Phần nội dung của bài viết này dài nhưng chi tiết, nên chúng ta sẽ rút gọn phần mở đầu hết mức có thể, đi thẳng vào câu hỏi: “Tại sao phải quan tâm đến gradient boosting?”
Có nhiều lý do thuyết phục:
- Gradient boosting là tốt nhất: độ chính xác và hiệu năng của nó không đối thủ cho các bài toán học có giám sát trên dữ liệu dạng bảng.
- Gradient boosting rất linh hoạt: có thể dùng cho nhiều tác vụ quan trọng như hồi quy, phân loại, xếp hạng và phân tích sống sót.
- Gradient boosting có thể diễn giải: khác với các thuật toán hộp đen như mạng nơ-ron, gradient boosting không đánh đổi khả năng diễn giải để lấy hiệu năng. Nó vận hành “chuẩn đồng hồ Thụy Sĩ” và với sự kiên nhẫn, bạn có thể giải thích cách nó hoạt động cho cả học sinh.
- Gradient boosting được hiện thực hóa tốt: không phải kiểu thuật toán giá trị thực tiễn thấp. Nhiều thư viện gradient boosting như XGBoost và LightGBM trong Python được hàng trăm nghìn người dùng.
- Gradient boosting đem lại chiến thắng: từ năm 2015, các chuyên gia đã dùng nó để liên tục thắng các cuộc thi dữ liệu dạng bảng trên các nền tảng như Kaggle.
Nếu bất kỳ điểm nào ở trên nghe có vẻ hấp dẫn, thì rất đáng để bạn tiếp tục đọc bài viết này.
Vậy, bắt đầu thôi!
Bạn sẽ học gì trong hướng dẫn này?
Điều quan trọng nhất bạn nhận được từ bài viết là nắm rất vững cơ chế bên trong của gradient boosting mà không phải đau đầu nhiều vì toán học. Rốt cuộc, gradient boosting là để dùng trong thực tế chứ không phải để phân tích thuần túy về mặt toán.
Gradient Boosting nói chung là gì?
Boosting là một kỹ thuật tổ hợp mạnh mẽ trong học máy. Khác với các mô hình truyền thống học độc lập từ dữ liệu, boosting kết hợp dự đoán của nhiều bộ học yếu để tạo thành một bộ học mạnh chính xác hơn.
Tôi vừa đưa ra một loạt thuật ngữ mới, nên hãy giải thích từng cái, bắt đầu với bộ học yếu.
Bộ học yếu là một mô hình học máy chỉ tốt hơn một chút so với đoán ngẫu nhiên. Ví dụ, giả sử ta phân loại nấm ăn được và không ăn được. Nếu mô hình đoán ngẫu nhiên đạt 40% chính xác, thì bộ học yếu sẽ nhỉnh hơn một chút: 50–60%.
Boosting kết hợp hàng chục hoặc hàng trăm bộ học yếu như vậy để xây dựng một bộ học mạnh, có thể đạt trên 95% chính xác cho cùng bài toán.
Bộ học yếu phổ biến nhất là cây quyết định, được chọn vì khả năng làm việc với hầu như mọi bộ dữ liệu. Nếu bạn chưa quen với cây quyết định, hãy xem hướng dẫn Phân loại bằng Cây quyết định của DataCamp.
Ứng dụng thực tế của Gradient Boosting
Gradient boosting đã trở thành một lực lượng thống trị trong học máy, nên ứng dụng của nó trải rộng nhiều ngành, từ dự đoán rời bỏ khách hàng đến phát hiện tiểu hành tinh. Dưới đây là vài câu chuyện thành công trên Kaggle và trường hợp sử dụng thực tế:
Thống trị các cuộc thi Kaggle:
- Otto Group Product Classification Challenge: cả top 10 đều dùng XGBoost, một hiện thực của gradient boosting.
- Santander Customer Transaction Prediction: các lời giải dựa trên XGBoost lại tiếp tục chiếm vị trí dẫn đầu trong dự đoán hành vi khách hàng và giao dịch tài chính.
- Netflix Movie Recommendation Challenge: Gradient boosting đóng vai trò then chốt trong việc xây dựng hệ thống gợi ý cho các công ty tỷ đô như Netflix.
Chuyển đổi kinh doanh và công nghiệp:
- Bán lẻ và thương mại điện tử: gợi ý cá nhân hóa, quản lý tồn kho, phát hiện gian lận
- Tài chính và bảo hiểm: đánh giá rủi ro tín dụng, dự đoán rời bỏ, giao dịch thuật toán
- Y tế và dược: chẩn đoán bệnh, khám phá thuốc, y học cá thể hóa
- Tìm kiếm và quảng cáo trực tuyến: xếp hạng tìm kiếm, nhắm mục tiêu quảng cáo, dự đoán tỷ lệ nhấp
Giờ thì hãy cùng “nhìn dưới nắp capo” của thuật toán huyền thoại này!
Thuật toán Gradient Boosting: Hướng dẫn từng bước
Dữ liệu đầu vào
Thuật toán gradient boosting hoạt động với dữ liệu bảng gồm một tập đặc trưng (X) và mục tiêu (y). Giống các thuật toán học máy khác, mục tiêu là học đủ từ dữ liệu huấn luyện để tổng quát hóa tốt cho các điểm dữ liệu chưa thấy.
Để hiểu quy trình bên dưới của gradient boosting, ta sẽ dùng một bộ dữ liệu bán hàng đơn giản với bốn dòng. Với ba đặc trưng — tuổi khách hàng, danh mục mua, và trọng lượng mua — ta muốn dự đoán số tiền mua:
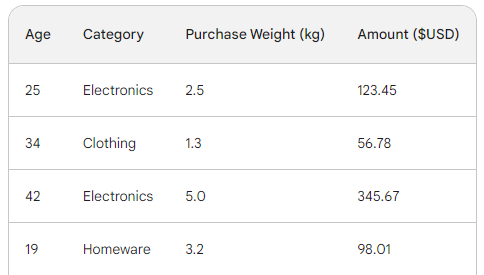
Hàm mất mát trong gradient boosting
Trong học máy, một hàm mất mát là thành phần then chốt giúp định lượng chênh lệch giữa dự đoán của mô hình và giá trị thực. Về bản chất, nó đo lường mức độ mô hình đang thể hiện.
Vai trò của nó gồm:
- Tính toán sai số: Lấy đầu ra dự đoán của mô hình và so sánh với sự thật nền (giá trị quan sát thực). Cách so sánh, tức cách tính chênh lệch, khác nhau tùy hàm.
- Hướng dẫn quá trình huấn luyện: mục tiêu của mô hình là tối thiểu hóa hàm mất mát. Xuyên suốt quá trình học, mô hình liên tục cập nhật cấu trúc và cấu hình bên trong để làm mất mát nhỏ nhất có thể.
- Chỉ số đánh giá: So sánh mất mát trên tập huấn luyện, kiểm định và kiểm tra giúp bạn đánh giá khả năng tổng quát hóa và tránh quá khớp của mô hình.
Hai hàm mất mát phổ biến nhất là:
- Lỗi bình phương trung bình (MSE): Hàm mất mát nổi tiếng cho hồi quy, đo tổng bình phương chênh lệch giữa giá trị dự đoán và thực tế. Gradient boosting thường dùng biến thể sau:
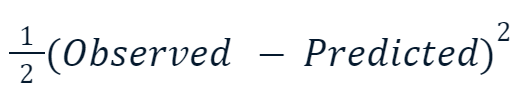
Lý do nhân thêm một nửa vào bình phương liên quan đến phép vi phân. Khi lấy đạo hàm của hàm mất mát này, hệ số một nửa triệt tiêu với số mũ hai theo quy tắc lũy thừa. Kết quả cuối cùng sẽ chỉ là -(Observed - Predicted), giúp việc tính toán đơn giản hơn và ít tốn kém hơn.
- Cross-entropy: Hàm này đo khác biệt giữa hai phân phối xác suất. Vì vậy, thường dùng cho tác vụ phân loại nơi mục tiêu là các hạng mục rời rạc.
Vì chúng ta đang làm hồi quy, ta sẽ dùng MSE.
Bước 1: Tạo dự đoán ban đầu
Gradient boosting là một thuật toán tăng dần độ chính xác. Để bắt đầu, ta cần một phỏng đoán ban đầu. Phỏng đoán ban đầu luôn là giá trị trung bình của mục tiêu. Nói cách khác, ở vòng đầu tiên, mô hình dự đoán mọi lần mua đều như nhau — 156 đô la:
![]()
Lý do chọn trung bình liên quan đến hàm mất mát và đạo hàm của nó. Ở mỗi bước, ta tìm một giá trị để cực tiểu hóa hàm mất mát. Tức là tìm giá trị làm đạo hàm (gradient) của hàm mất mát bằng 0.
Và khi lấy đạo hàm của hàm mất mát theo từng giá trị quan sát đối với giá trị dự đoán rồi cộng lại, ta nhận được trung bình của mục tiêu.
Vậy nên, dự đoán ban đầu là trung bình — 156 đô la. Hãy ghi nhớ con số này khi tiếp tục.
Bước 2: Tính các giả dư (pseudo-residual)
Bước tiếp theo là tìm chênh lệch giữa từng giá trị quan sát và dự đoán ban đầu: 156 - Observed. Để minh họa, ta sẽ đặt các chênh lệch đó vào một cột mới:
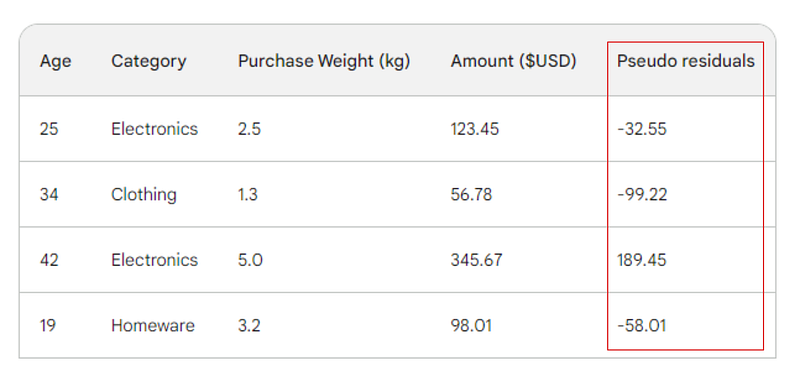
Hãy nhớ rằng trong hồi quy tuyến tính, chênh lệch giữa giá trị quan sát và dự đoán gọi là phần dư (residual). Để phân biệt với hồi quy tuyến tính, trong gradient boosting ta gọi chúng là giả dư (pseudo-residual) (còn những lý do khác cho tên gọi này, nhưng bài viết sẽ không bàn tới).
Bước 3: Xây dựng một bộ học yếu
Tiếp theo, ta xây dựng một cây quyết định (bộ học yếu) để dự đoán các giả dư dựa trên ba đặc trưng (tuổi, danh mục, trọng lượng mua). Với bài toán này, ta giới hạn cây ở bốn lá (nút tận), nhưng trong thực tế, người ta thường chọn từ 8 đến 32 lá.
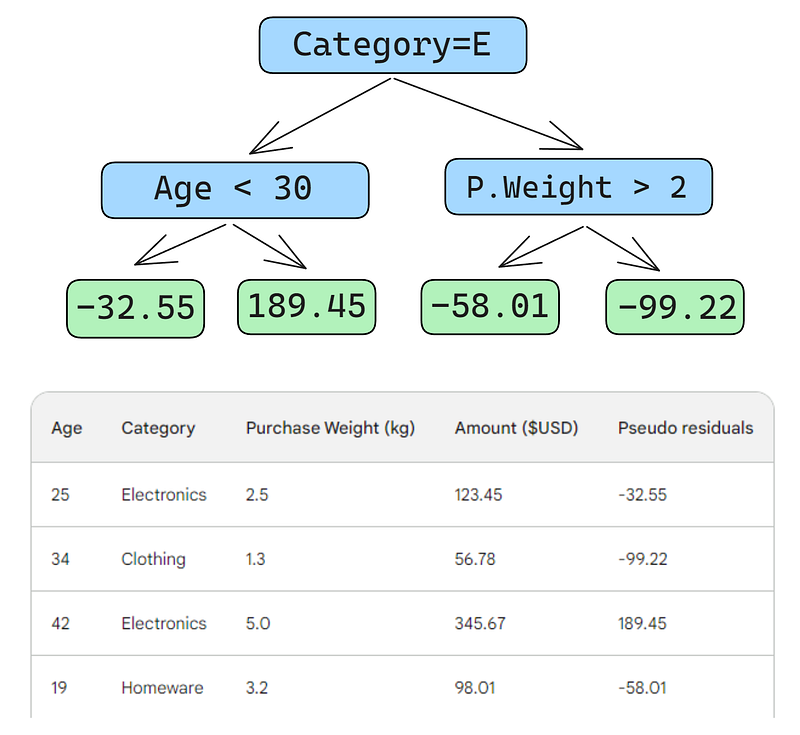
Sau khi cây được fit vào dữ liệu, ta tạo dự đoán cho từng dòng. Đây là cách làm cho dòng đầu tiên:
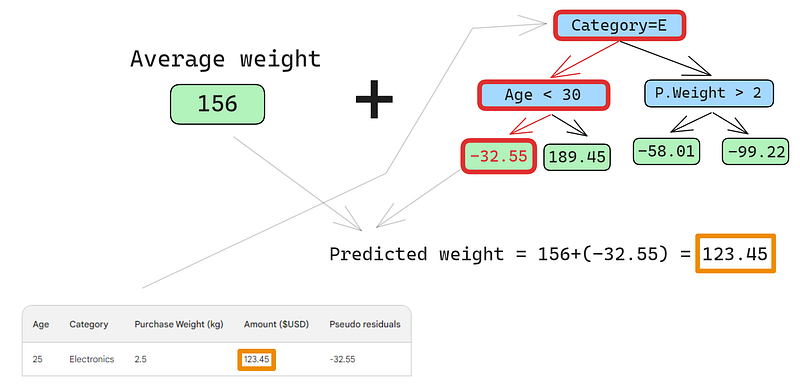
Một lỗi nhỏ trong các hình dưới: lẽ ra phải ghi “Số tiền mua dự đoán”, không phải “Trọng lượng dự đoán”
Dòng đầu tiên có các đặc trưng: danh mục điện tử (nhánh trái của nút gốc) và tuổi khách hàng dưới 30 (nhánh trái của nút con). Điều này đưa -32.55 vào nút lá. Để ra dự đoán cuối, ta cộng -32.55 với dự đoán đầu tiên, vốn trùng khớp với giá trị quan sát — 123.45 đô la!
Chúng ta vừa dự đoán hoàn hảo, vậy tại sao còn xây thêm cây khác? Bởi lúc này ta đang quá khớp nghiêm trọng với dữ liệu huấn luyện. Ta muốn mô hình tổng quát hóa. Để giảm vấn đề này, gradient boosting có một tham số gọi là tốc độ học (learning rate).
Tốc độ học trong gradient boosting đơn giản là một hệ số nhân từ 0 đến 1 để co hẹp dự đoán của mỗi bộ học yếu (xem phần dưới để biết chi tiết). Khi thêm tốc độ học tùy ý là 0.1, dự đoán của ta trở thành 152.75, không còn hoàn hảo 123.45 nữa.

Hãy dự đoán cho dòng thứ hai nữa:
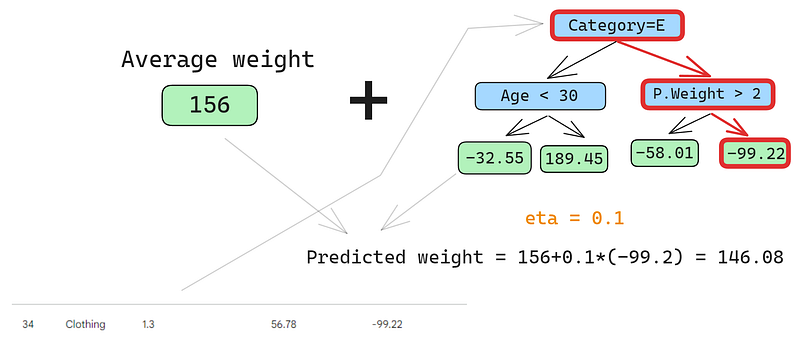
Ta đưa dòng này qua cây và nhận dự đoán 146.08. Tiếp tục như vậy cho tất cả các dòng đến khi có bốn dự đoán cho bốn dòng: 152.75, 146.08, 174.945, 150.2. Tạm thời thêm chúng vào một cột mới:
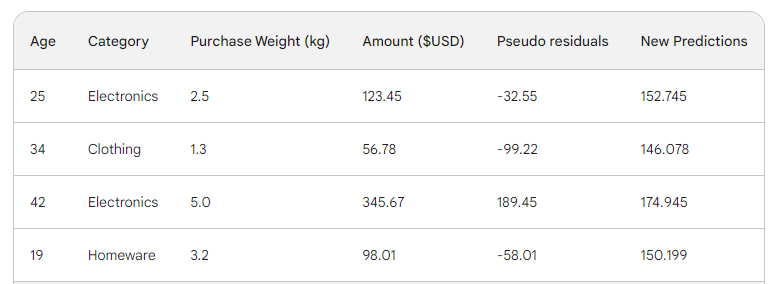
Tiếp đó, ta tìm các giả dư mới bằng cách lấy số tiền mua trừ đi dự đoán mới. Thêm chúng vào một cột mới và bỏ hai cột cuối:
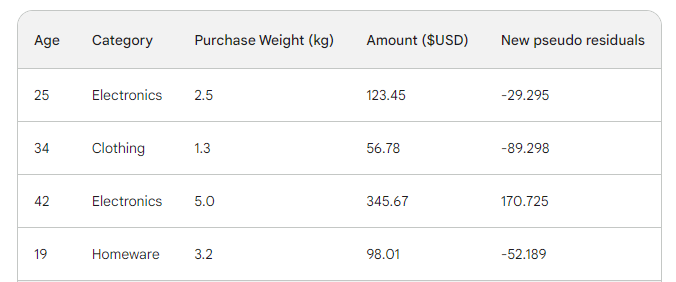
Như bạn thấy, các giả dư mới nhỏ hơn, nghĩa là mất mát đang giảm.
Bước 4: Lặp lại
Ở các bước tiếp theo, ta lặp lại bước 3, tức xây thêm các bộ học yếu. Điều duy nhất cần nhớ là phải tiếp tục cộng các giả dư của mỗi cây vào dự đoán ban đầu để tạo dự đoán kế tiếp.
Ví dụ, nếu xây 10 cây và giả dư của mỗi cây ký hiệu là r_i (1 <= i <= 10), dự đoán kế tiếp sẽ là p_10 = 156 + eta * (r_1 + r_2 + ... + r_10) trong đó p_10 là dự đoán ở vòng thứ mười.
Trong thực tế, các chuyên gia thường bắt đầu với 100 cây, không chỉ 10. Khi đó, nói rằng thuật toán huấn luyện trong 100 vòng boosting.
Nếu bạn không biết chính xác cần bao nhiêu cây cho vấn đề cụ thể, bạn có thể dùng kỹ thuật dừng sớm.
Với dừng sớm, ta chọn một số lượng cây lớn, như 1000 hoặc 10000. Sau đó, thay vì chờ thuật toán xây xong tất cả, ta theo dõi mất mát. Nếu mất mát không cải thiện trong một số vòng boosting nhất định, ví dụ 50, ta dừng huấn luyện sớm hơn, tiết kiệm thời gian và tài nguyên tính toán.
Cấu hình các mô hình Gradient Boosting
Trong học máy, việc chọn thiết lập cho mô hình gọi là “tinh chỉnh siêu tham số”. Những thiết lập này, gọi là “siêu tham số”, là các tùy chọn mà kỹ sư học máy phải tự chọn. Khác với các tham số khác, mô hình không thể tự học giá trị tốt nhất cho siêu tham số chỉ bằng huấn luyện trên dữ liệu.
Các mô hình gradient boosting có nhiều siêu tham số, một số sẽ được nêu dưới đây.
Mục tiêu (Objective)
Tham số này xác định hướng và hàm mất mát của thuật toán. Nếu mục tiêu là hồi quy, MSE được chọn làm hàm mất mát; còn với phân loại, Cross-Entropy là lựa chọn phù hợp. Các thư viện Python như XGBoost cung cấp các mục tiêu khác cho các tác vụ khác, như xếp hạng với các hàm mất mát tương ứng.
Tốc độ học (Learning rate)
Có lẽ siêu tham số quan trọng nhất của gradient boosting là tốc độ học. Nó kiểm soát mức đóng góp của mỗi bộ học yếu bằng cách điều chỉnh hệ số co. Giá trị nhỏ (tiệm cận 0) làm giảm “tiếng nói” của từng bộ học yếu trong tổ hợp. Điều này đòi hỏi xây nhiều cây hơn và do đó thời gian huấn luyện lâu hơn. Nhưng bộ học mạnh cuối cùng sẽ thực sự mạnh và khó bị quá khớp.
Số lượng cây
Tham số này, còn gọi là số vòng boosting hoặc n_es timators, kiểm soát số cây được xây. Càng nhiều cây, tổ hợp càng mạnh và hiệu quả hơn. Nó cũng trở nên phức tạp hơn vì nhiều cây cho phép mô hình nắm bắt nhiều mẫu hơn trong dữ liệu. Tuy nhiên, nhiều cây cũng làm tăng đáng kể nguy cơ quá khớp. Để giảm thiểu, hãy kết hợp dừng sớm và tốc độ học thấp.
Độ sâu tối đa
Tham số này kiểm soát số tầng trong mỗi bộ học yếu (cây quyết định). Độ sâu tối đa là 3 nghĩa là có ba tầng trong cây, tính cả tầng lá. Cây càng sâu, mô hình càng phức tạp và tốn kém tính toán. Hãy chọn giá trị gần 3 để ngăn quá khớp. Độ sâu tối đa khuyến nghị không vượt quá 10.
Số mẫu tối thiểu mỗi lá
Tham số này kiểm soát cách các nhánh tách trong cây quyết định. Đặt giá trị thấp cho số mẫu ở nút tận (lá) khiến thuật toán nhạy cảm với nhiễu. Số mẫu tối thiểu lớn hơn giúp ngăn quá khớp bằng cách khiến cây khó tạo các phép tách dựa trên quá ít điểm dữ liệu.
Tỷ lệ lấy mẫu hàng
Tham số này kiểm soát tỷ lệ dữ liệu dùng để huấn luyện mỗi cây. Ở ví dụ trên, ta dùng 100% số dòng vì chỉ có bốn dòng. Nhưng trong thực tế, bộ dữ liệu thường lớn hơn nhiều và cần lấy mẫu. Vì vậy, nếu đặt tỷ lệ lấy mẫu dưới 1, như 0.7, mỗi bộ học yếu sẽ huấn luyện trên 70% số dòng được lấy ngẫu nhiên. Tỷ lệ lấy mẫu nhỏ hơn có thể giúp huấn luyện nhanh hơn nhưng cũng có thể dẫn đến quá khớp.
Tỷ lệ lấy mẫu đặc trưng
Tham số này tương tự như lấy mẫu, nhưng là lấy theo cột đặc trưng. Với các bộ dữ liệu có hàng trăm đặc trưng, nên chọn tỷ lệ lấy mẫu đặc trưng trong khoảng 0.5 đến 1 để giảm khả năng quá khớp.
Gradient boosting là mô hình mạnh mẽ nhất chúng ta có cho các bài toán học có giám sát trên dữ liệu bảng. Vì vậy, hầu hết thời gian bạn không cần lo nó không đủ tốt cho tác vụ. Khi dùng gradient boosting, thời gian của bạn gần như luôn dành cho việc quy chuẩn hóa (regularize) — “thuần hóa” sức mạnh của nó để nó không nuốt trọn bộ dữ liệu và trở nên vô dụng với dữ liệu chưa thấy.
Các siêu tham số tôi đã giới thiệu đều giúp bạn trong nhiệm vụ này và có mặt trong mọi hiện thực gradient boosting bằng Python. Hãy dùng chúng một cách khôn ngoan.
Gradient Boosting trong Python
Như đã đề cập, gradient boosting được hỗ trợ tốt qua các thư viện Python. Bốn cái tên chính là:
- XGBoost: eXtreme Gradient Boosting
- LightGBM: Light Gradient Boosting Machine
- CatBoost: Categorical Boosting
- Scikit-learn: Có hai bộ ước lượng cho hồi quy và phân loại
Ba thư viện đầu khá giống nhau:
- Hiệu năng vượt trội
- Hỗ trợ GPU
- Bộ siêu tham số phong phú (dễ cấu hình)
- Cộng đồng hỗ trợ rất mạnh
- Được dùng rộng rãi trong công nghiệp
Một lựa chọn phổ biến thay thế ba thư viện trên là Scikit-learn, nhưng bất lợi là chỉ hỗ trợ CPU. Vì gradient boosting đòi hỏi tính toán nặng, chạy trên CPU có thể không khả thi với các bộ dữ liệu lớn (hàng trăm nghìn dòng).
Tuy nhiên, cũng cần nhớ rằng bản thân Scikit-learn còn phổ biến hơn cả ba thư viện kia cộng lại. Ngoài hai bộ ước lượng gradient boosting cho phân loại và hồi quy, Scikit-learn còn cung cấp hàng chục mô hình khác cho vô vàn tác vụ học có giám sát và không giám sát.
Ngoài ra, các mô hình gradient boosting xây bằng Scikit-learn có thể tích hợp vào hệ sinh thái phong phú của nó như pipeline, bộ ước lượng cross-validation, bộ xử lý dữ liệu, v.v.
Dưới đây là hướng dẫn từng bước để phân loại với GradientBoostingClassifier. Ta sẽ dự đoán chất lượng cắt của kim cương dựa trên giá và các đo đạc vật lý khác. Bộ dữ liệu này có sẵn trong thư viện Seaborn.
Mẹo hay: Hãy dùng nút “Giải thích mã” của trình biên tập snippet mã trên DataCamp để nhận giải thích chi tiết từng dòng.
1. Import thư viện
import pandas as pd
import seaborn as sns
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import cross_val_score, train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler2. Tải dữ liệu
# Load the diamonds dataset from Seaborn
diamonds = sns.load_dataset("diamonds")
# Split data into features and target
X = diamonds.drop("cut", axis=1)
y = diamonds["cut"]3. Chia dữ liệu
# Split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)4. Xác định các đặc trưng phân loại và số
# Define categorical and numerical features
categorical_features = X.select_dtypes(
include=["object"]
).columns.tolist()
numerical_features = X.select_dtypes(
include=["float64", "int64"]
).columns.tolist()5. Định nghĩa các bước tiền xử lý cho đặc trưng phân loại và số
preprocessor = ColumnTransformer(
transformers=[
("cat", OneHotEncoder(), categorical_features),
("num", StandardScaler(), numerical_features),
]
)6. Tạo pipeline cho Gradient Boosting Classifier
pipeline = Pipeline(
[
("preprocessor", preprocessor),
("classifier", GradientBoostingClassifier(random_state=42)),
]
)
7. Cross-validation và huấn luyện
# Perform 5-fold cross-validation
cv_scores = cross_val_score(pipeline, X_train, y_train, cv=5)
# Fit the model on the training data
pipeline.fit(X_train, y_train)
# Predict on the test set
y_pred = pipeline.predict(X_test)
# Generate classification report
report = classification_report(y_test, y_pred)
8. Báo cáo kết quả cuối cùng
print(f"Mean Cross-Validation Accuracy: {cv_scores.mean():.4f}")
print("\nClassification Report:")
print(report)
Mean Cross-Validation Accuracy: 0.7621
Classification Report:
precision recall f1-score support
Fair 0.90 0.91 0.91 335
Good 0.81 0.63 0.71 1004
Ideal 0.82 0.91 0.86 4292
Premium 0.70 0.86 0.77 2775
Very Good 0.66 0.41 0.51 2382
accuracy 0.76 10788
macro avg 0.78 0.74 0.75 10788
weighted avg 0.75 0.76 0.75 10788
Độ chính xác có trọng số là 75%, không tệ cho một mô hình cơ sở với tham số mặc định. Vậy nên, như một thử thách, tôi để bạn tinh chỉnh các siêu tham số của GradientBoostingClassifier để đạt hiệu năng trên 95%. Vâng, hoàn toàn có thể! (Gợi ý: đọc kỹ phần cuối và xem thêm tài liệu Scikit-learn cho bộ phân loại).
Kết luận và học thêm
Dù chúng ta đã học được rất nhiều, trọng tâm chính của bài là cơ chế bên trong của thuật toán gradient boosting. Hiểu cách nó hoạt động không tự động đồng nghĩa với việc dùng tốt trong thực tế. Tuy nhiên, trực giác tốt luôn là một trợ giúp lớn.
Để học thêm, tôi gợi ý các tài nguyên sau:
- Sử dụng Gradient Boosting với XGBoost bởi DataCamp: bài viết xếp hạng #1 về XGBoost trên Google
- Khóa học Extreme Gradient Boosting với XGBoost: khóa học toàn diện về XGBoost
Cảm ơn bạn đã đọc!
