El cuerpo de este artículo es largo pero detallado, así que haremos la introducción lo más breve posible, comenzando directamente con la pregunta: "¿Por qué molestarse con el refuerzo de gradiente?"
Hay varias razones excelentes:
- El refuerzo de gradiente es el mejor: su precisión y rendimiento son incomparables para las tareas de aprendizaje supervisado tabular.
- El refuerzo de gradiente es muy versátil: puede utilizarse en muchas tareas importantes, como la regresión, la clasificación, la jerarquización y el análisis de supervivencia.
- El refuerzo de gradiente es interpretable: a diferencia de los algoritmos de caja negra como las redes neuronales, el refuerzo de gradiente no sacrifica la interpretabilidad por el rendimiento. Funciona como un reloj suizo y, sin embargo, con paciencia, puedes enseñar cómo funciona a un escolar.
- El refuerzo de gradiente está bien implementado: no es uno de esos algoritmos que tienen poco valor práctico. Cientos de miles de personas utilizan varias bibliotecas de refuerzo de gradiente como XGBoost y LightGBM en Python.
- El refuerzo de gradiente gana: desde 2015, los profesionales lo han utilizado para ganar sistemáticamente competiciones tabulares en plataformas como Kaggle.
Si alguno de estos puntos te resulta remotamente atractivo, vale la pena que sigas leyendo este artículo.
Así que, ¡empecemos!
¿Qué aprenderás en este tutorial?
Lo más importante de este artículo es que te vas con una comprensión muy firme del funcionamiento interno del aumento de gradiente sin muchos quebraderos de cabeza matemáticos. Al fin y al cabo, el refuerzo de gradiente es para utilizarlo en la práctica, no para analizarlo matemáticamente.
¿Qué es el refuerzo de gradiente en general?
El refuerzo es una potente técnica de conjunto en el aprendizaje automático. A diferencia de los modelos tradicionales que aprenden de los datos de forma independiente, la potenciación combina las predicciones de múltiples aprendices débiles para crear un único aprendiz fuerte más preciso.
Acabo de escribir un montón de términos nuevos, así que déjame explicarte cada uno de ellos, empezando por los de aprendizaje débil.
Un aprendiz débil es un modelo de aprendizaje automático que es ligeramente mejor que un modelo de adivinación aleatoria. Por ejemplo, supongamos que clasificamos las setas en comestibles y no comestibles. Si un modelo de adivinación aleatoria tiene una precisión del 40%, un aprendiz débil estaría justo por encima: 50-60%.
El refuerzo combina docenas o cientos de estos aprendices débiles para construir un aprendiz fuerte con un potencial de más del 95% de precisión en el mismo problema.
El aprendiz débil más popular es un árbol de decisión, elegido por su capacidad para trabajar con casi cualquier conjunto de datos. Si no estás familiarizado con los árboles de decisión, echa un vistazo a este tutorial de Clasificación de Árboles de Decisión de DataCamp.
Aplicaciones reales del refuerzo de gradiente
El refuerzo de gradiente se ha convertido en una fuerza tan dominante en el aprendizaje automático que sus aplicaciones abarcan ahora diversos sectores, desde la predicción de la pérdida de clientes hasta la detección de asteroides. He aquí un vistazo a sus casos de éxito en Kaggle y a casos de uso en el mundo real:
Dominar las competiciones de Kaggle:
- Desafío de Clasificación de Productos del Grupo Otto: en las 10 primeras posiciones se utilizó la implementación XGBoost del refuerzo de gradiente.
- Predicción de transacciones de clientes de Santander: Las soluciones basadas en XGBoost volvieron a ocupar los primeros puestos en la predicción del comportamiento de los clientes y las transacciones financieras.
- Reto de recomendación de películas de Netflix: El refuerzo de gradiente desempeñó un papel crucial en la creación de sistemas de recomendación para empresas multimillonarias como Netflix.
Transformar la empresa y la industria:
- Comercio minorista y electrónico: recomendaciones personalizadas, gestión de inventarios, detección de fraudes
- Finanzas y seguros: evaluación del riesgo crediticio, predicción del churn, negociación algorítmica
- Sanidad y medicina: diagnóstico de enfermedades, descubrimiento de fármacos, medicina personalizada
- Búsqueda y publicidad en línea: clasificación de búsquedas, orientación de anuncios, predicción del porcentaje de clics
Así que, ¡vamos a echar un vistazo por fin bajo el capó de este legendario algoritmo!
El algoritmo de refuerzo de gradiente: Guía paso a paso
Entrada
El algoritmo de refuerzo de gradiente funciona para datos tabulares con un conjunto de características (X) y un objetivo (y). Como otros algoritmos de aprendizaje automático, el objetivo es aprender lo suficiente de los datos de entrenamiento para generalizar bien a puntos de datos no vistos.
Para comprender el proceso subyacente del refuerzo de gradiente, utilizaremos un sencillo conjunto de datos de ventas con cuatro filas. Utilizando tres características: edad del cliente, categoría de compra y peso de la compra, queremos predecir el importe de la compra:
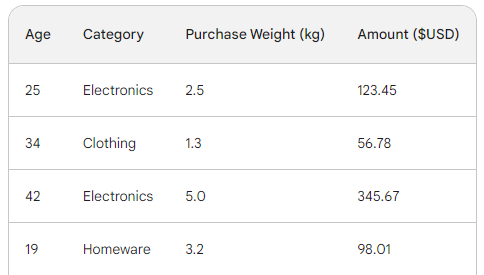
La función de pérdida en el refuerzo de gradiente
En el aprendizaje automático, una función de pérdida es un componente crítico que nos permite cuantificar la diferencia entre las predicciones de un modelo y los valores reales. En esencia, mide el rendimiento de un modelo.
Aquí tienes un desglose de su función:
- Calcula el error: Toma la salida prevista del modelo y compárala con la verdad sobre el terreno (valores reales observados). La forma en que compara, es decir, calcula la diferencia, varía de una función a otra.
- Guía el entrenamiento del modelo: el objetivo de un modelo es minimizar la función de pérdida. A lo largo del entrenamiento, el modelo actualiza continuamente su arquitectura y configuración internas para que la pérdida sea la menor posible.
- Métrica de evaluación: Comparando la pérdida en los conjuntos de datos de entrenamiento, validación y prueba, puedes evaluar la capacidad de generalización de tu modelo y evitar el sobreajuste.
Las dos funciones de pérdida más comunes son:
- Error cuadrático medio (ECM): Esta popular función de pérdida para la regresión mide la suma de las diferencias al cuadrado entre los valores predichos y los reales. El refuerzo de gradiente utiliza a menudo esta variante:
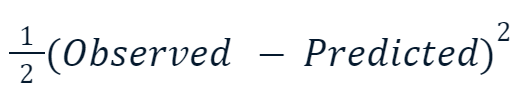
La razón por la que el valor al cuadrado se multiplica por la mitad tiene que ver con la diferenciación. Cuando tomamos la derivada de esta función de pérdida, la mitad se anula con el cuadrado debido a la regla de la potencia. Así, el resultado final sería simplemente -(Observed - Predicted), lo que facilitaría mucho las matemáticas y las haría menos costosas computacionalmente.
- Entropía cruzada: Esta función mide la diferencia entre dos distribuciones de probabilidad. Por lo tanto, se suele utilizar para tareas de clasificación en las que los objetivos tienen categorías discretas.
Como estamos haciendo una regresión, utilizaremos el MSE.
Paso 1: Haz una predicción inicial
El refuerzo de gradiente es un algoritmo que aumenta gradualmente su precisión. Para iniciar el proceso, necesitamos una conjetura o predicción inicial. La suposición inicial es siempre la media del objetivo. En otras palabras, para la primera ronda, nuestro modelo predice que todas las compras fueron iguales: 156 dólares:
![]()
La razón de elegir la media tiene que ver con la función de pérdida elegida y su derivada. A cada paso, buscamos un valor para encontrar el mínimo de la función de pérdida. En otras palabras, buscamos un valor que haga que la derivada (gradiente) de la función de pérdida sea 0.
Y cuando tomamos la derivada de la función de pérdida para cada valor observado con respecto al predicho y los sumamos, obtenemos la media del objetivo.
Por tanto, nuestra predicción inicial es la media:156 dólares. Mantenlo en la memoria mientras continuamos.
Paso 2: Calcula los pseudorresiduos
El siguiente paso es hallar las diferencias entre cada valor observado y nuestra predicción inicial: 156 - Observed. A título ilustrativo, pondremos esas diferencias en una nueva columna:
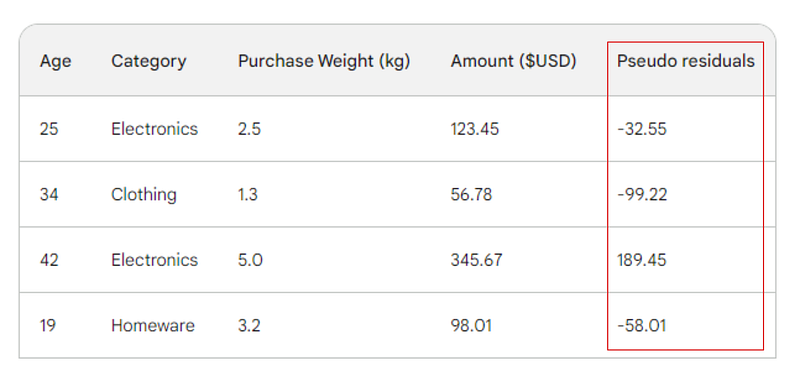
Recuerda que en la regresión lineal, la diferencia entre los valores observados y los valores predichos se denomina residuos. Para diferenciar la regresión lineal y el refuerzo de gradiente, los llamamos pseudorresiduos (hay otras razones por las que se llaman así, pero no entraremos en ellas en este artículo).
Paso 3: Construye un aprendiz débil
A continuación, construiremos un árbol de decisión (aprendiz débil) que prediga los residuos utilizando las tres características que tenemos (edad, categoría, peso de compra). Para este problema, limitaremos el árbol de decisión a sólo cuatro hojas (nodos terminales), pero en la práctica, la gente suele elegir hojas entre 8 y 32.
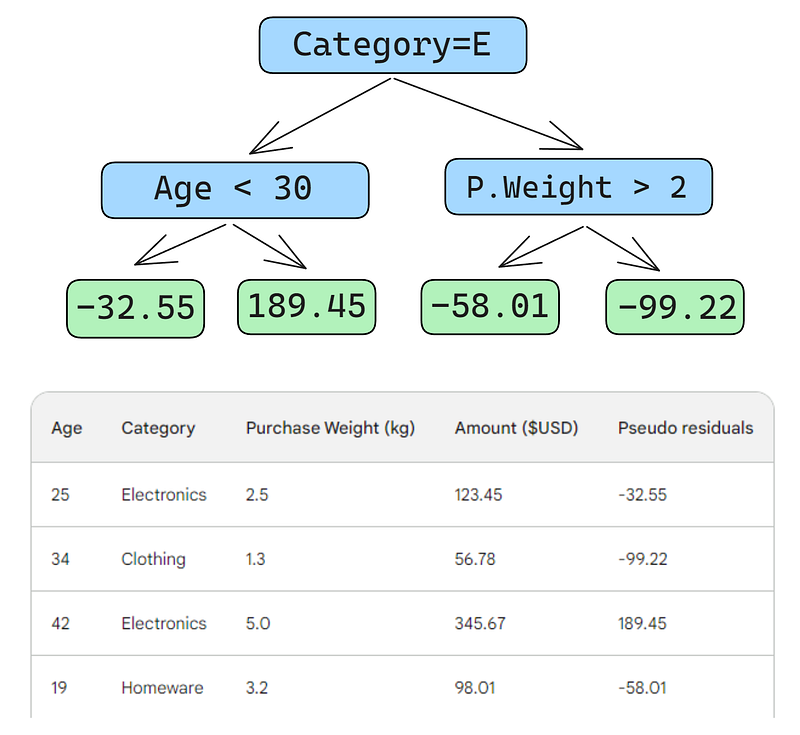
Una vez ajustado el árbol a los datos, hacemos una predicción para cada fila de los datos. He aquí cómo hacer el primero:
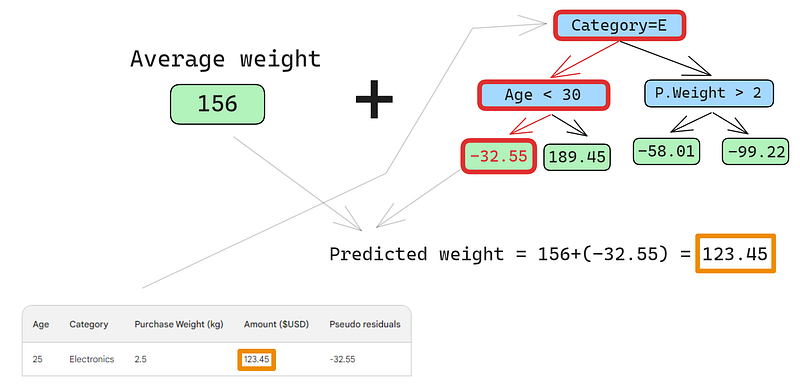
Un pequeño error en las imágenes de abajo: debería haberse escrito "Importe de compra previsto", no "Peso previsto"
La primera fila tiene las siguientes características: una categoría de electrónica (a la izquierda del nodo raíz) y una edad del cliente inferior a 30 años (a la izquierda del nodo hijo). Esto coloca -32,55 en el nodo hoja. Para hacer la predicción final, añadimos -32,55 a nuestra primera predicción, que es exactamente igual al valor observado: ¡123,45 dólares!
Acabamos de hacer una predicción perfecta, así que ¿para qué molestarse en construir otros árboles? Pues bien, ahora mismo, estamos sobreajustando mucho los datos de entrenamiento. Queremos que el modelo generalice. Así que, para mitigar este problema, el refuerzo de gradiente tiene un parámetro llamado tasa de aprendizaje.
La tasa de aprendizaje en el refuerzo de gradiente es simplemente un multiplicador entre 0 y 1 que escala la predicción de cada aprendiz débil (para más detalles sobre la tasa de aprendizaje, consulta la sección siguiente). Si añadimos una tasa de aprendizaje arbitraria de 0,1 a la mezcla, nuestra predicción pasa a ser 152,75, no la perfecta 123,45.

Vamos a predecir también en la segunda fila:
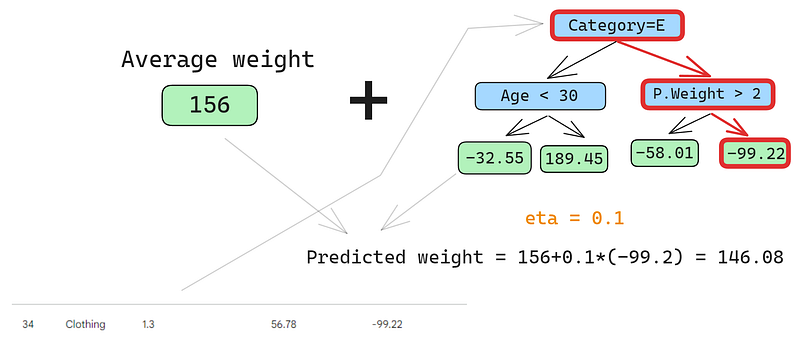
Pasamos la fila por el árbol y obtenemos 146,08 como predicción. Seguimos así para todas las filas hasta que tengamos cuatro predicciones para cuatro filas: 152.75, 146.08, 174.945, 150.2. De momento, añadámoslos como una nueva columna:
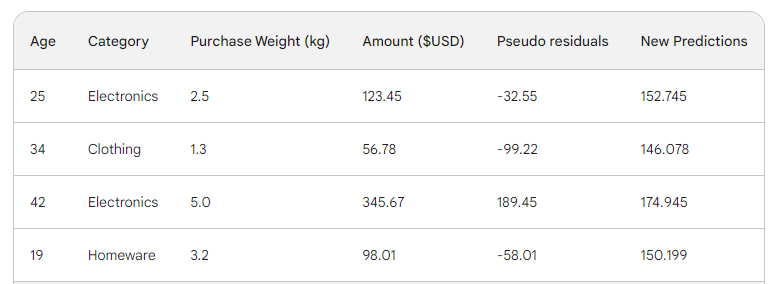
A continuación, hallamos los nuevos pseudorresiduos restando las nuevas predicciones del importe de la compra. Añadámoslas como una nueva columna a la tabla y eliminemos las dos últimas:
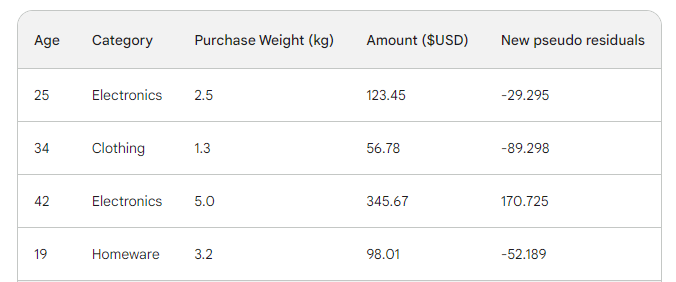
Como puedes ver, nuestros nuevos pseudoresiduos son más pequeños, lo que significa que nuestra pérdida está bajando.
Paso 4: Iterar
En los pasos siguientes, iteramos sobre el paso 3, es decir, construimos más aprendices débiles. Lo único que hay que recordar es que tenemos que ir añadiendo los residuos de cada árbol a la predicción inicial para generar la siguiente.
Por ejemplo, si construimos 10 árboles y los residuos de cada árbol se denotan como r_i (1 <= i <= 10), la siguiente predicción sería p_10 = 156 + eta * (r_1 + r_2 + ... + r_10) donde p_10 denota la predicción en la décima ronda.
En la práctica, los profesionales suelen empezar con 100 árboles, no sólo con 10. En este caso, se dice que el algoritmo se entrena durante 100 rondas de refuerzo.
Si no sabes el número exacto de árboles que necesitas para tu problema concreto, puedes utilizar una técnica sencilla llamada parada anticipada.
En la primera parada, elegimos un gran número de árboles, como 1000 ó 10000. Entonces, en lugar de esperar a que el algoritmo termine de construir todos esos árboles, controlamos la pérdida. Si la pérdida no mejora durante un cierto número de rondas de refuerzo, por ejemplo 50, dejamos de entrenar antes, ahorrando tiempo y recursos de cálculo.
Configuración de los modelos de refuerzo de gradiente
En el aprendizaje automático, elegir los ajustes de un modelo se conoce como "ajuste de hiperparámetros". Estos ajustes, llamados "hiperparámetros", son opciones que el ingeniero de aprendizaje automático debe elegir por sí mismo. A diferencia de otros parámetros, el modelo no puede aprender los mejores valores para los hiperparámetros simplemente entrenándose con los datos.
Los modelos de refuerzo de gradiente tienen muchos hiperparámetros, algunos de los cuales describiré a continuación.
Objetivo
Este parámetro establece la dirección y la función de pérdida del algoritmo. Si el objetivo es la regresión, se elige el MSE como función de pérdida, mientras que para la clasificación se opta por la Entropía Cruzada. Las bibliotecas de Python como XGBoost ofrecen otros objetivos para otros tipos de tareas, como la clasificación con las correspondientes funciones de pérdida.
Tasa de aprendizaje
El hiperparámetro más importante del refuerzo de gradiente es quizá la tasa de aprendizaje. Controla la contribución de cada aprendiz débil ajustando el factor de contracción. Los valores más pequeños (hacia 0) disminuyen el peso de cada aprendiz débil en el conjunto. Esto requiere construir más árboles y, por tanto, más tiempo para terminar el entrenamiento. Pero, el aprendiz fuerte final será realmente fuerte e impermeable al sobreajuste.
El número de árboles
Este parámetro, también llamado número de rondas de refuerzo o n_es timators, controla el número de árboles a construir. Cuantos más árboles construyas, más fuerte y eficaz será el conjunto. También se vuelve más complejo a medida que más árboles permiten al modelo captar más patrones en los datos. Sin embargo, un mayor número de árboles aumenta significativamente las posibilidades de sobreajuste. Para mitigarlo, emplea una combinación de parada temprana y baja tasa de aprendizaje.
Profundidad máxima
Este parámetro controla el número de niveles de cada aprendiz débil (árbol de decisión). Una profundidad máxima de 3 significa que hay tres niveles en el árbol, contando el nivel de hoja. Cuanto más profundo sea el árbol, más complejo y costoso computacionalmente será el modelo. Elige un valor próximo a 3 para evitar el sobreajuste. Tu máximo debe ser una profundidad de 10.
Número mínimo de muestras por hoja
Este parámetro controla cómo se dividen las ramas en los árboles de decisión. Establecer un valor bajo para el número de muestras en los nodos de terminación (hojas) hace que el algoritmo global sea sensible al ruido. Un mayor número mínimo de muestras ayuda a evitar el sobreajuste, al dificultar que los árboles creen divisiones basadas en muy pocos puntos de datos.
Frecuencia de submuestreo
Este parámetro controla la proporción de los datos utilizados para entrenar cada árbol. En los ejemplos anteriores, utilizamos el 100% de las filas, ya que sólo había cuatro filas en nuestro conjunto de datos. Pero los conjuntos de datos del mundo real suelen tener mucho más y requieren un muestreo. Así, si estableces la tasa de submuestreo en un valor inferior a 1, como 0,7, cada aprendiz débil se entrena en el 70% de las filas muestreadas aleatoriamente. Una tasa de submuestra más pequeña puede conducir a un entrenamiento más rápido, pero también a un sobreajuste.
Frecuencia de muestreo de características
Este parámetro es exactamente igual que el submuestreo, pero muestrea filas. Para conjuntos de datos con cientos de características, se recomienda elegir una tasa de muestreo de características entre 0,5 y 1 para reducir la probabilidad de sobreajuste.
El refuerzo de gradiente es el modelo más capaz que tenemos para las tareas de aprendizaje supervisado tabular. Así que, la mayoría de las veces, no tienes que preocuparte de que no sea lo suficientemente bueno para una tarea. Cuando utilizas el refuerzo de gradiente, casi siempre dedicas tu tiempo a cómo regularizarlo, es decir, a domar su potencia para que no se trague tu conjunto de datos y se vuelva inútil cuando se trate de datos no vistos.
Todos los hiperparámetros que he introducido te ayudarán en esta tarea y se incluyen en todas las implementaciones del refuerzo de gradiente en Python. Utilízalos bien.
Impulso por gradiente implementado en Python
Como he mencionado antes, el refuerzo de gradiente está bien establecido a través de las bibliotecas de Python. Éstos son los cuatro principales:
- XGBoosteXtreme Gradient Boosting
- LightGBM: Máquina de refuerzo de gradiente de luz
- CatBoost: Refuerzo categórico
- Scikit-learn: Tiene dos estimadores para regresión y clasificación
Las tres primeras bibliotecas son similares entre sí:
- Actuación dominante
- Compatible con GPU
- Amplio conjunto de hiperparámetros (fácil de configurar)
- Muy alto apoyo comunitario
- Muy utilizado en la industria
Una alternativa popular a estas tres bibliotecas es Scikit-learn, que tiene la desventaja de ser sólo para CPU. Dado que el refuerzo de gradiente es un algoritmo de cálculo pesado, ejecutarlo en una CPU podría ser inviable para grandes conjuntos de datos (estamos hablando de cientos de miles de filas).
Sin embargo, debemos recordar que Scikit-learn, por sí sola, es más popular que las tres bibliotecas juntas. Aparte de los dos estimadores de refuerzo de gradiente para clasificación y regresión, Scikit-learn ofrece docenas de otros modelos para una miríada de tareas de aprendizaje supervisado y no supervisado.
Además, los modelos de refuerzo de gradiente construidos con Scikit-learn podrían integrarse en su rico ecosistema, como pipelines, estimadores de validación cruzada, procesadores de datos, etc.
Aquí tienes una guía paso a paso sobre cómo hacer la clasificación con GradientBoostingClassifier. Predeciremos la calidad de talla de los diamantes basándonos en su precio y otras medidas físicas. Este conjunto de datos está integrado en la biblioteca Seaborn.
Consejo profesional: Utiliza el botón "Explicar código" del editor de fragmentos de código de DataCamp para obtener una explicación detallada línea por línea de lo que ocurre.
1. Bibliotecas de importación
import pandas as pd
import seaborn as sns
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import cross_val_score, train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler2. Datos de carga
# Load the diamonds dataset from Seaborn
diamonds = sns.load_dataset("diamonds")
# Split data into features and target
X = diamonds.drop("cut", axis=1)
y = diamonds["cut"]3. Divide los datos
# Split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)4. Definir rasgos categóricos y numéricos
# Define categorical and numerical features
categorical_features = X.select_dtypes(
include=["object"]
).columns.tolist()
numerical_features = X.select_dtypes(
include=["float64", "int64"]
).columns.tolist()5. Definir pasos de preprocesamiento para características categóricas y numéricas
preprocessor = ColumnTransformer(
transformers=[
("cat", OneHotEncoder(), categorical_features),
("num", StandardScaler(), numerical_features),
]
)6. Crear una canalización de Clasificador de Aumento Gradiente
pipeline = Pipeline(
[
("preprocessor", preprocessor),
("classifier", GradientBoostingClassifier(random_state=42)),
]
)
7. CV y formación
# Perform 5-fold cross-validation
cv_scores = cross_val_score(pipeline, X_train, y_train, cv=5)
# Fit the model on the training data
pipeline.fit(X_train, y_train)
# Predict on the test set
y_pred = pipeline.predict(X_test)
# Generate classification report
report = classification_report(y_test, y_pred)
8. Informar de los resultados finales
print(f"Mean Cross-Validation Accuracy: {cv_scores.mean():.4f}")
print("\nClassification Report:")
print(report)
Mean Cross-Validation Accuracy: 0.7621
Classification Report:
precision recall f1-score support
Fair 0.90 0.91 0.91 335
Good 0.81 0.63 0.71 1004
Ideal 0.82 0.91 0.86 4292
Premium 0.70 0.86 0.77 2775
Very Good 0.66 0.41 0.51 2382
accuracy 0.76 10788
macro avg 0.78 0.74 0.75 10788
weighted avg 0.75 0.76 0.75 10788
La precisión ponderada es del 75%, lo que no está mal para un modelo de referencia con parámetros por defecto. Así que, como reto, te dejo que afines los hiperparámetros de GradientBoostingClassifier para conseguir un rendimiento superior al 95%. Sí, ¡es posible! (Sugerencia: lee atentamente la última sección y consulta la documentación de Scikit-learn sobre el clasificador).
Conclusión y aprendizaje posterior
Aunque hemos aprendido mucho, el artículo se centraba principalmente en el funcionamiento interno del algoritmo de refuerzo de gradiente. Entender cómo funciona no se traduce en ser capaz de utilizarlo bien en la práctica. Sin embargo, la comprensión intuitiva siempre es de gran ayuda.
Para aprender más, te recomiendo los siguientes recursos:
- Utilización del Gradient Boosting con XGBoost por DataCamp: #Artículo nº 1 sobre XGBoost en Google
- Curso Extreme Gradient Boosting con XGBoost: Un curso completo sobre XGBoost
¡Gracias por leer!



