
Cursus
Concepten van Large Language Models (LLMs)
2 Hr
104.1K
Het Language Model is een type machinelearning-algoritme dat is ontworpen om het volgende woord in een zin te voorspellen op basis van de voorafgaande segmenten. Het is gebaseerd op de Transformers-architectuur, die uitgebreid wordt uitgelegd in ons artikel over Hoe Transformers werken.
Voorgetrainde taalmodellen, zoals GPT (Generative Pre-trained Transformer), zijn getraind op enorme hoeveelheden tekstdata. Hierdoor kunnen LLM’s de fundamentele principes begrijpen die het gebruik van woorden en hun volgorde in natuurlijke taal bepalen.

Afbeelding door de auteur. LLM-invoer en -uitvoer.
Het belangrijkste is dat deze modellen niet alleen goed zijn in het begrijpen van natuurlijke taal, maar ook mensachtige tekst kunnen genereren op basis van de input die ze ontvangen.
En het beste van alles?
Deze modellen zijn al toegankelijk voor het grote publiek via API’s. Wil je leren hoe je de krachtigste LLM’s van OpenAI benut, volg dan deze cheatsheet over de OpenAI API.
Fine-tunen is het proces waarbij je een voorgetraind model neemt en het verder traint op een domeinspecifieke dataset.
De meeste LLM’s presteren tegenwoordig wereldwijd zeer goed, maar laten het afweten bij specifieke, taakgerichte problemen. Fine-tuning biedt aanzienlijke voordelen, waaronder lagere rekenkosten en de mogelijkheid om toonaangevende modellen te benutten zonder er zelf een vanaf nul te hoeven bouwen.
Transformers bieden toegang tot een uitgebreide verzameling voorgetrainde modellen voor uiteenlopende taken. Het fine-tunen van deze modellen is een cruciale stap om de prestaties op specifieke taken, zoals sentimentanalyse, vraagbeantwoording of samenvatten van documenten, met hogere nauwkeurigheid te verbeteren.
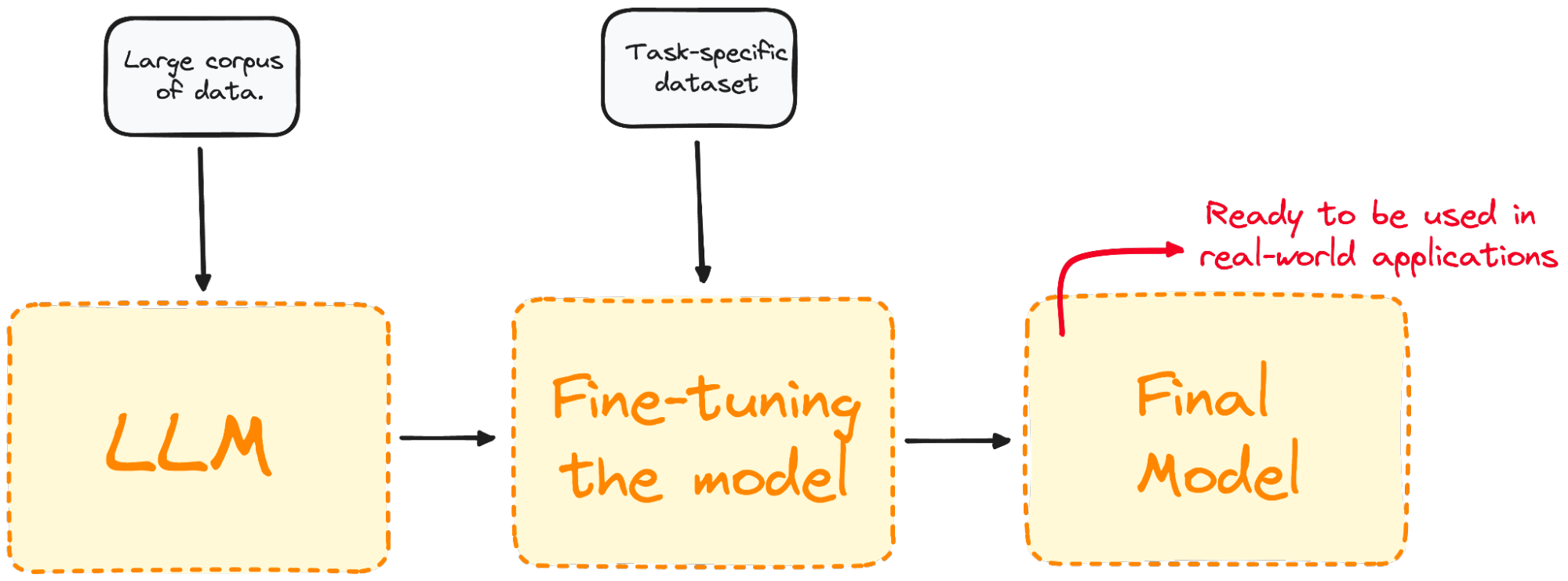
Afbeelding door de auteur. De fine-tuningprocedure visualiseren.
Fine-tuning stemt het model af voor betere prestaties op specifieke taken, waardoor het effectiever en veelzijdiger wordt in real-world toepassingen. Dit proces is essentieel om een bestaand model op een bepaalde taak of een bepaald domein af te stemmen.
Of je aan fine-tuning moet doen, hangt af van je doelen, die doorgaans variëren per specifiek domein of taak.
Fine-tuning kan op verschillende manieren worden aangepakt, afhankelijk van de focus en de specifieke doelen.
De meest eenvoudige en gebruikelijke benadering. Het model wordt verder getraind op een gelabelde dataset die specifiek is voor de doeltaak, zoals tekstclassificatie of named entity recognition.
Zo zouden we voor sentimentanalyse ons model trainen op een dataset met tekstvoorbeelden die gelabeld zijn met hun bijbehorende sentiment.
Soms is het onpraktisch om een grote gelabelde dataset te verzamelen. Few-shot learning probeert dit op te lossen door aan het begin van de inputprompts een paar voorbeelden (of shots) van de vereiste taak te geven. Dit helpt het model de taak beter te begrijpen zonder een uitgebreid fine-tuningproces.
Hoewel alle fine-tuningtechnieken een vorm van transfer learning zijn, is deze categorie er specifiek op gericht een model een andere taak te laten uitvoeren dan waarvoor het oorspronkelijk is getraind. Het idee is om de kennis die het model heeft opgedaan uit een grote, algemene dataset te benutten en toe te passen op een meer specifieke of verwante taak.
Dit type fine-tuning probeert het model te laten begrijpen en tekst te laten genereren die specifiek is voor een bepaald domein of een bepaalde sector. Het model wordt gefinetuned op een dataset met tekst uit het doeldomein om de context en kennis van domeinspecifieke taken te verbeteren.
Om bijvoorbeeld een chatbot voor een medische app te genereren, zou het model worden getraind met medische dossiers, zodat het zijn taalbegrip kan aanpassen aan het zorgdomein.
Voer de code uit deze tutorial online uit en pas 'm aan.
Code uitvoerenWe weten inmiddels dat fine-tunen het proces is waarbij je een voorgetraind model neemt en de parameters bijwerkt door te trainen op een dataset die specifiek is voor jouw taak. Laten we dit concept concreet maken door een echt model te fine-tunen.
Stel dat we met GPT-2 werken, maar merken dat het behoorlijk slecht is in het afleiden van het sentiment van tweets.
Een logische vraag is: Kunnen we iets doen om de prestaties te verbeteren?
We kunnen profiteren van fine-tuning door ons voorgetrainde GPT-2-model van Hugging Face te trainen met een dataset met tweets en hun bijbehorende sentimenten, zodat de prestaties verbeteren. Hier is een basisvoorbeeld van het fine-tunen van een model voor sequentieclassificatie:
Om een model te fine-tunen, heb je altijd een voorgetraind model nodig. In ons geval gaan we een eenvoudige fine-tuning uitvoeren met GPT-2.
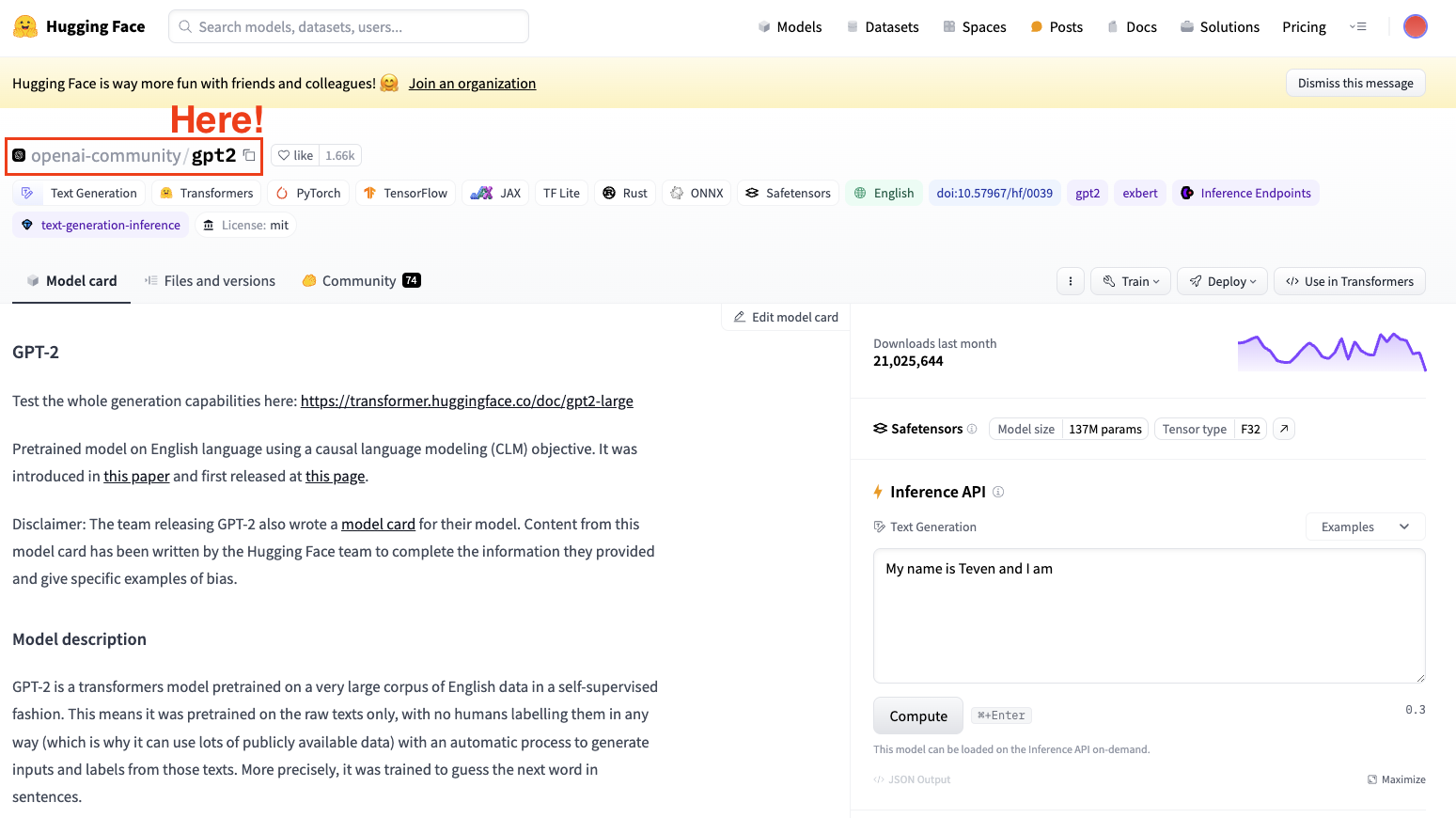
Screenshot van Hugging Face Datasets Hub. OpenAI’s GPT2-model selecteren.
Houd er altijd rekening mee dat je een modelarchitectuur kiest die bij je taak past.
Nu we ons model hebben, hebben we kwalitatief goede data nodig om mee te werken, en precies hier komt de datasets-bibliotheek van pas.
Ik gebruik de Hugging Face datasets-bibliotheek om een dataset te importeren met tweets die zijn ingedeeld naar sentiment (Positief, Neutraal of Negatief).
from datasets import load_dataset
dataset = load_dataset("mteb/tweet_sentiment_extraction")
df = pd.DataFrame(dataset['train'])
Als we de zojuist gedownloade dataset bekijken, zien we dat deze een subset voor training en een subset voor testen bevat. Als we de trainingssubset naar een dataframe omzetten, ziet die er als volgt uit.

De dataset die wordt gebruikt.
Nu we onze dataset hebben, hebben we een tokenizer nodig om deze voor te bereiden om door ons model geparsed te worden.
Omdat LLM’s met tokens werken, hebben we een tokenizer nodig om de dataset te verwerken. Gebruik de map-methode van Datasets om in één stap een preprocessfunctie op de volledige dataset toe te passen.
Daarom is de tweede stap het laden van een voorgetrainde Tokenizer en het tokenizen van onze dataset, zodat deze kan worden gebruikt voor fine-tuning.
from transformers import GPT2Tokenizer
# Loading the dataset to train our model
dataset = load_dataset("mteb/tweet_sentiment_extraction")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)BONUS: Om de verwerkingsvereisten te verlichten, kunnen we een kleinere subset van de volledige dataset maken om ons model te fine-tunen. De trainingsset wordt gebruikt om ons model te fine-tunen, terwijl de testset wordt gebruikt om het te evalueren.
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))Begin met het laden van je model en specificeer het aantal verwachte labels. Uit de datasetkaart voor Tweet-sentiment weet je dat er drie labels zijn:
from transformers import GPT2ForSequenceClassification
model = GPT2ForSequenceClassification.from_pretrained("gpt2", num_labels=3)Transformers biedt een Trainer-klasse die geoptimaliseerd is voor training. Deze methode omvat echter niet hoe je het model evalueert. Daarom moeten we, voordat we met de training beginnen, een functie meegeven aan Trainer om de prestaties van ons model te evalueren.
import evaluate
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)Onze laatste stap is het instellen van de trainingsargumenten en het starten van het trainingsproces. De Transformers-bibliotheek bevat de Trainer-klasse, die een breed scala aan trainingsopties en -functies ondersteunt, zoals logging, gradient accumulation en mixed precision. We definiëren eerst de trainingsargumenten samen met de evaluatiestrategie. Zodra alles is gedefinieerd, kunnen we het model eenvoudig trainen met het commando train().
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="test_trainer",
#evaluation_strategy="epoch",
per_device_train_batch_size=1, # Reduce batch size here
per_device_eval_batch_size=1, # Optionally, reduce for evaluation as well
gradient_accumulation_steps=4
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
Evalueer na de training de prestaties van het model op een validatie- of testset. Ook hiervoor bevat de Trainer-klasse al een evaluate-methode die dit afhandelt.
import evaluate
trainer.evaluate()
Dit zijn de meest basale stappen om een LLM te fine-tunen. Onthoud dat het fine-tunen van een LLM zeer rekenintensief is en dat je lokale computer mogelijk niet krachtig genoeg is.
Je kunt leren hoe je krachtigere LLM’s direct in de interface van OpenAI fine-tunet met deze tutorial over Fine-tunen van GPT 3.5.
Hanteer de volgende best practices om fine-tuning tot een succes te maken:
De kwaliteit van je fine-tuningdataset heeft grote invloed op de prestaties van het model. We kennen allemaal de uitspraak:
“Garbage In, Garbage Out”
Zorg er dus altijd voor dat de data schoon, relevant en voldoende groot is.
Fine-tuning is meestal een langdurig, iteratief proces. Verken altijd verschillende instellingen voor learning rates, batchgroottes en het aantal trainingsepochs om de beste setup voor je project te vinden.
Precieze afstelling is cruciaal om ervoor te zorgen dat het model efficiënt leert en goed generaliseert naar onzichtbare data, zodat overfitting wordt voorkomen.
Beoordeel de voortgang van het model regelmatig tijdens de training om de effectiviteit te volgen en noodzakelijke aanpassingen door te voeren. Dit houdt in dat je de prestaties van het model gedurende de training evalueert met een aparte validatieset.
Zo’n evaluatie is cruciaal om te bepalen hoe goed het model de taak uitvoert en of het de neiging heeft om te overfitten op de trainingsdata. Op basis van de resultaten uit de validatiefase kun je waar nodig bijsturen voor optimale prestaties.
Fine-tuning kan soms tot suboptimale resultaten leiden. Wees alert op de volgende valkuilen:
Train je met een kleine dataset of te veel epochs, dan kan overfitting ontstaan. Dit herken je vaak aan een hoge nauwkeurigheid op de trainingsdata, maar slechte generalisatie naar nieuwe data.
Omgekeerd kan onvoldoende training of een lage learning rate leiden tot underfitting, waarbij het model de taak niet goed genoeg leert.
Tijdens het fine-tunen voor een specifieke taak bestaat het risico dat het model de brede kennis die het aanvankelijk heeft opgedaan, verliest. Dit probleem, bekend als catastrophic forgetting, kan het vermogen van het model verminderen om goed te presteren op uiteenlopende NLP-taken.
Zorg er altijd voor dat trainings- en validatiedatasets gescheiden zijn en niet overlappen, omdat dit kan leiden tot misleidend hoge prestatiecijfers.
RAG combineert de sterke punten van retrieval-based modellen en generatieve modellen. In RAG zoekt een retrievercomponent in een grote database of kennisbank naar relevante informatie op basis van de inputquery. Deze opgehaalde informatie wordt vervolgens gebruikt door een generatief model om een nauwkeuriger en contextueel relevanter antwoord te produceren. Belangrijke voordelen van RAG zijn:
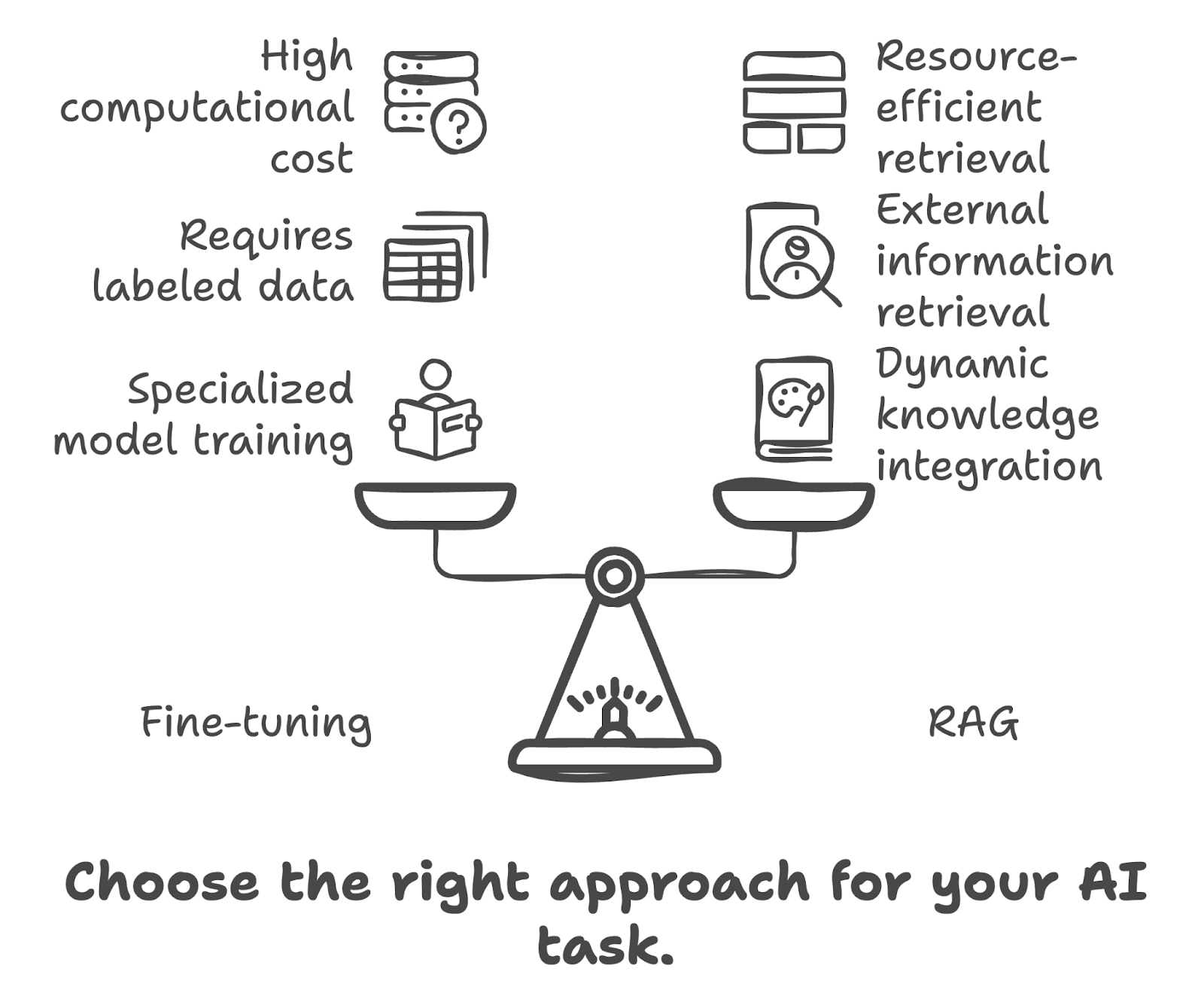
Overweeg de volgende factoren wanneer je beslist of je fine-tuning of RAG gebruikt:
Het traject van het fine-tunen van large language models opent een wereld aan mogelijkheden voor AI-toepassingen.
Door de besproken concepten, praktijken en aandachtspunten te begrijpen en toe te passen, kun je deze krachtige modellen effectief aanpassen aan specifieke behoeften en zo hun volledige potentieel ontsluiten.
Wil je blijven leren over fine-tuning, dan raad ik je sterk aan om met geavanceerdere fine-tuning aan de slag te gaan. Je kunt beginnen met DataCamp’s LLM Concepts-cursus, die veel van de belangrijkste trainingmethodologieën en het nieuwste onderzoek behandelt. Andere goede bronnen om te volgen zijn:
Begin vandaag nog aan je AI-reis!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
