Isi artikel ini panjang namun rinci, jadi kami akan membuat pengantarnya sesingkat mungkin, langsung mulai dengan pertanyaan, “Mengapa repot-repot menggunakan gradient boosting?”
Ada sejumlah alasan yang sangat baik:
- Gradient boosting adalah yang terbaik: akurasi dan performanya tak tertandingi untuk tugas pembelajaran terawasi pada data tabular.
- Gradient boosting sangat serbaguna: dapat digunakan dalam banyak tugas penting seperti regresi, klasifikasi, pemeringkatan, dan analisis survival.
- Gradient boosting dapat ditafsirkan: tidak seperti algoritme kotak-hitam seperti neural network, gradient boosting tidak mengorbankan keterjelasan demi performa. Ia bekerja seperti jam tangan Swiss dan, dengan kesabaran, Anda bahkan bisa menjelaskannya kepada anak sekolah.
- Gradient boosting diimplementasikan dengan baik: ini bukan algoritme yang nilai praktisnya minim. Berbagai pustaka gradient boosting seperti XGBoost dan LightGBM di Python digunakan oleh ratusan ribu orang.
- Gradient boosting menang: sejak 2015, para profesional menggunakannya untuk secara konsisten menang dalam kompetisi tabular di platform seperti Kaggle.
Jika salah satu poin ini sedikit pun menarik, ada baiknya Anda terus membaca artikel ini.
Jadi, mari kita mulai!
Apa yang Akan Anda Pelajari dalam Tutorial Ini?
Inti terpenting dari artikel ini adalah Anda pulang dengan pemahaman yang sangat mantap tentang cara kerja internal gradient boosting tanpa banyak sakit kepala matematika. Bagaimanapun, gradient boosting ditujukan untuk penggunaan praktis, bukan untuk dianalisis secara matematis.
Apa itu Gradient Boosting Secara Umum?
Boosting adalah teknik ansambel yang kuat dalam machine learning. Tidak seperti model tradisional yang belajar dari data secara independen, boosting menggabungkan prediksi dari banyak weak learner untuk menciptakan satu strong learner yang lebih akurat.
Saya baru saja menulis beberapa istilah baru, jadi mari saya jelaskan satu per satu, mulai dari weak learner.
Weak learner adalah model machine learning yang sedikit lebih baik daripada tebak acak. Misalnya, katakanlah kita mengklasifikasikan jamur menjadi dapat dimakan dan tidak dapat dimakan. Jika model tebak acak akurasinya 40%, weak learner akan sedikit di atas itu: 50–60%.
Boosting menggabungkan puluhan atau ratusan weak learner ini untuk membangun strong learner dengan potensi akurasi lebih dari 95% pada masalah yang sama.
Weak learner yang paling populer adalah decision tree, dipilih karena kemampuannya bekerja dengan hampir semua dataset. Jika Anda belum familiar dengan decision tree, lihat tutorial Decision Tree Classification dari DataCamp.
Aplikasi Dunia Nyata dari Gradient Boosting
Gradient boosting telah menjadi kekuatan dominan dalam machine learning sehingga aplikasinya kini menjangkau berbagai industri, mulai dari memprediksi churn pelanggan hingga mendeteksi asteroid. Berikut sekilas kisah suksesnya di Kaggle dan kasus penggunaan di dunia nyata:
Mendominasi kompetisi Kaggle:
- Otto Group Product Classification Challenge: seluruh 10 posisi teratas menggunakan implementasi gradient boosting XGBoost.
- Santander Customer Transaction Prediction: solusi berbasis XGBoost kembali meraih posisi puncak untuk memprediksi perilaku pelanggan dan transaksi keuangan.
- Netflix Movie Recommendation Challenge: Gradient boosting berperan penting dalam membangun sistem rekomendasi untuk perusahaan bernilai miliaran seperti Netflix.
Mengubah bisnis dan industri:
- Ritel dan e-commerce: rekomendasi personal, manajemen inventaris, deteksi penipuan
- Keuangan dan asuransi: penilaian risiko kredit, prediksi churn, perdagangan algoritmik
- Kesehatan dan medis: diagnosis penyakit, penemuan obat, pengobatan personal
- Pencarian dan iklan online: peringkat pencarian, penargetan iklan, prediksi click-through rate
Jadi, mari akhirnya kita mengintip bagian dalam algoritme legendaris ini!
Algoritma Gradient Boosting: Panduan Langkah demi Langkah
Input
Algoritma gradient boosting bekerja untuk data tabular dengan sekumpulan fitur (X) dan target (y). Seperti algoritme machine learning lainnya, tujuannya adalah belajar cukup banyak dari data pelatihan agar dapat menggeneralisasi dengan baik ke titik data yang belum terlihat.
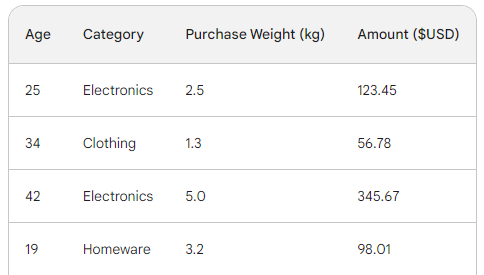
Untuk memahami proses dasar gradient boosting, kita akan menggunakan dataset penjualan sederhana dengan empat baris. Dengan tiga fitur — usia pelanggan, kategori pembelian, dan bobot pembelian, kita ingin memprediksi jumlah pembelian:
Fungsi loss dalam gradient boosting
Dalam machine learning, sebuah fungsi loss adalah komponen penting yang memungkinkan kita mengkuantifikasi perbedaan antara prediksi model dan nilai aktual. Intinya, ini mengukur bagaimana kinerja model.
Berikut rincian perannya:
- Menghitung galat: Mengambil keluaran prediksi model dan membandingkannya dengan ground truth (nilai observasi aktual). Cara membandingkannya, yakni menghitung selisihnya, bervariasi antar fungsi.
- Mengarahkan pelatihan model: tujuan model adalah meminimalkan fungsi loss. Sepanjang pelatihan, model terus memperbarui arsitektur internal dan konfigurasinya untuk membuat loss sekecil mungkin.
- Metrik evaluasi: Dengan membandingkan loss pada dataset pelatihan, validasi, dan uji, Anda dapat menilai kemampuan model untuk menggeneralisasi dan menghindari overfitting.
Dua fungsi loss yang paling umum adalah:
- Mean Squared Error (MSE): Fungsi loss populer untuk regresi ini mengukur jumlah kuadrat selisih antara nilai prediksi dan aktual. Gradient boosting sering menggunakan variasi berikut:
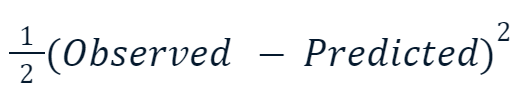
Alasan nilai kuadrat dikalikan setengah ada hubungannya dengan diferensiasi. Ketika kita mengambil turunan fungsi loss ini, setengahnya akan menghilang dengan kuadrat karena aturan pangkat. Jadi, hasil akhirnya akan menjadi -(Observed - Predicted), membuat matematika jauh lebih mudah dan kurang mahal secara komputasi.
- Cross-entropy: Fungsi ini mengukur perbedaan antara dua distribusi probabilitas. Jadi, umum digunakan untuk tugas klasifikasi di mana targetnya berupa kategori diskret.
Karena kita melakukan regresi, kita akan menggunakan MSE.
Langkah 1: Buat prediksi awal
Gradient boosting adalah algoritme yang secara bertahap meningkatkan akurasinya. Untuk memulai proses, kita memerlukan tebakan atau prediksi awal. Tebakan awal selalu berupa rata-rata target. Dengan kata lain, untuk putaran pertama, model kita memprediksi bahwa semua pembelian sama — 156 dolar:
![]()
Alasan memilih rata-rata berkaitan dengan fungsi loss yang kita pilih dan turunannya. Di setiap langkah, kita mencari nilai untuk menemukan minimum fungsi loss. Dengan kata lain, kita mencari nilai yang membuat turunan (gradien) dari fungsi loss bernilai 0.
Dan ketika kita mengambil turunan fungsi loss untuk setiap nilai observasi terhadap nilai prediksi lalu menjumlahkannya, kita akan mendapatkan rata-rata target.
Jadi, prediksi awal kita adalah rata-rata — 156 dolar. Simpan ini dalam ingatan saat kita lanjutkan.
Langkah 2: Hitung pseudo-residual
Langkah berikutnya adalah mencari selisih antara setiap nilai observasi dan prediksi awal kita: 156 - Observed. Untuk ilustrasi, kita letakkan selisih tersebut di kolom baru:
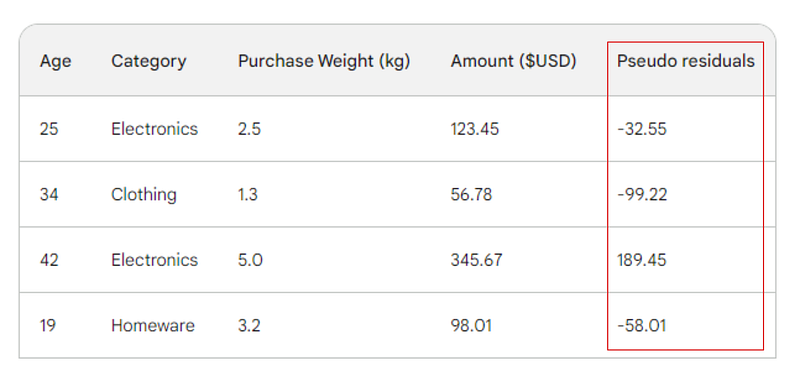
Ingat bahwa dalam regresi linear, selisih antara nilai observasi dan prediksi disebut residual. Untuk membedakan regresi linear dan gradient boosting, kita menyebutnya pseudo-residual (ada alasan lain penamaannya demikian, tetapi tidak akan kita bahas di artikel ini).
Langkah 3: Bangun weak learner
Selanjutnya, kita akan membangun decision tree (weak learner) yang memprediksi residual menggunakan tiga fitur yang kita punya (usia, kategori, bobot pembelian). Untuk masalah ini, kita batasi decision tree hanya empat daun (node terminal), tetapi dalam praktiknya, orang biasanya memilih antara 8 dan 32 daun.
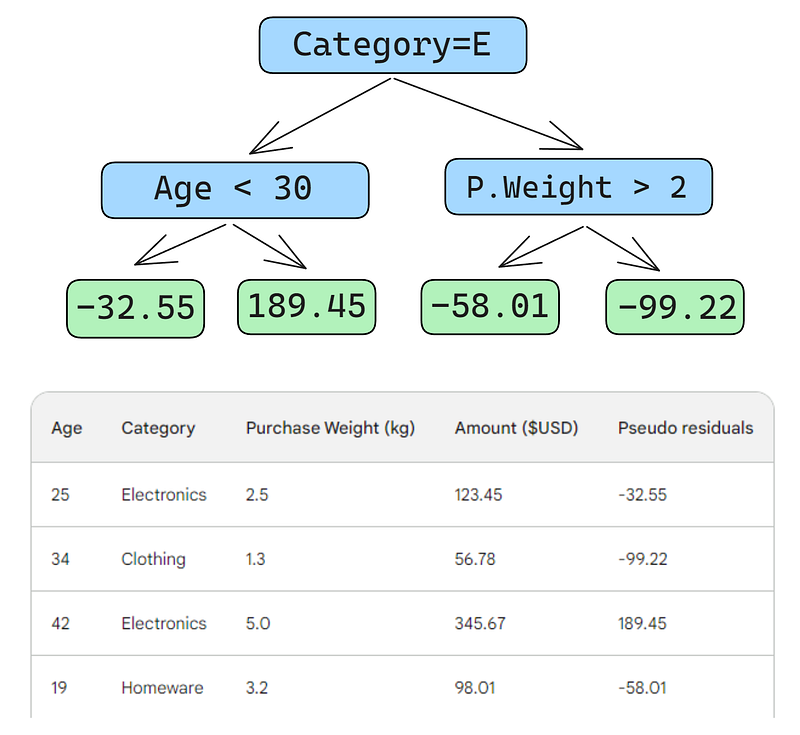
Setelah pohon di-fit ke data, kita membuat prediksi untuk tiap baris dalam data. Berikut cara melakukannya untuk baris pertama:
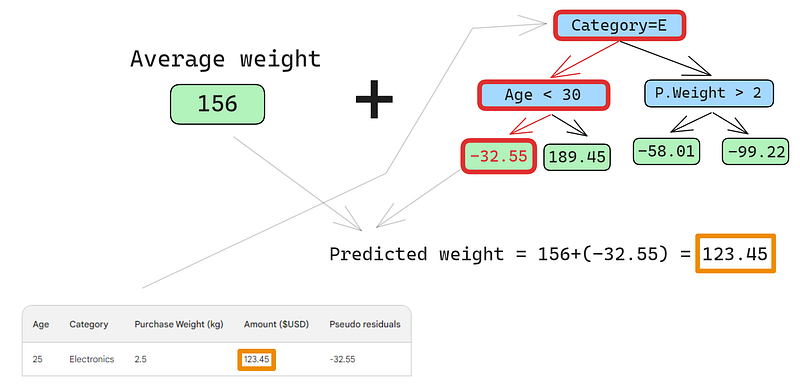
Ada kesalahan kecil pada gambar di bawah: seharusnya tertulis “Predicted purchase amount,” bukan “Predicted weight”
Baris pertama memiliki fitur berikut: kategori elektronik (cabang kiri dari node akar) dan usia pelanggan di bawah 30 (cabang kiri dari node anak). Ini menempatkan -32,55 ke node daun. Untuk membuat prediksi akhir, kita tambahkan -32,55 ke prediksi pertama kita, yang kebetulan persis sama dengan nilai observasi — 123,45 dolar!
Kita baru saja membuat prediksi sempurna, jadi mengapa repot membangun pohon lain? Nah, saat ini, kita sangat overfitting pada data pelatihan. Kita ingin modelnya menggeneralisasi. Jadi, untuk mengurangi masalah ini, gradient boosting memiliki parameter bernama learning rate.
Learning rate dalam gradient boosting hanyalah pengali antara 0 dan 1 yang menskalakan prediksi setiap weak learner (lihat bagian di bawah untuk detail tentang learning rate). Ketika kita menambahkan learning rate arbitrer sebesar 0,1, prediksi kita menjadi 152,75, bukan 123,45 yang sempurna.

Mari memprediksi baris kedua juga:
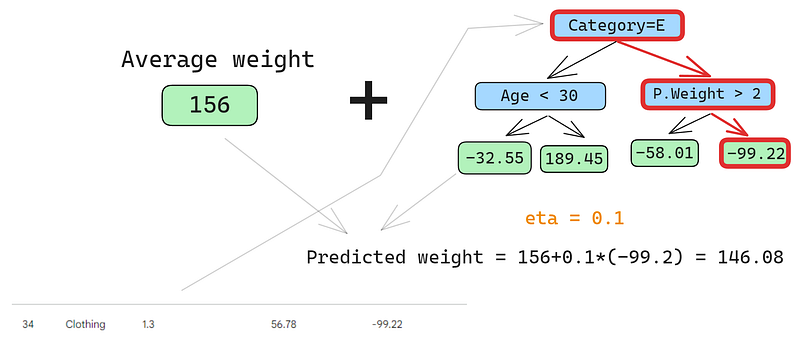
Kita jalankan baris tersebut melalui pohon dan mendapatkan 146,08 sebagai prediksi. Kita lanjutkan dengan cara ini untuk semua baris hingga kita punya empat prediksi untuk empat baris: 152,75; 146,08; 174,945; 150,2. Mari tambahkan sebagai kolom baru untuk sementara:
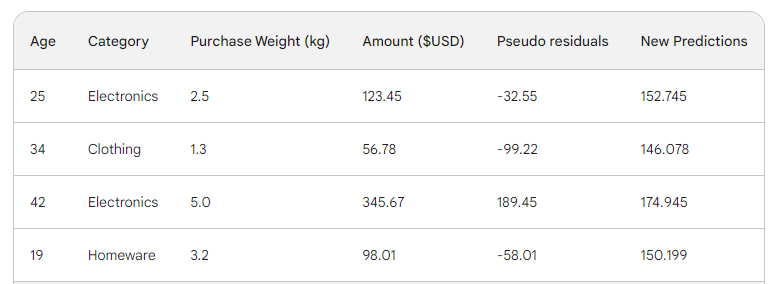
Berikutnya, kita cari pseudo-residual baru dengan mengurangkan prediksi baru dari jumlah pembelian. Mari tambahkan sebagai kolom baru pada tabel dan hapus dua kolom terakhir:
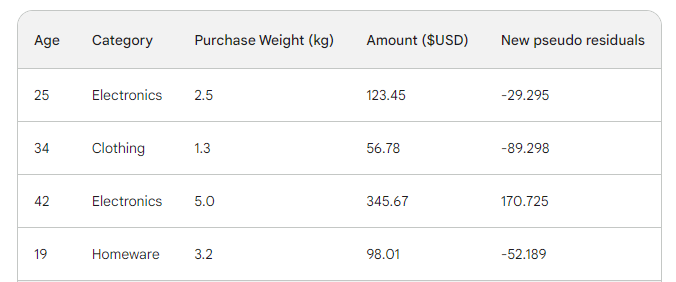
Seperti yang bisa Anda lihat, pseudo-residual baru kita lebih kecil, yang berarti loss kita turun.
Langkah 4: Iterasi
Pada langkah berikutnya, kita mengulang langkah 3, yaitu membangun lebih banyak weak learner. Satu hal yang perlu diingat adalah kita harus terus menambahkan residual dari setiap pohon ke prediksi awal untuk menghasilkan prediksi berikutnya.
Sebagai contoh, jika kita membangun 10 pohon dan residual setiap pohon dilambangkan sebagai r_i (1 <= i <= 10), maka prediksi berikutnya menjadi p_10 = 156 + eta * (r_1 + r_2 + ... + r_10) di mana p_10 menyatakan prediksi pada putaran kesepuluh.
Dalam praktiknya, para profesional sering memulai dengan 100 pohon, bukan hanya 10. Dalam kasus ini, algoritme dikatakan berlatih selama 100 boosting round.
Jika Anda tidak tahu jumlah pohon yang tepat yang dibutuhkan untuk masalah spesifik Anda, Anda dapat menggunakan teknik sederhana yang disebut early stopping.
Dalam early stopping, kita memilih jumlah pohon yang besar, seperti 1000 atau 10000. Lalu, alih-alih menunggu algoritme menyelesaikan semua pohon itu, kita memantau loss. Jika loss tidak membaik selama sejumlah boosting round tertentu, misalnya 50, kita hentikan pelatihan lebih awal, menghemat waktu dan sumber daya komputasi.
Mengonfigurasi Model Gradient Boosting
Dalam machine learning, memilih pengaturan untuk sebuah model dikenal sebagai "penyelarasan hyperparameter". Pengaturan ini, yang disebut "hyperparameter", adalah opsi yang harus dipilih sendiri oleh engineer machine learning. Tidak seperti parameter lain, model tidak dapat mempelajari nilai terbaik untuk hyperparameter hanya dengan dilatih pada data.
Model gradient boosting memiliki banyak hyperparameter, beberapa di antaranya akan saya uraikan di bawah.
Objective
Parameter ini menetapkan arah dan fungsi loss dari algoritme. Jika tujuannya adalah regresi, MSE dipilih sebagai fungsi loss, sedangkan untuk klasifikasi, Cross-Entropy yang digunakan. Pustaka Python seperti XGBoost menawarkan objective lain untuk jenis tugas lain, seperti ranking dengan fungsi loss yang sesuai.
Learning rate
Hyperparameter terpenting dari gradient boosting barangkali adalah learning rate. Ini mengontrol kontribusi setiap weak learner dengan menyesuaikan faktor penyusutan. Nilai yang lebih kecil (mendekati 0) menurunkan seberapa besar pengaruh setiap weak learner dalam ansambel. Ini memerlukan pembangunan lebih banyak pohon dan, karenanya, lebih banyak waktu untuk menyelesaikan pelatihan. Namun, strong learner akhirnya akan benar-benar kuat dan kebal terhadap overfitting.
Jumlah pohon
Parameter ini, juga disebut jumlah boosting round atau n_es timators, mengontrol jumlah pohon yang akan dibangun. Semakin banyak pohon yang Anda bangun, semakin kuat dan andal kinerja ansambelnya. Kompleksitasnya juga meningkat karena lebih banyak pohon memungkinkan model menangkap lebih banyak pola dalam data. Namun, lebih banyak pohon secara signifikan meningkatkan peluang overfitting. Untuk menguranginya, gunakan kombinasi early stopping dan learning rate rendah.
Kedalaman maksimum
Parameter ini mengontrol jumlah level pada setiap weak learner (decision tree). Kedalaman maksimum 3 berarti ada tiga level pada pohon, termasuk level daun. Semakin dalam pohon, semakin kompleks dan mahal secara komputasi model tersebut. Pilih nilai mendekati 3 untuk mencegah overfitting. Batas maksimum Anda sebaiknya kedalaman 10.
Jumlah minimum sampel per daun
Parameter ini mengontrol bagaimana cabang terbelah pada decision tree. Menetapkan nilai rendah untuk jumlah sampel di node terminal (daun) membuat keseluruhan algoritme sensitif terhadap derau. Jumlah minimum sampel yang lebih besar membantu mencegah overfitting dengan menyulitkan pohon membuat split berdasarkan titik data yang terlalu sedikit.
Tingkat subsampling
Parameter ini mengontrol proporsi data yang digunakan untuk melatih setiap pohon. Pada contoh di atas, kita menggunakan 100% baris karena hanya ada empat baris dalam dataset kita. Namun, dataset dunia nyata sering kali jauh lebih besar dan memerlukan sampling. Jadi, jika Anda menetapkan tingkat subsampling ke nilai di bawah 1, misalnya 0,7, setiap weak learner dilatih pada 70% baris yang diambil secara acak. Subsample rate yang lebih kecil dapat mempercepat pelatihan tetapi juga bisa menyebabkan overfitting.
Tingkat sampling fitur
Parameter ini persis seperti subsampling, tetapi men-sampling baris. Untuk dataset dengan ratusan fitur, direkomendasikan memilih tingkat sampling fitur antara 0,5 dan 1 untuk menurunkan peluang overfitting.
Gradient boosting adalah model paling mumpuni yang kita miliki untuk tugas pembelajaran terawasi pada data tabular. Jadi, sebagian besar waktu, Anda tidak perlu khawatir model ini tidak cukup baik untuk sebuah tugas. Saat menggunakan gradient boosting, waktu Anda hampir selalu dihabiskan untuk bagaimana meregularisasinya — menjinakkan kekuatannya agar tidak sekadar melahap dataset Anda dan menjadi tak berguna ketika berhadapan dengan data yang belum terlihat.
Hyperparameter yang saya perkenalkan semuanya membantu Anda dalam tugas ini dan disertakan dalam setiap implementasi gradient boosting di Python. Gunakan dengan bijak.
Gradient Boosting yang Diimplementasikan di Python
Seperti yang saya sebutkan sebelumnya, gradient boosting telah mapan melalui pustaka Python. Berikut empat yang utama:
- XGBoost: eXtreme Gradient Boosting
- LightGBM: Light Gradient Boosting Machine
- CatBoost: Categorical Boosting
- Scikit-learn: Memiliki dua estimator untuk regresi dan klasifikasi
Tiga pustaka pertama mirip satu sama lain:
- Kinerja dominan
- Dukungan GPU
- Set hyperparameter yang kaya (mudah dikonfigurasi)
- Dukungan komunitas yang sangat tinggi
- Banyak digunakan di industri
Alternatif populer untuk ketiga pustaka tersebut adalah Scikit-learn, yang memiliki kelemahan hanya mendukung CPU. Karena gradient boosting adalah algoritme yang berat secara komputasi, menjalankannya di CPU bisa jadi tidak layak untuk dataset besar (kita bicara ratusan ribu baris).
Namun, kita harus ingat bahwa Scikit-learn, sendirian, lebih populer daripada ketiga pustaka itu digabung. Selain dua estimator gradient boosting untuk klasifikasi dan regresi, Scikit-learn menawarkan puluhan model lain untuk berbagai tugas pembelajaran terawasi dan tidak terawasi.
Selain itu, model gradient boosting yang dibangun dengan Scikit-learn dapat diintegrasikan ke dalam ekosistemnya yang kaya seperti pipeline, estimator cross-validation, pemroses data, dan lain-lain.
Berikut panduan langkah demi langkah cara melakukan klasifikasi dengan GradientBoostingClassifier. Kita akan memprediksi kualitas cut berlian berdasarkan harganya dan ukuran fisik lainnya. Dataset ini sudah tersedia di pustaka Seaborn.
Pro tip: Gunakan tombol “Explain code” pada editor cuplikan kode DataCamp untuk mendapatkan penjelasan rinci baris demi baris tentang apa yang terjadi.
1. Impor pustaka
import pandas as pd
import seaborn as sns
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import cross_val_score, train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler2. Muat data
# Load the diamonds dataset from Seaborn
diamonds = sns.load_dataset("diamonds")
# Split data into features and target
X = diamonds.drop("cut", axis=1)
y = diamonds["cut"]3. Bagi data
# Split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)4. Definisikan fitur kategorikal dan numerik
# Define categorical and numerical features
categorical_features = X.select_dtypes(
include=["object"]
).columns.tolist()
numerical_features = X.select_dtypes(
include=["float64", "int64"]
).columns.tolist()5. Tentukan langkah prapemrosesan untuk fitur kategorikal dan numerik
preprocessor = ColumnTransformer(
transformers=[
("cat", OneHotEncoder(), categorical_features),
("num", StandardScaler(), numerical_features),
]
)6. Buat pipeline Gradient Boosting Classifier
pipeline = Pipeline(
[
("preprocessor", preprocessor),
("classifier", GradientBoostingClassifier(random_state=42)),
]
)
7. CV dan pelatihan
# Perform 5-fold cross-validation
cv_scores = cross_val_score(pipeline, X_train, y_train, cv=5)
# Fit the model on the training data
pipeline.fit(X_train, y_train)
# Predict on the test set
y_pred = pipeline.predict(X_test)
# Generate classification report
report = classification_report(y_test, y_pred)
8. Laporkan hasil akhir
print(f"Mean Cross-Validation Accuracy: {cv_scores.mean():.4f}")
print("\nClassification Report:")
print(report)
Mean Cross-Validation Accuracy: 0.7621
Classification Report:
precision recall f1-score support
Fair 0.90 0.91 0.91 335
Good 0.81 0.63 0.71 1004
Ideal 0.82 0.91 0.86 4292
Premium 0.70 0.86 0.77 2775
Very Good 0.66 0.41 0.51 2382
accuracy 0.76 10788
macro avg 0.78 0.74 0.75 10788
weighted avg 0.75 0.76 0.75 10788
Akurasi berbobotnya 75%, yang tidak buruk untuk model baseline dengan parameter default. Jadi, sebagai tantangan, saya serahkan kepada Anda untuk menyetel hyperparameter GradientBoostingClassifier agar mencapai performa di atas 95%. Ya, itu mungkin! (Petunjuk: baca bagian terakhir dengan saksama dan lihat dokumentasi Scikit-learn untuk classifier).
Kesimpulan dan pembelajaran lanjutan
Walaupun kita telah belajar banyak, fokus utama artikel ini adalah pada cara kerja internal algoritme gradient boosting. Memahami cara kerjanya tidak serta-merta berarti mampu menggunakannya dengan baik dalam praktik. Namun, pemahaman intuitif selalu sangat membantu.
Untuk pembelajaran lanjutan, saya merekomendasikan sumber berikut:
- Menggunakan Gradient Boosting dengan XGBoost oleh DataCamp: artikel peringkat #1 tentang XGBoost di Google
- Kursus Extreme Gradient Boosting With XGBoost: Kursus komprehensif tentang XGBoost
Terima kasih telah membaca!

