
Program
Insinyur Kecerdasan Buatan (AI) untuk Pengembang
26 Hr
Qwen3.6-35B-A3B adalah model mixture-of-experts ringan yang dirancang untuk tugas pengodean, penalaran, dan konteks panjang. Model ini memiliki total 35B parameter dengan 3B parameter aktif per token, sehingga lebih efisien dijalankan sambil tetap memberikan kinerja yang kuat. Model ini juga mendukung jendela konteks 262K token, sehingga berguna untuk basis kode besar, dokumen panjang, dan alur kerja multi-langkah.
Model ini berkinerja sangat baik pada tolok ukur bertipe pengodean dan agen, dengan hasil kuat di SWE-bench, Terminal-Bench, dan Claw-Eval. Model ini juga tetap kompetitif pada tolok ukur penalaran dan pengetahuan yang lebih luas seperti GPQA, AIME 2026, MMLU-Pro, dan C-Eval, sehingga menjadi model dasar yang kuat untuk eksperimen fine-tuning yang membutuhkan kinerja tugas praktis sekaligus kemampuan penalaran umum.
Dalam panduan ini, kita akan menyiapkan lingkungan RunPod H100 NVL, menyiapkan proyek, memuat dan membersihkan dataset tanya jawab medis, menjalankan Qwen3.6 dalam kuantisasi 4-bit, memformat prompt, membangun helper evaluasi, menguji model dasar sebelum fine-tuning, melatih dan menyimpan adapter, lalu membandingkan model lagi setelah fine-tuning.
Disclaimer: Tutorial ini menunjukkan proses fine-tuning teknis untuk tujuan edukasi saja. Model yang dihasilkan tidak dimaksudkan untuk penggunaan medis atau klinis dan tidak boleh dijadikan acuan untuk diagnosis, pengambilan keputusan, atau perawatan pasien.
Pada bagian pertama, kita akan meluncurkan instance RunPod H100 NVL, memasang pustaka yang diperlukan, menyambungkan ke Hugging Face, dan mendefinisikan konfigurasi inti proyek.
Mulailah dengan membuka RunPod dan memilih mesin GPU H100 NVL. GPU ini memiliki sekitar 94 GB VRAM dan 94 GB RAM sistem, yang cukup untuk alur kerja fine-tuning Qwen3.6 ini.
Pilih template PyTorch terbaru, lalu edit konfigurasi pod sebelum deployment. Atur ukuran disk container menjadi 100 GB dan ukuran disk volume menjadi 200 GB. Ini memberi ruang yang cukup untuk mengunduh model, menyimpan cache dependensi, dan menyimpan adapter hasil fine-tuning secara lokal.
Anda juga sebaiknya menambahkan variabel lingkungan HF_TOKEN pada tahap ini. Ini akan memungkinkan Anda masuk ke Hugging Face nanti, meningkatkan akses pengunduhan model, dan mempermudah mendorong model yang sudah difine-tuning ke Hub setelah pelatihan.
Sebelum meluncurkan instance, tinjau ringkasan pod agar Anda dapat memeriksa perkiraan biaya. Setelah semuanya terlihat benar, deploy pod.
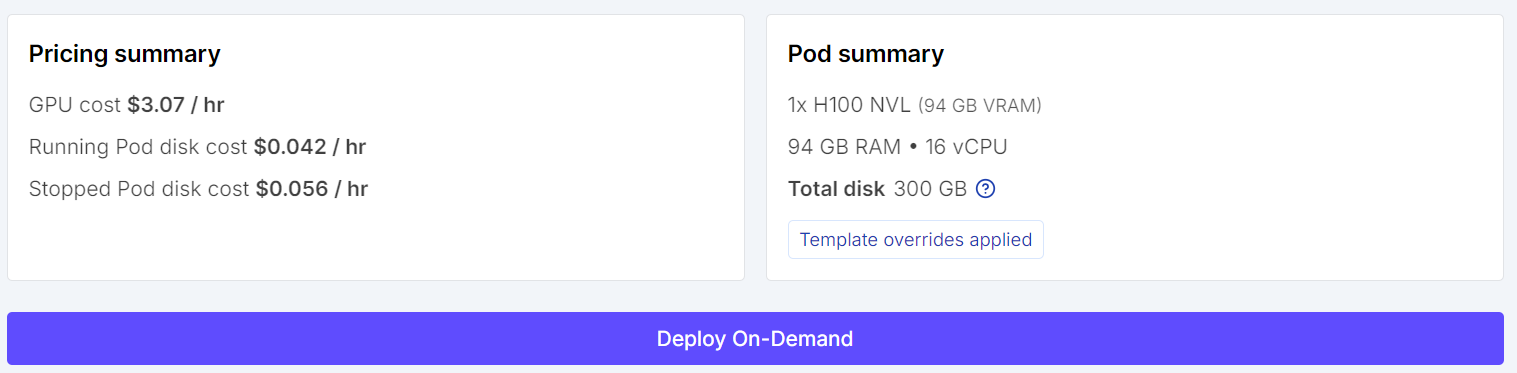
Setelah pod siap, buka tautan Jupyter Notebook dari dasbor RunPod untuk meluncurkan JupyterLab. Buat notebook Python baru, lalu pasang pustaka yang dibutuhkan untuk fine-tuning terkuantisasi, pemuatan dataset, dan supervised fine-tuning dengan TRL.
pip install -q -U transformers accelerate peft trl bitsandbytes datasets sentencepieceBerikutnya, masuk ke Hugging Face menggunakan variabel lingkungan HF_TOKEN yang Anda tambahkan saat membuat pod. Ini menghindari hardcode token Anda di notebook dan membuat alur kerja lebih rapi.
import os
from huggingface_hub import login
hf_token = os.getenv("HF_TOKEN")
login(token=hf_token)Sekarang impor pustaka yang diperlukan dan definisikan nilai konfigurasi yang akan kita gunakan sepanjang tutorial. Ini mencakup ID model, nama dataset, ukuran sampel, direktori keluaran, dan seed acak.
import os
import random
import re
import torch
from datasets import load_dataset
from peft import LoraConfig, prepare_model_for_kbit_training
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
set_seed,
)
from trl import SFTConfig, SFTTrainer
MODEL_ID = "Qwen/Qwen3.6-35B-A3B"
DATASET_ID = "keivalya/MedQuad-MedicalQnADataset"
SAMPLE_SIZE = 240
EVAL_SIZE = 24
COMPARISON_SAMPLE_COUNT = 3
MAX_SEQ_LENGTH = 768
OUTPUT_DIR = "qwen36-medquad-quick"
SEED = 42
set_seed(SEED)
random.seed(SEED)
def supports_bf16() -> bool:
return torch.cuda.is_available() and torch.cuda.get_device_capability(0)[0] >= 8
print(f"PyTorch: {torch.__version__}")
print(f"CUDA available: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"GPU: {torch.cuda.get_device_name(0)}")
print(
f"GPU memory (GB): {torch.cuda.get_device_properties(0).total_memory / 1024**3:.1f}"
)Saat Anda menjalankan sel ini, Anda akan melihat keluaran yang mengonfirmasi bahwa CUDA tersedia dan notebook terhubung ke GPU NVIDIA H100 NVL.
PyTorch: 2.8.0+cu128
CUDA available: True
GPU: NVIDIA H100 NVL
GPU memory (GB): 93.1Pada bagian ini, kita akan memuat dataset tanya jawab medis MedQuad, membersihkan kolom teks, menyaring contoh berkualitas lebih rendah, dan membuat split pelatihan serta evaluasi kecil untuk fine-tuning cepat.
Kita mulai dengan memuat split pelatihan dari dataset MedQuad di Hugging Face. Setelah memuatnya, kita meninjau struktur dataset, nama kolom, dan contoh pertama agar memahami jenis pasangan pertanyaan-jawaban medis yang kita gunakan.
raw_dataset = load_dataset(DATASET_ID, split="train")
print(raw_dataset)
print("First example:", raw_dataset[0])Ini menunjukkan bahwa dataset MedQuad berisi 16.407 contoh pertanyaan-jawaban medis di tiga kolom: qtype, Question, dan Answer.
Dataset({
features: ['qtype', 'Question', 'Answer'],
num_rows: 16407
})
First example: {'qtype': 'susceptibility', 'Question': 'Who is at risk for Lymphocytic Choriomeningitis (LCM)? ?', 'Answer': 'LCMV infections can occur after exposure to fresh urine, droppings, saliva, or nesting materials from infected rodents. Transmission may also occur when these materials are directly introduced into broken skin, the nose, the eyes, or the mouth, or presumably, via the bite of an infected rodent. Person-to-person transmission has not been reported, with the exception of vertical transmission from infected mother to fetus, and rarely, through organ transplantation.'}Berikutnya, kita mendefinisikan fungsi pembersihan teks kecil dan aturan penyaringan untuk menghapus sampel berkualitas rendah. Langkah pembersihan menormalkan spasi berlebih, sedangkan penyaringan menghapus contoh dengan pertanyaan sangat pendek, jawaban sangat pendek, jawaban terlalu panjang, atau templat jawaban generik yang kurang berguna untuk pelatihan.
def clean_text(text):
text = re.sub(r"\s+", " ", str(text)).strip()
return text
BAD_ANSWER_PREFIXES = (
"These resources address",
"These resources from MedlinePlus",
"For more information, go to",
"For more information go to",
)
def keep_example(example):
question = clean_text(example["Question"])
answer = clean_text(example["Answer"])
if len(question) < 12 or len(answer) < 40:
return False
if len(answer) > 900:
return False
if any(answer.startswith(prefix) for prefix in BAD_ANSWER_PREFIXES):
return False
return True
filtered_dataset = raw_dataset.filter(keep_example)Setelah penyaringan, kita mengacak dataset, memilih subset yang lebih kecil untuk tutorial cepat ini, dan membaginya menjadi set pelatihan dan evaluasi. Ini membuat proses tetap ringan sambil tetap memungkinkan kita membandingkan model sebelum dan sesudah fine-tuning.
subset = filtered_dataset.shuffle(seed=SEED).select(range(SAMPLE_SIZE))
split_dataset = subset.train_test_split(test_size=EVAL_SIZE, seed=SEED)
train_dataset = split_dataset["train"]
eval_dataset = split_dataset["test"]
print(f"Filtered dataset size: {len(filtered_dataset)}")
print(f"Train size: {len(train_dataset)}")
print(f"Eval size: {len(eval_dataset)}")Setelah penyaringan, tersisa 7.355 contoh berkualitas lebih tinggi, dari mana kita ambil sampel 216 contoh pelatihan dan 24 contoh evaluasi untuk fine-tuning cepat ini.
Filtered dataset size: 7355
Train size: 216
Eval size: 24Pada langkah ini, kita akan mengonfigurasi kuantisasi 4-bit dengan BitsAndBytes, memuat tokenizer Qwen3.6, lalu memuat model dasar agar dapat berjalan lebih efisien di GPU H100 NVL.
Qwen3.6 tetap merupakan model besar, sehingga memuatnya dalam presisi penuh akan menggunakan memori jauh lebih banyak. Untuk membuat fine-tuning lebih efisien, kita memuat model dalam presisi 4-bit dengan BitsAndBytes. Ini mengurangi penggunaan memori sambil tetap menjaga model praktis untuk fine-tuning berbasis QLoRA.
Di sini, kita menggunakan nf4 kuantisasi, mengaktifkan double quantization, dan menetapkan compute dtype ke bfloat16 saat GPU mendukungnya.
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16 if supports_bf16() else torch.float16,
)Berikutnya, kita memuat tokenizer untuk Qwen3.6. Kita juga memeriksa apakah token padding sudah didefinisikan. Jika belum ada, kita menggunakan kembali token end-of-sequence sebagai token padding agar batching berfungsi dengan benar saat pelatihan dan generasi nanti.
tokenizer = AutoTokenizer.from_pretrained(
MODEL_ID,
trust_remote_code=True,
use_fast=False,
)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_tokenSekarang kita memuat model dasar Qwen3.6 dengan pengaturan kuantisasi 4-bit yang telah kita definisikan sebelumnya. Kita menggunakan device_map="auto" agar model ditempatkan secara otomatis pada GPU yang tersedia, dan kembali menggunakan bfloat16 saat didukung untuk komputasi yang lebih efisien.
Setelah memuat model, kita menetapkan ID token padding dan menonaktifkan penggunaan cache. Ini penting karena cache membantu untuk inferensi, tetapi selama fine-tuning, cache dapat mengganggu pelatihan dan meningkatkan penggunaan memori.
model = AutoModelForCausalLM.from_pretrained(
MODEL_ID,
quantization_config=bnb_config,
device_map="auto",
dtype=torch.bfloat16 if supports_bf16() else torch.float16,
trust_remote_code=True,
)
model.config.pad_token_id = tokenizer.pad_token_id
model.config.use_cache = FalsePada langkah ini, kita akan mendefinisikan struktur prompt untuk Qwen3.6, membersihkan keluaran model, membuat fungsi helper untuk pelatihan dan inferensi, serta menyiapkan beberapa sampel pratinjau untuk membandingkan model sebelum dan sesudah fine-tuning.
Kita mulai dengan mendefinisikan system prompt singkat yang memberi tahu model cara menjawab. Karena ini adalah tugas tanya jawab medis, kita menginginkan respons yang langsung, faktual, dan ringkas.
SYSTEM_PROMPT = "Answer the medical question directly in 2-4 factual sentences."Qwen3.6 menggunakan format input bergaya chat, jadi kita memerlukan fungsi helper yang mengonversi pesan kita ke struktur prompt yang benar. Fungsi ini menerapkan chat template milik tokenizer dan menonaktifkan keluaran reasoning agar model tetap fokus pada jawaban akhir.
def apply_chat_template(messages, add_generation_prompt=False):
kwargs = {
"tokenize": False,
"add_generation_prompt": add_generation_prompt,
}
try:
return tokenizer.apply_chat_template(
messages,
enable_thinking=False,
**kwargs,
)
except TypeError:
return tokenizer.apply_chat_template(
messages,
chat_template_kwargs={"enable_thinking": False},
**kwargs,
)Berikutnya, kita mendefinisikan fungsi pembersihan kecil untuk menormalkan teks yang dihasilkan. Ini menghapus spasi berlebih dan menghilangkan awalan answer: jika muncul pada keluaran.
def clean_answer_text(answer):
answer = clean_text(answer)
answer = re.sub(r"^answer\s*:\s*", "", answer, flags=re.IGNORECASE)
return answerKita juga membuat fungsi helper untuk user prompt. Ini menjaga format pertanyaan tetap konsisten di seluruh pelatihan dan evaluasi, serta memberi tahu model untuk hanya mengembalikan jawaban tanpa mengulang pertanyaan.
def make_user_prompt(question):
return (
f"Question: {clean_text(question)}\n\n"
"Respond with only the answer. Do not restate the question."
)Sekarang kita dapat memformat setiap contoh dataset menjadi percakapan penuh bergaya chat dengan pesan sistem, pertanyaan pengguna, dan jawaban asisten yang diharapkan. Ini adalah struktur yang akan kita gunakan untuk supervised fine-tuning.
def format_training_example(example):
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": make_user_prompt(example["Question"]),
},
{
"role": "assistant",
"content": clean_answer_text(example["Answer"]),
},
]
return {"text": apply_chat_template(messages, add_generation_prompt=False)}Sebelum mulai melatih, kita membutuhkan fungsi helper yang dapat menghasilkan jawaban dari model dasar. Kita akan menggunakannya untuk membandingkan respons model sebelum dan sesudah fine-tuning.
Fungsi di bawah membangun prompt, melakukan tokenisasi, menjalankan generasi, lalu menghapus jejak <think> dan pemformatan berlebih dari keluaran.
@torch.inference_mode()
def generate_answer(question, max_new_tokens=160):
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": make_user_prompt(question),
},
]
prompt = apply_chat_template(messages, add_generation_prompt=True)
model_inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
generated = model.generate(
**model_inputs,
max_new_tokens=max_new_tokens,
do_sample=False,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
new_tokens = generated[0][model_inputs["input_ids"].shape[1] :]
text = tokenizer.decode(new_tokens, skip_special_tokens=True).strip()
return clean_answer_text(re.sub(r"<think>.*?</think>", " ", text, flags=re.DOTALL))Kita juga menambahkan fungsi helper kecil untuk memendekkan keluaran panjang saat mencetak contoh pratinjau.
def clip_text(text, max_chars=600):
text = re.sub(r"<think>.*?</think>", " ", text, flags=re.DOTALL)
text = re.sub(r"\s+", " ", text).strip()
return text if len(text) <= max_chars else text[:max_chars] + "..."Terakhir, kita membangun fungsi helper yang membuat beberapa baris pratinjau berdampingan. Setiap baris berisi pertanyaan, prediksi model, dan jawaban referensi. Ini memberi cara sederhana untuk meninjau kinerja sebelum dan sesudah fine-tuning.
def generate_preview_rows(dataset, sample_count=COMPARISON_SAMPLE_COUNT):
sample_count = min(sample_count, len(dataset))
subset = dataset.select(range(sample_count))
previews = []
for row in subset:
previews.append(
{
"question": row["Question"],
"prediction": generate_answer(row["Question"]),
"reference": clean_answer_text(row["Answer"]),
}
)
return previews
formatted_train_dataset = train_dataset.map(
format_training_example,
remove_columns=train_dataset.column_names,
)
comparison_examples = eval_dataset.shuffle(seed=SEED).select(
range(COMPARISON_SAMPLE_COUNT)
)
print(formatted_train_dataset[0])Saat Anda mencetak contoh pelatihan terformat pertama, Anda akan melihat sampel bergaya chat dengan system prompt, pertanyaan pengguna, dan jawaban asisten yang sudah dibungkus dalam format template Qwen.
{'text': '<|im_start|>system\nAnswer the medical question directly in 2-4 factual sentences.<|im_end|>\n<|im_start|>user\nQuestion: What is (are) COPD ?\n\nRespond with only the answer. Do not restate the question.<|im_end|>\n<|im_start|>assistant\n<think>\n\n</think>\n\nMore information on COPD is available at: What is COPD? and at the Learn More, Breathe Better Campaign For information on quitting smoking, visit http://www.surgeongeneral.gov/tobacco/ or Smokefree.gov. For information on the H1N1 flu and COPD, go to The Centers for Disease Control and Prevention.<|im_end|>\n'}Kita akan menguji model dasar Qwen3.6 pada beberapa contoh evaluasi sebelum pelatihan. Ini memberi baseline agar nanti kita dapat membandingkan bagaimana model berubah setelah fine-tuning.
Kita mulai dengan menghasilkan jawaban pratinjau untuk beberapa contoh yang diambil dari set evaluasi.
Setiap pratinjau mencakup pertanyaan, jawaban model sebelum fine-tuning, dan jawaban referensi dari dataset.
baseline_previews = generate_preview_rows(comparison_examples)
for idx, sample in enumerate(baseline_previews, start=1):
print(f"\n--- Preview {idx} ---")
print("Question:", sample["question"])
print("Model answer (before fine-tuning):", clip_text(sample["prediction"]))
print("Reference answer:", clip_text(sample["reference"]))Berikut adalah perbandingan berdampingan antara respons model saat ini dan jawaban referensi. Contoh-contoh ini membantu kita memahami titik awal model sebelum pelatihan khusus tugas.

Dari contoh-contoh ini, kita sudah dapat melihat bahwa model dasar mampu menghasilkan jawaban yang relevan secara medis dan umumnya benar.
Namun, responsnya tidak selalu cocok dengan gaya, tingkat detail, atau perumusan dari jawaban referensi dalam dataset. Dalam beberapa kasus, model memberikan penjelasan yang lebih luas atau lebih generik, sementara jawaban referensi lebih spesifik dan selaras dengan format target.
Pada bagian ini, kita akan mendefinisikan pengaturan adapter LoRA, mengonfigurasi argumen supervised fine-tuning, dan menginisialisasi trainer yang akan menangani proses pelatihan QLoRA.
Alih-alih memperbarui semua parameter model, QLoRA melakukan fine-tuning pada sekumpulan bobot adapter terlatih yang jauh lebih kecil. Ini membuat pelatihan jauh lebih efisien dalam memori sambil tetap memungkinkan model beradaptasi dengan tugas baru.
Di sini, kita mendefinisikan konfigurasi LoRA dengan rank 8, faktor skala 16, dan nilai dropout kecil. Kita juga menargetkan semua lapisan linear sehingga adapter diterapkan secara luas di seluruh model.
lora_config = LoraConfig(
r=8,
lora_alpha=16,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules="all-linear",
)Berikutnya, kita mendefinisikan konfigurasi pelatihan menggunakan SFTConfig. Pengaturan ini mengontrol bagaimana supervised fine-tuning akan berjalan, termasuk ukuran batch, akumulasi gradien, laju pembelajaran, frekuensi logging, dan mode presisi.
Tutorial ini menggunakan pengaturan ringan dengan satu epoch pelatihan dan ukuran batch kecil, sehingga tetap praktis untuk tujuan demonstrasi. Kita juga mengaktifkan gradient checkpointing dan paged 8-bit AdamW untuk mengurangi penggunaan memori selama pelatihan.
trainer_config = SFTConfig(
output_dir=OUTPUT_DIR,
dataset_text_field="text",
max_length=MAX_SEQ_LENGTH,
per_device_train_batch_size=2,
gradient_accumulation_steps=2,
num_train_epochs=1,
learning_rate=1e-4,
warmup_steps=5,
logging_steps=5,
save_strategy="epoch",
report_to="none",
packing=False,
gradient_checkpointing=True,
optim="paged_adamw_8bit",
bf16=supports_bf16(),
fp16=not supports_bf16(),
)Dengan pengaturan adapter dan argumen pelatihan yang sudah siap, kita sekarang dapat menginisialisasi SFTTrainer. Trainer ini menggabungkan model dasar, dataset pelatihan terformat, konfigurasi LoRA, dan tokenizer sehingga model siap untuk supervised fine-tuning.
trainer = SFTTrainer(
model=model,
train_dataset=formatted_train_dataset,
peft_config=lora_config,
args=trainer_config,
processing_class=tokenizer,
)Sebelum memulai pelatihan, ada baiknya mengonfirmasi berapa banyak parameter yang benar-benar akan diperbarui. Salah satu keunggulan utama QLoRA adalah hanya sebagian kecil dari parameter model yang dapat dilatih.
trainer.model.print_trainable_parameters()Ini menunjukkan bahwa hanya sekitar 0,03% dari seluruh parameter model yang dilatih. Inilah yang membuat QLoRA sangat praktis untuk fine-tuning model bahasa besar pada perangkat keras terbatas.
trainable params: 11,238,720 || all params: 34,671,849,408 || trainable%: 0.0324Pada bagian ini, kita akan memulai supervised fine-tuning, menyimpan adapter terlatih secara lokal, lalu mendorongnya ke Hugging Face sehingga dapat digunakan kembali nanti.
Sekarang model, dataset, dan trainer sudah siap, kita dapat memulai proses fine-tuning. Trainer akan menjalankan set pelatihan terformat dan hanya memperbarui bobot adapter LoRA, bukan seluruh model.
train_result = trainer.train()
train_resultSaat pelatihan berjalan, Anda akan melihat loss berangsur menurun. Ini pertanda baik bahwa model mempelajari format tugas dan beradaptasi dengan data tanya jawab medis.
Setelah pelatihan selesai, simpan adapter dan tokenizer yang sudah difine-tuning secara lokal. Ini memberi Anda checkpoint yang dapat digunakan kembali tanpa perlu mengulang seluruh pelatihan.
trainer.model.save_pretrained(OUTPUT_DIR)
tokenizer.save_pretrained(OUTPUT_DIR)Setelah adapter tersimpan secara lokal, Anda dapat mengunggahnya ke Hugging Face. Ini memudahkan untuk berbagi, melakukan versioning, dan memuat ulang model yang sudah difine-tuning di notebook atau alur kerja deployment di masa depan.
HF_REPO_ID = "kingabzpro/qwen36-medquad-quick"
trainer.model.push_to_hub(HF_REPO_ID)
tokenizer.push_to_hub(HF_REPO_ID) Setelah unggahan selesai, adapter yang sudah difine-tuning akan tersedia di repositori.
Setelah unggahan selesai, adapter yang sudah difine-tuning akan tersedia di repositori.
Sumber: kingabzpro/qwen36-medquad-quick
Sekarang pelatihan selesai, kita dapat mengevaluasi model yang sudah difine-tuning pada contoh perbandingan yang sama seperti sebelumnya. Ini membantu kita membuat perbandingan sebelum-dan-sesudah secara langsung pada pertanyaan yang sama.
model.eval()
fine_tuned_previews = generate_preview_rows(comparison_examples)
for idx, (before, after) in enumerate(
zip(baseline_previews, fine_tuned_previews), start=1
):
print(f"\n{'=' * 80}")
print(f"Sample {idx}")
print(f"{'=' * 80}")
print("Question:", before["question"])
print("\nBefore fine-tuning:")
print(clip_text(before["prediction"]))
print("\nAfter fine-tuning:")
print(clip_text(after["prediction"]))
print("\nReference answer:")
print(clip_text(before["reference"]))Anda akan melihat jawaban baseline, jawaban setelah fine-tuning, dan jawaban referensi untuk tiap sampel. Ini memudahkan untuk meninjau bagaimana adapter mengubah gaya dan konten respons model.

Contoh-contoh ini menunjukkan bahwa fine-tuning membantu model beradaptasi lebih dekat dengan gaya dataset target, terutama pada pertanyaan medis faktual yang lebih pendek.
Pada saat yang sama, hasil ini juga menunjukkan bahwa ini hanyalah fine-tuning kecil pada subset terbatas dari dataset, sehingga peningkatan pada setiap sampel tidak dijamin. Beberapa jawaban menjadi lebih selaras dengan distribusi pelatihan, sementara yang lain mungkin kehilangan detail berguna atau menjadi terlalu sempit.
Untuk mendapatkan hasil yang lebih baik, langkah berikutnya adalah melatih pada seluruh dataset alih-alih subset kecil dan menjalankan proses fine-tuning setidaknya selama 3 epoch. Anda juga dapat meningkatkan rank LoRA untuk memberi kapasitas belajar lebih besar pada adapter, serta memperhalus system prompt agar model lebih konsisten mengikuti gaya jawaban medis yang diinginkan.
Perubahan ini kemungkinan menghasilkan peningkatan yang lebih stabil di berbagai jenis pertanyaan.
Melakukan fine-tuning model bahasa modern tidak sesederhana yang terlihat pada awalnya.
Meskipun Qwen3.6-35B-A3B adalah model mixture-of-experts yang efisien dengan total 35 miliar parameter, tetap dibutuhkan komputasi serius hanya untuk memuatnya dalam mode 4-bit dan menyiapkannya untuk pelatihan. Pelatihan itu sendiri juga tetap mahal, terutama ketika Anda melampaui subset eksperimental kecil dan mulai bekerja dengan dataset yang lebih besar atau beberapa epoch.
Perangkat keras juga sangat berpengaruh. Dalam tutorial ini, kita menggunakan H100 NVL agar alur kerja tetap praktis. Pada GPU yang lebih lama, waktu pelatihan dapat meningkat drastis. Bahkan pada A100, pengaturan serupa bisa dengan mudah memakan waktu sekitar satu jam, dan GPU yang lebih lemah akan membutuhkan waktu jauh lebih lama.
Jadi meskipun QLoRA dan pemuatan 4-bit membuat fine-tuning lebih mudah diakses, itu tidak membuatnya ringan dalam pengertian sehari-hari. Juga patut dipertanyakan apakah fine-tuning memang diperlukan sejak awal. Untuk banyak tugas dasar, saya tidak menyarankan langsung melakukan fine-tuning.
Jika Anda meluangkan waktu untuk memperbaiki prompt, menata alur kerja dengan lebih baik, serta menggunakan tools, MCP, atau metode berbasis retrieval, Anda sering kali dapat mendekati perilaku target tanpa pelatihan sama sekali. Dalam banyak kasus, itu bisa mendekati 80% dari hasil yang Anda inginkan, sekaligus jauh lebih cepat, murah, dan mudah untuk diiterasi.
Fine-tuning menjadi jauh lebih bernilai ketika Anda perlu model secara konsisten mempelajari gaya respons yang sangat spesifik, perilaku domain, atau format institusional. Di situlah ini mulai masuk akal. Jika Anda ingin model menjawab persis seperti cara rumah sakit tertentu, sistem medis, atau alur kerja spesialis merespons pertanyaan, maka fine-tuning adalah jalur yang lebih tepat.
Dengan kata lain, gunakan terlebih dahulu perancangan prompt dan alur kerja, dan beralih ke fine-tuning saat Anda benar-benar membutuhkan model untuk menginternalisasi cara berespons yang terspesialisasi.
Kursus AI Teratas
Program
Program
Kursus
blogs
Dario Radečić
15 mnt
blogs
David Woods
13 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
