
Lernpfad
Associate AI Engineer für Entwickler
26 Std.
Qwen3.6-35B-A3B ist ein leichtgewichtiges Mixture-of-Experts-Modell für starke Leistungen bei Coding, Reasoning und Aufgaben mit langem Kontext. Es nutzt insgesamt 35B Parameter, mit 3B aktiven Parametern pro Token. Dadurch läuft es effizienter, liefert aber dennoch starke Performance. Außerdem unterstützt es ein Kontextfenster von 262K Tokens und ist damit nützlich für größere Codebasen, lange Dokumente und mehrstufige Workflows.
Das Modell schneidet besonders gut auf Coding- und Agent-Benchmarks ab, mit starken Ergebnissen bei SWE-bench, Terminal-Bench und Claw-Eval. Gleichzeitig bleibt es bei umfassenderen Reasoning- und Wissensbenchmarks wie GPQA, AIME 2026, MMLU-Pro und C-Eval konkurrenzfähig. Das macht es zu einem starken Basismodell für Feinabstimmungs-Experimente, die sowohl praktische Aufgabenleistung als auch allgemeine Denkfähigkeit erfordern.
In diesem Guide richten wir eine RunPod H100 NVL Umgebung ein, bereiten das Projekt vor, laden und bereinigen einen medizinischen Q&A-Datensatz, führen Qwen3.6 in 4‑Bit‑Quantisierung aus, formatieren Prompts, bauen Evaluation-Helper, testen das Basismodell vor der Feinabstimmung, trainieren und speichern den Adapter und vergleichen das Modell danach erneut.
Hinweis: Dieses Tutorial zeigt den technischen Feinabstimmungsprozess ausschließlich zu Lernzwecken. Das resultierende Modell ist nicht für medizinische oder klinische Zwecke bestimmt und darf nicht für Diagnose, Entscheidungen oder Patientenversorgung herangezogen werden.
Im ersten Abschnitt starten wir eine RunPod H100 NVL Instanz, installieren die benötigten Bibliotheken, verbinden uns mit Hugging Face und definieren die zentrale Projektkonfiguration.
Gehe zunächst zu RunPod und wähle eine H100 NVL GPU-Maschine. Diese GPU bietet rund 94 GB VRAM und 94 GB Systemspeicher – ausreichend für diesen Qwen3.6-Feinabstimmungs-Workflow.
Wähle das neueste PyTorch-Template und bearbeite vor dem Deployment die Pod-Konfiguration. Setze die Container-Disk auf 100 GB und die Volume-Disk auf 200 GB. So hast du genug Platz, um das Modell herunterzuladen, Abhängigkeiten zu cachen und den feinabgestimmten Adapter lokal zu speichern.
Füge in diesem Schritt außerdem eine HF_TOKEN-Umgebungsvariable hinzu. So kannst du dich später bei Hugging Face anmelden, den Modelldownload verbessern und den Upload des feinabgestimmten Modells in den Hub nach dem Training erleichtern.
Bevor du die Instanz startest, prüfe die Pod-Zusammenfassung, um die geschätzten Kosten zu sehen. Wenn alles passt, deploye den Pod.
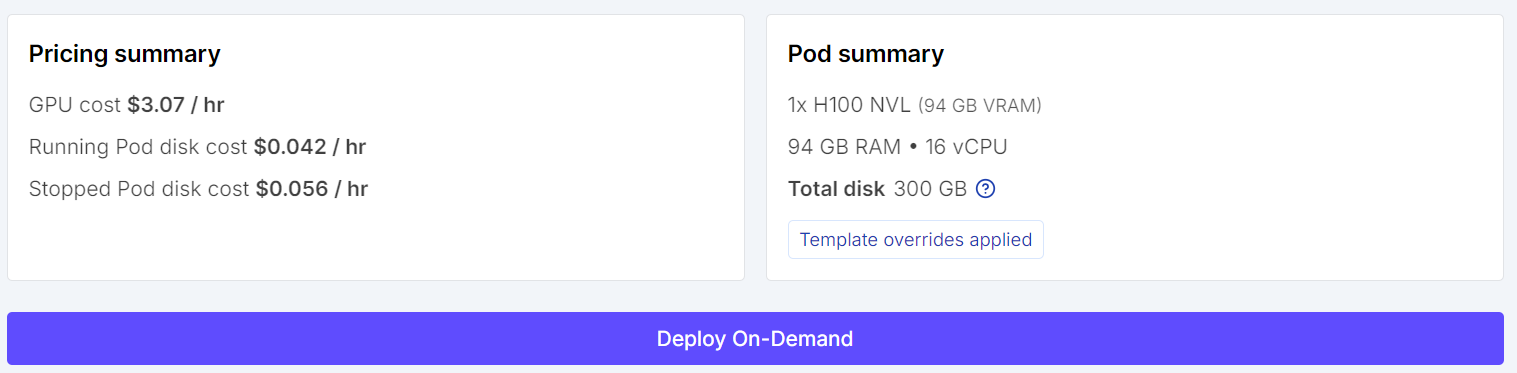
Sobald der Pod bereit ist, öffne den Jupyter-Notebook-Link im RunPod-Dashboard, um JupyterLab zu starten. Erstelle ein neues Python-Notebook und installiere die Bibliotheken für quantisierte Feinabstimmung, Datensatzladen und Supervised Fine-Tuning mit TRL.
pip install -q -U transformers accelerate peft trl bitsandbytes datasets sentencepieceMelde dich als Nächstes bei Hugging Face mit der HF_TOKEN-Umgebungsvariablen an, die du beim Erstellen des Pods hinzugefügt hast. So musst du den Token nicht im Notebook hardcoden und der Workflow bleibt aufgeräumt.
import os
from huggingface_hub import login
hf_token = os.getenv("HF_TOKEN")
login(token=hf_token)Importiere nun die benötigten Bibliotheken und definiere die Konfigurationswerte, die wir im gesamten Tutorial verwenden. Dazu gehören die Modell-ID, der Datensatzname, Stichprobengrößen, Ausgabeverzeichnis und Zufallssamen.
import os
import random
import re
import torch
from datasets import load_dataset
from peft import LoraConfig, prepare_model_for_kbit_training
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
set_seed,
)
from trl import SFTConfig, SFTTrainer
MODEL_ID = "Qwen/Qwen3.6-35B-A3B"
DATASET_ID = "keivalya/MedQuad-MedicalQnADataset"
SAMPLE_SIZE = 240
EVAL_SIZE = 24
COMPARISON_SAMPLE_COUNT = 3
MAX_SEQ_LENGTH = 768
OUTPUT_DIR = "qwen36-medquad-quick"
SEED = 42
set_seed(SEED)
random.seed(SEED)
def supports_bf16() -> bool:
return torch.cuda.is_available() and torch.cuda.get_device_capability(0)[0] >= 8
print(f"PyTorch: {torch.__version__}")
print(f"CUDA available: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"GPU: {torch.cuda.get_device_name(0)}")
print(
f"GPU memory (GB): {torch.cuda.get_device_properties(0).total_memory / 1024**3:.1f}"
)Wenn du diese Zelle ausführst, solltest du sehen, dass CUDA verfügbar ist und das Notebook mit einer NVIDIA H100 NVL GPU verbunden ist.
PyTorch: 2.8.0+cu128
CUDA available: True
GPU: NVIDIA H100 NVL
GPU memory (GB): 93.1In diesem Teil laden wir den medizinischen MedQuad Q&A-Datensatz, bereinigen die Textfelder, filtern minderwertige Beispiele heraus und erstellen kleine Trainings- und Evaluationssplits für eine schnelle Feinabstimmung.
Wir beginnen mit dem Laden des Trainingssplits von MedQuad aus Hugging Face. Anschließend inspizieren wir die Struktur, Spaltennamen und das erste Beispiel, um zu verstehen, mit welchen medizinischen Frage-Antwort-Paaren wir arbeiten.
raw_dataset = load_dataset(DATASET_ID, split="train")
print(raw_dataset)
print("First example:", raw_dataset[0])Das zeigt, dass der MedQuad-Datensatz 16.407 medizinische Frage-Antwort-Beispiele in drei Feldern enthält: qtype, Question und Answer.
Dataset({
features: ['qtype', 'Question', 'Answer'],
num_rows: 16407
})
First example: {'qtype': 'susceptibility', 'Question': 'Who is at risk for Lymphocytic Choriomeningitis (LCM)? ?', 'Answer': 'LCMV infections can occur after exposure to fresh urine, droppings, saliva, or nesting materials from infected rodents. Transmission may also occur when these materials are directly introduced into broken skin, the nose, the eyes, or the mouth, or presumably, via the bite of an infected rodent. Person-to-person transmission has not been reported, with the exception of vertical transmission from infected mother to fetus, and rarely, through organ transplantation.'}Als Nächstes definieren wir eine kleine Textbereinigungsfunktion und eine Filterregel, um minderwertige Samples zu entfernen. Die Bereinigung normalisiert überflüssige Leerzeichen, während die Filterung Beispiele mit sehr kurzen Fragen, sehr kurzen Antworten, zu langen Antworten oder generischen Antwortschablonen entfernt, die fürs Training wenig hilfreich sind.
def clean_text(text):
text = re.sub(r"\s+", " ", str(text)).strip()
return text
BAD_ANSWER_PREFIXES = (
"These resources address",
"These resources from MedlinePlus",
"For more information, go to",
"For more information go to",
)
def keep_example(example):
question = clean_text(example["Question"])
answer = clean_text(example["Answer"])
if len(question) < 12 or len(answer) < 40:
return False
if len(answer) > 900:
return False
if any(answer.startswith(prefix) for prefix in BAD_ANSWER_PREFIXES):
return False
return True
filtered_dataset = raw_dataset.filter(keep_example)Nach dem Filtern mischen wir den Datensatz, wählen für dieses kurze Tutorial eine kleinere Teilmenge aus und teilen sie in Trainings- und Evaluationsdaten. So bleibt der Lauf schlank, erlaubt aber dennoch den Vergleich vor und nach der Feinabstimmung.
subset = filtered_dataset.shuffle(seed=SEED).select(range(SAMPLE_SIZE))
split_dataset = subset.train_test_split(test_size=EVAL_SIZE, seed=SEED)
train_dataset = split_dataset["train"]
eval_dataset = split_dataset["test"]
print(f"Filtered dataset size: {len(filtered_dataset)}")
print(f"Train size: {len(train_dataset)}")
print(f"Eval size: {len(eval_dataset)}")Nach dem Filtern bleiben 7.355 höherwertige Beispiele übrig. Daraus ziehen wir 216 Trainingsbeispiele und 24 Evaluationsbeispiele für diesen schnellen Feinabstimmungsdurchlauf.
Filtered dataset size: 7355
Train size: 216
Eval size: 24In diesem Schritt konfigurieren wir 4‑Bit‑Quantisierung mit BitsAndBytes, laden den Qwen3.6-Tokenizer und anschließend das Basismodell, damit es auf der H100 NVL GPU effizienter läuft.
Qwen3.6 ist weiterhin ein großes Modell. In Vollpräzision zu laden würde deutlich mehr Speicher beanspruchen. Um die Feinabstimmung effizienter zu machen, laden wir das Modell mit BitsAndBytes in 4‑Bit-Präzision. Das reduziert den Speicherbedarf und bleibt dennoch praxistauglich für QLoRA-basierte Feinabstimmung.
Hier verwenden wir nf4-Quantisierung, aktivieren Double Quantization und setzen den Compute-Datentyp auf bfloat16, sofern die GPU ihn unterstützt.
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16 if supports_bf16() else torch.float16,
)Als Nächstes laden wir den Tokenizer für Qwen3.6. Wir prüfen außerdem, ob bereits ein Padding-Token definiert ist. Falls nicht, verwenden wir das End-of-Sequence-Token als Padding-Token, damit Batching während Training und Generierung korrekt funktioniert.
tokenizer = AutoTokenizer.from_pretrained(
MODEL_ID,
trust_remote_code=True,
use_fast=False,
)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_tokenJetzt laden wir das Qwen3.6-Basismodell mit den zuvor definierten 4‑Bit‑Einstellungen. Mit device_map="auto" wird das Modell automatisch auf die verfügbare GPU gelegt. Außerdem nutzen wir, wenn unterstützt, erneut bfloat16 für effizientere Berechnungen.
Nach dem Laden setzen wir die Padding-Token-ID und deaktivieren den Cache. Caching ist für Inferenz hilfreich, kann während der Feinabstimmung jedoch stören und den Speicherverbrauch erhöhen.
model = AutoModelForCausalLM.from_pretrained(
MODEL_ID,
quantization_config=bnb_config,
device_map="auto",
dtype=torch.bfloat16 if supports_bf16() else torch.float16,
trust_remote_code=True,
)
model.config.pad_token_id = tokenizer.pad_token_id
model.config.use_cache = FalseIn diesem Schritt definieren wir die Promptstruktur für Qwen3.6, bereinigen Modellantworten, erstellen Helper-Funktionen für Training und Inferenz und bereiten einige Vorschau-Beispiele vor, um das Modell vor und nach der Feinabstimmung zu vergleichen.
Wir beginnen mit einem kurzen System-Prompt, der dem Modell die gewünschte Antwortweise vorgibt. Da es um medizinische Q&A geht, sollen die Antworten direkt, faktenbasiert und knapp sein.
SYSTEM_PROMPT = "Answer the medical question directly in 2-4 factual sentences."Qwen3.6 verwendet ein Chat-basiertes Eingabeformat, daher brauchen wir eine Helper-Funktion, die unsere Nachrichten in die richtige Promptstruktur umwandelt. Diese Funktion nutzt das Chat-Template des Tokenizers und deaktiviert Reasoning-Ausgaben, damit sich das Modell auf die finale Antwort konzentriert.
def apply_chat_template(messages, add_generation_prompt=False):
kwargs = {
"tokenize": False,
"add_generation_prompt": add_generation_prompt,
}
try:
return tokenizer.apply_chat_template(
messages,
enable_thinking=False,
**kwargs,
)
except TypeError:
return tokenizer.apply_chat_template(
messages,
chat_template_kwargs={"enable_thinking": False},
**kwargs,
)Als Nächstes definieren wir eine kleine Bereinigungsfunktion, um den generierten Text zu normalisieren. Sie entfernt überflüssige Leerzeichen und streicht ggf. ein führendes answer:-Präfix aus der Ausgabe.
def clean_answer_text(answer):
answer = clean_text(answer)
answer = re.sub(r"^answer\s*:\s*", "", answer, flags=re.IGNORECASE)
return answerWir erstellen außerdem eine Helper-Funktion für den User-Prompt. So bleibt das Frageformat in Training und Evaluation konsistent, und das Modell wird angewiesen, nur die Antwort zurückzugeben, ohne die Frage zu wiederholen.
def make_user_prompt(question):
return (
f"Question: {clean_text(question)}\n\n"
"Respond with only the answer. Do not restate the question."
)Jetzt können wir jedes Datensatzbeispiel in eine vollständige Chat-Unterhaltung mit Systemnachricht, Nutzerfrage und erwarteter Assistenzantwort formatieren. Diese Struktur nutzen wir für das Supervised Fine-Tuning.
def format_training_example(example):
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": make_user_prompt(example["Question"]),
},
{
"role": "assistant",
"content": clean_answer_text(example["Answer"]),
},
]
return {"text": apply_chat_template(messages, add_generation_prompt=False)}Bevor wir mit dem Training starten, brauchen wir eine Helper-Funktion, die Antworten aus dem Basismodell erzeugt. Damit vergleichen wir die Antworten vor und nach der Feinabstimmung.
Die folgende Funktion baut den Prompt, tokenisiert ihn, führt die Generierung aus und entfernt anschließend etwaige <think>-Spuren sowie überflüssige Formatierungen aus der Ausgabe.
@torch.inference_mode()
def generate_answer(question, max_new_tokens=160):
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": make_user_prompt(question),
},
]
prompt = apply_chat_template(messages, add_generation_prompt=True)
model_inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
generated = model.generate(
**model_inputs,
max_new_tokens=max_new_tokens,
do_sample=False,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
new_tokens = generated[0][model_inputs["input_ids"].shape[1] :]
text = tokenizer.decode(new_tokens, skip_special_tokens=True).strip()
return clean_answer_text(re.sub(r"<think>.*?</think>", " ", text, flags=re.DOTALL))Außerdem fügen wir eine kleine Helper-Funktion hinzu, um lange Ausgaben in Vorschauen zu kürzen.
def clip_text(text, max_chars=600):
text = re.sub(r"<think>.*?</think>", " ", text, flags=re.DOTALL)
text = re.sub(r"\s+", " ", text).strip()
return text if len(text) <= max_chars else text[:max_chars] + "..."Zum Schluss bauen wir eine Helper-Funktion, die einige Nebeneinander-Vorschauen erzeugt. Jede Zeile enthält die Frage, die Modellvorhersage und die Referenzantwort. So können wir die Performance vor und nach der Feinabstimmung einfach prüfen.
def generate_preview_rows(dataset, sample_count=COMPARISON_SAMPLE_COUNT):
sample_count = min(sample_count, len(dataset))
subset = dataset.select(range(sample_count))
previews = []
for row in subset:
previews.append(
{
"question": row["Question"],
"prediction": generate_answer(row["Question"]),
"reference": clean_answer_text(row["Answer"]),
}
)
return previews
formatted_train_dataset = train_dataset.map(
format_training_example,
remove_columns=train_dataset.column_names,
)
comparison_examples = eval_dataset.shuffle(seed=SEED).select(
range(COMPARISON_SAMPLE_COUNT)
)
print(formatted_train_dataset[0])Wenn du das erste formatierte Trainingsbeispiel ausgibst, solltest du ein Chat-ähnliches Sample mit System-Prompt, Nutzerfrage und Assistenzantwort sehen, eingebettet im Qwen-Templateformat.
{'text': '<|im_start|>system\nAnswer the medical question directly in 2-4 factual sentences.<|im_end|>\n<|im_start|>user\nQuestion: What is (are) COPD ?\n\nRespond with only the answer. Do not restate the question.<|im_end|>\n<|im_start|>assistant\n<think>\n\n</think>\n\nMore information on COPD is available at: What is COPD? and at the Learn More, Breathe Better Campaign For information on quitting smoking, visit http://www.surgeongeneral.gov/tobacco/ or Smokefree.gov. For information on the H1N1 flu and COPD, go to The Centers for Disease Control and Prevention.<|im_end|>\n'}Wir testen das Qwen3.6-Basismodell auf einigen Evaluationsbeispielen vor dem Training. So erhalten wir eine Basislinie, um später die Veränderungen nach der Feinabstimmung zu vergleichen.
Wir starten, indem wir Vorscha uantworten für einige zufällig ausgewählte Beispiele aus dem Evaluationsset generieren.
Jede Vorschau enthält die Frage, die Modellantwort vor der Feinabstimmung und die Referenzantwort aus dem Datensatz.
baseline_previews = generate_preview_rows(comparison_examples)
for idx, sample in enumerate(baseline_previews, start=1):
print(f"\n--- Preview {idx} ---")
print("Question:", sample["question"])
print("Model answer (before fine-tuning):", clip_text(sample["prediction"]))
print("Reference answer:", clip_text(sample["reference"]))Hier sind die Nebeneinander-Vergleiche zwischen der aktuellen Modellantwort und der Referenzantwort. Diese Beispiele helfen, den Ausgangszustand vor jeglichem aufgabenspezifischen Training zu verstehen.

Anhand dieser Beispiele sehen wir, dass das Basismodell bereits medizinisch relevante und im Allgemeinen korrekte Antworten erzeugen kann.
Allerdings entspricht der Stil, Detaillierungsgrad oder die Wortwahl nicht immer den Referenzantworten im Datensatz. Mitunter gibt das Modell eine breitere oder allgemeinere Erklärung, während die Referenz präziser und näher am Zielformat ist.
In diesem Teil definieren wir die LoRA-Adaptereinstellungen, konfigurieren die Argumente für das Supervised Fine-Tuning und initialisieren den Trainer, der das QLoRA-Training übernimmt.
Anstatt alle Modellparameter zu aktualisieren, passt QLoRA nur eine deutlich kleinere Menge trainierbarer Adaptergewichte an. So wird das Training erheblich speichereffizienter, während sich das Modell trotzdem an die neue Aufgabe anpasst.
Hier definieren wir eine LoRA-Konfiguration mit Rang 8, Skalierungsfaktor 16 und kleinem Dropout. Wir zielen außerdem auf alle linearen Schichten, damit die Adapter breit im Modell eingesetzt werden.
lora_config = LoraConfig(
r=8,
lora_alpha=16,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules="all-linear",
)Als Nächstes definieren wir die Trainingskonfiguration mit SFTConfig. Diese Einstellungen steuern den Ablauf des Supervised Fine-Tuning, einschließlich Batchgröße, Gradientenakkumulation, Lernrate, Logging-Frequenz und Präzisionsmodus.
Dieses Tutorial verwendet ein leichtgewichtiges Setup mit einer Epoche und kleiner Batchgröße, damit der Lauf für Demonstrationszwecke praktikabel bleibt. Außerdem aktivieren wir Gradient Checkpointing und paged 8‑Bit AdamW, um den Speicherverbrauch während des Trainings zu reduzieren.
trainer_config = SFTConfig(
output_dir=OUTPUT_DIR,
dataset_text_field="text",
max_length=MAX_SEQ_LENGTH,
per_device_train_batch_size=2,
gradient_accumulation_steps=2,
num_train_epochs=1,
learning_rate=1e-4,
warmup_steps=5,
logging_steps=5,
save_strategy="epoch",
report_to="none",
packing=False,
gradient_checkpointing=True,
optim="paged_adamw_8bit",
bf16=supports_bf16(),
fp16=not supports_bf16(),
)Mit den Adaptereinstellungen und Trainingsargumenten können wir nun den SFTTrainer initialisieren. Der Trainer verbindet Basismodell, formatierten Trainingsdatensatz, LoRA-Konfiguration und Tokenizer, sodass das Modell für Supervised Fine-Tuning bereit ist.
trainer = SFTTrainer(
model=model,
train_dataset=formatted_train_dataset,
peft_config=lora_config,
args=trainer_config,
processing_class=tokenizer,
)Vor dem Start ist es hilfreich zu prüfen, wie viele Parameter tatsächlich aktualisiert werden. Einer der Hauptvorteile von QLoRA ist, dass nur ein sehr kleiner Bruchteil des Modells trainierbar wird.
trainer.model.print_trainable_parameters()Das zeigt, dass nur etwa 0,03% der gesamten Modellparameter trainiert werden. Genau das macht QLoRA so praxistauglich, um große Sprachmodelle auf begrenzter Hardware feinabzustimmen.
trainable params: 11,238,720 || all params: 34,671,849,408 || trainable%: 0.0324In diesem Abschnitt starten wir das Supervised Fine-Tuning, speichern den trainierten Adapter lokal und pushen ihn anschließend zu Hugging Face, um ihn später wiederzuverwenden.
Da Modell, Datensatz und Trainer bereit sind, können wir mit der Feinabstimmung beginnen. Der Trainer durchläuft den formatierten Trainingssatz und aktualisiert nur die LoRA-Adaptergewichte statt des vollständigen Modells.
train_result = trainer.train()
train_resultWährend des Trainings solltest du sehen, wie der Loss schrittweise sinkt. Das ist ein gutes Zeichen dafür, dass das Modell das Aufgabenformat lernt und sich an die medizinischen Frage-Antwort-Daten anpasst.
Nach Abschluss des Trainings speicherst du den feinabgestimmten Adapter und den Tokenizer lokal. So erhältst du einen wiederverwendbaren Checkpoint, den du später ohne erneutes Volltraining laden kannst.
trainer.model.save_pretrained(OUTPUT_DIR)
tokenizer.save_pretrained(OUTPUT_DIR)Sobald der Adapter lokal gespeichert ist, kannst du ihn zu Hugging Face hochladen. Das erleichtert das Teilen, Versionieren und erneute Laden in künftigen Notebooks oder Deployments.
HF_REPO_ID = "kingabzpro/qwen36-medquad-quick"
trainer.model.push_to_hub(HF_REPO_ID)
tokenizer.push_to_hub(HF_REPO_ID) Nach dem Upload ist der feinabgestimmte Adapter im Repository verfügbar.
Nach dem Upload ist der feinabgestimmte Adapter im Repository verfügbar.
Quelle: kingabzpro/qwen36-medquad-quick
Da das Training abgeschlossen ist, evaluieren wir das feinabgestimmte Modell auf denselben Vergleichsbeispielen wie zuvor. So erhalten wir einen direkten Vorher-Nachher-Vergleich mit identischen Fragen.
model.eval()
fine_tuned_previews = generate_preview_rows(comparison_examples)
for idx, (before, after) in enumerate(
zip(baseline_previews, fine_tuned_previews), start=1
):
print(f"\n{'=' * 80}")
print(f"Sample {idx}")
print(f"{'=' * 80}")
print("Question:", before["question"])
print("\nBefore fine-tuning:")
print(clip_text(before["prediction"]))
print("\nAfter fine-tuning:")
print(clip_text(after["prediction"]))
print("\nReference answer:")
print(clip_text(before["reference"]))Du solltest für jedes Sample die Baseline-Antwort, die feinabgestimmte Antwort und die Referenz sehen. So lässt sich leicht beurteilen, wie sich Stil und Inhalt durch den Adapter verändert haben.

Diese Beispiele zeigen, dass die Feinabstimmung das Modell näher an den Stil des Zieldatensatzes herangeführt hat – besonders bei kürzeren, faktenbasierten medizinischen Fragen.
Gleichzeitig erkennt man, dass dies nur ein kleiner Feinabstimmungsdurchlauf auf einer begrenzten Teilmenge war. Verbesserungen sind daher nicht in jedem Fall garantiert. Manche Antworten passen sich stärker an die Trainingsverteilung an, andere verlieren nützliche Details oder werden zu eng.
Für bessere Ergebnisse wäre der nächste Schritt, das vollständige Dataset statt einer kleinen Teilmenge zu nutzen und mindestens 3 Epochen zu trainieren. Du könntest auch den LoRA-Rang erhöhen, um dem Adapter mehr Kapazität zu geben, und den System-Prompt weiter verfeinern, damit das Modell den gewünschten medizinischen Antwortstil konsistenter befolgt.
Diese Anpassungen dürften stabilere Verbesserungen über ein breiteres Fragenspektrum hinweg bringen.
Die Feinabstimmung eines modernen Sprachmodells ist komplexer, als es auf den ersten Blick wirkt.
Auch wenn Qwen3.6-35B-A3B als effizientes Mixture-of-Experts-Modell mit 35 Milliarden Parametern gilt, erfordert bereits das Laden im 4‑Bit‑Modus und die Trainingsvorbereitung erhebliche Rechenressourcen. Das eigentliche Training bleibt teuer – besonders, wenn du über kleine Experimente hinausgehst und mit größeren Datensätzen oder mehreren Epochen arbeitest.
Auch die Hardware macht einen großen Unterschied. In diesem Tutorial haben wir eine H100 NVL genutzt, um den Workflow praktikabel zu halten. Auf älteren GPUs steigt die Trainingszeit deutlich. Selbst auf einer A100 kann ein ähnliches Setup leicht rund eine Stunde dauern, schwächere GPUs brauchen entsprechend länger.
QLoRA und 4‑Bit‑Loading machen Feinabstimmung zwar zugänglicher, aber nicht „leichtgewichtig“ im Alltagsverständnis. Es lohnt sich auch zu fragen, ob Feinabstimmung überhaupt nötig ist. Für viele grundlegende Aufgaben würde ich nicht direkt mit Feinabstimmung starten.
Wenn du Zeit in besseres Prompting, eine saubere Prozessstruktur sowie Tools, MCPs oder Retrieval-Methoden investierst, kommst du oft nah an das Zielverhalten heran – ganz ohne Training. In vielen Fällen erreichst du so rund 80% des gewünschten Ergebnisses, deutlich schneller, günstiger und einfacher iterierbar.
Wertvoll wird Feinabstimmung vor allem dann, wenn das Modell konsistent einen sehr spezifischen Antwortstil, ein Domänenverhalten oder ein institutionelles Format lernen soll. Dann ergibt es Sinn. Soll das Modell beispielsweise genau so antworten, wie es in einem bestimmten Krankenhaus, Medizinsystem oder Spezial-Workflow üblich ist, ist Feinabstimmung der bessere Weg.
Kurz: Starte mit Prompting und Workflow-Design – und greife zur Feinabstimmung, wenn das Modell wirklich eine spezialisierte Antwortweise verinnerlichen soll.
Top-Kurse zu KI
Lernpfad
Lernpfad
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nisha Arya Ahmed
15 Min.
Tutorial
Matt Crabtree