
Cours
Concepts des grands modèles de langage (LLM)
2 h
99.8K
Depuis un an et demi, le domaine du traitement du langage naturel (NLP) a connu une transformation significative grâce à la popularisation des grands modèles de langage (LLM). Les compétences en langage naturel que présentent ces modèles ont permis des applications qui semblaient impossibles à réaliser il y a quelques années.
Les LLM repoussent les limites de ce qui était auparavant considéré comme réalisable, avec des capacités allant de la traduction linguistique à l'analyse des sentiments et à la génération de textes.
Cependant, nous savons tous que la formation de ces modèles est longue et coûteuse. C'est pourquoi il est important d'affiner les grands modèles linguistiques pour adapter ces algorithmes avancés à des tâches ou domaines spécifiques.
Ce processus améliore les performances du modèle pour les tâches spécialisées et élargit considérablement son applicabilité dans différents domaines. Cela signifie que nous pouvons tirer parti de la capacité de traitement du langage naturel des LLM pré-entraînés et open-source et les former davantage pour qu'ils effectuent nos tâches spécifiques.
Aujourd'hui, explorez l'essence des modèles linguistiques pré-entraînés et approfondissez le processus de réglage fin.
Passons donc en revue les étapes pratiques pour affiner un modèle tel que GPT-2 à l'aide de Hugging Face.
Le modèle linguistique est un type d'algorithme d'apprentissage automatique conçu pour prévoir le mot suivant dans une phrase, en s'appuyant sur les segments précédents. Il est basé sur l'architecture Transformers, qui est expliquée en détail dans notre article sur le fonctionnement des Transformers.
Les modèles linguistiques préformés, tels que le GPT (Generative Pre-trained Transformer), sont formés sur de grandes quantités de données textuelles. Cela permet aux LLM de saisir les principes fondamentaux qui régissent l'utilisation des mots et leur disposition dans la langue naturelle.

Image par l'auteur. Entrée et sortie du LLM.
Le plus important est que ces modèles sont non seulement capables de comprendre le langage naturel, mais aussi de générer des textes semblables à ceux d'un humain sur la base des données qu'ils reçoivent.
Et le meilleur dans tout ça ?
Ces modèles sont déjà accessibles au plus grand nombre grâce aux API. Si vous souhaitez apprendre à tirer parti des LLM les plus puissants d'OpenAI, vous pouvez le faire en suivant cet aide-mémoire sur l'API d'OpenAI.
La mise au point est le processus qui consiste à prendre un modèle pré-entraîné et à l'entraîner de nouveau sur un ensemble de données spécifiques à un domaine.
La plupart des modèles LLM actuels ont une très bonne performance globale mais échouent dans des problèmes spécifiques orientés vers une tâche. Le processus de mise au point offre des avantages considérables, notamment la réduction des frais de calcul et la possibilité d'utiliser des modèles de pointe sans avoir à en construire un à partir de zéro.
Les transformateurs permettent d'accéder à une vaste collection de modèles pré-entraînés adaptés à diverses tâches. La mise au point de ces modèles est une étape cruciale pour améliorer la capacité du modèle à effectuer des tâches spécifiques, telles que l'analyse des sentiments, la réponse aux questions ou le résumé de documents, avec une plus grande précision.
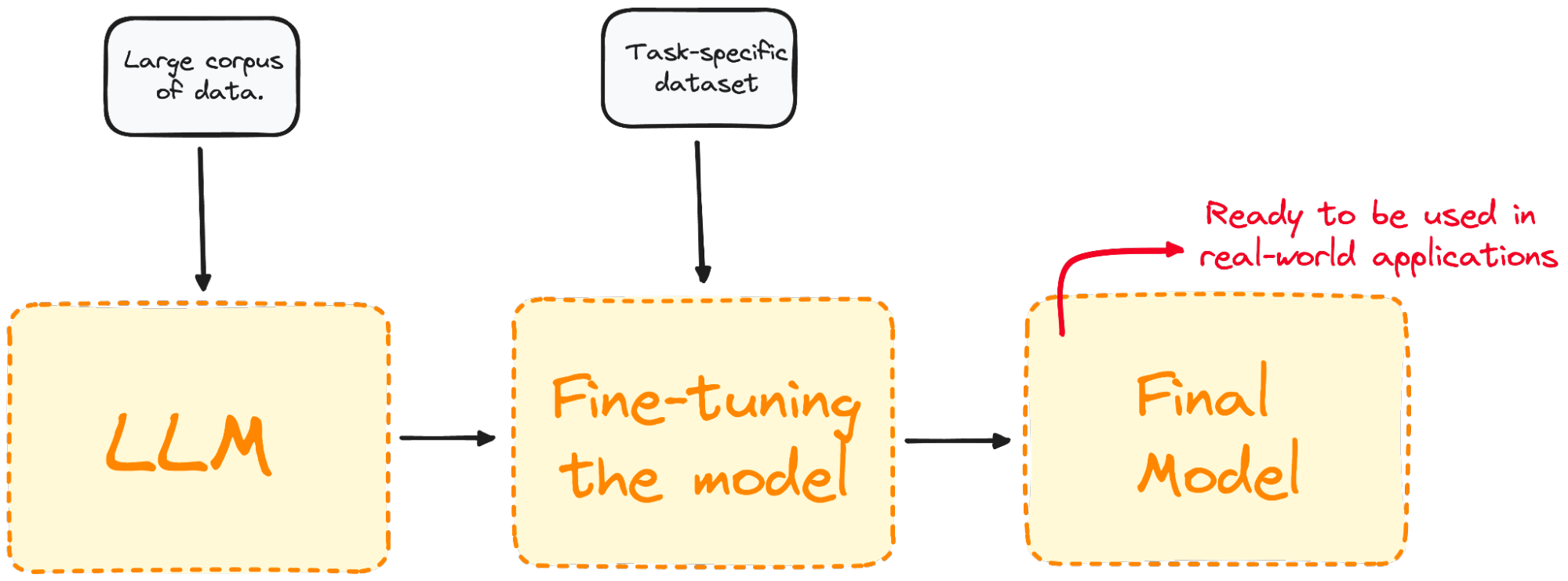
Image par l'auteur. Visualisation du processus de mise au point.
Le réglage fin permet d'adapter le modèle à des tâches spécifiques, ce qui le rend plus efficace et plus polyvalent dans les applications du monde réel. Ce processus est essentiel pour adapter un modèle existant à une tâche ou à un domaine particulier.
La décision de procéder à un réglage fin dépend de vos objectifs, qui varient généralement en fonction du domaine spécifique ou de la tâche à accomplir.
La mise au point peut être abordée de plusieurs manières, en fonction principalement de son objectif principal et de ses buts spécifiques.
L'approche la plus simple et la plus courante de la mise au point. Le modèle est ensuite entraîné sur un ensemble de données étiquetées spécifique à la tâche cible à effectuer, comme la classification de textes ou la reconnaissance d'entités nommées.
Par exemple, nous entraînerons notre modèle sur un ensemble de données contenant des échantillons de texte étiquetés avec leur sentiment correspondant pour l'analyse du sentiment.
Dans certains cas, la collecte d'un grand ensemble de données étiquetées n'est pas pratique. L'apprentissage à partir de quelques images tente de remédier à ce problème en fournissant quelques exemples (ou images) de la tâche requise au début des invites de saisie. Cela permet au modèle d'avoir un meilleur contexte de la tâche sans avoir besoin d'un processus d'ajustement approfondi.
Même si toutes les techniques de réglage fin sont une forme d'apprentissage par transfert, cette catégorie vise spécifiquement à permettre à un modèle d'effectuer une tâche différente de celle pour laquelle il a été initialement formé. L'idée principale est d'exploiter les connaissances que le modèle a acquises à partir d'un vaste ensemble de données générales et de les appliquer à une tâche plus spécifique ou connexe.
Ce type de mise au point vise à adapter le modèle pour qu'il comprenne et génère des textes spécifiques à un domaine ou à un secteur d'activité particulier. Le modèle est affiné sur un ensemble de données composé de textes du domaine cible afin d'améliorer son contexte et sa connaissance des tâches spécifiques au domaine.
Par exemple, pour créer un chatbot destiné à une application médicale, le modèle sera entraîné à partir de dossiers médicaux, afin d'adapter ses capacités de compréhension du langage au domaine de la santé.
Exécutez et modifiez le code de ce tutoriel en ligne
Exécuter le codeNous savons déjà que le réglage fin est le processus qui consiste à prendre un modèle pré-entraîné et à mettre à jour ses paramètres en s'entraînant sur un ensemble de données spécifique à votre tâche. Nous allons donc illustrer ce concept en affinant un modèle réel.
Imaginons que nous travaillions avec GPT-2, mais nous constatons qu'il est assez mauvais pour déduire les sentiments des tweets.
La question qui vient naturellement à l'esprit est la suivante : Pouvons-nous faire quelque chose pour améliorer ses performances ?
Nous pouvons tirer parti du réglage fin en entraînant notre modèle GPT-2 pré-entraîné à partir du modèle Hugging Face avec un ensemble de données contenant des tweets et leurs sentiments correspondants afin d'améliorer les performances. Voici un exemple de base pour affiner un modèle de classification de séquences :
Pour affiner un modèle, nous devons toujours avoir à l'esprit un modèle pré-entraîné. Dans notre cas, nous allons effectuer quelques réglages simples à l'aide de GPT-2.
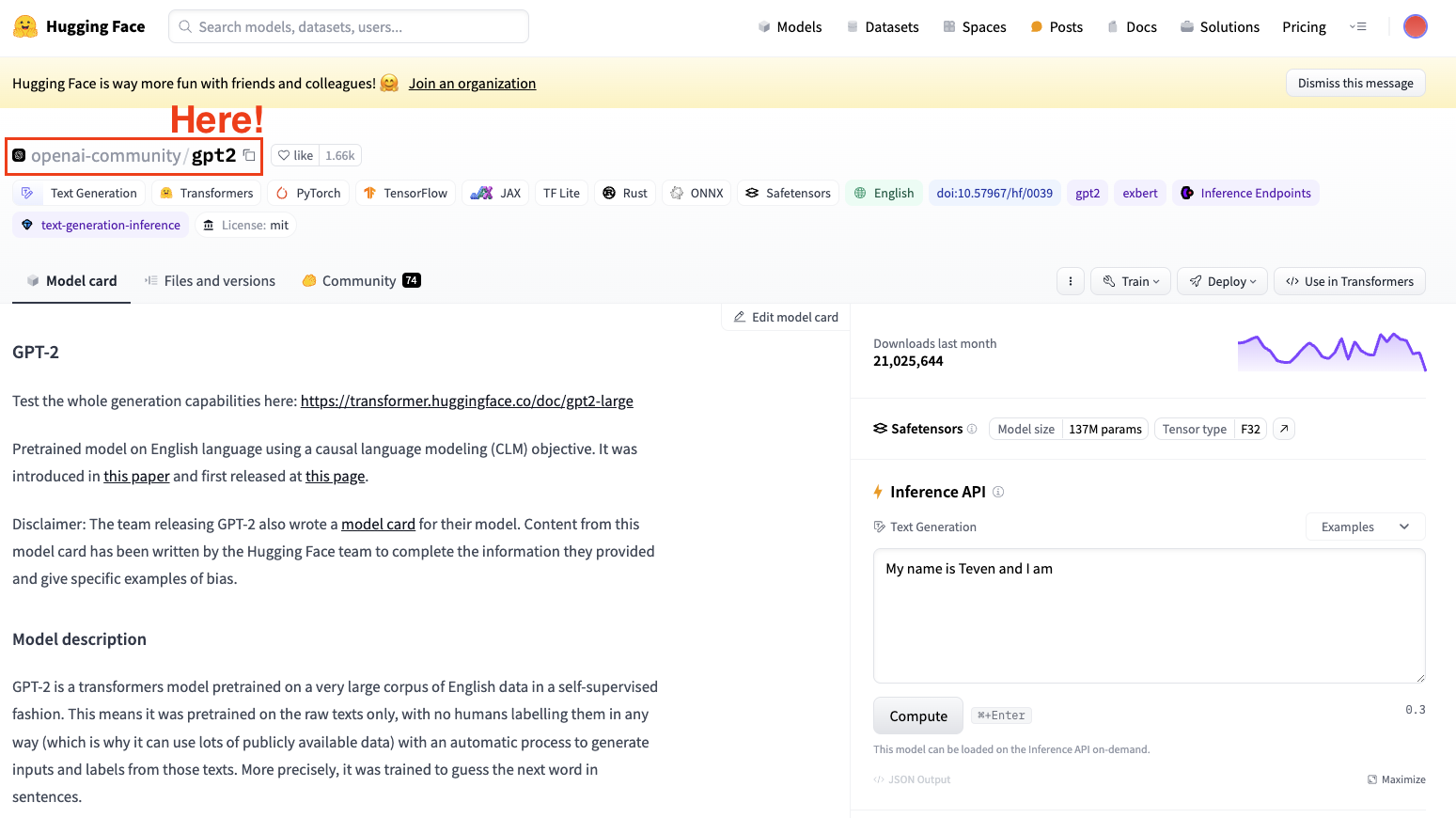
Capture d'écran de Hugging Face Datasets Hub. Sélection du modèle GPT2 d'OpenAI.
Gardez toujours à l'esprit de sélectionner un modèle d'architecture adapté à votre tâche.
Maintenant que nous avons notre modèle, nous avons besoin de données de bonne qualité pour travailler, et c'est précisément là que la bibliothèque datasets entre en jeu.
Dans mon cas, j'utiliserai la bibliothèque Hugging Face datasets pour importer un ensemble de données contenant des tweets segmentés en fonction de leur sentiment (positif, neutre ou négatif).
from datasets import load_dataset
dataset = load_dataset("mteb/tweet_sentiment_extraction")
df = pd.DataFrame(dataset['train'])
Si nous vérifions l'ensemble de données que nous venons de télécharger, il s'agit d'un ensemble de données contenant un sous-ensemble pour l'entraînement et un sous-ensemble pour le test. Si nous convertissons le sous-ensemble de formation en un cadre de données, il se présente comme suit.

L'ensemble des données à utiliser.
Maintenant que nous avons notre jeu de données, nous avons besoin d'un tokenizer pour le préparer à être analysé par notre modèle.
Comme les LLM travaillent avec des jetons, nous avons besoin d'un tokenizer pour traiter l'ensemble des données. Pour traiter votre ensemble de données en une seule étape, utilisez la méthode Datasets map pour appliquer une fonction de prétraitement à l'ensemble de l'ensemble de données.
C'est pourquoi la deuxième étape consiste à charger un tokenizer pré-entraîné et à tokeniser notre ensemble de données afin qu'il puisse être utilisé pour un réglage fin.
from transformers import GPT2Tokenizer
# Loading the dataset to train our model
dataset = load_dataset("mteb/tweet_sentiment_extraction")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)BONUS : Pour améliorer nos exigences en matière de traitement, nous pouvons créer un sous-ensemble plus petit de l'ensemble des données afin d'affiner notre modèle. L'ensemble de formation sera utilisé pour affiner notre modèle, tandis que l'ensemble de test sera utilisé pour l'évaluer.
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))Commencez par charger votre modèle et spécifiez le nombre d'étiquettes attendues. La carte de l'ensemble de données sur le sentiment du tweet vous indique qu'il y a trois étiquettes :
from transformers import GPT2ForSequenceClassification
model = GPT2ForSequenceClassification.from_pretrained("gpt2", num_labels=3)Transformers propose une classe Trainer optimisée pour la formation. Toutefois, cette méthode ne prévoit pas la manière d'évaluer le modèle. C'est pourquoi, avant de commencer notre formation, nous devrons faire passer à Trainer une fonction permettant d'évaluer les performances de notre modèle.
import evaluate
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)La dernière étape consiste à mettre en place les arguments de formation et à lancer le processus de formation. La bibliothèque Transformers contient la classe Trainer, qui prend en charge un large éventail d'options d'apprentissage et de fonctionnalités telles que l'enregistrement, l'accumulation de gradients et la précision mixte. Nous commençons par définir les arguments de formation ainsi que la stratégie d'évaluation. Une fois que tout est défini, nous pouvons facilement entraîner le modèle en utilisant la commande train().
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="test_trainer",
#evaluation_strategy="epoch",
per_device_train_batch_size=1, # Reduce batch size here
per_device_eval_batch_size=1, # Optionally, reduce for evaluation as well
gradient_accumulation_steps=4
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
Après la formation, évaluez les performances du modèle sur un ensemble de validation ou de test. Là encore, la classe du formateur contient déjà une méthode d'évaluation qui s'en charge.
import evaluate
trainer.evaluate()
Il s'agit des étapes les plus élémentaires pour effectuer un réglage fin de n'importe quel LLM. N'oubliez pas que le réglage fin d'un LLM est très exigeant en termes de calcul et que votre ordinateur local n'a peut-être pas la puissance suffisante pour le faire.
Vous pouvez apprendre à affiner des LLM plus puissants directement sur l'interface de l'OpenAI en suivant ce tutoriel sur la manière d'affiner le GPT 3.5.
Commencez dès aujourd'hui votre voyage dans l'IA !
Cours
Cours
Cours
blog
Kurtis Pykes
9 min
blog
blog
Zoumana Keita
15 min
blog
Lynn Heidmann
Tutoriel
Tutoriel
Samuel Shaibu


