
Kurs
Large Language Models (LLMs) Kavramları
2 sa
104.1K
Dil Modeli, bir cümlenin önceki bölümlerinden yola çıkarak sonraki kelimeyi tahmin etmek üzere tasarlanmış bir makine öğrenmesi algoritması türüdür. Transformer'ların nasıl çalıştığı hakkındaki makalemizde ayrıntılı biçimde açıklanan Transformers mimarisine dayanır.
GPT (Generative Pre-trained Transformer) gibi önceden eğitilmiş dil modelleri, çok büyük miktarda metin verisi üzerinde eğitilir. Bu, LLM'lerin doğal dilde kelimelerin kullanımı ve dizilişini yöneten temel ilkeleri kavramasını sağlar.

Yazarın görseli. LLM girdi ve çıktı.
En önemli nokta, bu modellerin yalnızca doğal dili anlamada değil, aynı zamanda aldıkları girdiye dayanarak insan benzeri metin üretmede de iyi olmalarıdır.
Ve işin en güzel tarafı?
Bu modeller, API'ler aracılığıyla halihazırda herkesin kullanımına açık. OpenAI’nin en güçlü LLM’lerinden nasıl yararlanacağınızı öğrenmek istiyorsanız, OpenAI API’si hakkındaki bu kopya kâğıdını takip edebilirsiniz.
İnce ayar, önceden eğitilmiş bir modeli alıp alanına özgü bir veri kümesi üzerinde daha fazla eğitme sürecidir.
Bugün çoğu LLM modeli genel olarak çok iyi performans gösterse de, belirli görev odaklı problemler söz konusu olduğunda yetersiz kalır. İnce ayar süreci, hesaplama maliyetlerinin düşürülmesi ve sıfırdan bir model oluşturma gerekliliği olmadan en gelişmiş modellerden yararlanma gibi önemli avantajlar sunar.
Transformers, çeşitli görevlere uygun geniş bir önceden eğitilmiş model koleksiyonuna erişim sağlar. Bu modellerin ince ayarı, duygu analizi, soru yanıtlama veya belge özetleme gibi belirli görevleri daha yüksek doğrulukla yerine getirme becerisini geliştirmek için kritik bir adımdır.
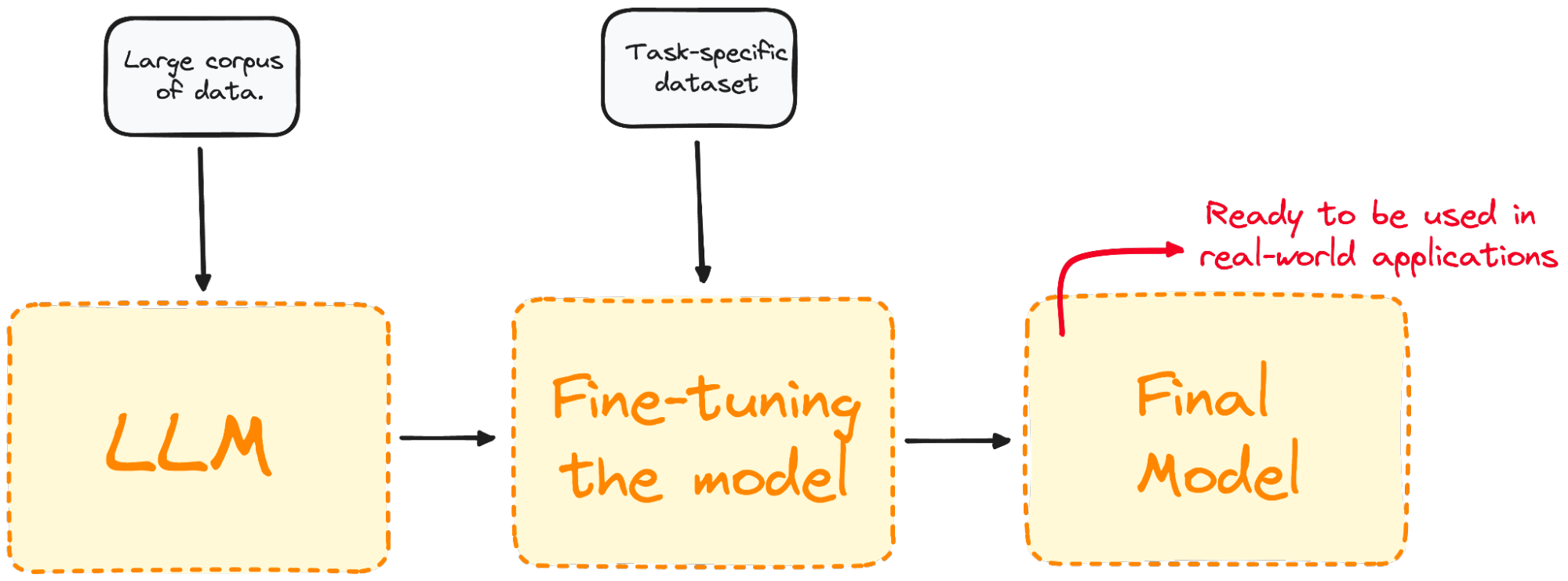
Yazarın görseli. İnce ayar sürecinin görselleştirilmesi.
İnce ayar, modelin belirli görevlerde daha iyi performans göstermesini sağlayarak onu gerçek dünyadaki uygulamalarda daha etkili ve çok yönlü kılar. Bu süreç, mevcut bir modeli belirli bir göreve veya alana uyarlamak için esastır.
İnce ayar yapıp yapmama kararı, genellikle ele alınan belirli alan veya göreve bağlı olan hedeflerinize dayanır.
İnce ayara, ağırlıklı olarak odağına ve belirli hedeflerine göre çeşitli şekillerde yaklaşılabilir.
En basit ve en yaygın ince ayar yaklaşımıdır. Model, metin sınıflandırma veya adlandırılmış varlık tanıma gibi hedef göreve özgü etiketli bir veri kümesi üzerinde ilave olarak eğitilir.
Örneğin, duygu analizi için, duygu etiketleriyle işaretlenmiş metin örnekleri içeren bir veri kümesi üzerinde modelimizi eğitiriz.
Büyük bir etiketli veri kümesi toplamanın pratik olmadığı bazı durumlar vardır. Few-shot öğrenme, girdi istemlerinin başında gerekli görevin birkaç örneğini (veya shot'unu) sağlayarak bunu ele almaya çalışır. Bu, kapsamlı bir ince ayar sürecine gerek kalmadan modelin görevin bağlamını daha iyi kavramasına yardımcı olur.
Her ne kadar tüm ince ayar teknikleri bir tür transfer öğrenme olsa da, bu kategori özellikle bir modelin ilk eğitim aldığı görevden farklı bir görevi yerine getirmesini sağlamayı hedefler. Ana fikir, modelin geniş ve genel bir veri kümesinden edindiği bilgiyi daha spesifik veya ilişkili bir göreve uygulamaktır.
Bu tür ince ayar, modeli belirli bir alan veya sektöre özgü metni anlamaya ve üretmeye uyarlamayı amaçlar. Model, hedef alandan oluşan bir metin veri kümesi üzerinde ince ayar yapılarak, o alana özgü görevlerde bağlam ve bilgi düzeyi geliştirilir.
Örneğin, bir sağlık uygulaması için sohbet botu üretmek adına, model sağlık alanına yönelik dil anlama yeteneklerini uyarlamak için tıbbi kayıtlarla eğitilir.
Bu eğitimdeki kodu çevrimiçi olarak çalıştırın ve düzenleyin
Kodu çalıştırArtık biliyoruz ki ince ayar, önceden eğitilmiş bir modeli alıp, görevinize özgü bir veri kümesi üzerinde eğiterek parametrelerini güncelleme sürecidir. Öyleyse bu kavramı gerçek bir model üzerinde ince ayar yaparak örneklendirelim.
GPT-2 ile çalıştığımızı, ancak tweet’lerin duygusunu çıkarmada oldukça kötü olduğunu fark ettiğimizi hayal edin.
Aklımıza gelen doğal bir soru: Performansını iyileştirmek için bir şey yapabilir miyiz?
Hugging Face model havuzundan aldığımız önceden eğitilmiş GPT-2 modelimizi, tweet’ler ve karşılık gelen duygularını içeren bir veri kümesiyle eğiterek ince ayardan yararlanabilir ve performansı artırabiliriz. İşte dizi sınıflandırma için bir modeli ince ayar yapmanın temel bir örneği:
Bir modeli ince ayar yapmak için her zaman aklımızda önceden eğitilmiş bir model olmalıdır. Bizim durumda, GPT-2 kullanarak basit bir ince ayar yapacağız.
Hugging Face Datasets Hub ekran görüntüsü. OpenAI’nin GPT2 modelini seçme.
Her zaman görevinize uygun bir model mimarisi seçmeyi unutmayın.
Artık modelimiz olduğuna göre, üzerinde çalışmak için kaliteli veriye ihtiyacımız var ve tam da burada datasets kütüphanesi devreye giriyor.
Benim örneğimde, duygularına göre (Pozitif, Nötr veya Negatif) ayrılmış tweet’ler içeren bir veri kümesini içe aktarmak için Hugging Face datasets kütüphanesini kullanacağım.
from datasets import load_dataset
dataset = load_dataset("mteb/tweet_sentiment_extraction")
df = pd.DataFrame(dataset['train'])
Az önce indirdiğimiz veri kümesini incelersek, eğitim ve test için alt kümeler içerdiğini görürüz. Eğitim alt kümesini bir veri çerçevesine dönüştürürsek aşağıdaki gibi görünür.

Kullanılacak veri kümesi.
Artık veri kümemiz olduğuna göre, modelimiz tarafından ayrıştırılmak üzere hazırlamak için bir tokenizer’a ihtiyacımız var.
LLM'ler token'larla çalıştığından, veri kümesini işlemek için bir tokenizer gereklidir. Veri kümenizi tek adımda işlemek için, tüm veri kümesi üzerinde bir ön işleme fonksiyonu uygulamak üzere Datasets'in map metodunu kullanın.
Bu yüzden ikinci adım, önceden eğitilmiş bir Tokenizer yüklemek ve veri kümemizi ince ayarda kullanılabilecek şekilde tokenleştirmektir.
from transformers import GPT2Tokenizer
# Loading the dataset to train our model
dataset = load_dataset("mteb/tweet_sentiment_extraction")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)BONUS: İşleme gereksinimlerimizi iyileştirmek için, modelimizi ince ayar yapmak üzere tam veri kümesinin daha küçük bir alt kümesini oluşturabiliriz. Eğitim seti modeli ince ayar için, test seti ise değerlendirme için kullanılacaktır.
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))Modelinizi yükleyerek başlayın ve beklenen etiket sayısını belirtin. Tweet duygu veri kümesi kartından üç etiket olduğunu biliyorsunuz:
from transformers import GPT2ForSequenceClassification
model = GPT2ForSequenceClassification.from_pretrained("gpt2", num_labels=3)Transformers, eğitim için optimize edilmiş bir Trainer sınıfı sağlar. Ancak bu yöntem, modelin nasıl değerlendirileceğini içermez. Bu nedenle eğitime başlamadan önce, model performansını değerlendirmek için Trainer'a bir fonksiyon geçirmemiz gerekecek.
import evaluate
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)Son adımımız, eğitim argümanlarını ayarlayıp eğitim sürecini başlatmaktır. Transformers kütüphanesi, günlükleme, gradyan biriktirme ve karma hassasiyet gibi çok çeşitli eğitim seçenekleri ve özellikleri destekleyen Trainer sınıfını içerir. Önce eğitim argümanlarını değerlendirme stratejisiyle birlikte tanımlarız. Her şey tanımlandığında, train() komutunu kullanarak modeli kolayca eğitebiliriz.
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="test_trainer",
#evaluation_strategy="epoch",
per_device_train_batch_size=1, # Reduce batch size here
per_device_eval_batch_size=1, # Optionally, reduce for evaluation as well
gradient_accumulation_steps=4
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
Eğitimden sonra, modelin performansını bir doğrulama veya test seti üzerinde değerlendirin. Yine, trainer sınıfı bunu üstlenen bir evaluate metodunu zaten içerir.
import evaluate
trainer.evaluate()
Bunlar, herhangi bir LLM üzerinde ince ayar gerçekleştirmek için en temel adımlardır. Unutmayın, bir LLM'i ince ayar yapmak yüksek hesaplama gücü gerektirir ve yerel bilgisayarınız bunun için yeterli güce sahip olmayabilir.
Daha güçlü LLM’lere doğrudan OpenAI arayüzü üzerinden nasıl ince ayar yapacağınızı, GPT 3.5’e Nasıl İnce Ayar Yapılır başlıklı bu eğitimle öğrenebilirsiniz.
Başarılı bir ince ayar için aşağıdaki en iyi uygulamaları dikkate alın:
İnce ayar veri kümenizin kalitesi, modelin performansını önemli ölçüde etkiler. Hepimizin bildiği söz:
“Çöp Girdi, Çöp Çıktı”
Bu nedenle verinin temiz, ilgili ve yeterince büyük olduğundan her zaman emin olun.
İnce ayar genellikle yineleme gerektiren uzun bir süreçtir. Projeniz için en iyi kurulumu belirlemek üzere öğrenme oranları, yığın boyutları ve eğitim dönemlerinin sayısı için çeşitli ayarları daima keşfedin.
Hassas ayarlamalar, modelin verimli öğrenmesini ve görülmemiş verilere iyi uyum sağlamasını, aşırı öğrenme riskinden kaçınmasını sağlamak için anahtardır.
Eğitim sırasında modelin ilerlemesini düzenli olarak değerlendirin; böylece etkinliğini takip edebilir ve gerekli değişiklikleri uygulayabilirsiniz. Bu, eğitim süresi boyunca modelin performansını ayrı bir doğrulama veri kümesi kullanarak değerlendirmeyi içerir.
Bu tür bir değerlendirme, modelin ele alınan görevdeki performansını ve eğitim veri kümesine aşırı uyum sağlama (overfitting) potansiyelini belirlemek için kritiktir. Doğrulama aşamasından elde edilen sonuçlara dayanarak performansı eniyilemek için gerekli ayarlamalar yapılabilir.
İnce ayar bazen optimal olmayan sonuçlara yol açabilir. Aşağıdaki tuzaklara karşı dikkatli olun:
Eğitim için küçük bir veri kümesi kullanmak veya dönem sayısını aşırı artırmak, aşırı öğrenmeye neden olabilir. Bu durum genellikle modelin eğitim veri kümesinde yüksek doğruluk göstermesi, ancak yeni verilere genelleyememesiyle karakterizedir.
Buna karşılık, yetersiz eğitim veya düşük öğrenme oranı, modelin görevi yeterince öğrenemediği yetersiz öğrenmeye yol açabilir.
Belirli bir görev için ince ayar yapma sürecinde, modelin başlangıçta edindiği geniş bilgiyi kaybetme riski vardır. Felaket unutma olarak adlandırılan bu sorun, modelin doğal dil işleme kapsamında çeşitli görevlerde iyi performans gösterme yeteneğini azaltabilir.
Eğitim ve doğrulama veri kümelerinin ayrı olduğundan ve örtüşme bulunmadığından her zaman emin olun; aksi takdirde yanıltıcı biçimde yüksek performans metrikleri elde edilebilir.
RAG, alma tabanlı modeller ile üretken modellerin güçlü yönlerini birleştirir. RAG’de bir getirici bileşen, girdi sorgusuna dayanarak ilgili bilgiyi bulmak için büyük bir veritabanında veya bilgi tabanında arama yapar. Ardından bu alınan bilgi, üretken bir model tarafından daha doğru ve bağlamsal olarak ilgili bir yanıt üretmek için kullanılır. RAG’in temel faydaları şunlardır:
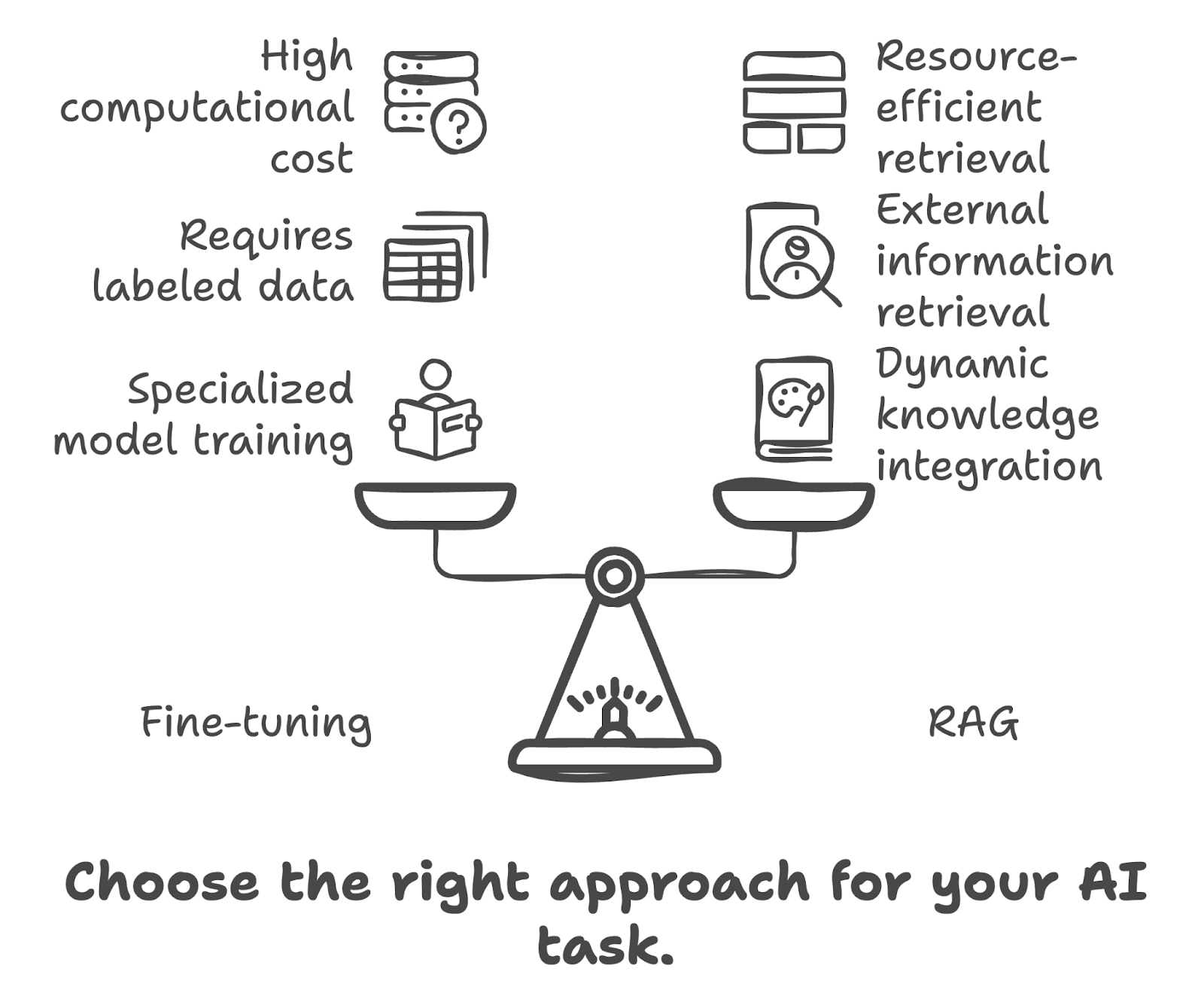
İnce ayar mı yoksa RAG mi kullanacağınıza karar verirken aşağıdaki faktörleri göz önünde bulundurun:
Büyük dil modellerine ince ayar yapma yolculuğuna çıkmak, yapay zekâ uygulamaları için bir olasılıklar dünyasının kapılarını aralar.
Burada açıklanan kavramları, uygulamaları ve önlemleri anlayıp hayata geçirerek, bu güçlü modelleri belirli ihtiyaçlara etkili şekilde uyarlayabilir ve bu süreçte tüm potansiyellerini açığa çıkarabilirsiniz.
İnce ayar hakkında öğrenmeye devam etmek için, daha ileri düzey ince ayarlar yapmanızı şiddetle tavsiye ederim. LLM Kavramları kursu ile başlayabilir, temel eğitim yöntemlerinin çoğunu ve en güncel araştırmaları keşfedebilirsiniz. Takip edilebilecek diğer bazı iyi kaynaklar:
Yapay Zekâ Yolculuğunuza Bugün Başlayın!
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
