
Programma
Ingegnere AI associato per sviluppatori
26 h
Qwen3.6-35B-A3B è un modello mixture-of-experts leggero, progettato per eccellere in attività di coding, ragionamento e contesti lunghi. Usa 35B parametri totali con 3B parametri attivi per token, il che lo rende più efficiente da eseguire pur offrendo prestazioni solide. Supporta inoltre una finestra di contesto da 262K token, rendendolo utile per codebase grandi, documenti lunghi e workflow multi-step.
Il modello si comporta particolarmente bene nei benchmark di coding e stile agente, con risultati solidi su SWE-bench, Terminal-Bench e Claw-Eval. Rimane competitivo anche su benchmark più ampi di ragionamento e conoscenza come GPQA, AIME 2026, MMLU-Pro e C-Eval, il che lo rende un'ottima base per esperimenti di fine-tuning che richiedono sia prestazioni pratiche sui task sia capacità generali di ragionamento.
In questa guida imposteremo un ambiente RunPod H100 NVL, prepareremo il progetto, caricheremo e puliremo un dataset di Q&A mediche, eseguiremo Qwen3.6 in quantizzazione a 4 bit, formatteremo i prompt, costruiremo helper per la valutazione, testeremo il modello base prima del fine-tuning, alleneremo e salveremo l'adapter e poi confronteremo di nuovo il modello dopo il fine-tuning.
Disclaimer: questo tutorial illustra un processo tecnico di fine-tuning a solo scopo didattico. Il modello risultante non è destinato a uso medico o clinico e non deve essere utilizzato per diagnosi, decisioni o cura dei pazienti.
Nella prima sezione lanceremo un'istanza RunPod H100 NVL, installeremo le librerie necessarie, ci connetteremo a Hugging Face e definiremo la configurazione principale del progetto.
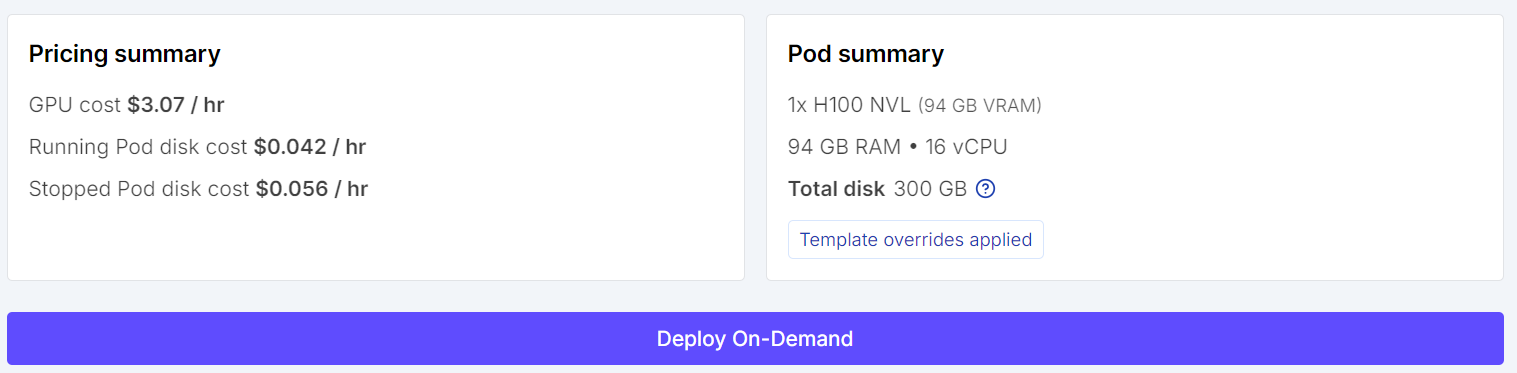
Inizia andando su RunPod e selezionando una macchina con GPU H100 NVL. Questa GPU offre circa 94 GB di VRAM e 94 GB di RAM di sistema, sufficienti per questo workflow di fine-tuning di Qwen3.6.
Scegli il template PyTorch più recente, quindi modifica la configurazione del pod prima del deployment. Imposta la dimensione del disco del container a 100 GB e quella del volume a 200 GB. Avrai così spazio sufficiente per scaricare il modello, mettere in cache le dipendenze e salvare in locale l'adapter fine-tunato.
Dovresti anche aggiungere una variabile d'ambiente HF_TOKEN in questa fase. Ti permetterà di accedere a Hugging Face in seguito, migliorare l'accesso al download del modello e semplificare la pubblicazione dell'adapter fine-tunato sull'Hub dopo il training.
Prima di avviare l'istanza, rivedi il riepilogo del pod per verificare il costo stimato. Quando è tutto corretto, distribuisci il pod.
Quando il pod è pronto, apri il link a Jupyter Notebook dalla dashboard di RunPod per lanciare JupyterLab. Crea un nuovo notebook Python e installa le librerie necessarie per il fine-tuning quantizzato, il caricamento del dataset e il supervised fine-tuning con TRL.
pip install -q -U transformers accelerate peft trl bitsandbytes datasets sentencepiecePoi accedi a Hugging Face usando la variabile d'ambiente HF_TOKEN che hai aggiunto durante la creazione del pod. In questo modo eviti di inserire il token in chiaro nel notebook e mantieni il workflow più pulito.
import os
from huggingface_hub import login
hf_token = os.getenv("HF_TOKEN")
login(token=hf_token)Ora importa le librerie necessarie e definisci i valori di configurazione che useremo durante il tutorial. Includono l'ID del modello, il nome del dataset, le dimensioni dei campioni, la directory di output e il seed casuale.
import os
import random
import re
import torch
from datasets import load_dataset
from peft import LoraConfig, prepare_model_for_kbit_training
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
set_seed,
)
from trl import SFTConfig, SFTTrainer
MODEL_ID = "Qwen/Qwen3.6-35B-A3B"
DATASET_ID = "keivalya/MedQuad-MedicalQnADataset"
SAMPLE_SIZE = 240
EVAL_SIZE = 24
COMPARISON_SAMPLE_COUNT = 3
MAX_SEQ_LENGTH = 768
OUTPUT_DIR = "qwen36-medquad-quick"
SEED = 42
set_seed(SEED)
random.seed(SEED)
def supports_bf16() -> bool:
return torch.cuda.is_available() and torch.cuda.get_device_capability(0)[0] >= 8
print(f"PyTorch: {torch.__version__}")
print(f"CUDA available: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"GPU: {torch.cuda.get_device_name(0)}")
print(
f"GPU memory (GB): {torch.cuda.get_device_properties(0).total_memory / 1024**3:.1f}"
)Eseguendo questa cella, dovresti vedere un output che conferma la disponibilità di CUDA e che il notebook è connesso a una GPU NVIDIA H100 NVL.
PyTorch: 2.8.0+cu128
CUDA available: True
GPU: NVIDIA H100 NVL
GPU memory (GB): 93.1In questa parte caricheremo il dataset medico di Q&A MedQuad, puliremo i campi di testo, filtreremo gli esempi di qualità inferiore e creeremo piccoli split di training e valutazione per un fine-tuning rapido.
Si parte caricando lo split di training del dataset MedQuad da Hugging Face. Dopo il caricamento, ispezioniamo la struttura del dataset, i nomi delle colonne e il primo esempio per capire con che tipo di coppie domanda-risposta mediche stiamo lavorando.
raw_dataset = load_dataset(DATASET_ID, split="train")
print(raw_dataset)
print("First example:", raw_dataset[0])Questo mostra che il dataset MedQuad contiene 16.407 esempi di domande e risposte mediche su tre campi: qtype, Question e Answer.
Dataset({
features: ['qtype', 'Question', 'Answer'],
num_rows: 16407
})
First example: {'qtype': 'susceptibility', 'Question': 'Who is at risk for Lymphocytic Choriomeningitis (LCM)? ?', 'Answer': 'LCMV infections can occur after exposure to fresh urine, droppings, saliva, or nesting materials from infected rodents. Transmission may also occur when these materials are directly introduced into broken skin, the nose, the eyes, or the mouth, or presumably, via the bite of an infected rodent. Person-to-person transmission has not been reported, with the exception of vertical transmission from infected mother to fetus, and rarely, through organ transplantation.'}Definiamo quindi una piccola funzione di pulizia del testo e una regola di filtraggio per rimuovere i campioni di bassa qualità. Il passaggio di cleaning normalizza gli spazi extra, mentre il filtraggio rimuove esempi con domande molto brevi, risposte molto brevi, risposte troppo lunghe o template di risposta generici meno utili per il training.
def clean_text(text):
text = re.sub(r"\s+", " ", str(text)).strip()
return text
BAD_ANSWER_PREFIXES = (
"These resources address",
"These resources from MedlinePlus",
"For more information, go to",
"For more information go to",
)
def keep_example(example):
question = clean_text(example["Question"])
answer = clean_text(example["Answer"])
if len(question) < 12 or len(answer) < 40:
return False
if len(answer) > 900:
return False
if any(answer.startswith(prefix) for prefix in BAD_ANSWER_PREFIXES):
return False
return True
filtered_dataset = raw_dataset.filter(keep_example)Dopo il filtraggio, mescoliamo il dataset, selezioniamo un sottoinsieme più piccolo per questo tutorial rapido e lo dividiamo in set di training e valutazione. In questo modo l'esecuzione resta leggera pur consentendoci di confrontare il modello prima e dopo il fine-tuning.
subset = filtered_dataset.shuffle(seed=SEED).select(range(SAMPLE_SIZE))
split_dataset = subset.train_test_split(test_size=EVAL_SIZE, seed=SEED)
train_dataset = split_dataset["train"]
eval_dataset = split_dataset["test"]
print(f"Filtered dataset size: {len(filtered_dataset)}")
print(f"Train size: {len(train_dataset)}")
print(f"Eval size: {len(eval_dataset)}")Dopo il filtraggio, rimangono 7.355 esempi di qualità superiore, da cui campioniamo 216 esempi di training e 24 di valutazione per questo run di fine-tuning veloce.
Filtered dataset size: 7355
Train size: 216
Eval size: 24In questo step configureremo la quantizzazione a 4 bit con BitsAndBytes, caricheremo il tokenizer di Qwen3.6 e poi il modello base per farlo girare in modo più efficiente sulla GPU H100 NVL.
Qwen3.6 è comunque un modello grande, quindi caricarlo in piena precisione userebbe molta più memoria. Per rendere il fine-tuning più efficiente, carichiamo il modello in precisione a 4 bit con BitsAndBytes. Questo riduce l'uso di memoria mantenendo il modello praticabile per il fine-tuning basato su QLoRA.
Qui usiamo la nf4 quantizzazione, abilitiamo la doppia quantizzazione e impostiamo il dtype di calcolo a bfloat16 quando la GPU lo supporta.
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16 if supports_bf16() else torch.float16,
)Successivamente, carichiamo il tokenizer per Qwen3.6. Verifichiamo anche se è già definito un token di padding. Se manca, riutilizziamo il token di fine sequenza come padding token, così il batching funziona correttamente durante training e generazione.
tokenizer = AutoTokenizer.from_pretrained(
MODEL_ID,
trust_remote_code=True,
use_fast=False,
)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_tokenOra carichiamo il modello base Qwen3.6 con le impostazioni di quantizzazione a 4 bit definite in precedenza. Usiamo device_map="auto" così il modello viene posizionato automaticamente sulla GPU disponibile e nuovamente bfloat16 quando supportato per un calcolo più efficiente.
Dopo il caricamento del modello, impostiamo l'ID del padding token e disabilitiamo l'uso della cache. È importante perché la cache è utile in inferenza, ma durante il fine-tuning può interferire con l'addestramento e aumentare l'uso di memoria.
model = AutoModelForCausalLM.from_pretrained(
MODEL_ID,
quantization_config=bnb_config,
device_map="auto",
dtype=torch.bfloat16 if supports_bf16() else torch.float16,
trust_remote_code=True,
)
model.config.pad_token_id = tokenizer.pad_token_id
model.config.use_cache = FalseIn questo step definiremo la struttura del prompt per Qwen3.6, puliremo gli output del modello, creeremo funzioni helper per training e inferenza e prepareremo alcuni esempi di anteprima per confrontare il modello prima e dopo il fine-tuning.
Partiamo definendo un breve system prompt che indichi al modello come rispondere. Poiché si tratta di Q&A mediche, vogliamo risposte dirette, fattuali e concise.
SYSTEM_PROMPT = "Answer the medical question directly in 2-4 factual sentences."Qwen3.6 usa un formato di input in stile chat, quindi ci serve una funzione helper che converta i nostri messaggi nella struttura di prompt corretta. Questa funzione applica il chat template del tokenizer e disabilita l'output di ragionamento così che il modello resti focalizzato sulla risposta finale.
def apply_chat_template(messages, add_generation_prompt=False):
kwargs = {
"tokenize": False,
"add_generation_prompt": add_generation_prompt,
}
try:
return tokenizer.apply_chat_template(
messages,
enable_thinking=False,
**kwargs,
)
except TypeError:
return tokenizer.apply_chat_template(
messages,
chat_template_kwargs={"enable_thinking": False},
**kwargs,
)Definiamo quindi una piccola funzione di pulizia per normalizzare il testo generato. Rimuove gli spazi extra e qualsiasi prefisso tipo answer: se appare nell'output.
def clean_answer_text(answer):
answer = clean_text(answer)
answer = re.sub(r"^answer\s*:\s*", "", answer, flags=re.IGNORECASE)
return answerCreiamo anche una funzione helper per il prompt utente. Mantiene il formato della domanda coerente tra training e valutazione e indica al modello di restituire solo la risposta senza ripetere la domanda.
def make_user_prompt(question):
return (
f"Question: {clean_text(question)}\n\n"
"Respond with only the answer. Do not restate the question."
)Ora possiamo formattare ogni esempio del dataset in una conversazione completa in stile chat con un messaggio di sistema, una domanda dell'utente e la risposta attesa dell'assistente. Questa è la struttura che useremo per il supervised fine-tuning.
def format_training_example(example):
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": make_user_prompt(example["Question"]),
},
{
"role": "assistant",
"content": clean_answer_text(example["Answer"]),
},
]
return {"text": apply_chat_template(messages, add_generation_prompt=False)}Prima di iniziare il training, ci serve una funzione helper che generi risposte dal modello base. La useremo per confrontare le risposte del modello prima e dopo il fine-tuning.
La funzione qui sotto costruisce il prompt, lo tokenizza, esegue la generazione e poi rimuove eventuali tracce di <think> e formattazioni extra dall'output.
@torch.inference_mode()
def generate_answer(question, max_new_tokens=160):
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": make_user_prompt(question),
},
]
prompt = apply_chat_template(messages, add_generation_prompt=True)
model_inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
generated = model.generate(
**model_inputs,
max_new_tokens=max_new_tokens,
do_sample=False,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
new_tokens = generated[0][model_inputs["input_ids"].shape[1] :]
text = tokenizer.decode(new_tokens, skip_special_tokens=True).strip()
return clean_answer_text(re.sub(r"<think>.*?</think>", " ", text, flags=re.DOTALL))Aggiungiamo anche una piccola funzione helper per accorciare output lunghi quando stampiamo esempi di anteprima.
def clip_text(text, max_chars=600):
text = re.sub(r"<think>.*?</think>", " ", text, flags=re.DOTALL)
text = re.sub(r"\s+", " ", text).strip()
return text if len(text) <= max_chars else text[:max_chars] + "..."Infine, costruiamo una funzione helper che crei alcune righe di anteprima affiancate. Ogni riga contiene la domanda, la previsione del modello e la risposta di riferimento. È un modo semplice per ispezionare le prestazioni prima e dopo il fine-tuning.
def generate_preview_rows(dataset, sample_count=COMPARISON_SAMPLE_COUNT):
sample_count = min(sample_count, len(dataset))
subset = dataset.select(range(sample_count))
previews = []
for row in subset:
previews.append(
{
"question": row["Question"],
"prediction": generate_answer(row["Question"]),
"reference": clean_answer_text(row["Answer"]),
}
)
return previews
formatted_train_dataset = train_dataset.map(
format_training_example,
remove_columns=train_dataset.column_names,
)
comparison_examples = eval_dataset.shuffle(seed=SEED).select(
range(COMPARISON_SAMPLE_COUNT)
)
print(formatted_train_dataset[0])Quando stampi il primo esempio di training formattato, dovresti vedere un campione in stile chat con il system prompt, la domanda dell'utente e la risposta dell'assistente già racchiusi nel template di Qwen.
{'text': '<|im_start|>system\nAnswer the medical question directly in 2-4 factual sentences.<|im_end|>\n<|im_start|>user\nQuestion: What is (are) COPD ?\n\nRespond with only the answer. Do not restate the question.<|im_end|>\n<|im_start|>assistant\n<think>\n\n</think>\n\nMore information on COPD is available at: What is COPD? and at the Learn More, Breathe Better Campaign For information on quitting smoking, visit http://www.surgeongeneral.gov/tobacco/ or Smokefree.gov. For information on the H1N1 flu and COPD, go to The Centers for Disease Control and Prevention.<|im_end|>\n'}Testeremo il modello base Qwen3.6 su alcuni esempi di valutazione prima del training. Questo ci fornisce un baseline per confrontare successivamente come cambia il modello dopo il fine-tuning.
Iniziamo generando risposte di anteprima per alcuni esempi campionati dallo split di valutazione.
Ogni anteprima include la domanda, la risposta del modello prima del fine-tuning e la risposta di riferimento dal dataset.
baseline_previews = generate_preview_rows(comparison_examples)
for idx, sample in enumerate(baseline_previews, start=1):
print(f"\n--- Preview {idx} ---")
print("Question:", sample["question"])
print("Model answer (before fine-tuning):", clip_text(sample["prediction"]))
print("Reference answer:", clip_text(sample["reference"]))Ecco i confronti affiancati tra la risposta attuale del modello e la risposta di riferimento. Questi esempi aiutano a capire il punto di partenza del modello prima di qualsiasi training specifico per il task.

Da questi esempi si vede già che il modello base è in grado di produrre risposte pertinenti dal punto di vista medico e generalmente corrette.
Tuttavia, le sue risposte non sempre corrispondono allo stile, al livello di dettaglio o alla formulazione delle risposte di riferimento del dataset. In alcuni casi, il modello fornisce una spiegazione più ampia o generica, mentre la risposta di riferimento è più specifica e meglio allineata al formato target.
In questa parte definiremo le impostazioni dell'adapter LoRA, configureremo gli argomenti per il supervised fine-tuning e inizializzeremo il trainer che gestirà il processo QLoRA.
Invece di aggiornare tutti i parametri del modello, QLoRA fa fine-tuning su un set molto più piccolo di pesi dell'adapter addestrabili. Questo rende il training molto più efficiente in termini di memoria, consentendo comunque al modello di adattarsi al nuovo task.
Qui definiamo una configurazione LoRA con rank 8, fattore di scaling 16 e un piccolo dropout. Prendiamo di mira tutti i layer lineari così che gli adapter vengano applicati in modo ampio nel modello.
lora_config = LoraConfig(
r=8,
lora_alpha=16,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules="all-linear",
)Quindi definiamo la configurazione di training usando SFTConfig. Queste impostazioni controllano il comportamento del run di supervised fine-tuning, inclusi batch size, accumulo dei gradienti, learning rate, frequenza di logging e modalità di precisione.
Questo tutorial usa una configurazione leggera con un'epoca di training e un batch size ridotto, così il run rimane pratico a scopo dimostrativo. Abilitiamo anche il gradient checkpointing e AdamW a 8 bit paginato per ridurre l'uso di memoria durante il training.
trainer_config = SFTConfig(
output_dir=OUTPUT_DIR,
dataset_text_field="text",
max_length=MAX_SEQ_LENGTH,
per_device_train_batch_size=2,
gradient_accumulation_steps=2,
num_train_epochs=1,
learning_rate=1e-4,
warmup_steps=5,
logging_steps=5,
save_strategy="epoch",
report_to="none",
packing=False,
gradient_checkpointing=True,
optim="paged_adamw_8bit",
bf16=supports_bf16(),
fp16=not supports_bf16(),
)Con le impostazioni dell'adapter e gli argomenti di training pronti, possiamo inizializzare l'SFTTrainer. Questo trainer riunisce il modello base, il dataset di training formattato, la configurazione LoRA e il tokenizer, preparando il modello al supervised fine-tuning.
trainer = SFTTrainer(
model=model,
train_dataset=formatted_train_dataset,
peft_config=lora_config,
args=trainer_config,
processing_class=tokenizer,
)Prima di iniziare il training, è utile confermare quanti parametri verranno effettivamente aggiornati. Uno dei principali vantaggi di QLoRA è che solo una piccolissima frazione del modello diventa addestrabile.
trainer.model.print_trainable_parameters()Questo mostra che viene addestrato solo circa lo 0,03% dei parametri del modello completo. È ciò che rende QLoRA un approccio così pratico per il fine-tuning di LLM su hardware limitato.
trainable params: 11,238,720 || all params: 34,671,849,408 || trainable%: 0.0324In questa sezione avvieremo il run di supervised fine-tuning, salveremo in locale l'adapter addestrato e poi lo pubblicheremo su Hugging Face, così potrà essere riutilizzato in seguito.
Ora che modello, dataset e trainer sono pronti, possiamo iniziare il processo di fine-tuning. Il trainer scorrerà il set di training formattato e aggiornerà solo i pesi dell'adapter LoRA invece dell'intero modello.
train_result = trainer.train()
train_resultDurante il training dovresti vedere la loss diminuire gradualmente. È un buon segno che il modello sta imparando il formato del task e si sta adattando ai dati di domanda-risposta mediche.
Al termine del training, salva in locale l'adapter fine-tunato e il tokenizer. Otterrai così un checkpoint riutilizzabile che potrai ricaricare in seguito senza ripetere l'intero run di training.
trainer.model.save_pretrained(OUTPUT_DIR)
tokenizer.save_pretrained(OUTPUT_DIR)Una volta salvato in locale l'adapter, puoi caricarlo su Hugging Face. In questo modo è più facile condividerlo, versionarlo e ricaricarlo in futuri notebook o workflow di deployment.
HF_REPO_ID = "kingabzpro/qwen36-medquad-quick"
trainer.model.push_to_hub(HF_REPO_ID)
tokenizer.push_to_hub(HF_REPO_ID) Al termine del caricamento, l'adapter fine-tunato sarà disponibile nel repository.
Al termine del caricamento, l'adapter fine-tunato sarà disponibile nel repository.
Fonte: kingabzpro/qwen36-medquad-quick
Ora che il training è completo, possiamo valutare il modello fine-tunato sugli stessi esempi di confronto usati in precedenza. Questo ci aiuta a fare un confronto diretto prima/dopo sulle stesse identiche domande.
model.eval()
fine_tuned_previews = generate_preview_rows(comparison_examples)
for idx, (before, after) in enumerate(
zip(baseline_previews, fine_tuned_previews), start=1
):
print(f"\n{'=' * 80}")
print(f"Sample {idx}")
print(f"{'=' * 80}")
print("Question:", before["question"])
print("\nBefore fine-tuning:")
print(clip_text(before["prediction"]))
print("\nAfter fine-tuning:")
print(clip_text(after["prediction"]))
print("\nReference answer:")
print(clip_text(before["reference"]))Dovresti vedere per ogni campione la risposta di baseline, la risposta fine-tunata e la risposta di riferimento. Questo rende più semplice ispezionare come l'adapter ha modificato stile e contenuto della risposta del modello.

Questi esempi mostrano che il fine-tuning ha aiutato il modello ad allinearsi meglio allo stile del dataset target, soprattutto su domande mediche brevi e fattuali.
Allo stesso tempo, i risultati mostrano anche che si è trattato solo di un run di fine-tuning ridotto su un sottoinsieme limitato del dataset, quindi non è garantito un miglioramento su ogni campione. Alcune risposte diventano più allineate alla distribuzione di training, mentre altre possono perdere dettagli utili o diventare troppo strette.
Per ottenere risultati migliori, il passo successivo sarebbe addestrare sull'intero dataset invece che su un piccolo sottoinsieme e far girare il fine-tuning per almeno 3 epoche. Potresti anche aumentare il rank di LoRA per dare all'adapter maggiore capacità di apprendimento e affinare ulteriormente il system prompt, così che il modello segua in modo più coerente lo stile di risposta medico desiderato.
Questi cambiamenti probabilmente produrranno miglioramenti più stabili su una gamma più ampia di domande.
Fare fine-tuning su un modello linguistico moderno non è così semplice come può sembrare all'inizio.
Anche se Qwen3.6-35B-A3B è un efficiente modello mixture-of-experts con 35 miliardi di parametri totali, serve comunque una potenza di calcolo notevole solo per caricarlo in modalità a 4 bit e prepararlo al training. Il training stesso rimane costoso, soprattutto quando si va oltre un piccolo sottoinsieme sperimentale e si inizia a lavorare con un dataset più grande o più epoche.
L'hardware conta molto. In questo tutorial abbiamo usato un H100 NVL per mantenere il workflow pratico. Su una GPU più vecchia, il tempo di training può aumentare drasticamente. Anche su una A100, una configurazione simile potrebbe richiedere facilmente circa un'ora e GPU più deboli allungherebbero ulteriormente i tempi.
Quindi, sebbene QLoRA e il caricamento a 4 bit rendano il fine-tuning più accessibile, non lo rendono "leggero" nel senso comune. Vale anche la pena chiedersi se il fine-tuning sia necessario in primo luogo. Per molti task di base, non consiglierei di passare subito al fine-tuning.
Se dedichi tempo a migliorare il prompt, strutturare meglio il workflow e usare tool, MCP o metodi basati su retrieval, spesso puoi avvicinarti al comportamento target senza alcun training. In molti casi, questo può portarti vicino all'80% del risultato desiderato, risultando molto più veloce, economico e facile da iterare.
Il fine-tuning diventa molto più prezioso quando ti serve che il modello impari in modo consistente uno stile di risposta molto specifico, un comportamento di dominio o un formato istituzionale. È lì che inizia ad avere senso. Se vuoi che il modello risponda esattamente come farebbe un determinato ospedale, sistema medico o workflow specialistico, allora il fine-tuning è la strada migliore.
In altre parole, parti prima da prompting e design del workflow, e passa al fine-tuning quando hai davvero bisogno che il modello interiorizzi un modo specializzato di rispondere.
I migliori corsi di AI
Programma
Programma
Corso
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min

