
Cursus
Associate AI Engineer pour développeurs
26 h
Qwen3.6-35B-A3B est un modèle Mixture-of-Experts léger, conçu pour l’écriture de code, le raisonnement et les contextes longs. Il utilise 35 milliards de paramètres au total avec 3 milliards de paramètres actifs par jeton, ce qui le rend plus efficient à l’exécution tout en offrant d’excellentes performances. Il prend également en charge une fenêtre de contexte de 262 k jetons, utile pour de vastes bases de code, des documents longs et des workflows en plusieurs étapes.
Le modèle se distingue particulièrement sur les benchmarks orientés code et agents, avec de bons résultats sur SWE-bench, Terminal-Bench et Claw-Eval. Il reste également compétitif sur des benchmarks de raisonnement et de connaissances plus larges comme GPQA, AIME 2026, MMLU-Pro et C-Eval, ce qui en fait un excellent modèle de base pour des expériences d’ajustement fin nécessitant à la fois des performances pratiques sur les tâches et des capacités de raisonnement général.
Dans ce guide, nous allons configurer un environnement RunPod H100 NVL, préparer le projet, charger et nettoyer un jeu de données médicales de questions-réponses, exécuter Qwen3.6 en quantification 4 bits, formater les invites, créer des utilitaires d’évaluation, tester le modèle de base avant l’ajustement fin, entraîner et enregistrer l’adaptateur, puis comparer à nouveau le modèle après l’ajustement fin.
Avertissement : ce tutoriel illustre un processus technique d’ajustement fin à des fins pédagogiques uniquement. Le modèle obtenu n’est pas destiné à un usage médical ou clinique et ne doit pas être utilisé pour le diagnostic, la décision thérapeutique ou la prise en charge des patients.
Dans cette première section, nous allons lancer une instance RunPod H100 NVL, installer les bibliothèques requises, nous connecter à Hugging Face et définir la configuration principale du projet.
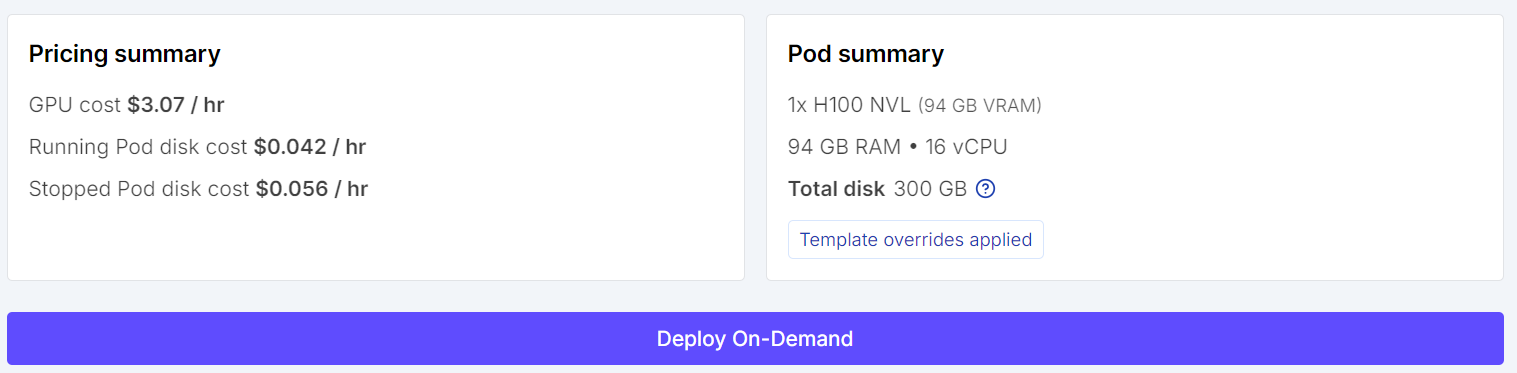
Commencez par aller sur RunPod et sélectionner une machine GPU H100 NVL. Ce GPU propose environ 94 Go de VRAM et 94 Go de RAM système, suffisants pour ce workflow d’ajustement fin de Qwen3.6.
Choisissez le dernier template PyTorch, puis modifiez la configuration du pod avant le déploiement. Réglez la taille du disque du conteneur à 100 Go et celle du volume à 200 Go. Cela vous laisse l’espace nécessaire pour télécharger le modèle, mettre en cache les dépendances et enregistrer localement l’adaptateur ajusté finement.
Vous devez également ajouter une variable d’environnement HF_TOKEN. Elle vous permettra de vous connecter à Hugging Face par la suite, d’améliorer l’accès au téléchargement du modèle et de faciliter la publication du modèle ajusté sur le Hub après l’entraînement.
Avant de lancer l’instance, passez en revue le récapitulatif du pod afin de vérifier le coût estimé. Une fois tout confirmé, déployez le pod.
Une fois le pod prêt, ouvrez le lien Jupyter Notebook depuis le tableau de bord RunPod pour lancer JupyterLab. Créez un nouveau notebook Python, puis installez les bibliothèques nécessaires à l’ajustement fin quantifié, au chargement du jeu de données et au Supervised Fine-Tuning avec TRL.
pip install -q -U transformers accelerate peft trl bitsandbytes datasets sentencepieceConnectez-vous ensuite à Hugging Face à l’aide de la variable d’environnement HF_TOKEN que vous avez ajoutée lors de la création du pod. Cela évite d’intégrer en dur votre jeton dans le notebook et garde le workflow plus propre.
import os
from huggingface_hub import login
hf_token = os.getenv("HF_TOKEN")
login(token=hf_token)Importez maintenant les bibliothèques requises et définissez les valeurs de configuration que nous utiliserons tout au long du tutoriel. Cela inclut l’ID du modèle, le nom du jeu de données, les tailles d’échantillons, le répertoire de sortie et la graine aléatoire.
import os
import random
import re
import torch
from datasets import load_dataset
from peft import LoraConfig, prepare_model_for_kbit_training
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
set_seed,
)
from trl import SFTConfig, SFTTrainer
MODEL_ID = "Qwen/Qwen3.6-35B-A3B"
DATASET_ID = "keivalya/MedQuad-MedicalQnADataset"
SAMPLE_SIZE = 240
EVAL_SIZE = 24
COMPARISON_SAMPLE_COUNT = 3
MAX_SEQ_LENGTH = 768
OUTPUT_DIR = "qwen36-medquad-quick"
SEED = 42
set_seed(SEED)
random.seed(SEED)
def supports_bf16() -> bool:
return torch.cuda.is_available() and torch.cuda.get_device_capability(0)[0] >= 8
print(f"PyTorch: {torch.__version__}")
print(f"CUDA available: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"GPU: {torch.cuda.get_device_name(0)}")
print(
f"GPU memory (GB): {torch.cuda.get_device_properties(0).total_memory / 1024**3:.1f}"
)Lorsque vous exécutez cette cellule, vous devez voir une sortie confirmant que CUDA est disponible et que le notebook est connecté à un GPU NVIDIA H100 NVL.
PyTorch: 2.8.0+cu128
CUDA available: True
GPU: NVIDIA H100 NVL
GPU memory (GB): 93.1Dans cette partie, nous allons charger le jeu de données médicales de questions-réponses MedQuad, nettoyer les champs texte, filtrer les exemples de moindre qualité et créer de petits jeux d’entraînement et d’évaluation pour un ajustement fin rapide.
Nous commençons par charger la division d’entraînement du jeu de données MedQuad depuis Hugging Face. Après le chargement, nous inspectons la structure, les noms de colonnes et le premier exemple pour comprendre le type de paires question-réponse médicales utilisées.
raw_dataset = load_dataset(DATASET_ID, split="train")
print(raw_dataset)
print("First example:", raw_dataset[0])On observe que le jeu de données MedQuad contient 16 407 exemples de questions-réponses médicales répartis sur trois champs : qtype, Question et Answer.
Dataset({
features: ['qtype', 'Question', 'Answer'],
num_rows: 16407
})
First example: {'qtype': 'susceptibility', 'Question': 'Who is at risk for Lymphocytic Choriomeningitis (LCM)? ?', 'Answer': 'LCMV infections can occur after exposure to fresh urine, droppings, saliva, or nesting materials from infected rodents. Transmission may also occur when these materials are directly introduced into broken skin, the nose, the eyes, or the mouth, or presumably, via the bite of an infected rodent. Person-to-person transmission has not been reported, with the exception of vertical transmission from infected mother to fetus, and rarely, through organ transplantation.'}Nous définissons ensuite une petite fonction de nettoyage de texte et une règle de filtrage pour supprimer les échantillons de faible qualité. Le nettoyage normalise les espaces superflus, tandis que le filtrage écarte les exemples avec des questions très courtes, des réponses trop courtes, des réponses trop longues ou des modèles de réponses génériques moins utiles pour l’entraînement.
def clean_text(text):
text = re.sub(r"\s+", " ", str(text)).strip()
return text
BAD_ANSWER_PREFIXES = (
"These resources address",
"These resources from MedlinePlus",
"For more information, go to",
"For more information go to",
)
def keep_example(example):
question = clean_text(example["Question"])
answer = clean_text(example["Answer"])
if len(question) < 12 or len(answer) < 40:
return False
if len(answer) > 900:
return False
if any(answer.startswith(prefix) for prefix in BAD_ANSWER_PREFIXES):
return False
return True
filtered_dataset = raw_dataset.filter(keep_example)Après filtrage, nous mélangeons le jeu de données, sélectionnons un sous-ensemble plus petit pour ce tutoriel rapide, puis le divisons en jeux d’entraînement et d’évaluation. Cela garde l’exécution légère tout en nous permettant de comparer le modèle avant et après l’ajustement fin.
subset = filtered_dataset.shuffle(seed=SEED).select(range(SAMPLE_SIZE))
split_dataset = subset.train_test_split(test_size=EVAL_SIZE, seed=SEED)
train_dataset = split_dataset["train"]
eval_dataset = split_dataset["test"]
print(f"Filtered dataset size: {len(filtered_dataset)}")
print(f"Train size: {len(train_dataset)}")
print(f"Eval size: {len(eval_dataset)}")Après filtrage, 7 355 exemples de meilleure qualité restent. Nous en échantillonnons 216 pour l’entraînement et 24 pour l’évaluation lors de cette exécution d’ajustement fin rapide.
Filtered dataset size: 7355
Train size: 216
Eval size: 24Dans cette étape, nous allons configurer la quantification 4 bits avec BitsAndBytes, charger le tokenizer Qwen3.6, puis charger le modèle de base pour qu’il fonctionne plus efficacement sur le GPU H100 NVL.
Qwen3.6 reste un grand modèle, donc un chargement en pleine précision utiliserait bien plus de mémoire. Pour rendre l’ajustement fin plus efficient, nous chargeons le modèle en précision 4 bits avec BitsAndBytes. Cela réduit l’usage mémoire tout en gardant le modèle exploitable pour un ajustement fin basé sur QLoRA.
Ici, nous utilisons la quantification nf4, activons la double quantification, et définissons le type de calcul sur bfloat16 lorsque le GPU le prend en charge.
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16 if supports_bf16() else torch.float16,
)Ensuite, nous chargeons le tokenizer de Qwen3.6. Nous vérifions aussi si un jeton de padding est déjà défini. S’il manque, nous réutilisons le jeton de fin de séquence comme jeton de padding afin que le batching fonctionne correctement pendant l’entraînement et la génération.
tokenizer = AutoTokenizer.from_pretrained(
MODEL_ID,
trust_remote_code=True,
use_fast=False,
)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_tokenNous chargeons maintenant le modèle Qwen3.6 de base avec les paramètres de quantification 4 bits définis précédemment. Nous utilisons device_map="auto" pour placer automatiquement le modèle sur le GPU disponible, et nous utilisons à nouveau le bfloat16 lorsqu’il est pris en charge pour des calculs plus efficients.
Après le chargement, nous définissons l’ID du jeton de padding et désactivons le cache. C’est important car le cache aide en inférence, mais pendant l’ajustement fin, il peut perturber l’entraînement et augmenter l’utilisation mémoire.
model = AutoModelForCausalLM.from_pretrained(
MODEL_ID,
quantization_config=bnb_config,
device_map="auto",
dtype=torch.bfloat16 if supports_bf16() else torch.float16,
trust_remote_code=True,
)
model.config.pad_token_id = tokenizer.pad_token_id
model.config.use_cache = FalseDans cette étape, nous allons définir la structure de l’invite pour Qwen3.6, nettoyer les sorties du modèle, créer des fonctions utilitaires pour l’entraînement et l’inférence, et préparer quelques échantillons de prévisualisation pour comparer le modèle avant et après l’ajustement fin.
Nous commençons par définir une courte invite système indiquant au modèle comment répondre. Étant donné qu’il s’agit d’une tâche de questions-réponses médicales, nous voulons des réponses directes, factuelles et concises.
SYSTEM_PROMPT = "Answer the medical question directly in 2-4 factual sentences."Qwen3.6 utilise un format d’entrée de type chat, nous avons donc besoin d’une fonction utilitaire qui convertit nos messages dans la structure d’invite correcte. Cette fonction applique le modèle de chat du tokenizer et désactive la sortie de raisonnement afin que le modèle se concentre sur la réponse finale.
def apply_chat_template(messages, add_generation_prompt=False):
kwargs = {
"tokenize": False,
"add_generation_prompt": add_generation_prompt,
}
try:
return tokenizer.apply_chat_template(
messages,
enable_thinking=False,
**kwargs,
)
except TypeError:
return tokenizer.apply_chat_template(
messages,
chat_template_kwargs={"enable_thinking": False},
**kwargs,
)Nous définissons ensuite une petite fonction de nettoyage pour normaliser le texte généré. Elle supprime les espaces superflus et retire tout préfixe de type answer: au début de la sortie s’il apparaît.
def clean_answer_text(answer):
answer = clean_text(answer)
answer = re.sub(r"^answer\s*:\s*", "", answer, flags=re.IGNORECASE)
return answerNous créons également une fonction utilitaire pour l’invite utilisateur. Elle garde un format de question cohérent pour l’entraînement et l’évaluation, et demande au modèle de ne renvoyer que la réponse sans répéter la question.
def make_user_prompt(question):
return (
f"Question: {clean_text(question)}\n\n"
"Respond with only the answer. Do not restate the question."
)Nous pouvons maintenant formater chaque exemple du jeu de données en une conversation de type chat avec un message système, une question utilisateur et la réponse attendue de l’assistant. C’est la structure que nous utiliserons pour l’ajustement fin supervisé.
def format_training_example(example):
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": make_user_prompt(example["Question"]),
},
{
"role": "assistant",
"content": clean_answer_text(example["Answer"]),
},
]
return {"text": apply_chat_template(messages, add_generation_prompt=False)}Avant de commencer l’entraînement, nous avons besoin d’une fonction utilitaire pour générer des réponses avec le modèle de base. Nous l’utiliserons pour comparer les réponses du modèle avant et après l’ajustement fin.
La fonction ci-dessous construit l’invite, la tokenise, lance la génération, puis retire toute trace de <think> et le formatage superflu de la sortie.
@torch.inference_mode()
def generate_answer(question, max_new_tokens=160):
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": make_user_prompt(question),
},
]
prompt = apply_chat_template(messages, add_generation_prompt=True)
model_inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
generated = model.generate(
**model_inputs,
max_new_tokens=max_new_tokens,
do_sample=False,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
new_tokens = generated[0][model_inputs["input_ids"].shape[1] :]
text = tokenizer.decode(new_tokens, skip_special_tokens=True).strip()
return clean_answer_text(re.sub(r"<think>.*?</think>", " ", text, flags=re.DOTALL))Nous ajoutons aussi une petite fonction utilitaire pour raccourcir les longues sorties lors de l’affichage des aperçus.
def clip_text(text, max_chars=600):
text = re.sub(r"<think>.*?</think>", " ", text, flags=re.DOTALL)
text = re.sub(r"\s+", " ", text).strip()
return text if len(text) <= max_chars else text[:max_chars] + "..."Enfin, nous construisons une fonction utilitaire qui crée quelques lignes d’aperçu côte à côte. Chaque ligne contient la question, la prédiction du modèle et la réponse de référence. Cela nous offre un moyen simple d’inspecter les performances avant et après l’ajustement fin.
def generate_preview_rows(dataset, sample_count=COMPARISON_SAMPLE_COUNT):
sample_count = min(sample_count, len(dataset))
subset = dataset.select(range(sample_count))
previews = []
for row in subset:
previews.append(
{
"question": row["Question"],
"prediction": generate_answer(row["Question"]),
"reference": clean_answer_text(row["Answer"]),
}
)
return previews
formatted_train_dataset = train_dataset.map(
format_training_example,
remove_columns=train_dataset.column_names,
)
comparison_examples = eval_dataset.shuffle(seed=SEED).select(
range(COMPARISON_SAMPLE_COUNT)
)
print(formatted_train_dataset[0])Lorsque vous affichez le premier exemple d’entraînement formaté, vous devez voir un échantillon de type chat avec l’invite système, la question utilisateur et la réponse de l’assistant déjà encapsulées dans le format de template de Qwen.
{'text': '<|im_start|>system\nAnswer the medical question directly in 2-4 factual sentences.<|im_end|>\n<|im_start|>user\nQuestion: What is (are) COPD ?\n\nRespond with only the answer. Do not restate the question.<|im_end|>\n<|im_start|>assistant\n<think>\n\n</think>\n\nMore information on COPD is available at: What is COPD? and at the Learn More, Breathe Better Campaign For information on quitting smoking, visit http://www.surgeongeneral.gov/tobacco/ or Smokefree.gov. For information on the H1N1 flu and COPD, go to The Centers for Disease Control and Prevention.<|im_end|>\n'}Nous allons tester le modèle Qwen3.6 de base sur quelques exemples d’évaluation avant l’entraînement. Cela nous donne une base de référence pour comparer ensuite l’évolution du modèle après l’ajustement fin.
Nous commençons par générer des réponses d’aperçu pour quelques exemples échantillonnés du jeu d’évaluation.
Chaque aperçu inclut la question, la réponse du modèle avant l’ajustement fin et la réponse de référence du jeu de données.
baseline_previews = generate_preview_rows(comparison_examples)
for idx, sample in enumerate(baseline_previews, start=1):
print(f"\n--- Preview {idx} ---")
print("Question:", sample["question"])
print("Model answer (before fine-tuning):", clip_text(sample["prediction"]))
print("Reference answer:", clip_text(sample["reference"]))Voici les comparaisons côte à côte entre la réponse actuelle du modèle et la réponse de référence. Ces exemples nous aident à comprendre le point de départ du modèle avant tout entraînement spécifique à la tâche.

Ces exemples montrent déjà que le modèle de base est capable de produire des réponses médicales pertinentes et généralement correctes.
Cependant, ses réponses ne correspondent pas toujours au style, au niveau de détail ou au phrasé des réponses de référence du jeu de données. Dans certains cas, le modèle fournit une explication plus large ou générique, tandis que la réponse de référence est plus spécifique et mieux alignée sur le format cible.
Dans cette partie, nous allons définir les paramètres de l’adaptateur LoRA, configurer les arguments d’ajustement fin supervisé et initialiser l’entraîneur qui gèrera le processus QLoRA.
Au lieu de mettre à jour tous les paramètres du modèle, QLoRA n’ajuste finement qu’un petit ensemble de poids d’adaptateur entraînables. Cela rend l’entraînement bien plus économe en mémoire tout en permettant au modèle de s’adapter à la nouvelle tâche.
Ici, nous définissons une configuration LoRA avec un rang de 8, un facteur d’échelle de 16 et un petit taux de dropout. Nous ciblons également toutes les couches linéaires pour appliquer les adaptateurs de manière large dans le modèle.
lora_config = LoraConfig(
r=8,
lora_alpha=16,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules="all-linear",
)Nous définissons ensuite la configuration d’entraînement avec SFTConfig. Ces paramètres contrôlent le déroulement de l’ajustement fin supervisé, notamment la taille de lot, l’accumulation de gradients, le taux d’apprentissage, la fréquence de journalisation et le mode de précision.
Ce tutoriel utilise une configuration légère avec une seule époque d’entraînement et une petite taille de lot, pour garder l’exécution pratique. Nous activons aussi le gradient checkpointing et l’optimiseur AdamW paginé en 8 bits pour réduire l’usage mémoire pendant l’entraînement.
trainer_config = SFTConfig(
output_dir=OUTPUT_DIR,
dataset_text_field="text",
max_length=MAX_SEQ_LENGTH,
per_device_train_batch_size=2,
gradient_accumulation_steps=2,
num_train_epochs=1,
learning_rate=1e-4,
warmup_steps=5,
logging_steps=5,
save_strategy="epoch",
report_to="none",
packing=False,
gradient_checkpointing=True,
optim="paged_adamw_8bit",
bf16=supports_bf16(),
fp16=not supports_bf16(),
)Avec les paramètres d’adaptateur et d’entraînement en place, nous pouvons maintenant initialiser le SFTTrainer. Cet entraîneur réunit le modèle de base, le jeu de données d’entraînement formaté, la configuration LoRA et le tokenizer pour préparer le modèle à l’ajustement fin supervisé.
trainer = SFTTrainer(
model=model,
train_dataset=formatted_train_dataset,
peft_config=lora_config,
args=trainer_config,
processing_class=tokenizer,
)Avant de démarrer l’entraînement, il est utile de confirmer combien de paramètres seront réellement mis à jour. L’un des principaux atouts de QLoRA est qu’une très petite fraction du modèle devient entraînable.
trainer.model.print_trainable_parameters()On voit qu’environ 0,03 % des paramètres du modèle complet sont entraînés. C’est ce qui rend QLoRA si pratique pour ajuster finement de grands modèles de langue sur du matériel limité.
trainable params: 11,238,720 || all params: 34,671,849,408 || trainable%: 0.0324Dans cette section, nous allons lancer l’ajustement fin supervisé, enregistrer localement l’adaptateur entraîné, puis le pousser sur Hugging Face pour une réutilisation ultérieure.
Maintenant que le modèle, le jeu de données et l’entraîneur sont prêts, nous pouvons commencer l’ajustement fin. L’entraîneur parcourra le jeu d’entraînement formaté et n’actualisera que les poids de l’adaptateur LoRA, pas l’ensemble du modèle.
train_result = trainer.train()
train_resultAu fil de l’entraînement, vous devriez voir la perte diminuer progressivement. C’est un bon signe que le modèle apprend le format de la tâche et s’adapte aux données de questions-réponses médicales.
Une fois l’entraînement terminé, enregistrez localement l’adaptateur ajusté finement et le tokenizer. Vous obtenez ainsi un point de contrôle réutilisable que vous pourrez recharger plus tard sans relancer tout l’entraînement.
trainer.model.save_pretrained(OUTPUT_DIR)
tokenizer.save_pretrained(OUTPUT_DIR)Après avoir enregistré l’adaptateur en local, vous pouvez le téléverser sur Hugging Face. Cela facilite le partage, la gestion de versions et le rechargement du modèle ajusté dans de futurs notebooks ou workflows de déploiement.
HF_REPO_ID = "kingabzpro/qwen36-medquad-quick"
trainer.model.push_to_hub(HF_REPO_ID)
tokenizer.push_to_hub(HF_REPO_ID) Une fois le téléversement terminé, l’adaptateur ajusté finement sera disponible dans le dépôt.
Une fois le téléversement terminé, l’adaptateur ajusté finement sera disponible dans le dépôt.
Source : kingabzpro/qwen36-medquad-quick
Maintenant que l’entraînement est terminé, nous pouvons évaluer le modèle ajusté sur les mêmes exemples de comparaison utilisés plus tôt. Cela permet une comparaison avant/après directe sur exactement les mêmes questions.
model.eval()
fine_tuned_previews = generate_preview_rows(comparison_examples)
for idx, (before, after) in enumerate(
zip(baseline_previews, fine_tuned_previews), start=1
):
print(f"\n{'=' * 80}")
print(f"Sample {idx}")
print(f"{'=' * 80}")
print("Question:", before["question"])
print("\nBefore fine-tuning:")
print(clip_text(before["prediction"]))
print("\nAfter fine-tuning:")
print(clip_text(after["prediction"]))
print("\nReference answer:")
print(clip_text(before["reference"]))Vous devez voir, pour chaque échantillon, la réponse de base, la réponse après ajustement fin et la réponse de référence. Cela facilite l’observation de l’évolution du style et du contenu des réponses induite par l’adaptateur.

Ces exemples montrent que l’ajustement fin a aidé le modèle à se rapprocher davantage du style du jeu de données cible, en particulier sur des questions médicales courtes et factuelles.
En même temps, les résultats montrent aussi qu’il ne s’agissait que d’une petite exécution d’ajustement fin sur un sous-ensemble limité du jeu de données, donc l’amélioration n’est pas garantie pour chaque échantillon. Certaines réponses deviennent plus alignées sur la distribution d’entraînement, tandis que d’autres peuvent perdre des détails utiles ou devenir trop étroites.
Pour obtenir de meilleurs résultats, l’étape suivante consisterait à entraîner sur l’ensemble complet du jeu de données au lieu d’un petit sous-ensemble et à exécuter le processus pendant au moins 3 époques. Vous pourriez également augmenter le rang LoRA pour offrir plus de capacité d’apprentissage à l’adaptateur, et affiner davantage l’invite système afin que le modèle suive plus régulièrement le style de réponse médicale souhaité.
Ces changements devraient produire des améliorations plus stables sur un éventail plus large de questions.
Ajuster finement un modèle de langage moderne n’est pas aussi simple qu’il y paraît au premier abord.
Même si Qwen3.6-35B-A3B est un modèle Mixture-of-Experts efficient avec 35 milliards de paramètres au total, il faut tout de même des ressources de calcul sérieuses rien que pour le charger en mode 4 bits et le préparer à l’entraînement. L’entraînement en lui-même reste coûteux, surtout dès que l’on dépasse un petit sous-ensemble expérimental pour travailler avec un jeu de données plus vaste ou plusieurs époques.
Le matériel compte aussi beaucoup. Dans ce tutoriel, nous avons utilisé un H100 NVL pour garder le workflow réaliste. Sur un GPU plus ancien, le temps d’entraînement peut augmenter considérablement. Même sur un A100, une configuration similaire peut facilement prendre environ une heure, et des GPU plus modestes allongeraient encore ce délai.
Ainsi, si QLoRA et le chargement en 4 bits rendent l’ajustement fin plus accessible, ils n’en font pas pour autant une tâche légère au quotidien. Il est aussi pertinent de se demander si l’ajustement fin est nécessaire. Pour de nombreuses tâches de base, je ne recommande pas de s’y lancer d’emblée.
En travaillant l’ingénierie d’invite, en structurant mieux le workflow et en utilisant des outils, des MCP ou des approches par récupération de contexte, vous pouvez souvent vous rapprocher du comportement cible sans aucun entraînement. Dans bien des cas, cela vous amènera à environ 80 % du résultat souhaité, tout en étant plus rapide, moins coûteux et plus simple à itérer.
L’ajustement fin devient beaucoup plus précieux lorsque vous devez amener le modèle à adopter de manière constante un style de réponse très spécifique, un comportement métier ou un format institutionnel. C’est là que cela prend tout son sens. Si vous souhaitez que le modèle réponde exactement comme le ferait un hôpital, un système de santé ou un flux de travail spécialisé donné, l’ajustement fin est la meilleure voie.
En d’autres termes, privilégiez d’abord l’ingénierie d’invite et la conception du workflow, puis tournez-vous vers l’ajustement fin lorsque vous avez vraiment besoin que le modèle internalise une manière spécialisée de répondre.
Les meilleures formations en IA
Cursus
Cursus
Cours
blog
Kurtis Pykes
9 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
Tutoriel
Tutoriel
Samuel Shaibu

