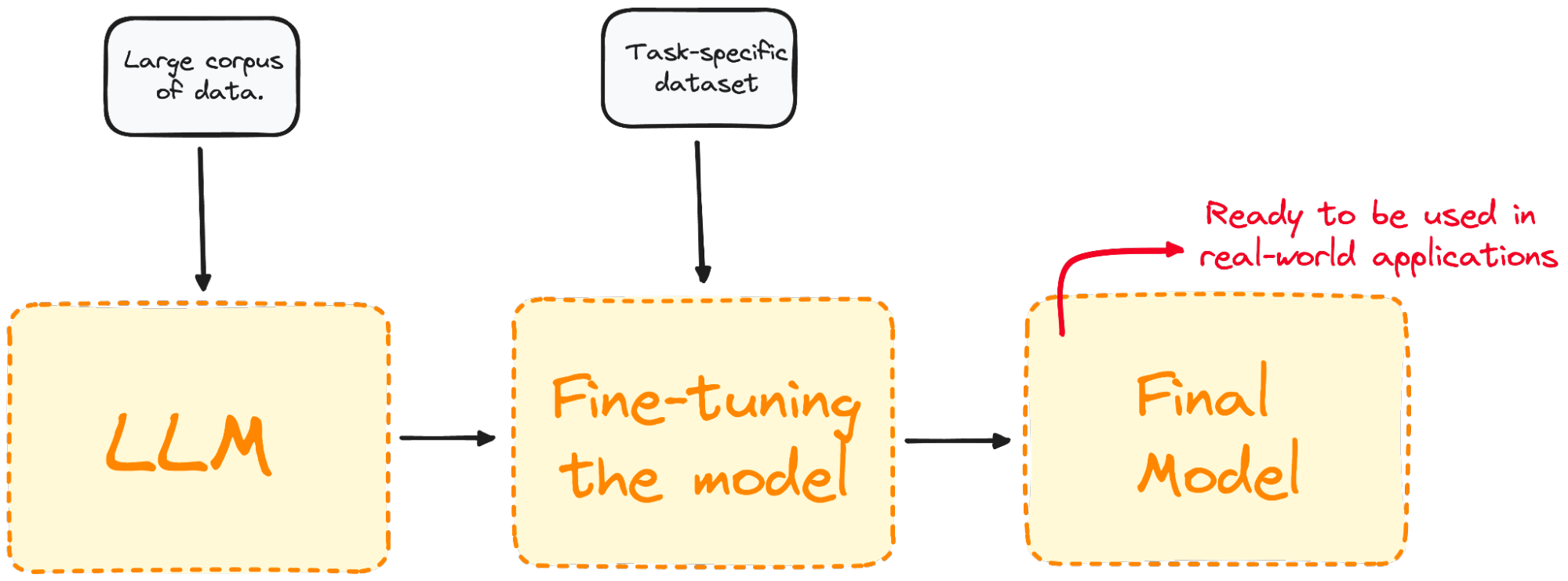
Hình do Tác giả thực hiện. Trực quan hóa quy trình Fine-Tuning.
Fine-tuning điều chỉnh mô hình để đạt hiệu suất tốt hơn cho các tác vụ cụ thể, giúp mô hình hiệu quả và linh hoạt hơn trong các ứng dụng thực tế. Quy trình này rất cần thiết để điều chỉnh một mô hình hiện có cho một tác vụ hoặc lĩnh vực nhất định.
Việc có nên thực hiện fine-tuning hay không phụ thuộc vào mục tiêu của bạn, thường thay đổi theo lĩnh vực hoặc tác vụ cụ thể.
Fine-tuning có thể được tiếp cận theo nhiều cách, chủ yếu tùy thuộc vào trọng tâm và mục tiêu cụ thể.
Cách tiếp cận đơn giản và phổ biến nhất. Mô hình được huấn luyện bổ sung trên một tập dữ liệu gán nhãn dành riêng cho tác vụ mục tiêu, như phân loại văn bản hoặc nhận diện thực thể có tên.
Ví dụ, chúng ta sẽ huấn luyện mô hình trên một tập dữ liệu chứa các mẫu văn bản được gán nhãn cảm xúc tương ứng để phục vụ phân tích cảm xúc.
Có những trường hợp việc thu thập một tập dữ liệu gán nhãn lớn là không khả thi. Few-shot learning cố gắng giải quyết điều này bằng cách cung cấp một vài ví dụ (shots) của tác vụ cần thực hiện ở phần đầu của prompt đầu vào. Cách này giúp mô hình có thêm ngữ cảnh về tác vụ mà không cần quy trình fine-tuning mở rộng.
Mặc dù tất cả kỹ thuật fine-tuning đều là một dạng học chuyển giao, danh mục này nhắm đến việc cho phép mô hình thực hiện một tác vụ khác với tác vụ ban đầu nó được huấn luyện. Ý tưởng chính là tận dụng kiến thức mà mô hình đã học từ một tập dữ liệu lớn, tổng quát và áp dụng nó cho một tác vụ cụ thể hoặc có liên quan hơn.
Dạng fine-tuning này cố gắng điều chỉnh mô hình để hiểu và tạo văn bản đặc thù cho một lĩnh vực hoặc ngành công nghiệp cụ thể. Mô hình được fine-tuned trên một tập dữ liệu gồm văn bản từ miền mục tiêu để cải thiện ngữ cảnh và kiến thức về các tác vụ đặc thù miền.
Ví dụ, để tạo chatbot cho một ứng dụng y tế, mô hình sẽ được huấn luyện với hồ sơ y khoa nhằm điều chỉnh khả năng hiểu ngôn ngữ cho lĩnh vực sức khỏe.
Chạy và chỉnh sửa mã từ hướng dẫn trực tuyến này.
Chạy mãChúng ta đã biết Fine-tuning là quá trình lấy một mô hình huấn luyện sẵn và cập nhật các tham số của nó bằng cách huấn luyện trên tập dữ liệu dành riêng cho tác vụ của bạn. Vậy hãy minh họa khái niệm này bằng cách fine-tuning một mô hình thực tế.
Hãy tưởng tượng chúng ta đang làm việc với GPT-2, nhưng nhận thấy nó khá kém trong việc suy luận cảm xúc của các tweet.
Một câu hỏi tự nhiên xuất hiện: Chúng ta có thể làm gì để cải thiện hiệu suất không?
Chúng ta có thể tận dụng fine-tuning bằng cách huấn luyện mô hình GPT-2 đã được huấn luyện sẵn từ Hugging Face với một tập dữ liệu chứa các tweet và cảm xúc tương ứng để cải thiện hiệu suất. Dưới đây là ví dụ cơ bản về fine-tuning một mô hình cho phân loại chuỗi:
Để fine-tuning một mô hình, chúng ta luôn cần có sẵn một mô hình đã huấn luyện. Trong trường hợp này, chúng ta sẽ thực hiện một số bước fine-tuning đơn giản với GPT-2.
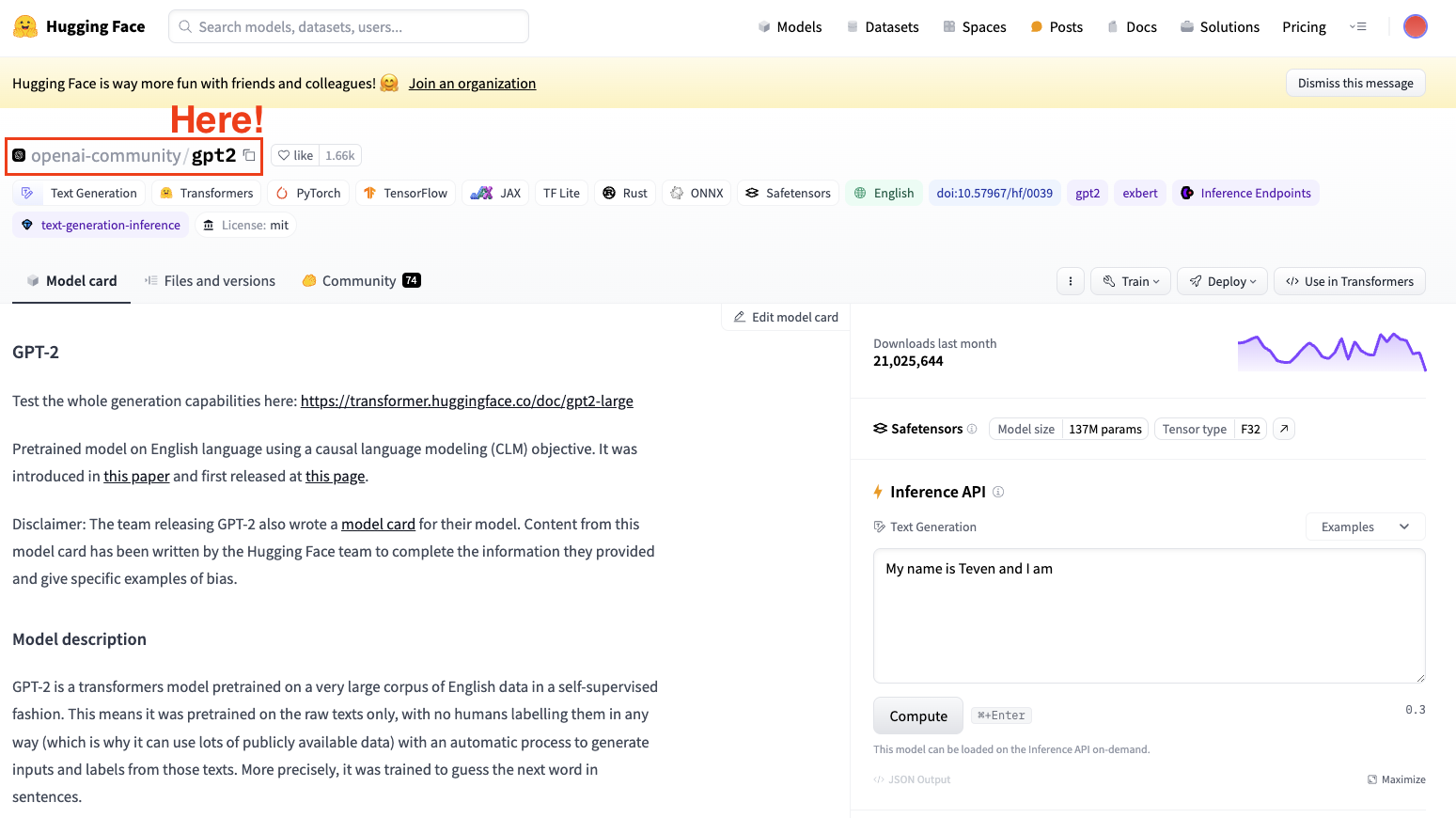
Ảnh chụp màn hình Hugging Face Datasets Hub. Chọn mô hình GPT2 của OpenAI.
Luôn ghi nhớ chọn kiến trúc mô hình phù hợp với tác vụ của bạn.
Bây giờ chúng ta đã có mô hình, cần có dữ liệu chất lượng tốt để làm việc, và đây chính là lúc thư viện datasets phát huy tác dụng.
Trong trường hợp của tôi, tôi sẽ dùng thư viện datasets của Hugging Face để nhập một tập dữ liệu chứa các tweet được phân theo cảm xúc (Tích cực, Trung lập hoặc Tiêu cực).
from datasets import load_dataset
dataset = load_dataset("mteb/tweet_sentiment_extraction")
df = pd.DataFrame(dataset['train'])
Nếu chúng ta kiểm tra tập dữ liệu vừa tải, đây là tập dữ liệu có một phần cho huấn luyện và một phần cho kiểm thử. Nếu chuyển phần huấn luyện sang dataframe, nó sẽ trông như sau.

Tập dữ liệu sẽ sử dụng.
Giờ chúng ta đã có tập dữ liệu, cần một tokenizer để chuẩn bị dữ liệu cho mô hình xử lý.
Vì LLM làm việc với token, chúng ta cần một tokenizer để xử lý tập dữ liệu. Để xử lý tập dữ liệu trong một bước, hãy dùng phương thức map của Datasets để áp dụng một hàm tiền xử lý lên toàn bộ tập dữ liệu.
Đó là lý do bước thứ hai là nạp một Tokenizer đã huấn luyện sẵn và tokenize tập dữ liệu để có thể dùng cho fine-tuning.
from transformers import GPT2Tokenizer
# Loading the dataset to train our model
dataset = load_dataset("mteb/tweet_sentiment_extraction")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)THÊM: Để giảm yêu cầu xử lý, chúng ta có thể tạo một tập con nhỏ hơn của toàn bộ dữ liệu để fine-tuning mô hình. Tập huấn luyện sẽ dùng để fine-tuning mô hình, trong khi tập kiểm thử sẽ dùng để đánh giá.
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))Bắt đầu bằng cách nạp mô hình và chỉ định số lượng nhãn mong đợi. Từ thẻ mô tả tập dữ liệu cảm xúc Tweet, bạn biết có ba nhãn:
from transformers import GPT2ForSequenceClassification
model = GPT2ForSequenceClassification.from_pretrained("gpt2", num_labels=3)Transformers cung cấp lớp Trainer được tối ưu cho huấn luyện. Tuy nhiên, phương thức này không bao gồm cách đánh giá mô hình. Vì vậy, trước khi bắt đầu huấn luyện, chúng ta sẽ cần truyền cho Trainer một hàm để đánh giá hiệu suất mô hình.
import evaluate
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)Bước cuối cùng là thiết lập các tham số huấn luyện và khởi động quá trình huấn luyện. Thư viện Transformers có lớp Trainer, hỗ trợ nhiều tùy chọn và tính năng huấn luyện như logging, tích lũy gradient và tính toán hỗn hợp. Trước tiên, chúng ta xác định tham số huấn luyện cùng chiến lược đánh giá. Khi mọi thứ đã sẵn sàng, ta có thể dễ dàng huấn luyện mô hình chỉ với lệnh train().
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="test_trainer",
#evaluation_strategy="epoch",
per_device_train_batch_size=1, # Reduce batch size here
per_device_eval_batch_size=1, # Optionally, reduce for evaluation as well
gradient_accumulation_steps=4
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
Sau khi huấn luyện, hãy đánh giá hiệu suất mô hình trên tập xác thực hoặc kiểm thử. Một lần nữa, lớp trainer đã có sẵn phương thức evaluate để xử lý việc này.
import evaluate
trainer.evaluate()
Đây là các bước cơ bản nhất để thực hiện fine-tuning bất kỳ LLM nào. Hãy nhớ rằng fine-tuning một LLM đòi hỏi rất nhiều tài nguyên tính toán và máy tính cá nhân của bạn có thể không đủ mạnh để thực hiện.
Bạn có thể học cách fine-tuning các LLM mạnh mẽ hơn trực tiếp trên giao diện của OpenAI theo hướng dẫn này về Cách Fine-Tuning GPT 3.5.
Để đảm bảo fine-tuning thành công, hãy cân nhắc các thực tiễn sau:
Chất lượng của tập dữ liệu fine-tuning ảnh hưởng đáng kể đến hiệu suất của mô hình. Chúng ta đều biết câu:
“Rác vào, rác ra”
Vì vậy, hãy luôn đảm bảo dữ liệu sạch, liên quan và đủ lớn.
Fine-tuning thường là một quá trình dài cần lặp lại nhiều lần. Luôn thử nghiệm nhiều thiết lập cho tốc độ học, kích thước batch và số epoch huấn luyện để tìm cấu hình tốt nhất cho dự án của bạn.
Các điều chỉnh chính xác là chìa khóa để đảm bảo mô hình học hiệu quả và thích ứng tốt với dữ liệu chưa thấy, tránh rơi vào bẫy overfitting.
Thường xuyên đánh giá tiến độ của mô hình trong quá trình huấn luyện để theo dõi hiệu quả và áp dụng các điều chỉnh cần thiết. Điều này bao gồm việc đánh giá hiệu suất mô hình bằng một tập xác thực riêng biệt trong suốt thời gian huấn luyện.
Việc đánh giá như vậy rất quan trọng để xác định mức độ hoàn thành tác vụ và khả năng mô hình bị overfitting vào tập huấn luyện. Dựa trên kết quả từ giai đoạn xác thực, có thể điều chỉnh khi cần để tối ưu hóa hiệu suất.
Fine-tuning đôi khi có thể dẫn đến kết quả không tối ưu. Hãy cảnh giác với các cạm bẫy sau:
Sử dụng tập dữ liệu nhỏ để huấn luyện hoặc kéo dài số epoch quá mức có thể dẫn đến overfitting. Thường biểu hiện ở việc mô hình đạt độ chính xác cao trên tập huấn luyện nhưng thất bại khi khái quát hóa sang dữ liệu mới.
Ngược lại, huấn luyện không đủ hoặc tốc độ học quá thấp có thể dẫn tới underfitting, khi mô hình không học đủ tốt về tác vụ.
Trong quá trình fine-tuning cho một tác vụ cụ thể, có nguy cơ mô hình đánh mất kiến thức tổng quát ban đầu. Vấn đề này, gọi là quên thảm họa, có thể làm suy giảm khả năng của mô hình trong việc thực hiện tốt nhiều tác vụ xử lý ngôn ngữ tự nhiên.
Luôn đảm bảo các tập dữ liệu huấn luyện và xác thực tách biệt và không có sự trùng lặp, vì điều này có thể tạo ra chỉ số hiệu suất cao sai lệch.
RAG kết hợp thế mạnh của mô hình truy hồi (retrieval) và mô hình sinh (generative). Trong RAG, thành phần truy hồi sẽ tìm kiếm trong một cơ sở dữ liệu hoặc kho tri thức lớn để tìm thông tin phù hợp dựa trên truy vấn đầu vào. Thông tin được truy hồi sau đó được mô hình sinh sử dụng để tạo ra phản hồi chính xác và phù hợp với ngữ cảnh hơn. Các lợi ích chính của RAG bao gồm:
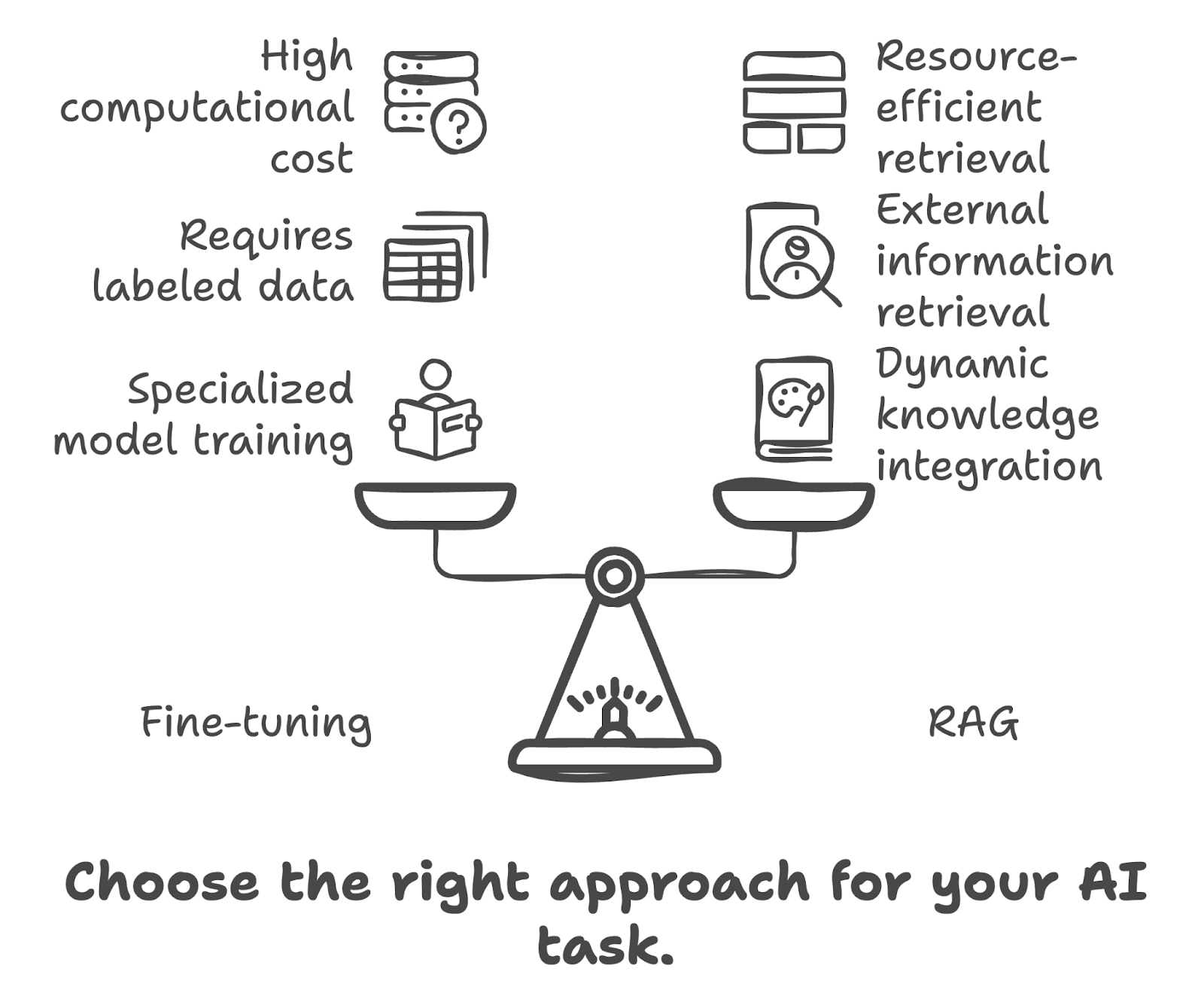
Khi quyết định dùng fine-tuning hay RAG, hãy cân nhắc các yếu tố sau:
Bắt tay vào hành trình fine-tuning các mô hình ngôn ngữ lớn sẽ mở ra một thế giới cơ hội cho các ứng dụng AI.
Bằng cách hiểu và áp dụng các khái niệm, thực tiễn và lưu ý đã nêu, bạn có thể hiệu quả điều chỉnh các mô hình mạnh mẽ này để đáp ứng nhu cầu cụ thể, đồng thời khai mở toàn bộ tiềm năng của chúng.
Để tiếp tục học về fine-tuning, tôi khuyến khích bạn thực hiện các bài fine-tuning nâng cao hơn. Bạn có thể bắt đầu với khóa học Khái niệm LLM của DataCamp, bao quát nhiều phương pháp huấn luyện chủ chốt và nghiên cứu mới nhất. Một số nguồn tốt khác để theo dõi gồm:
Bắt đầu Hành trình AI của Bạn ngay hôm nay!
Courses
Courses
Courses