
Corso
Concetti sui Large Language Models (LLM)
2 h
104.1K
Il Language Model è un tipo di algoritmo di machine learning progettato per prevedere la parola successiva in una frase, basandosi sui segmenti precedenti. Si fonda sull'architettura Transformers, spiegata in dettaglio nel nostro articolo su come funzionano i Transformer.
I modelli linguistici pre-addestrati, come GPT (Generative Pre-trained Transformer), sono addestrati su enormi quantità di dati testuali. Questo consente agli LLM di cogliere i principi fondamentali che regolano l'uso delle parole e il loro ordine nel linguaggio naturale.

Immagine dell'autore. Input e output di un LLM.
La parte più importante è che questi modelli non sono solo bravi a comprendere il linguaggio naturale, ma sono anche capaci di generare testo simile a quello umano in base all'input ricevuto.
E la cosa migliore qual è?
Questi modelli sono già accessibili a tutti tramite API. Se vuoi imparare a sfruttare gli LLM più potenti di OpenAI, puoi farlo seguendo questa cheat sheet sull'API di OpenAI.
Il fine-tuning è il processo con cui si prende un modello pre-addestrato e lo si addestra ulteriormente su un dataset specifico per un dominio.
La maggior parte degli LLM oggi ha prestazioni globali molto buone, ma fatica su problemi specifici orientati al compito. Il processo di fine-tuning offre vantaggi considerevoli, tra cui la riduzione dei costi computazionali e la possibilità di sfruttare modelli all'avanguardia senza doverne costruire uno da zero.
Transformers mette a disposizione un'ampia raccolta di modelli pre-addestrati adatti a vari compiti. Effettuare il fine-tuning di questi modelli è un passaggio cruciale per migliorarne la capacità di svolgere compiti specifici, come analisi del sentiment, question answering o sintesi di documenti, con maggiore accuratezza.
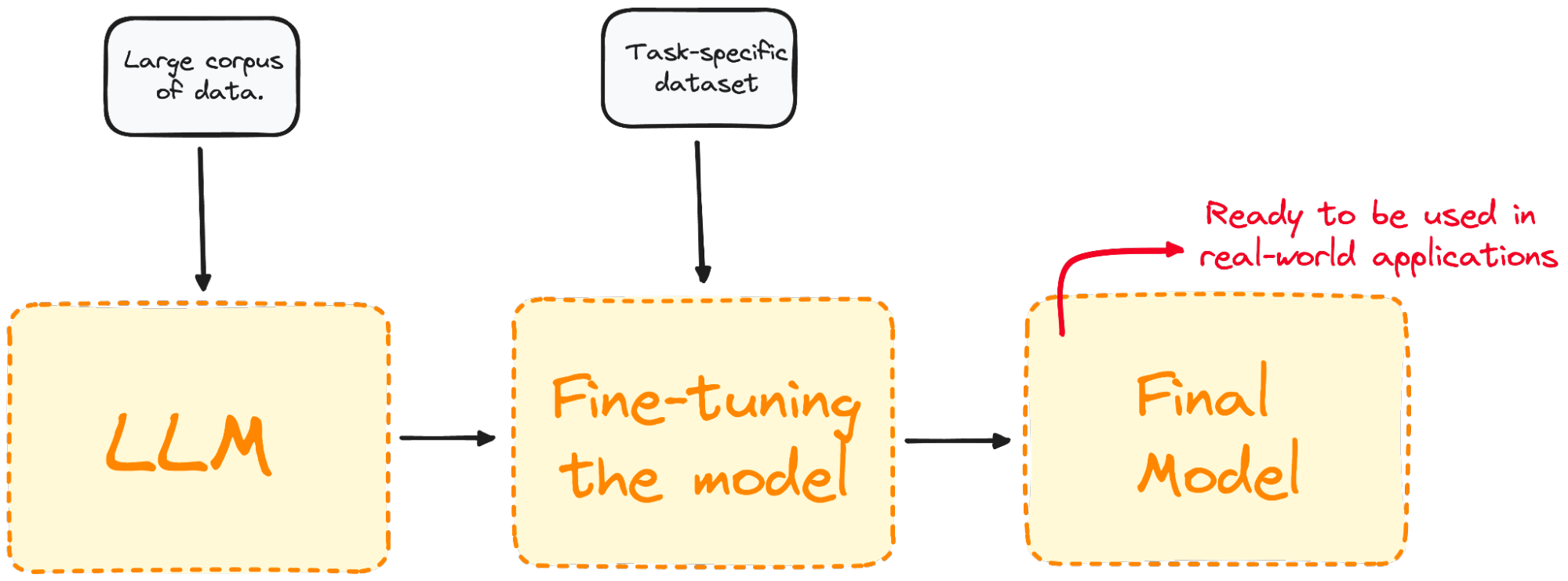
Immagine dell'autore. Visualizzazione del processo di fine-tuning.
Il fine-tuning adatta il modello per ottenere prestazioni migliori su compiti specifici, rendendolo più efficace e versatile nelle applicazioni reali. Questo processo è essenziale per adattare un modello esistente a un particolare compito o dominio.
La decisione di ricorrere o meno al fine-tuning dipende dai tuoi obiettivi, che in genere variano in base al dominio o al compito specifico.
Il fine-tuning può essere affrontato in vari modi, a seconda soprattutto del focus principale e degli obiettivi specifici.
L'approccio più semplice e comune. Il modello viene addestrato ulteriormente su un dataset etichettato specifico per il compito da svolgere, come classificazione del testo o riconoscimento di entità nominate.
Per esempio, per l'analisi del sentiment, addestreremmo il nostro modello su un dataset contenente campioni di testo etichettati con il relativo sentimento.
Ci sono casi in cui raccogliere un ampio dataset etichettato non è praticabile. Il few-shot learning affronta il problema fornendo alcuni esempi (o shot) del compito richiesto all'inizio dei prompt di input. Questo aiuta il modello ad avere un contesto migliore del compito senza un lungo processo di fine-tuning.
Anche se tutte le tecniche di fine-tuning sono una forma di transfer learning, questa categoria mira specificamente a consentire a un modello di svolgere un compito diverso da quello su cui è stato inizialmente addestrato. L'idea principale è sfruttare la conoscenza che il modello ha acquisito da un grande dataset generale e applicarla a un compito più specifico o correlato.
Questo tipo di fine-tuning cerca di adattare il modello a comprendere e generare testo specifico di un determinato dominio o settore. Il modello viene sottoposto a fine-tuning su un dataset composto da testi del dominio di destinazione per migliorarne il contesto e la conoscenza dei compiti specifici del dominio.
Ad esempio, per generare un chatbot per un'app medica, il modello verrebbe addestrato con cartelle cliniche, in modo da adattare le sue capacità di comprensione linguistica al campo della salute.
Esegui e modifica il codice da questo tutorial online
Esegui codiceSappiamo già che il fine-tuning è il processo con cui si prende un modello pre-addestrato e si aggiornano i suoi parametri addestrandolo su un dataset specifico per il tuo compito. Quindi, esemplifichiamo questo concetto effettuando il fine-tuning di un modello reale.
Immagina di lavorare con GPT-2, ma di notare che è piuttosto scarso nell'inferire il sentiment dei tweet.
Una domanda naturale che viene in mente è: possiamo fare qualcosa per migliorarne le prestazioni?
Possiamo sfruttare il fine-tuning addestrando il nostro modello GPT-2 pre-addestrato da Hugging Face con un dataset contenente tweet e i relativi sentiment, così da migliorarne le prestazioni. Ecco un esempio di base di fine-tuning di un modello per la classificazione di sequenze:
Per fare il fine-tuning di un modello, dobbiamo sempre avere in mente un modello pre-addestrato. Nel nostro caso, effettueremo un semplice fine-tuning usando GPT-2.
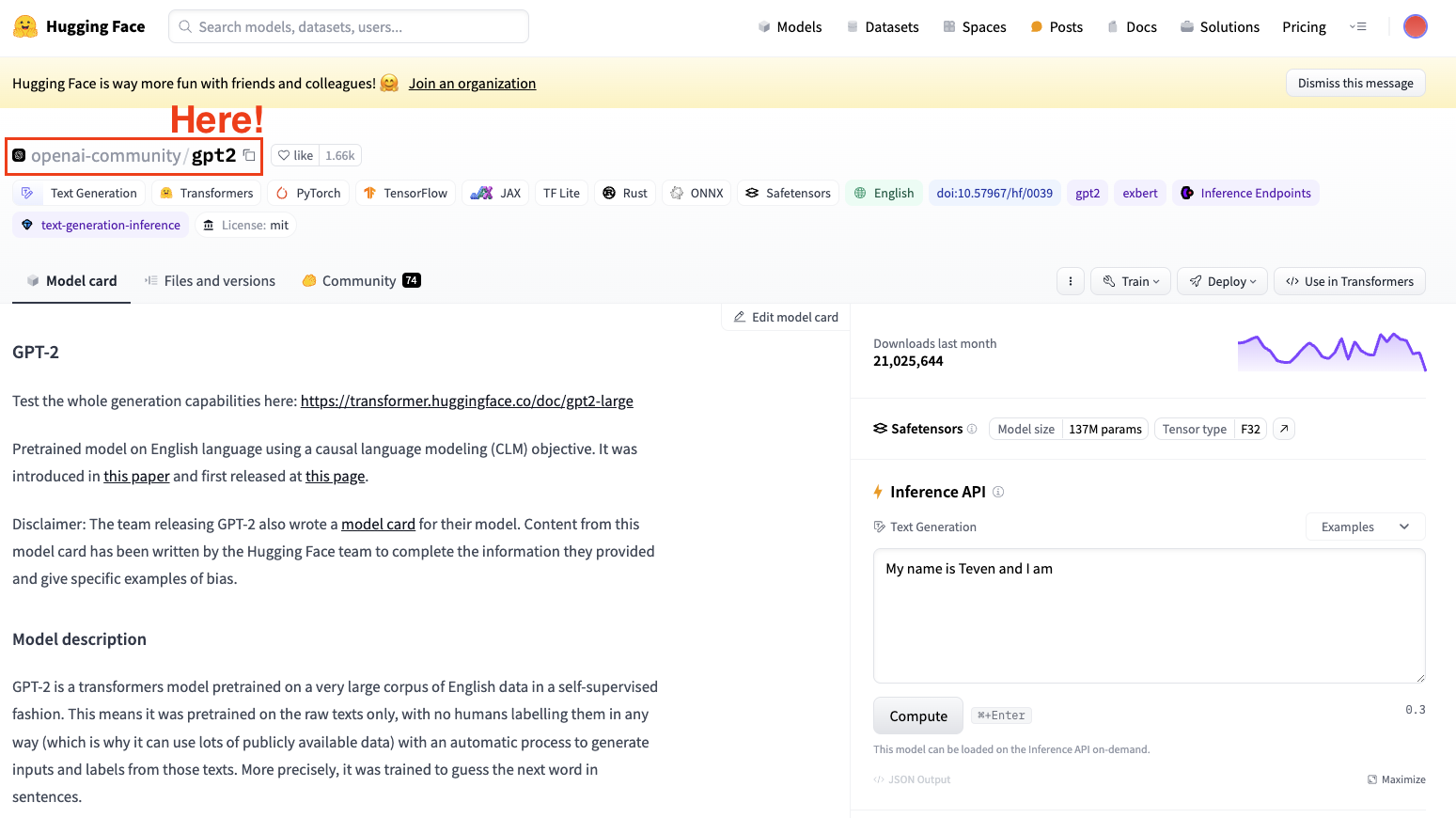
Screenshot di Hugging Face Datasets Hub. Selezione del modello GPT2 di OpenAI.
Ricorda sempre di selezionare un'architettura di modello adatta al tuo compito.
Ora che abbiamo il nostro modello, ci servono dati di buona qualità con cui lavorare, ed è qui che entra in gioco la libreria datasets.
Nel mio caso, userò la libreria datasets di Hugging Face per importare un dataset contenente tweet segmentati per sentiment (Positivo, Neutro o Negativo).
from datasets import load_dataset
dataset = load_dataset("mteb/tweet_sentiment_extraction")
df = pd.DataFrame(dataset['train'])
Se controlliamo il dataset appena scaricato, troviamo un sottoinsieme per l'addestramento e uno per il test. Se convertiamo il sottoinsieme di training in un dataframe, appare così.

Il dataset che verrà utilizzato.
Ora che abbiamo il nostro dataset, ci serve un tokenizer per prepararlo all'analisi da parte del modello.
Poiché gli LLM lavorano con i token, abbiamo bisogno di un tokenizer per processare il dataset. Per elaborare il dataset in un solo passaggio, usa il metodo map di Datasets per applicare una funzione di pre-processing all'intero dataset.
Per questo, il secondo passo è caricare un Tokenizer pre-addestrato e tokenizzare il dataset, così da poterlo usare per il fine-tuning.
from transformers import GPT2Tokenizer
# Loading the dataset to train our model
dataset = load_dataset("mteb/tweet_sentiment_extraction")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)BONUS: Per ridurre i requisiti di elaborazione, possiamo creare un sottoinsieme più piccolo dell'intero dataset per effettuare il fine-tuning. Il set di training verrà usato per il fine-tuning del modello, mentre il set di test servirà per valutarlo.
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))Inizia caricando il modello e specificando il numero di etichette attese. Dalla scheda del dataset sul sentiment dei Tweet, sappiamo che ci sono tre etichette:
from transformers import GPT2ForSequenceClassification
model = GPT2ForSequenceClassification.from_pretrained("gpt2", num_labels=3)Transformers fornisce una classe Trainer ottimizzata per l'addestramento. Tuttavia, questo metodo non include come valutare il modello. Per questo, prima di iniziare l'addestramento, dovremo passare a Trainer una funzione per valutare le prestazioni del modello.
import evaluate
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)L'ultimo passaggio è impostare gli argomenti di training e avviare il processo di addestramento. La libreria Transformers include la classe Trainer, che supporta un'ampia gamma di opzioni e funzionalità, come logging, accumulo dei gradienti e precisione mista. Per prima cosa definiamo gli argomenti di training insieme alla strategia di valutazione. Una volta definito tutto, possiamo addestrare facilmente il modello usando semplicemente il comando train().
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="test_trainer",
#evaluation_strategy="epoch",
per_device_train_batch_size=1, # Reduce batch size here
per_device_eval_batch_size=1, # Optionally, reduce for evaluation as well
gradient_accumulation_steps=4
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
Dopo l'addestramento, valuta le prestazioni del modello su un set di validazione o di test. Anche in questo caso, la classe Trainer include già un metodo evaluate che se ne occupa.
import evaluate
trainer.evaluate()
Questi sono i passaggi più basilari per effettuare il fine-tuning di qualsiasi LLM. Ricorda che fare il fine-tuning di un LLM è molto impegnativo dal punto di vista computazionale e il tuo computer locale potrebbe non avere potenza sufficiente.
Puoi imparare come effettuare il fine-tuning di LLM più potenti direttamente sull'interfaccia di OpenAI seguendo questo tutorial su come fare il fine-tuning di GPT 3.5.
Per assicurare un fine-tuning efficace, considera le seguenti best practice:
La qualità del dataset di fine-tuning incide notevolmente sulle prestazioni del modello. Conosciamo tutti l'espressione:
“Garbage In, Garbage Out”
Quindi, assicurati sempre che i dati siano puliti, pertinenti e sufficientemente ampi.
Il fine-tuning è di solito un processo lungo che richiede iterazioni. Esplora sempre diverse impostazioni per learning rate, dimensione dei batch e numero di epoche di training per individuare la configurazione migliore per il tuo progetto.
Regolazioni precise sono fondamentali per assicurare che il modello apprenda in modo efficiente e si adatti bene a dati non visti, evitando il rischio di overfitting.
Valuta regolarmente i progressi del modello durante l'addestramento per monitorarne l'efficacia e applicare le modifiche necessarie. Ciò comporta la valutazione delle prestazioni del modello usando un dataset di validazione distinto durante l'intero periodo di training.
Questa valutazione è fondamentale per determinare le prestazioni del modello sul compito in questione e il suo potenziale di overfitting sul dataset di training. In base ai risultati della fase di validazione, è possibile apportare gli aggiustamenti necessari per ottimizzare le prestazioni.
Il fine-tuning talvolta può portare a risultati subottimali. Fai attenzione ai seguenti rischi:
Usare un dataset piccolo per l'addestramento o prolungare eccessivamente il numero di epoche può causare overfitting. Di solito si manifesta con un'elevata accuratezza sul dataset di training ma una scarsa generalizzazione su nuovi dati.
Al contrario, un addestramento insufficiente o un learning rate troppo basso possono portare a underfitting, per cui il modello non apprende adeguatamente il compito.
Nel processo di fine-tuning per un compito specifico, c'è il rischio che il modello perda le ampie conoscenze inizialmente acquisite. Questo problema, noto come catastrophic forgetting, può ridurre la capacità del modello di ottenere buoni risultati su una varietà di compiti di elaborazione del linguaggio naturale.
Assicurati sempre che i dataset di training e di validazione siano separati e non si sovrappongano, poiché ciò può produrre metriche di performance fuorvianti.
RAG combina i punti di forza dei modelli basati su retrieval e dei modelli generativi. In RAG, un componente retriever cerca in un grande database o base di conoscenza per trovare informazioni rilevanti in base alla query di input. Queste informazioni recuperate vengono poi utilizzate da un modello generativo per produrre una risposta più accurata e contestualmente pertinente. I principali vantaggi di RAG includono:
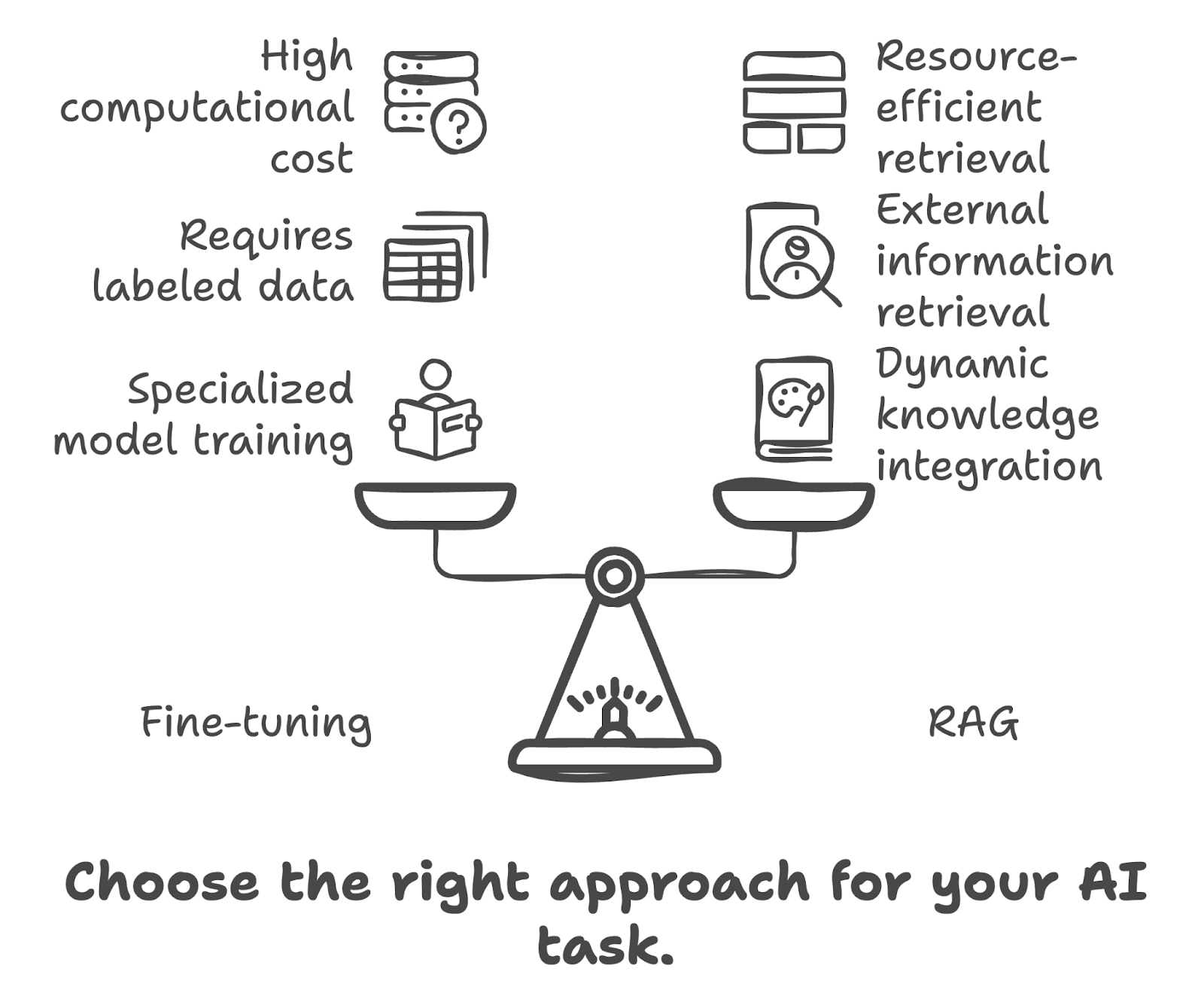
Quando decidi se usare il fine-tuning o RAG, considera i seguenti fattori:
Intraprendere il percorso del fine-tuning dei large language model apre un mondo di possibilità per le applicazioni di AI.
Capendo e applicando i concetti, le pratiche e le precauzioni illustrate, puoi adattare efficacemente questi potenti modelli alle esigenze specifiche, sbloccandone il pieno potenziale.
Per continuare a imparare sul fine-tuning, ti incoraggio vivamente a cimentarti con un fine-tuning più avanzato. Puoi iniziare con il corso LLM Concepts di DataCamp, che copre molte delle principali metodologie di training e le ricerche più recenti. Altre buone risorse da seguire sono:
Inizia oggi il tuo percorso nell'AI!
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min

