
Kurs
Konzepte großer Sprachmodelle (LLMs)
2 Std.
99.8K
In den letzten anderthalb Jahren hat sich der Bereich der Verarbeitung natürlicher Sprache (NLP) durch die Popularisierung von Large Language Models (LLMs) stark verändert. Die natürlichen Sprachkenntnisse, die diese Modelle mitbringen, haben Anwendungen ermöglicht, die noch vor ein paar Jahren unmöglich schienen.
LLMs verschieben die Grenzen dessen, was bisher als machbar galt, mit Fähigkeiten, die von der Sprachübersetzung bis hin zur Stimmungsanalyse und Texterstellung reichen.
Wir alle wissen jedoch, dass die Ausbildung solcher Modelle zeitaufwändig und teuer ist. Aus diesem Grund ist die Feinabstimmung großer Sprachmodelle wichtig, um diese fortschrittlichen Algorithmen auf bestimmte Aufgaben oder Bereiche zuzuschneiden.
Dieser Prozess verbessert die Leistung des Modells bei speziellen Aufgaben und erweitert seine Anwendbarkeit in verschiedenen Bereichen erheblich. Das bedeutet, dass wir die Natural Language Processing-Kapazitäten von vortrainierten und Open-Source-LLMs nutzen und sie weiter trainieren können, um unsere spezifischen Aufgaben zu erfüllen.
Heute erforschen wir das Wesen von vortrainierten Sprachmodellen und gehen näher auf den Feinabstimmungsprozess ein.
Gehen wir also durch die praktischen Schritte zur Feinabstimmung eines Modells wie GPT-2 mit Hugging Face.
Das Sprachmodell ist eine Art maschineller Lernalgorithmus, der das nächste Wort in einem Satz anhand der vorangegangenen Segmente vorhersagt. Sie basiert auf der Transformers-Architektur, die in unserem Artikel über die Funktionsweise von Transformers ausführlich erklärt wird .
Vorgefertigte Sprachmodelle wie GPT (Generative Pre-trained Transformer) werden auf großen Mengen von Textdaten trainiert. Dies ermöglicht es den LLMs, die grundlegenden Prinzipien der Verwendung von Wörtern und ihrer Anordnung in der natürlichen Sprache zu verstehen.

Bild vom Autor. LLM-Eingang und -Ausgang.
Das Wichtigste ist, dass diese Modelle nicht nur gut darin sind, natürliche Sprache zu verstehen, sondern auch in der Lage sind, auf der Grundlage der Eingaben, die sie erhalten, menschenähnlichen Text zu erzeugen.
Und was ist das Beste daran?
Diese Modelle sind bereits über APIs für die breite Masse zugänglich. Wenn du lernen willst, wie du die leistungsfähigsten LLMs von OpenAI nutzen kannst, kannst du das mit diesem Spickzettel über die API von OpenAI tun.
Bei der Feinabstimmung wird ein bereits trainiertes Modell auf einem domänenspezifischen Datensatz weiter trainiert.
Die meisten LLM-Modelle haben heute eine sehr gute globale Leistung, versagen aber bei spezifischen aufgabenorientierten Problemen. Der Feinabstimmungsprozess bietet erhebliche Vorteile, wie z.B. einen geringeren Rechenaufwand und die Möglichkeit, modernste Modelle zu nutzen, ohne sie von Grund auf neu erstellen zu müssen.
Transformers ermöglichen den Zugriff auf eine umfangreiche Sammlung von vortrainierten Modellen, die für verschiedene Aufgaben geeignet sind. Die Feinabstimmung dieser Modelle ist ein entscheidender Schritt, um die Fähigkeit des Modells zu verbessern, bestimmte Aufgaben wie Stimmungsanalyse, Fragenbeantwortung oder Dokumentenzusammenfassung mit höherer Genauigkeit durchzuführen.
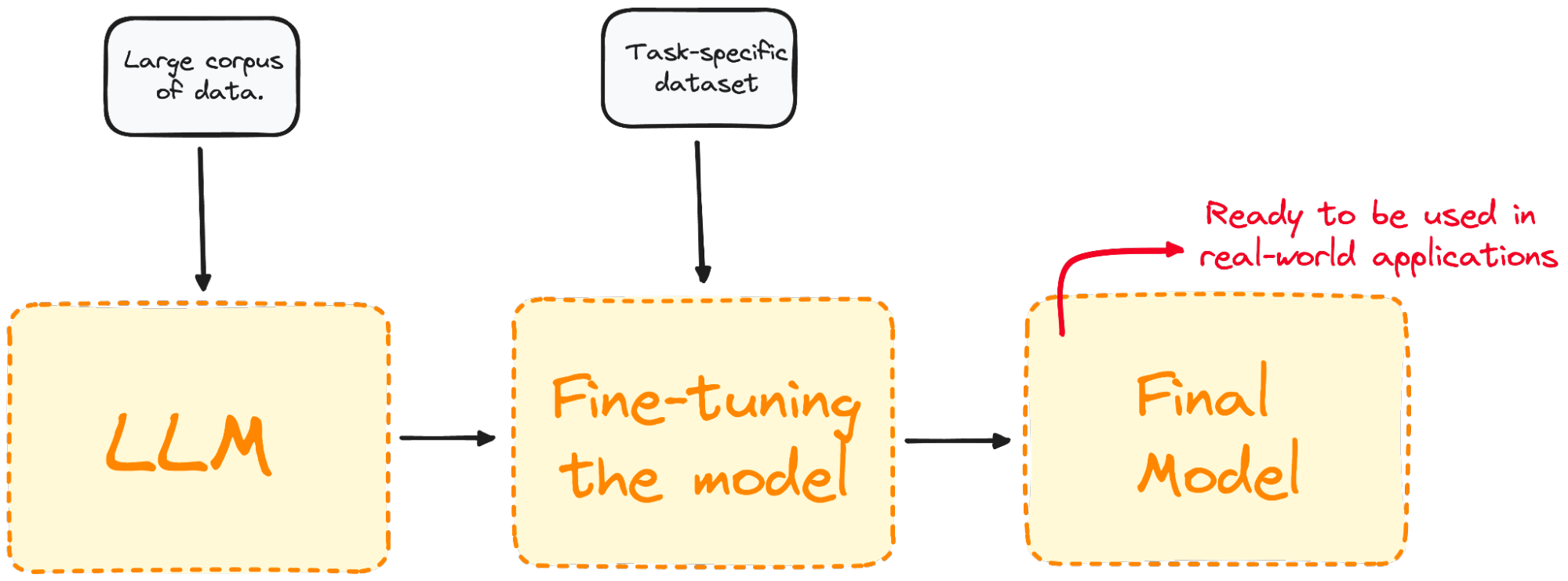
Bild vom Autor. Visualisierung des Fine-Tuning-Prozesses.
Durch die Feinabstimmung wird das Modell so angepasst, dass es für bestimmte Aufgaben besser geeignet ist, wodurch es in der Praxis effektiver und vielseitiger eingesetzt werden kann. Dieser Prozess ist wichtig, um ein bestehendes Modell auf eine bestimmte Aufgabe oder einen bestimmten Bereich zuzuschneiden.
Ob du eine Feinabstimmung vornehmen solltest, hängt von deinen Zielen ab, die in der Regel von dem jeweiligen Bereich oder der Aufgabe abhängen.
Das Feintuning kann auf verschiedene Arten angegangen werden, die vor allem von den Schwerpunkten und spezifischen Zielen abhängen.
Der einfachste und gängigste Ansatz für die Feinabstimmung. Das Modell wird dann auf einem gelabelten Datensatz trainiert, der für die jeweilige Aufgabe spezifisch ist, z. B. Textklassifizierung oder Named-Entity-Erkennung.
Wir würden unser Modell zum Beispiel auf einem Datensatz trainieren, der Textproben enthält, die für die Sentiment-Analyse mit den entsprechenden Gefühlen gekennzeichnet sind.
Es gibt einige Fälle, in denen es unpraktisch ist, einen großen markierten Datensatz zu sammeln. Das Few-Shot-Lernen versucht, dieses Problem zu lösen, indem es zu Beginn der Eingabeaufforderungen einige Beispiele (oder Aufnahmen) der geforderten Aufgabe liefert. Das hilft dem Modell, einen besseren Kontext für die Aufgabe zu haben, ohne dass ein umfangreicher Feinabstimmungsprozess erforderlich ist.
Obwohl alle Feinabstimmungstechniken eine Form des Transferlernens sind, zielt diese Kategorie speziell darauf ab, dass ein Modell eine andere Aufgabe ausführen kann als die, für die es ursprünglich trainiert wurde. Die Hauptidee ist, das Wissen, das das Modell aus einem großen, allgemeinen Datensatz gewonnen hat, zu nutzen und auf eine spezifischere oder verwandte Aufgabe anzuwenden.
Bei dieser Art der Feinabstimmung wird versucht, das Modell so anzupassen, dass es Texte versteht und erzeugt, die für einen bestimmten Bereich oder eine bestimmte Branche spezifisch sind. Das Modell wird anhand eines Datensatzes mit Texten aus der Zieldomäne feinabgestimmt, um seinen Kontext und sein Wissen über domänenspezifische Aufgaben zu verbessern.
Um zum Beispiel einen Chatbot für eine medizinische App zu entwickeln, würde das Modell mit Krankenakten trainiert werden, um seine Sprachverständnisfähigkeiten an den Gesundheitsbereich anzupassen.
Code aus diesem Tutorial online ausführen und bearbeiten
Code ausführenWir wissen bereits, dass das Feintuning ein Prozess ist, bei dem man ein bereits trainiertes Modell nimmt und seine Parameter aktualisiert, indem man es auf einem für deine Aufgabe spezifischen Datensatz trainiert. Veranschaulichen wir uns dieses Konzept also anhand eines echten Modells.
Stell dir vor, wir arbeiten mit GPT-2, aber wir stellen fest, dass es ziemlich schlecht darin ist, die Stimmung von Tweets zu erkennen.
Eine Frage, die sich natürlich aufdrängt, ist: Können wir etwas tun, um seine Leistung zu verbessern?
Wir können uns die Feinabstimmung zunutze machen, indem wir unser vortrainiertes GPT-2-Modell aus dem Hugging Face-Modell mit einem Datensatz trainieren, der Tweets und die dazugehörigen Stimmungen enthält, damit sich die Leistung verbessert. Hier ist ein einfaches Beispiel für die Feinabstimmung eines Modells zur Sequenzklassifizierung:
Für die Feinabstimmung eines Modells müssen wir immer ein bereits trainiertes Modell im Kopf haben. In unserem Fall werden wir eine einfache Feinabstimmung mit GPT-2 durchführen.
Screenshot des Hugging Face Datasets Hub. Wähle das GPT2-Modell von OpenAI.
Denke immer daran, eine für deine Aufgabe geeignete Modellarchitektur auszuwählen.
Jetzt, wo wir unser Modell haben, brauchen wir Daten von guter Qualität, mit denen wir arbeiten können, und genau hier kommt die datasets Bibliothek ins Spiel.
In meinem Fall verwende ich die Hugging Face Datasets Library, um einen Datensatz mit Tweets zu importieren, die nach ihrer Stimmung (positiv, neutral oder negativ) segmentiert sind.
from datasets import load_dataset
dataset = load_dataset("mteb/tweet_sentiment_extraction")
df = pd.DataFrame(dataset['train'])
Wenn wir uns den Datensatz ansehen, den wir gerade heruntergeladen haben, ist es ein Datensatz, der eine Teilmenge zum Trainieren und eine Teilmenge zum Testen enthält. Wenn wir die Trainingsuntermenge in einen Datenrahmen umwandeln, sieht er wie folgt aus.

Der zu verwendende Datensatz.
Jetzt, wo wir unseren Datensatz haben, brauchen wir einen Tokenizer, um ihn für das Parsen durch unser Modell vorzubereiten.
Da LLMs mit Token arbeiten, benötigen wir einen Tokenizer, um den Datensatz zu verarbeiten. Um deinen Datensatz in einem Schritt zu verarbeiten, wendest du mit der Methode Datensätze zuordnen eine Vorverarbeitungsfunktion auf den gesamten Datensatz an.
Deshalb laden wir im zweiten Schritt einen vortrainierten Tokenizer und tokenisieren unseren Datensatz, damit er für die Feinabstimmung verwendet werden kann.
from transformers import GPT2Tokenizer
# Loading the dataset to train our model
dataset = load_dataset("mteb/tweet_sentiment_extraction")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)BONUS: Um unsere Anforderungen an die Verarbeitung zu verbessern, können wir eine kleinere Teilmenge des gesamten Datensatzes erstellen, um unser Modell fein abzustimmen. Die Trainingsmenge wird zur Feinabstimmung unseres Modells verwendet, während die Testmenge dazu dient, es zu bewerten.
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))Lade zunächst dein Modell und gib die Anzahl der erwarteten Beschriftungen an. Aus der Karte des Tweet-Sentiment-Datensatzes weißt du, dass es drei Labels gibt:
from transformers import GPT2ForSequenceClassification
model = GPT2ForSequenceClassification.from_pretrained("gpt2", num_labels=3)Transformers bietet eine für die Ausbildung optimierte Trainerklasse. Diese Methode beinhaltet jedoch nicht, wie das Modell zu bewerten ist. Deshalb müssen wir vor Beginn des Trainings Trainer eine Funktion übergeben, um die Leistung unseres Modells zu bewerten.
import evaluate
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)Unser letzter Schritt besteht darin, die Trainingsargumente festzulegen und den Trainingsprozess zu starten. Die Transformers-Bibliothek enthält die Klasse Trainer, die eine Vielzahl von Trainingsoptionen und Funktionen wie Protokollierung, Gradientenakkumulation und gemischte Präzision unterstützt. Zuerst definieren wir die Trainingsargumente zusammen mit der Bewertungsstrategie. Sobald alles definiert ist, können wir das Modell ganz einfach mit dem Befehl train() trainieren.
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="test_trainer",
#evaluation_strategy="epoch",
per_device_train_batch_size=1, # Reduce batch size here
per_device_eval_batch_size=1, # Optionally, reduce for evaluation as well
gradient_accumulation_steps=4
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
Nach dem Training bewertest du die Leistung des Modells anhand eines Validierungs- oder Testsatzes. Auch hier enthält die Trainerklasse bereits eine Evaluierungsmethode, die sich um diese Aufgabe kümmert.
import evaluate
trainer.evaluate()
Dies sind die grundlegendsten Schritte, um eine Feinabstimmung eines LLM durchzuführen. Denk daran, dass die Feinabstimmung eines LLM sehr rechenintensiv ist und dein lokaler Computer dafür möglicherweise nicht genug Leistung hat.
Du kannst lernen, wie du leistungsstärkere LLMs direkt auf der OpenAI-Oberfläche feinabstimmen kannst, indem du diesem Tutorial über die Feinabstimmung von GPT 3.5 folgst .
Beginne deine KI-Reise noch heute!
Kurs
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Nisha Arya Ahmed
15 Min.
Tutorial
Mark Pedigo
Tutorial
Matt Crabtree
Tutorial
Javier Canales Luna
