
Program
Geliştiriciler için Yardımcı Yapay Zeka Mühendisi
26 sa
Qwen3.6-35B-A3B, güçlü kodlama, akıl yürütme ve uzun bağlam görevleri için oluşturulmuş hafif bir uzman karışımı (mixture-of-experts) modelidir. Toplam 35B parametre kullanır ve token başına 3B aktif parametreyle çalışır; bu da çalıştırmayı daha verimli kılarken güçlü performans sunmasını sağlar. Ayrıca 262K tokenlık bir bağlam penceresini destekler; bu da daha büyük kod tabanları, uzun belgeler ve çok adımlı iş akışları için işe yarar.
Model özellikle SWE-bench, Terminal-Bench ve Claw-Eval gibi kodlama ve ajan tarzı kıyaslamalarda başarılıdır. GPQA, AIME 2026, MMLU-Pro ve C-Eval gibi daha geniş kapsamlı akıl yürütme ve bilgi kıyaslamalarında da rekabetçi kalır; bu da onu hem pratik görev performansı hem de genel akıl yürütme yeteneği gerektiren ince ayar deneyleri için güçlü bir temel model yapar.
Bu kılavuzda bir RunPod H100 NVL ortamı kuracak, projeyi hazırlayacak, tıbbi bir S&C veri kümesini yükleyip temizleyecek, Qwen3.6’yı 4 bit nicelemeyle çalıştıracak, istemleri biçimlendirecek, değerlendirme yardımcıları oluşturacak, ince ayardan önce temel modeli test edecek, adaptörü eğitip kaydedecek ve ardından ince ayardan sonra modeli yeniden karşılaştıracağız.
Sorumluluk Reddi: Bu eğitim yalnızca eğitim amaçlı teknik bir ince ayar sürecini göstermektedir. Ortaya çıkan model tıbbi veya klinik kullanım için tasarlanmamıştır ve tanı, karar verme veya hasta bakımı için güvenilmemelidir.
İlk bölümde bir RunPod H100 NVL örneği başlatacak, gerekli kütüphaneleri kuracak, Hugging Face’e bağlanacak ve temel proje yapılandırmasını tanımlayacağız.
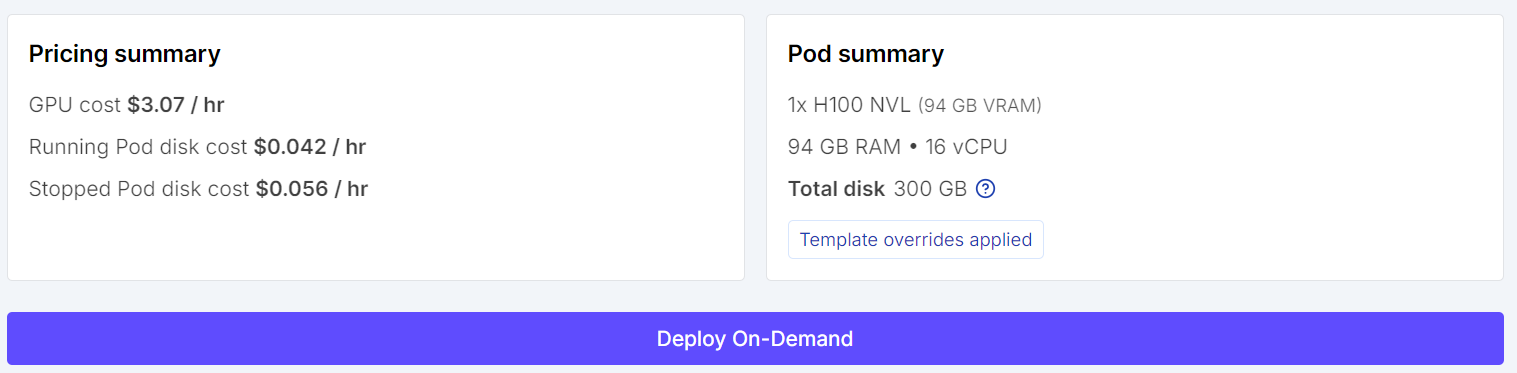
RunPod’a giderek bir H100 NVL GPU makinesi seçerek başlayın. Bu GPU yaklaşık 94 GB VRAM ve 94 GB sistem RAM ile gelir; bu da bu Qwen3.6 ince ayar iş akışı için yeterlidir.
En güncel PyTorch şablonunu seçin, ardından dağıtımdan önce pod yapılandırmasını düzenleyin. Kap (container) disk boyutunu 100 GB, birim (volume) disk boyutunu 200 GB olarak ayarlayın. Bu, modeli indirmeniz, bağımlılıkları önbelleğe almanız ve ince ayarlı adaptörü yerel olarak kaydetmeniz için yeterli alan sağlar.
Ayrıca bu aşamada bir HF_TOKEN ortam değişkeni eklemelisiniz. Bu, daha sonra Hugging Face’e giriş yapmanızı, model indirme erişimini iyileştirmenizi ve eğitimden sonra ince ayarlı modeli Hub’a göndermeyi kolaylaştırır.
Örneği başlatmadan önce, tahmini maliyeti kontrol edebilmek için pod özetini gözden geçirin. Her şey doğru görünüyorsa pod’u dağıtın.
Pod hazır olduğunda, JupyterLab’i başlatmak için RunPod panosundan Jupyter Notebook bağlantısını açın. Yeni bir Python defteri oluşturun ve nicelemeli ince ayar, veri kümesi yükleme ve TRL ile denetimli ince ayar için gereken kütüphaneleri kurun.
pip install -q -U transformers accelerate peft trl bitsandbytes datasets sentencepieceSonraki adımda, pod’u oluştururken eklediğiniz HF_TOKEN ortam değişkenini kullanarak Hugging Face’e giriş yapın. Bu, belirtecinizi deftere sert kodlamaktan kaçınır ve iş akışını daha temiz tutar.
import os
from huggingface_hub import login
hf_token = os.getenv("HF_TOKEN")
login(token=hf_token)Şimdi gerekli kütüphaneleri içe aktarın ve eğitim boyunca kullanacağımız yapılandırma değerlerini tanımlayın. Buna model kimliği, veri kümesi adı, örnek boyutları, çıktı dizini ve rastgelelik tohumu dahildir.
import os
import random
import re
import torch
from datasets import load_dataset
from peft import LoraConfig, prepare_model_for_kbit_training
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
set_seed,
)
from trl import SFTConfig, SFTTrainer
MODEL_ID = "Qwen/Qwen3.6-35B-A3B"
DATASET_ID = "keivalya/MedQuad-MedicalQnADataset"
SAMPLE_SIZE = 240
EVAL_SIZE = 24
COMPARISON_SAMPLE_COUNT = 3
MAX_SEQ_LENGTH = 768
OUTPUT_DIR = "qwen36-medquad-quick"
SEED = 42
set_seed(SEED)
random.seed(SEED)
def supports_bf16() -> bool:
return torch.cuda.is_available() and torch.cuda.get_device_capability(0)[0] >= 8
print(f"PyTorch: {torch.__version__}")
print(f"CUDA available: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"GPU: {torch.cuda.get_device_name(0)}")
print(
f"GPU memory (GB): {torch.cuda.get_device_properties(0).total_memory / 1024**3:.1f}"
)Bu hücreyi çalıştırdığınızda, CUDA’nın kullanılabilir olduğunu ve defterin bir NVIDIA H100 NVL GPU’ya bağlı olduğunu doğrulayan çıktıyı görmelisiniz.
PyTorch: 2.8.0+cu128
CUDA available: True
GPU: NVIDIA H100 NVL
GPU memory (GB): 93.1Bu bölümde MedQuad tıbbi S&C veri kümesini yükleyecek, metin alanlarını temizleyecek, daha düşük kaliteli örnekleri filtreleyecek ve hızlı ince ayar için küçük eğitim ve değerlendirme bölümleri oluşturacağız.
Hugging Face’ten MedQuad veri kümesinin eğitim bölümünü yükleyerek başlıyoruz. Yükledikten sonra, hangi tür tıbbi soru-cevap çiftleriyle çalıştığımızı anlamak için veri kümesinin yapısını, sütun adlarını ve ilk örneği inceliyoruz.
raw_dataset = load_dataset(DATASET_ID, split="train")
print(raw_dataset)
print("First example:", raw_dataset[0])Bu, MedQuad veri kümesinin qtype, Question ve Answer olmak üzere üç alanda 16.407 tıbbi soru-cevap örneği içerdiğini gösterir.
Dataset({
features: ['qtype', 'Question', 'Answer'],
num_rows: 16407
})
First example: {'qtype': 'susceptibility', 'Question': 'Who is at risk for Lymphocytic Choriomeningitis (LCM)? ?', 'Answer': 'LCMV infections can occur after exposure to fresh urine, droppings, saliva, or nesting materials from infected rodents. Transmission may also occur when these materials are directly introduced into broken skin, the nose, the eyes, or the mouth, or presumably, via the bite of an infected rodent. Person-to-person transmission has not been reported, with the exception of vertical transmission from infected mother to fetus, and rarely, through organ transplantation.'}Sonraki adımda küçük bir metin temizleme işlevi ve düşük kaliteli örnekleri kaldırmak için bir filtreleme kuralı tanımlıyoruz. Temizleme adımı fazla boşlukları normalleştirir; filtreleme adımı ise çok kısa sorulara, çok kısa yanıtlara, aşırı uzun yanıtlara veya eğitim için daha az yararlı olan genel yanıt şablonlarına sahip örnekleri kaldırır.
def clean_text(text):
text = re.sub(r"\s+", " ", str(text)).strip()
return text
BAD_ANSWER_PREFIXES = (
"These resources address",
"These resources from MedlinePlus",
"For more information, go to",
"For more information go to",
)
def keep_example(example):
question = clean_text(example["Question"])
answer = clean_text(example["Answer"])
if len(question) < 12 or len(answer) < 40:
return False
if len(answer) > 900:
return False
if any(answer.startswith(prefix) for prefix in BAD_ANSWER_PREFIXES):
return False
return True
filtered_dataset = raw_dataset.filter(keep_example)Filtrelemeden sonra veri kümesini karıştırıyor, bu hızlı eğitim için daha küçük bir alt küme seçiyor ve bunu eğitim ve değerlendirme setlerine ayırıyoruz. Bu, çalışmayı hafif tutarken ince ayardan önce ve sonra modeli karşılaştırmamıza olanak tanır.
subset = filtered_dataset.shuffle(seed=SEED).select(range(SAMPLE_SIZE))
split_dataset = subset.train_test_split(test_size=EVAL_SIZE, seed=SEED)
train_dataset = split_dataset["train"]
eval_dataset = split_dataset["test"]
print(f"Filtered dataset size: {len(filtered_dataset)}")
print(f"Train size: {len(train_dataset)}")
print(f"Eval size: {len(eval_dataset)}")Filtrelemeden sonra 7.355 daha yüksek kaliteli örnek kalır; bu hızlı ince ayar çalışması için bunlardan 216 eğitim ve 24 değerlendirme örneği örnekliyoruz.
Filtered dataset size: 7355
Train size: 216
Eval size: 24Bu adımda BitsAndBytes ile 4 bit nicelemeyi yapılandıracak, Qwen3.6’nın belirteçleyicisini (tokenizer) yükleyecek ve ardından temel modeli H100 NVL GPU’da daha verimli çalışacak şekilde yükleyeceğiz.
Qwen3.6 hâlâ büyük bir modeldir; bu nedenle tam duyarlıkta yüklemek çok daha fazla bellek kullanır. İnce ayarı daha verimli kılmak için modeli BitsAndBytes ile 4 bit duyarlıkta yüklüyoruz. Bu, belleği azaltırken modeli QLoRA tabanlı ince ayar için pratik tutar.
Burada nf4 niceleme kullanıyor, çift nicelemeyi etkinleştiriyor ve GPU desteklediğinde hesaplama türünü bfloat16 olarak ayarlıyoruz.
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16 if supports_bf16() else torch.float16,
)Sonraki adımda, Qwen3.6 için belirteçleyiciyi yüklüyoruz. Ayrıca bir dolgu (padding) belirteci tanımlı mı diye kontrol ediyoruz. Eksikse, toplu işlemelerin eğitim ve üretim sırasında düzgün çalışması için dizisonu belirtecini dolgu belirteci olarak yeniden kullanıyoruz.
tokenizer = AutoTokenizer.from_pretrained(
MODEL_ID,
trust_remote_code=True,
use_fast=False,
)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_tokenŞimdi, daha önce tanımladığımız 4 bit niceleme ayarlarıyla temel Qwen3.6 modelini yüklüyoruz. Modelin mevcut GPU’ya otomatik olarak yerleştirilmesi için device_map="auto" kullanıyor ve yine desteklendiğinde daha verimli hesaplama için bfloat16 kullanıyoruz.
Modeli yükledikten sonra dolgu belirteci kimliğini ayarlıyor ve önbellek kullanımını devre dışı bırakıyoruz. Bu önemlidir; çünkü önbellekleme çıkarımda yardımcı olsa da, ince ayar sırasında eğitime müdahale edebilir ve bellek kullanımını artırabilir.
model = AutoModelForCausalLM.from_pretrained(
MODEL_ID,
quantization_config=bnb_config,
device_map="auto",
dtype=torch.bfloat16 if supports_bf16() else torch.float16,
trust_remote_code=True,
)
model.config.pad_token_id = tokenizer.pad_token_id
model.config.use_cache = FalseBu adımda Qwen3.6 için istem yapısını tanımlayacak, model çıktısını temizleyecek, eğitim ve çıkarım için yardımcı işlevler oluşturacak ve ince ayardan önce ve sonra modeli karşılaştırmak için birkaç önizleme örneği hazırlayacağız.
Modelin nasıl yanıt vereceğini söyleyen kısa bir sistem istemi tanımlayarak başlıyoruz. Bu bir tıbbi S&C görevi olduğundan, yanıtların doğrudan, olgusal ve öz olmasını istiyoruz.
SYSTEM_PROMPT = "Answer the medical question directly in 2-4 factual sentences."Qwen3.6 sohbet tarzı bir giriş biçimi kullanır; bu nedenle iletilerimizi doğru istem yapısına dönüştüren bir yardımcı işlev gerekir. Bu işlev belirteçleyicinin sohbet şablonunu uygular ve model nihai yanıta odaklı kalsın diye akıl yürütme çıktısını devre dışı bırakır.
def apply_chat_template(messages, add_generation_prompt=False):
kwargs = {
"tokenize": False,
"add_generation_prompt": add_generation_prompt,
}
try:
return tokenizer.apply_chat_template(
messages,
enable_thinking=False,
**kwargs,
)
except TypeError:
return tokenizer.apply_chat_template(
messages,
chat_template_kwargs={"enable_thinking": False},
**kwargs,
)Sonraki adımda, üretilen metni normalleştirmek için küçük bir temizleme işlevi tanımlıyoruz. Bu, fazla boşlukları kaldırır ve çıktı başında yer alırsa answer: önekini temizler.
def clean_answer_text(answer):
answer = clean_text(answer)
answer = re.sub(r"^answer\s*:\s*", "", answer, flags=re.IGNORECASE)
return answerAyrıca kullanıcı istemi için bir yardımcı işlev oluşturuyoruz. Bu, soru biçimini eğitim ve değerlendirme boyunca tutarlı kılar ve modelden soruyu tekrar etmeden yalnızca yanıtı döndürmesini ister.
def make_user_prompt(question):
return (
f"Question: {clean_text(question)}\n\n"
"Respond with only the answer. Do not restate the question."
)Artık her veri kümesi örneğini bir sistem iletisi, bir kullanıcı sorusu ve beklenen asistan yanıtından oluşan tam sohbet tarzı bir konuşmaya dönüştürebiliriz. Denetimli ince ayar için bu yapıyı kullanacağız.
def format_training_example(example):
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": make_user_prompt(example["Question"]),
},
{
"role": "assistant",
"content": clean_answer_text(example["Answer"]),
},
]
return {"text": apply_chat_template(messages, add_generation_prompt=False)}Eğitime başlamadan önce, temel modelden yanıt üretebilen bir yardımcı işlev gerekir. Bunu, modelin ince ayardan önceki ve sonraki yanıtlarını karşılaştırmak için kullanacağız.
Aşağıdaki işlev istemi oluşturur, belirteçler, üretimi çalıştırır ve ardından çıktıda yer alan <think> izlerini ve fazla biçimlendirmeyi kaldırır.
@torch.inference_mode()
def generate_answer(question, max_new_tokens=160):
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": make_user_prompt(question),
},
]
prompt = apply_chat_template(messages, add_generation_prompt=True)
model_inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
generated = model.generate(
**model_inputs,
max_new_tokens=max_new_tokens,
do_sample=False,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
new_tokens = generated[0][model_inputs["input_ids"].shape[1] :]
text = tokenizer.decode(new_tokens, skip_special_tokens=True).strip()
return clean_answer_text(re.sub(r"<think>.*?</think>", " ", text, flags=re.DOTALL))Ayrıca, önizleme örneklerini yazdırırken uzun çıktıları kısaltmak için küçük bir yardımcı işlev ekliyoruz.
def clip_text(text, max_chars=600):
text = re.sub(r"<think>.*?</think>", " ", text, flags=re.DOTALL)
text = re.sub(r"\s+", " ", text).strip()
return text if len(text) <= max_chars else text[:max_chars] + "..."Son olarak, yan yana birkaç önizleme satırı oluşturan bir yardımcı işlev kuruyoruz. Her satırda soru, model tahmini ve başvuru yanıtı yer alır. Bu, ince ayardan önce ve sonra performansı basit şekilde incelememizi sağlar.
def generate_preview_rows(dataset, sample_count=COMPARISON_SAMPLE_COUNT):
sample_count = min(sample_count, len(dataset))
subset = dataset.select(range(sample_count))
previews = []
for row in subset:
previews.append(
{
"question": row["Question"],
"prediction": generate_answer(row["Question"]),
"reference": clean_answer_text(row["Answer"]),
}
)
return previews
formatted_train_dataset = train_dataset.map(
format_training_example,
remove_columns=train_dataset.column_names,
)
comparison_examples = eval_dataset.shuffle(seed=SEED).select(
range(COMPARISON_SAMPLE_COUNT)
)
print(formatted_train_dataset[0])İlk biçimlendirilmiş eğitim örneğini yazdırdığınızda, sistem istemi, kullanıcı sorusu ve asistan yanıtının Qwen’in şablon biçimine zaten sarıldığı sohbet tarzı bir örnek görmelisiniz.
{'text': '<|im_start|>system\nAnswer the medical question directly in 2-4 factual sentences.<|im_end|>\n<|im_start|>user\nQuestion: What is (are) COPD ?\n\nRespond with only the answer. Do not restate the question.<|im_end|>\n<|im_start|>assistant\n<think>\n\n</think>\n\nMore information on COPD is available at: What is COPD? and at the Learn More, Breathe Better Campaign For information on quitting smoking, visit http://www.surgeongeneral.gov/tobacco/ or Smokefree.gov. For information on the H1N1 flu and COPD, go to The Centers for Disease Control and Prevention.<|im_end|>\n'}Eğitimden önce temel Qwen3.6 modelini birkaç değerlendirme örneği üzerinde test edeceğiz. Bu, daha sonra modelin ince ayardan sonra nasıl değiştiğini karşılaştırabilmemiz için bir başlangıç değeri verir.
Değerlendirme setinden örneklenen birkaç örnek için önizleme yanıtları üreterek başlıyoruz.
Her önizleme; soru, ince ayardan önce modelin yanıtı ve veri kümesindeki başvuru yanıtını içerir.
baseline_previews = generate_preview_rows(comparison_examples)
for idx, sample in enumerate(baseline_previews, start=1):
print(f"\n--- Preview {idx} ---")
print("Question:", sample["question"])
print("Model answer (before fine-tuning):", clip_text(sample["prediction"]))
print("Reference answer:", clip_text(sample["reference"]))Aşağıda modelin mevcut yanıtı ile başvuru yanıtının yan yana karşılaştırmaları yer alır. Bu örnekler, görev özelindeki herhangi bir eğitimden önce modelin başlangıç noktasını anlamamıza yardımcı olur.

Bu örneklerden, temel modelin zaten tıbbi açıdan ilgili ve genel olarak doğru yanıtlar üretebildiğini görebiliyoruz.
Ancak, yanıtları her zaman veri kümesindeki başvuru yanıtlarının tarzı, ayrıntı düzeyi veya ifadesiyle eşleşmiyor. Bazı durumlarda model daha geniş veya daha genel bir açıklama verirken, başvuru yanıtı daha spesifik ve hedef biçime daha iyi hizalanmıştır.
Bu bölümde LoRA adaptör ayarlarını tanımlayacak, denetimli ince ayar argümanlarını yapılandıracak ve QLoRA eğitim sürecini yönetecek eğitmeni (trainer) başlatacağız.
Tüm model parametrelerini güncellemek yerine, QLoRA çok daha küçük bir eğitilebilir adaptör ağırlıkları kümesini ince ayar yapar. Bu, eğitimi çok daha bellek verimli kılar ve modelin yeni göreve uyum sağlamasına olanak tanır.
Burada rütbe (rank) 8, ölçekleme faktörü 16 ve küçük bir bırakma (dropout) değeriyle bir LoRA yapılandırması tanımlıyoruz. Ayrıca tüm doğrusal katmanları hedefliyoruz; böylece adaptörler model genelinde geniş şekilde uygulanır.
lora_config = LoraConfig(
r=8,
lora_alpha=16,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules="all-linear",
)Sonraki adımda SFTConfig kullanarak eğitim yapılandırmasını tanımlıyoruz. Bu ayarlar denetimli ince ayar çalışmasının davranışını; toplu iş boyutu, gradyan biriktirme, öğrenme oranı, günlükleme sıklığı ve duyarlık modu dahil olmak üzere kontrol eder.
Bu eğitim, gösterim amaçlı pratik kalması için bir eğitim dönemine ve küçük bir toplu iş boyutuna sahip hafif bir kurulum kullanır. Ayrıca eğitim sırasında bellek kullanımını azaltmak için gradyan denetim noktalamasını ve sayfalı 8 bit AdamW’yi etkinleştiriyoruz.
trainer_config = SFTConfig(
output_dir=OUTPUT_DIR,
dataset_text_field="text",
max_length=MAX_SEQ_LENGTH,
per_device_train_batch_size=2,
gradient_accumulation_steps=2,
num_train_epochs=1,
learning_rate=1e-4,
warmup_steps=5,
logging_steps=5,
save_strategy="epoch",
report_to="none",
packing=False,
gradient_checkpointing=True,
optim="paged_adamw_8bit",
bf16=supports_bf16(),
fp16=not supports_bf16(),
)Adaptör ayarları ve eğitim argümanları hazır olduğunda, SFTTrainer’ı başlatabiliriz. Bu eğitmen; temel modeli, biçimlendirilmiş eğitim veri kümesini, LoRA yapılandırmasını ve belirteçleyiciyi bir araya getirerek modeli denetimli ince ayara hazırlar.
trainer = SFTTrainer(
model=model,
train_dataset=formatted_train_dataset,
peft_config=lora_config,
args=trainer_config,
processing_class=tokenizer,
)Eğitime başlamadan önce, gerçekte kaç parametrenin güncelleneceğini doğrulamak faydalıdır. QLoRA’nın başlıca avantajlarından biri, modelin yalnızca çok küçük bir kısmının eğitilebilir hale gelmesidir.
trainer.model.print_trainable_parameters()Bu, tam model parametrelerinin yalnızca yaklaşık %0,03’ünün eğitildiğini gösterir. Bu da QLoRA’yı sınırlı donanımda büyük dil modellerine ince ayar yapmak için bu kadar pratik kılar.
trainable params: 11,238,720 || all params: 34,671,849,408 || trainable%: 0.0324Bu bölümde denetimli ince ayar çalışmasını başlatacak, eğitilmiş adaptörü yerel olarak kaydedecek ve ardından daha sonra yeniden kullanılabilmesi için Hugging Face’e göndereceğiz.
Model, veri kümesi ve eğitmen hazır olduğuna göre ince ayar sürecini başlatabiliriz. Eğitmen, biçimlendirilmiş eğitim setinde ilerleyecek ve tam model yerine yalnızca LoRA adaptör ağırlıklarını güncelleyecektir.
train_result = trainer.train()
train_resultEğitim devam ederken, kaybın kademeli olarak azaldığını görmelisiniz. Bu, modelin görev biçimini öğrendiğinin ve tıbbi soru-cevap verilerine uyum sağladığının iyi bir göstergesidir.
Eğitim tamamlandıktan sonra, ince ayarlı adaptörü ve belirteçleyiciyi yerel olarak kaydedin. Bu, tam eğitim çalışmasını tekrarlamadan daha sonra yeniden yükleyebileceğiniz yeniden kullanılabilir bir denetim noktası sağlar.
trainer.model.save_pretrained(OUTPUT_DIR)
tokenizer.save_pretrained(OUTPUT_DIR)Adaptör yerel olarak kaydedildikten sonra, onu Hugging Face’e yükleyebilirsiniz. Bu, ince ayarlı modeli gelecekteki defterlerde veya dağıtım iş akışlarında paylaşmayı, sürümlendirmeyi ve yeniden yüklemeyi kolaylaştırır.
HF_REPO_ID = "kingabzpro/qwen36-medquad-quick"
trainer.model.push_to_hub(HF_REPO_ID)
tokenizer.push_to_hub(HF_REPO_ID) Yükleme tamamlandıktan sonra ince ayarlı adaptör depodan erişilebilir olacaktır.
Yükleme tamamlandıktan sonra ince ayarlı adaptör depodan erişilebilir olacaktır.
Kaynak: kingabzpro/qwen36-medquad-quick
Artık eğitim tamamlandığına göre, daha önce kullandığımız aynı karşılaştırma örneklerinde ince ayarlı modeli değerlendirebiliriz. Bu, tamamen aynı sorular üzerinde doğrudan bir önce-sonra karşılaştırması yapmamıza yardımcı olur.
model.eval()
fine_tuned_previews = generate_preview_rows(comparison_examples)
for idx, (before, after) in enumerate(
zip(baseline_previews, fine_tuned_previews), start=1
):
print(f"\n{'=' * 80}")
print(f"Sample {idx}")
print(f"{'=' * 80}")
print("Question:", before["question"])
print("\nBefore fine-tuning:")
print(clip_text(before["prediction"]))
print("\nAfter fine-tuning:")
print(clip_text(after["prediction"]))
print("\nReference answer:")
print(clip_text(before["reference"]))Her örnek için temel yanıtı, ince ayarlı yanıtı ve başvuru yanıtını görmelisiniz. Bu, adaptörün modelin yanıt tarzını ve içeriğini nasıl değiştirdiğini incelemeyi kolaylaştırır.

Bu örnekler, ince ayarın özellikle daha kısa olgusal tıbbi sorularda modelin hedef veri kümesi tarzına daha yakından uyum sağlamasına yardımcı olduğunu gösteriyor.
Aynı zamanda, bunun yalnızca veri kümesinin sınırlı bir alt kümesi üzerinde yapılan küçük bir ince ayar çalışması olduğunu da gösterir; bu nedenle her örnekte iyileşme garanti değildir. Bazı yanıtlar eğitim dağılımına daha fazla hizalanırken, diğerleri yararlı ayrıntıları kaybedebilir veya fazla daralabilir.
Daha iyi sonuçlar için bir sonraki adım, küçük bir alt küme yerine tam veri kümesi üzerinde eğitmek ve ince ayar sürecini en az 3 dönem çalıştırmak olacaktır. Ayrıca adaptöre daha fazla öğrenme kapasitesi vermek için LoRA rütbesini artırabilir ve modelin istenen tıbbi yanıt tarzını daha tutarlı şekilde takip etmesi için sistem istemini daha da iyileştirebilirsiniz.
Bu değişiklikler, daha geniş bir soru yelpazesinde daha istikrarlı iyileşmeler sağlayacaktır.
Modern bir dil modeline ince ayar yapmak, ilk bakışta göründüğü kadar basit değildir.
Qwen3.6-35B-A3B, toplam 35 milyar parametreli verimli bir uzman karışımı modeli olsa da, yine de yalnızca 4 bit modda yüklemek ve eğitime hazırlamak için ciddi hesaplama gücü gerektirir. Eğitimin kendisi de özellikle küçük bir deneysel alt kümenin ötesine geçip daha büyük bir veri kümesi veya birden fazla dönemle çalışmaya başladığınızda maliyetli kalır.
Donanım da çok önemlidir. Bu eğitimde iş akışını pratik tutmak için bir H100 NVL kullandık. Daha eski bir GPU’da eğitim süresi dramatik biçimde artabilir. Hatta bir A100 üzerinde bile benzer bir kurulum kolaylıkla yaklaşık bir saat sürebilir; daha zayıf GPU’larda bu süre daha da uzayacaktır.
Dolayısıyla QLoRA ve 4 bit yükleme ince ayarı daha erişilebilir kılsa da, günlük anlamda hafif hale getirmez. Ayrıca baştan ince ayarın gerçekten gerekli olup olmadığını sormaya değerdir. Birçok temel görev için doğrudan ince ayara atlamayı önermem.
İstemi iyileştirmeye, iş akışını daha iyi yapılandırmaya ve araçlar, MCP’ler veya alma (retrieval) tabanlı yöntemler kullanmaya zaman ayırırsanız, çoğu zaman hiç eğitim yapmadan hedef davranışa yaklaşabilirsiniz. Çoğu durumda bu, istediğiniz sonucun yaklaşık %80’ine çok daha hızlı, daha ucuz ve yinelemeye daha elverişli biçimde ulaşmanızı sağlayabilir.
İnce ayar, modelin çok belirli bir yanıt tarzını, alan davranışını veya kurumsal biçimi tutarlı şekilde öğrenmesini istediğinizde çok daha değerli hale gelir. İşte o zaman mantıklı olmaya başlar. Modelin belirli bir hastane, sağlık sistemi veya uzman iş akışının sorulara yanıt verme biçimine tam olarak uymasını istiyorsanız, ince ayar daha iyi bir yoldur.
Başka bir deyişle, önce istem vermeyi ve iş akışı tasarımını kullanın; modelin özel bir yanıt verme biçimini gerçekten içselleştirmesini gerektiğinde ince ayara dönün.
En İyi Yapay Zekâ Kursları
Program
Program
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
