
Tracks
Kỹ sư Trợ lý Trí tuệ Nhân tạo (AI) cho Lập trình viên
26 giờ
Qwen3.6-35B-A3B là một mô hình mixture-of-experts gọn nhẹ được xây dựng cho các tác vụ lập trình, lập luận và ngữ cảnh dài. Mô hình có tổng 35B tham số với 3B tham số hoạt động mỗi token, giúp vận hành hiệu quả hơn nhưng vẫn giữ hiệu suất mạnh. Nó cũng hỗ trợ cửa sổ ngữ cảnh 262K token, hữu ích cho codebase lớn, tài liệu dài và quy trình nhiều bước.
Mô hình đặc biệt mạnh trên các benchmark lập trình và tác tử, với kết quả tốt trên SWE-bench, Terminal-Bench và Claw-Eval. Nó cũng cạnh tranh trên các benchmark lập luận và kiến thức rộng như GPQA, AIME 2026, MMLU-Pro và C-Eval, khiến nó trở thành mô hình nền tảng vững chắc cho các thí nghiệm fine-tuning đòi hỏi cả hiệu suất thực tiễn lẫn khả năng suy luận tổng quát.
Trong hướng dẫn này, chúng ta sẽ thiết lập môi trường RunPod H100 NVL, chuẩn bị dự án, nạp và làm sạch bộ dữ liệu Hỏi & Đáp y khoa, chạy Qwen3.6 ở chế độ lượng hóa 4-bit, định dạng prompt, xây dựng tiện ích đánh giá, kiểm thử mô hình gốc trước khi fine-tune, huấn luyện và lưu adapter, rồi so sánh mô hình sau khi fine-tune.
Tuyên bố miễn trừ trách nhiệm: Tutorial này chỉ minh họa quy trình kỹ thuật fine-tuning cho mục đích giáo dục. Mô hình tạo ra không dành cho mục đích y tế hay lâm sàng và không nên được sử dụng để chẩn đoán, ra quyết định hoặc chăm sóc bệnh nhân.
Ở phần đầu, chúng ta sẽ khởi chạy một instance RunPod H100 NVL, cài đặt các thư viện cần thiết, đăng nhập Hugging Face và định nghĩa cấu hình cốt lõi của dự án.
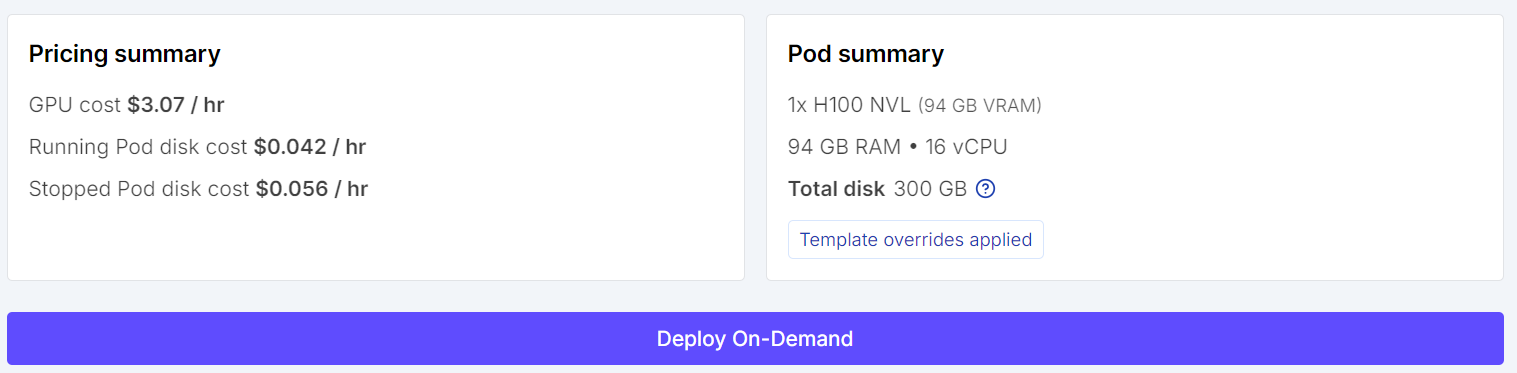
Bắt đầu bằng cách vào RunPod và chọn máy GPU H100 NVL. GPU này có khoảng 94 GB VRAM và 94 GB RAM hệ thống, đủ cho quy trình fine-tuning Qwen3.6 này.
Chọn template PyTorch mới nhất, rồi chỉnh sửa cấu hình pod trước khi triển khai. Đặt dung lượng đĩa container là 100 GB và dung lượng volume là 200 GB. Như vậy đủ chỗ để tải mô hình, cache phụ thuộc và lưu adapter đã fine-tune cục bộ.
Bạn cũng nên thêm biến môi trường HF_TOKEN ở bước này. Điều này cho phép bạn đăng nhập Hugging Face sau đó, cải thiện quyền tải mô hình và giúp đẩy mô hình đã fine-tune lên Hub dễ dàng sau khi huấn luyện.
Trước khi khởi chạy instance, hãy xem lại tóm tắt pod để kiểm tra chi phí ước tính. Khi mọi thứ ổn, hãy triển khai pod.
Sau khi pod sẵn sàng, mở liên kết Jupyter Notebook từ bảng điều khiển RunPod để khởi chạy JupyterLab. Tạo một notebook Python mới, rồi cài đặt các thư viện cần cho fine-tuning với lượng hóa, nạp dữ liệu và supervised fine-tuning bằng TRL.
pip install -q -U transformers accelerate peft trl bitsandbytes datasets sentencepieceTiếp theo, đăng nhập Hugging Face bằng biến môi trường HF_TOKEN bạn đã thêm khi tạo pod. Cách này tránh phải hardcode token trong notebook và giúp quy trình gọn gàng hơn.
import os
from huggingface_hub import login
hf_token = os.getenv("HF_TOKEN")
login(token=hf_token)Giờ hãy import các thư viện cần thiết và định nghĩa các giá trị cấu hình sẽ dùng xuyên suốt tutorial. Bao gồm ID mô hình, tên bộ dữ liệu, kích thước mẫu, thư mục đầu ra và seed ngẫu nhiên.
import os
import random
import re
import torch
from datasets import load_dataset
from peft import LoraConfig, prepare_model_for_kbit_training
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
set_seed,
)
from trl import SFTConfig, SFTTrainer
MODEL_ID = "Qwen/Qwen3.6-35B-A3B"
DATASET_ID = "keivalya/MedQuad-MedicalQnADataset"
SAMPLE_SIZE = 240
EVAL_SIZE = 24
COMPARISON_SAMPLE_COUNT = 3
MAX_SEQ_LENGTH = 768
OUTPUT_DIR = "qwen36-medquad-quick"
SEED = 42
set_seed(SEED)
random.seed(SEED)
def supports_bf16() -> bool:
return torch.cuda.is_available() and torch.cuda.get_device_capability(0)[0] >= 8
print(f"PyTorch: {torch.__version__}")
print(f"CUDA available: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"GPU: {torch.cuda.get_device_name(0)}")
print(
f"GPU memory (GB): {torch.cuda.get_device_properties(0).total_memory / 1024**3:.1f}"
)Khi chạy cell này, bạn sẽ thấy đầu ra xác nhận CUDA khả dụng và notebook đang kết nối với GPU NVIDIA H100 NVL.
PyTorch: 2.8.0+cu128
CUDA available: True
GPU: NVIDIA H100 NVL
GPU memory (GB): 93.1Ở phần này, chúng ta sẽ nạp bộ dữ liệu Hỏi & Đáp y khoa MedQuad, làm sạch các trường văn bản, lọc bỏ ví dụ chất lượng thấp và tạo các tập train và đánh giá nhỏ để fine-tune nhanh.
Chúng ta bắt đầu bằng cách nạp split train của bộ dữ liệu MedQuad từ Hugging Face. Sau khi nạp, ta kiểm tra cấu trúc, tên cột và ví dụ đầu tiên để hiểu loại cặp hỏi–đáp y khoa sẽ làm việc.
raw_dataset = load_dataset(DATASET_ID, split="train")
print(raw_dataset)
print("First example:", raw_dataset[0])Điều này cho thấy MedQuad có 16.407 ví dụ hỏi–đáp y khoa trên ba trường: qtype, Question và Answer.
Dataset({
features: ['qtype', 'Question', 'Answer'],
num_rows: 16407
})
First example: {'qtype': 'susceptibility', 'Question': 'Who is at risk for Lymphocytic Choriomeningitis (LCM)? ?', 'Answer': 'LCMV infections can occur after exposure to fresh urine, droppings, saliva, or nesting materials from infected rodents. Transmission may also occur when these materials are directly introduced into broken skin, the nose, the eyes, or the mouth, or presumably, via the bite of an infected rodent. Person-to-person transmission has not been reported, with the exception of vertical transmission from infected mother to fetus, and rarely, through organ transplantation.'}Tiếp theo, chúng ta định nghĩa một hàm làm sạch văn bản nhỏ và một quy tắc lọc để loại bỏ các mẫu chất lượng thấp. Bước làm sạch chuẩn hóa khoảng trắng thừa, còn bước lọc loại ví dụ có câu hỏi quá ngắn, câu trả lời quá ngắn, câu trả lời quá dài, hoặc các mẫu trả lời mang tính khuôn mẫu chung chung ít hữu ích cho huấn luyện.
def clean_text(text):
text = re.sub(r"\s+", " ", str(text)).strip()
return text
BAD_ANSWER_PREFIXES = (
"These resources address",
"These resources from MedlinePlus",
"For more information, go to",
"For more information go to",
)
def keep_example(example):
question = clean_text(example["Question"])
answer = clean_text(example["Answer"])
if len(question) < 12 or len(answer) < 40:
return False
if len(answer) > 900:
return False
if any(answer.startswith(prefix) for prefix in BAD_ANSWER_PREFIXES):
return False
return True
filtered_dataset = raw_dataset.filter(keep_example)Sau khi lọc, chúng ta xáo trộn bộ dữ liệu, chọn một tập con nhỏ cho tutorial nhanh này và chia thành tập huấn luyện và đánh giá. Cách này giữ cho lần chạy nhẹ nhàng nhưng vẫn cho phép so sánh mô hình trước và sau khi fine-tune.
subset = filtered_dataset.shuffle(seed=SEED).select(range(SAMPLE_SIZE))
split_dataset = subset.train_test_split(test_size=EVAL_SIZE, seed=SEED)
train_dataset = split_dataset["train"]
eval_dataset = split_dataset["test"]
print(f"Filtered dataset size: {len(filtered_dataset)}")
print(f"Train size: {len(train_dataset)}")
print(f"Eval size: {len(eval_dataset)}")Sau khi lọc, còn lại 7.355 ví dụ chất lượng cao hơn, từ đó chúng ta lấy mẫu 216 ví dụ huấn luyện và 24 ví dụ đánh giá cho lần fine-tune nhanh này.
Filtered dataset size: 7355
Train size: 216
Eval size: 24Ở bước này, chúng ta sẽ cấu hình lượng hóa 4-bit với BitsAndBytes, nạp tokenizer của Qwen3.6 và sau đó nạp mô hình gốc để chạy hiệu quả hơn trên GPU H100 NVL.
Qwen3.6 vẫn là mô hình lớn, nên nạp ở độ chính xác đầy đủ sẽ dùng nhiều bộ nhớ hơn. Để fine-tune hiệu quả hơn, chúng ta nạp mô hình ở độ chính xác 4-bit với BitsAndBytes. Điều này giảm sử dụng bộ nhớ trong khi vẫn đảm bảo tính thực tiễn cho fine-tuning dựa trên QLoRA.
Ở đây, chúng ta dùng nf4 lượng hóa, bật double quantization và đặt compute dtype là bfloat16 khi GPU hỗ trợ.
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16 if supports_bf16() else torch.float16,
)Tiếp theo, chúng ta nạp tokenizer cho Qwen3.6. Chúng ta cũng kiểm tra xem đã có token đệm hay chưa. Nếu thiếu, ta tái sử dụng token kết thúc chuỗi làm token đệm để batching hoạt động đúng trong huấn luyện và sinh văn bản.
tokenizer = AutoTokenizer.from_pretrained(
MODEL_ID,
trust_remote_code=True,
use_fast=False,
)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_tokenGiờ chúng ta nạp mô hình Qwen3.6 gốc với thiết lập lượng hóa 4-bit đã định nghĩa. Ta dùng device_map="auto" để mô hình tự động đặt lên GPU khả dụng, và tiếp tục dùng bfloat16 khi được hỗ trợ để tính toán hiệu quả hơn.
Sau khi nạp mô hình, chúng ta đặt padding token ID và tắt cache. Điều này quan trọng vì cache hữu ích cho suy luận, nhưng trong fine-tuning, nó có thể gây nhiễu việc huấn luyện và tăng sử dụng bộ nhớ.
model = AutoModelForCausalLM.from_pretrained(
MODEL_ID,
quantization_config=bnb_config,
device_map="auto",
dtype=torch.bfloat16 if supports_bf16() else torch.float16,
trust_remote_code=True,
)
model.config.pad_token_id = tokenizer.pad_token_id
model.config.use_cache = FalseỞ bước này, chúng ta sẽ định nghĩa cấu trúc prompt cho Qwen3.6, làm sạch đầu ra mô hình, tạo các hàm tiện ích cho huấn luyện và suy luận, và chuẩn bị một vài mẫu xem trước để so sánh mô hình trước và sau fine-tuning.
Bắt đầu bằng cách định nghĩa một system prompt ngắn hướng dẫn cách trả lời. Vì đây là tác vụ Hỏi & Đáp y khoa, chúng ta muốn câu trả lời trực tiếp, chính xác, súc tích.
SYSTEM_PROMPT = "Answer the medical question directly in 2-4 factual sentences."Qwen3.6 dùng định dạng đầu vào kiểu chat, nên ta cần một hàm chuyển đổi thông điệp sang cấu trúc prompt đúng. Hàm này áp dụng chat template của tokenizer và tắt đầu ra reasoning để mô hình tập trung vào câu trả lời cuối cùng.
def apply_chat_template(messages, add_generation_prompt=False):
kwargs = {
"tokenize": False,
"add_generation_prompt": add_generation_prompt,
}
try:
return tokenizer.apply_chat_template(
messages,
enable_thinking=False,
**kwargs,
)
except TypeError:
return tokenizer.apply_chat_template(
messages,
chat_template_kwargs={"enable_thinking": False},
**kwargs,
)Tiếp theo, chúng ta định nghĩa một hàm dọn dẹp nhỏ để chuẩn hóa văn bản sinh ra. Hàm này loại bỏ khoảng trắng thừa và bỏ bất kỳ tiền tố answer: ở đầu nếu có trong đầu ra.
def clean_answer_text(answer):
answer = clean_text(answer)
answer = re.sub(r"^answer\s*:\s*", "", answer, flags=re.IGNORECASE)
return answerChúng ta cũng tạo một hàm tiện ích cho user prompt. Điều này giữ định dạng câu hỏi nhất quán giữa huấn luyện và đánh giá, đồng thời yêu cầu mô hình chỉ trả về câu trả lời, không lặp lại câu hỏi.
def make_user_prompt(question):
return (
f"Question: {clean_text(question)}\n\n"
"Respond with only the answer. Do not restate the question."
)Giờ chúng ta có thể định dạng mỗi ví dụ dữ liệu thành một cuộc hội thoại kiểu chat với thông điệp hệ thống, câu hỏi của người dùng và câu trả lời mong đợi của trợ lý. Đây là cấu trúc sẽ dùng cho supervised fine-tuning.
def format_training_example(example):
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": make_user_prompt(example["Question"]),
},
{
"role": "assistant",
"content": clean_answer_text(example["Answer"]),
},
]
return {"text": apply_chat_template(messages, add_generation_prompt=False)}Trước khi bắt đầu huấn luyện, chúng ta cần một hàm có thể sinh câu trả lời từ mô hình gốc. Chúng ta sẽ dùng nó để so sánh phản hồi của mô hình trước và sau khi fine-tune.
Hàm dưới đây xây dựng prompt, tokenize, chạy sinh và sau đó loại bỏ mọi dấu vết <think> và định dạng thừa khỏi đầu ra.
@torch.inference_mode()
def generate_answer(question, max_new_tokens=160):
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": make_user_prompt(question),
},
]
prompt = apply_chat_template(messages, add_generation_prompt=True)
model_inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
generated = model.generate(
**model_inputs,
max_new_tokens=max_new_tokens,
do_sample=False,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
new_tokens = generated[0][model_inputs["input_ids"].shape[1] :]
text = tokenizer.decode(new_tokens, skip_special_tokens=True).strip()
return clean_answer_text(re.sub(r"<think>.*?</think>", " ", text, flags=re.DOTALL))Chúng ta cũng thêm một hàm nhỏ để rút gọn đầu ra dài khi in các ví dụ xem trước.
def clip_text(text, max_chars=600):
text = re.sub(r"<think>.*?</think>", " ", text, flags=re.DOTALL)
text = re.sub(r"\s+", " ", text).strip()
return text if len(text) <= max_chars else text[:max_chars] + "..."Cuối cùng, chúng ta xây dựng một hàm tạo một vài hàng xem trước đặt cạnh nhau. Mỗi hàng gồm câu hỏi, dự đoán của mô hình và câu trả lời tham chiếu. Cách này giúp ta dễ dàng quan sát hiệu suất trước và sau fine-tuning.
def generate_preview_rows(dataset, sample_count=COMPARISON_SAMPLE_COUNT):
sample_count = min(sample_count, len(dataset))
subset = dataset.select(range(sample_count))
previews = []
for row in subset:
previews.append(
{
"question": row["Question"],
"prediction": generate_answer(row["Question"]),
"reference": clean_answer_text(row["Answer"]),
}
)
return previews
formatted_train_dataset = train_dataset.map(
format_training_example,
remove_columns=train_dataset.column_names,
)
comparison_examples = eval_dataset.shuffle(seed=SEED).select(
range(COMPARISON_SAMPLE_COUNT)
)
print(formatted_train_dataset[0])Khi in ví dụ huấn luyện đã định dạng đầu tiên, bạn sẽ thấy một mẫu kiểu chat với system prompt, câu hỏi của người dùng và câu trả lời của trợ lý đã được bọc theo template của Qwen.
{'text': '<|im_start|>system\nAnswer the medical question directly in 2-4 factual sentences.<|im_end|>\n<|im_start|>user\nQuestion: What is (are) COPD ?\n\nRespond with only the answer. Do not restate the question.<|im_end|>\n<|im_start|>assistant\n<think>\n\n</think>\n\nMore information on COPD is available at: What is COPD? and at the Learn More, Breathe Better Campaign For information on quitting smoking, visit http://www.surgeongeneral.gov/tobacco/ or Smokefree.gov. For information on the H1N1 flu and COPD, go to The Centers for Disease Control and Prevention.<|im_end|>\n'}Chúng ta sẽ kiểm thử mô hình Qwen3.6 gốc trên một vài ví dụ đánh giá trước khi huấn luyện. Điều này cung cấp đường cơ sở để sau đó so sánh mô hình thay đổi ra sao sau khi fine-tune.
Bắt đầu bằng cách sinh câu trả lời xem trước cho một vài ví dụ được lấy mẫu từ tập đánh giá.
Mỗi bản xem trước gồm câu hỏi, câu trả lời của mô hình trước khi fine-tune và câu trả lời tham chiếu từ bộ dữ liệu.
baseline_previews = generate_preview_rows(comparison_examples)
for idx, sample in enumerate(baseline_previews, start=1):
print(f"\n--- Preview {idx} ---")
print("Question:", sample["question"])
print("Model answer (before fine-tuning):", clip_text(sample["prediction"]))
print("Reference answer:", clip_text(sample["reference"]))Dưới đây là các so sánh đặt cạnh nhau giữa phản hồi hiện tại của mô hình và câu trả lời tham chiếu. Những ví dụ này giúp hiểu điểm xuất phát của mô hình trước bất kỳ huấn luyện đặc thù nào.

Từ các ví dụ này, ta có thể thấy mô hình gốc đã có khả năng đưa ra câu trả lời liên quan y khoa và nhìn chung là đúng.
Tuy nhiên, phản hồi không phải lúc nào cũng khớp phong cách, mức độ chi tiết hoặc cách diễn đạt của câu trả lời tham chiếu trong bộ dữ liệu. Đôi khi mô hình đưa ra giải thích rộng hoặc chung chung hơn, trong khi câu trả lời tham chiếu cụ thể hơn và phù hợp định dạng mục tiêu.
Ở phần này, chúng ta sẽ định nghĩa thiết lập adapter LoRA, cấu hình các tham số supervised fine-tuning và khởi tạo trainer xử lý quá trình huấn luyện QLoRA.
Thay vì cập nhật toàn bộ tham số mô hình, QLoRA fine-tune một tập trọng số adapter có thể huấn luyện nhỏ hơn nhiều. Điều này giúp huấn luyện tiết kiệm bộ nhớ hơn đáng kể nhưng vẫn cho phép mô hình thích ứng với tác vụ mới.
Tại đây, chúng ta định nghĩa cấu hình LoRA với rank 8, hệ số scale 16 và dropout nhỏ. Chúng ta cũng nhắm đến tất cả các lớp tuyến tính để adapter được áp dụng rộng khắp mô hình.
lora_config = LoraConfig(
r=8,
lora_alpha=16,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules="all-linear",
)Tiếp theo, chúng ta định nghĩa cấu hình huấn luyện bằng SFTConfig. Các thiết lập này điều khiển cách phiên supervised fine-tuning hoạt động, gồm kích thước batch, tích lũy gradient, tốc độ học, tần suất logging và chế độ độ chính xác.
Tutorial này dùng cấu hình gọn nhẹ với một epoch huấn luyện và batch nhỏ, để việc chạy phù hợp cho mục đích minh họa. Chúng ta cũng bật gradient checkpointing và paged AdamW 8-bit để giảm sử dụng bộ nhớ khi huấn luyện.
trainer_config = SFTConfig(
output_dir=OUTPUT_DIR,
dataset_text_field="text",
max_length=MAX_SEQ_LENGTH,
per_device_train_batch_size=2,
gradient_accumulation_steps=2,
num_train_epochs=1,
learning_rate=1e-4,
warmup_steps=5,
logging_steps=5,
save_strategy="epoch",
report_to="none",
packing=False,
gradient_checkpointing=True,
optim="paged_adamw_8bit",
bf16=supports_bf16(),
fp16=not supports_bf16(),
)Với thiết lập adapter và tham số huấn luyện sẵn sàng, ta có thể khởi tạo SFTTrainer. Trainer này kết hợp mô hình gốc, bộ dữ liệu huấn luyện đã định dạng, cấu hình LoRA và tokenizer để mô hình sẵn sàng cho supervised fine-tuning.
trainer = SFTTrainer(
model=model,
train_dataset=formatted_train_dataset,
peft_config=lora_config,
args=trainer_config,
processing_class=tokenizer,
)Trước khi bắt đầu huấn luyện, nên xác nhận có bao nhiêu tham số thực sự được cập nhật. Một trong những lợi thế chính của QLoRA là chỉ một phần rất nhỏ của mô hình có thể huấn luyện.
trainer.model.print_trainable_parameters()Kết quả cho thấy chỉ khoảng 0,03% tổng tham số mô hình được huấn luyện. Đây là lý do QLoRA là cách tiếp cận thực tiễn để fine-tune các mô hình ngôn ngữ lớn trên phần cứng hạn chế.
trainable params: 11,238,720 || all params: 34,671,849,408 || trainable%: 0.0324Ở phần này, chúng ta sẽ bắt đầu phiên supervised fine-tuning, lưu adapter đã huấn luyện cục bộ và sau đó đẩy lên Hugging Face để có thể tái sử dụng.
Khi mô hình, dữ liệu và trainer đã sẵn sàng, chúng ta có thể bắt đầu quá trình fine-tuning. Trainer sẽ chạy qua tập huấn luyện đã định dạng và chỉ cập nhật trọng số adapter LoRA thay vì toàn bộ mô hình.
train_result = trainer.train()
train_resultKhi huấn luyện chạy, bạn sẽ thấy loss giảm dần. Đây là dấu hiệu tốt cho thấy mô hình đang học định dạng tác vụ và thích nghi với dữ liệu hỏi–đáp y khoa.
Sau khi huấn luyện xong, lưu adapter và tokenizer cục bộ. Điều này cung cấp một checkpoint có thể tái sử dụng để nạp lại sau mà không cần chạy lại toàn bộ huấn luyện.
trainer.model.save_pretrained(OUTPUT_DIR)
tokenizer.save_pretrained(OUTPUT_DIR)Khi adapter đã được lưu cục bộ, bạn có thể tải nó lên Hugging Face. Điều này giúp chia sẻ, quản lý phiên bản và nạp lại mô hình đã fine-tune trong các notebook hoặc quy trình triển khai về sau dễ dàng hơn.
HF_REPO_ID = "kingabzpro/qwen36-medquad-quick"
trainer.model.push_to_hub(HF_REPO_ID)
tokenizer.push_to_hub(HF_REPO_ID) Sau khi tải lên hoàn tất, adapter đã fine-tune sẽ có sẵn tại repository.
Sau khi tải lên hoàn tất, adapter đã fine-tune sẽ có sẵn tại repository.
Nguồn: kingabzpro/qwen36-medquad-quick
Giờ khi huấn luyện đã hoàn tất, chúng ta có thể đánh giá mô hình đã fine-tune trên chính các ví dụ so sánh đã dùng trước đó. Điều này giúp so sánh trực tiếp trước–sau trên đúng các câu hỏi đó.
model.eval()
fine_tuned_previews = generate_preview_rows(comparison_examples)
for idx, (before, after) in enumerate(
zip(baseline_previews, fine_tuned_previews), start=1
):
print(f"\n{'=' * 80}")
print(f"Sample {idx}")
print(f"{'=' * 80}")
print("Question:", before["question"])
print("\nBefore fine-tuning:")
print(clip_text(before["prediction"]))
print("\nAfter fine-tuning:")
print(clip_text(after["prediction"]))
print("\nReference answer:")
print(clip_text(before["reference"]))Bạn sẽ thấy câu trả lời gốc, câu trả lời sau fine-tune và câu trả lời tham chiếu cho mỗi mẫu. Điều này giúp quan sát adapter đã thay đổi phong cách và nội dung phản hồi của mô hình như thế nào.

Những ví dụ này cho thấy fine-tuning giúp mô hình thích nghi sát hơn với phong cách của bộ dữ liệu mục tiêu, đặc biệt trên các câu hỏi y khoa ngắn, mang tính thực chứng.
Đồng thời, kết quả cũng cho thấy đây chỉ là một lượt fine-tune nhỏ trên tập con hạn chế, nên không đảm bảo cải thiện ở mọi mẫu. Một số câu trả lời trở nên phù hợp hơn với phân phối huấn luyện, trong khi số khác có thể mất chi tiết hữu ích hoặc trở nên quá hẹp.
Để có kết quả tốt hơn, bước tiếp theo là huấn luyện trên toàn bộ bộ dữ liệu thay vì tập con nhỏ và chạy ít nhất 3 epoch. Bạn cũng có thể tăng rank LoRA để adapter có nhiều khả năng học hơn, và tinh chỉnh thêm system prompt để mô hình tuân thủ phong cách trả lời y khoa mong muốn ổn định hơn.
Những thay đổi này có khả năng mang lại cải thiện ổn định hơn trên nhiều loại câu hỏi.
Fine-tuning một mô hình ngôn ngữ hiện đại không đơn giản như tưởng.
Dù Qwen3.6-35B-A3B là mô hình mixture-of-experts hiệu quả với 35 tỷ tham số, chỉ riêng việc nạp ở chế độ 4-bit và chuẩn bị cho huấn luyện đã cần tài nguyên tính toán đáng kể. Bản thân quá trình huấn luyện cũng tốn kém, nhất là khi vượt quá tập con thử nghiệm nhỏ và làm việc với bộ dữ liệu lớn hoặc nhiều epoch.
Phần cứng cũng rất quan trọng. Trong tutorial này, chúng ta dùng H100 NVL để quy trình khả thi. Trên GPU cũ hơn, thời gian huấn luyện có thể tăng mạnh. Ngay cả trên A100, thiết lập tương tự cũng có thể mất khoảng một giờ, và GPU yếu hơn sẽ còn lâu hơn.
Vì vậy, dù QLoRA và nạp 4-bit giúp fine-tuning dễ tiếp cận hơn, chúng không biến nó thành nhẹ nhàng theo nghĩa thường ngày. Cũng đáng cân nhắc liệu fine-tuning có cần thiết ngay từ đầu hay không. Với nhiều tác vụ cơ bản, tôi không khuyến nghị lao vào fine-tuning ngay.
Nếu bạn dành thời gian cải thiện prompt, cấu trúc quy trình tốt hơn và dùng công cụ, MCP hoặc phương pháp truy xuất, bạn thường có thể đạt gần hành vi mục tiêu mà không cần huấn luyện. Trong nhiều trường hợp, điều đó có thể mang lại khoảng 80% kết quả mong muốn, đồng thời nhanh hơn, rẻ hơn và dễ lặp hơn nhiều.
Fine-tuning trở nên giá trị hơn khi bạn cần mô hình nhất quán học một phong cách phản hồi rất cụ thể, hành vi theo miền hay định dạng theo tổ chức. Khi đó nó mới hợp lý. Nếu bạn muốn mô hình trả lời đúng như cách một bệnh viện, hệ thống y tế hoặc quy trình chuyên khoa cụ thể phản hồi câu hỏi, thì fine-tuning là lựa chọn tốt hơn.
Nói cách khác, hãy ưu tiên prompting và thiết kế quy trình trước, và chỉ chuyển sang fine-tuning khi bạn thực sự cần mô hình nội tại hóa một cách phản hồi chuyên biệt.
Các khóa học AI hàng đầu
Tracks
Tracks
Courses
blogs
Matt Crabtree
10 phút