Bu makalenin gövdesi uzun ama ayrıntılı, bu yüzden giriş kısmını mümkün olduğunca kısa tutacağız ve doğrudan şu soruyla başlayacağız: “Gradyan artırma ile neden uğraşalım?”
Bunun bir dizi çok iyi nedeni var:
- Gradyan artırma en iyisidir: doğruluğu ve performansı, tablo biçimli denetimli öğrenme görevlerinde eşsizdir.
- Gradyan artırma son derece çok yönlüdür: regresyon, sınıflandırma, sıralama ve sağkalım analizi gibi birçok önemli görevde kullanılabilir.
- Gradyan artırma yorumlanabilirdir: sinir ağları gibi kara kutu algoritmaların aksine, gradyan artırma performans uğruna yorumlanabilirlikten ödün vermez. İsviçre saati gibi çalışır ve sabırla, nasıl çalıştığını bir okul çocuğuna bile öğretebilirsiniz.
- Gradyan artırma iyi uygulanmıştır: pratikte pek değeri olmayan algoritmalardan değildir. Python’daki XGBoost ve LightGBM gibi çeşitli gradyan artırma kütüphaneleri yüz binlerce kişi tarafından kullanılır.
- Gradyan artırma kazandırır: 2015’ten bu yana, profesyoneller Kaggle gibi platformlardaki tablo veri yarışmalarını istikrarlı biçimde bununla kazanıyor.
Bu maddelerden herhangi biri az da olsa ilginizi çektiyse, bu makaleyi okumaya devam etmeye değer.
O hâlde başlayalım!
Bu Eğitimde Neler Öğreneceksiniz?
Bu makalenin en önemli kazanımı, çok fazla matematiksel baş ağrısı yaşamadan gradyan artırmanın iç işleyişini çok sağlam kavramanızdır. Sonuçta, gradyan artırma matematiksel analiz için değil, pratikte kullanılmak içindir.
Genel Olarak Gradyan Artırma Nedir?
Artırma (boosting), makine öğreniminde güçlü bir topluluk (ensemble) tekniğidir. Veriden bağımsız şekilde öğrenen geleneksel modellerin aksine, artırma birden çok zayıf öğrenicinin tahminlerini bir araya getirerek tek, daha doğru bir güçlü öğrenici oluşturur.
Bir dizi yeni terim kullandım; zayıf öğrenicilerden başlayarak her birini açıklayayım.
Zayıf öğrenici, rastgele tahmin eden bir modelden biraz daha iyi olan bir makine öğrenimi modelidir. Örneğin, mantarları yenilebilir ve yenilemez diye sınıflandırdığımızı varsayalım. Eğer rastgele tahmin eden bir modelin doğruluğu %40 ise, bir zayıf öğrenici bunun biraz üzerindedir: %50–60.
Artırma, bu zayıf öğrenicilerden düzinelercesini veya yüzlercesini birleştirerek aynı problemde %95’in üzerinde doğruluk potansiyeli olan bir güçlü öğrenici inşa eder.
En popüler zayıf öğrenici karar ağacıdır; hemen her veri kümesiyle çalışabilme becerisi nedeniyle tercih edilir. Karar ağaçlarına aşina değilseniz, DataCamp’in Karar Ağacı Sınıflandırma eğitimine göz atın.
Gradyan Artırmanın Gerçek Dünya Uygulamaları
Gradyan artırma makine öğreniminde öyle baskın bir güç haline geldi ki, uygulamaları artık müşteri kaybını öngörmekten asteroid tespitine kadar pek çok sektöre yayılıyor. İşte Kaggle’daki başarı öykülerinden ve gerçek dünya kullanım alanlarından bir kesit:
Kaggle yarışmalarında hakimiyet:
- Otto Group Ürün Sınıflandırma Yarışması: ilk 10’un tamamı, gradyan artırmanın XGBoost uygulamasını kullandı.
- Santander Müşteri İşlem Tahmini: XGBoost tabanlı çözümler, müşteri davranışı ve finansal işlemleri tahmin etmede yine üst sıraları aldı.
- Netflix Film Öneri Yarışması: Gradyan artırma, Netflix gibi milyar dolarlık şirketlerin öneri sistemlerinin inşasında kritik rol oynadı.
İş ve endüstriyi dönüştürüyor:
- Perakende ve e-ticaret: kişiselleştirilmiş öneriler, stok yönetimi, sahtekarlık tespiti
- Finans ve sigorta: kredi risk değerlendirmesi, müşteri kaybı tahmini, algoritmik alım satım
- Sağlık ve tıp: hastalık teşhisi, ilaç keşfi, kişiselleştirilmiş tıp
- Arama ve çevrimiçi reklamcılık: arama sıralaması, reklam hedefleme, tıklama oranı tahmini
Şimdi, gelin bu efsanevi algoritmanın kaputunun altına son bir bakış atalım!
Gradyan Artırma Algoritması: Adım Adım Rehber
Girdi
Gradyan artırma algoritması, bir dizi özelliğe (X) ve bir hedefe (y) sahip tablo verilerinde çalışır. Diğer makine öğrenimi algoritmaları gibi, amaç eğitim verilerinden yeterince öğrenerek görülmemiş veri noktalarına iyi genelleme yapmaktır.
Gradyan artırmanın temel sürecini anlamak için dört satırlık basit bir satış veri kümesi kullanacağız. Üç özelliği — müşteri yaşı, satın alma kategorisi ve satın alma ağırlığı — kullanarak satın alma tutarını tahmin etmek istiyoruz:
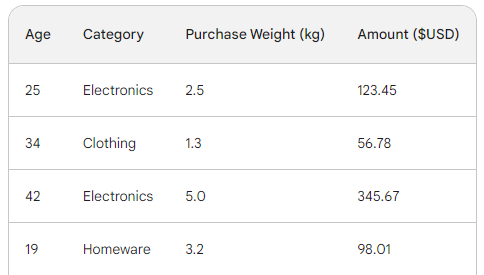
Gradyan artırmada kayıp fonksiyonu
Makine öğreniminde bir kayıp fonksiyonu, bir modelin tahminleriyle gerçek değerler arasındaki farkı nicelleştirmemizi sağlayan kritik bir bileşendir. Özünde, bir modelin nasıl performans gösterdiğini ölçer.
Rolünün bir dökümü şöyle:
- Hata hesaplar: Modelin tahmin edilen çıktısını alır ve gerçeğe (gözlemlenen gerçek değerlere) kıyaslar. Nasıl kıyasladığı, yani farkı nasıl hesapladığı fonksiyona göre değişir.
- Model eğitimine yön verir: bir modelin hedefi kayıp fonksiyonunu en aza indirmektir. Eğitim boyunca model, kaybı olabildiğince küçültmek için iç yapısını ve yapılandırmasını sürekli günceller.
- Değerlendirme metriği: Eğitim, doğrulama ve test veri kümelerindeki kaybı karşılaştırarak modelinizin genelleme yeteneğini ve aşırı uyumdan kaçınma becerisini değerlendirebilirsiniz.
En yaygın iki kayıp fonksiyonu şunlardır:
- Ortalama Kare Hatası (MSE): Regresyon için popüler olan bu kayıp fonksiyonu, tahmin edilen ve gerçek değerler arasındaki kare farkların toplamını ölçer. Gradyan artırma genellikle bunun şu varyasyonunu kullanır:
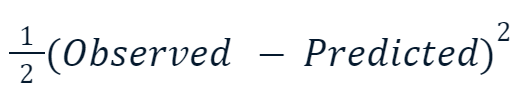
Kareli değerin bir-buçukla çarpılmasının nedeni türevle ilgilidir. Bu kayıp fonksiyonunun türevini aldığımızda, kuvvet kuralı nedeniyle bir-buçuk kareyle sadeleşir. Böylece nihai sonuç sadece -(Gözlenen - Tahmin) olur, bu da matematiği çok daha kolay ve daha az hesaplama maliyetli kılar.
- Çapraz entropi: Bu fonksiyon iki olasılık dağılımı arasındaki farkı ölçer. Bu nedenle, hedeflerin ayrık kategoriler olduğu sınıflandırma görevlerinde yaygın olarak kullanılır.
Biz regresyon yaptığımız için MSE kullanacağız.
Adım 1: İlk tahmini yapın
Gradyan artırma doğruluğunu kademeli olarak artıran bir algoritmadır. Süreci başlatmak için bir başlangıç tahminine ihtiyacımız var. Başlangıç tahmini her zaman hedefin ortalamasıdır. Başka bir deyişle, ilk tur için modelimiz tüm satın almaların aynı olduğunu — 156 dolar — tahmin eder:
![]()
Ortalamanın seçilmesinin nedeni, seçtiğimiz kayıp fonksiyonu ve onun türeviyle ilgilidir. Her adımda kayıp fonksiyonunun minimumunu bulmak için bir değer arıyoruz. Yani, kayıp fonksiyonunun türevini (gradyanını) 0 yapan bir değer arıyoruz.
Ve gözlenen her değer için kayıp fonksiyonunun türevini tahmine göre alıp topladığımızda, hedefin ortalamasıyla karşılaşırız.
Dolayısıyla ilk tahminimiz ortalama — 156 dolar. Devam ederken bunu akılda tutun.
Adım 2: Psödo artıklarını hesaplayın
Bir sonraki adım, her bir gözlenen değer ile ilk tahminimiz arasındaki farkları bulmaktır: 156 - Gözlenen. Gösterim amacıyla bu farkları yeni bir sütunda göstereceğiz:
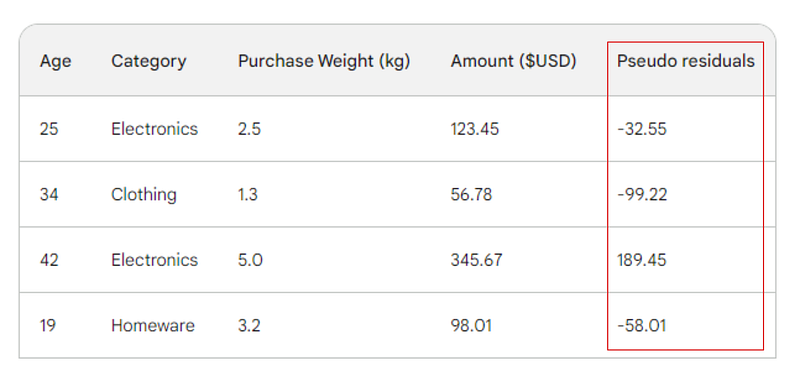
Doğrusal regresyonda, gözlenen değerlerle tahmin edilen değerler arasındaki farka artıklar dendiğini unutmayın. Doğrusal regresyon ile gradyan artırmayı ayırt etmek için bunlara psödo artıklar diyoruz (bu ismin başka nedenleri de var, ancak bu makalede onlara girmeyeceğiz).
Adım 3: Bir zayıf öğrenici oluşturun
Şimdi, elimizdeki üç özelliği (yaş, kategori, satın alma ağırlığı) kullanarak artıkları tahmin eden bir karar ağacı (zayıf öğrenici) kuracağız. Bu problem için karar ağacını yalnızca dört yaprakla (terminal düğüm) sınırlayacağız, ancak pratikte genellikle 8 ile 32 arasında yaprak seçilir.
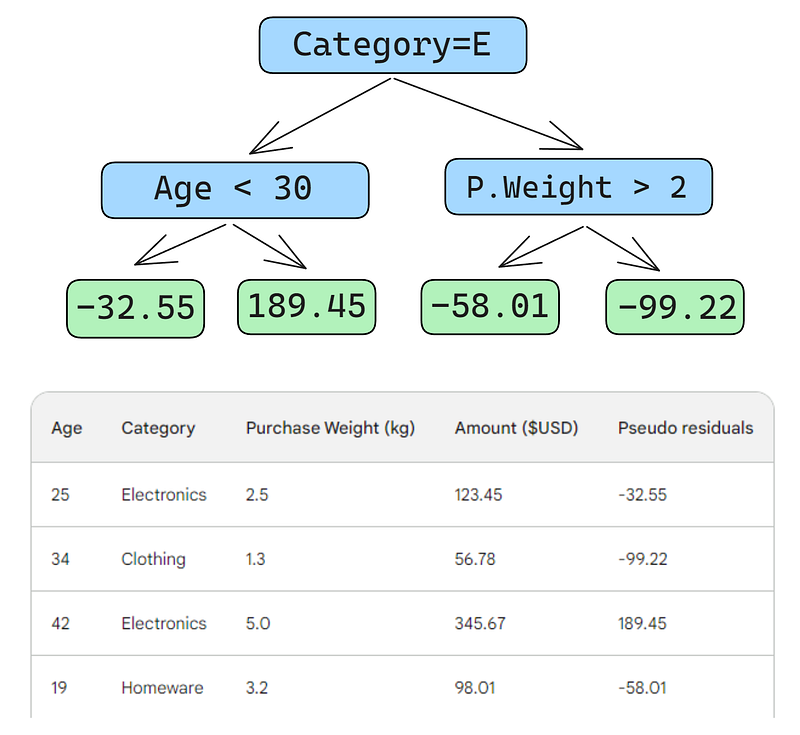
Ağaç veriye uydurulduktan sonra, verideki her satır için bir tahmin yaparız. İlk satırı şöyle yaparız:
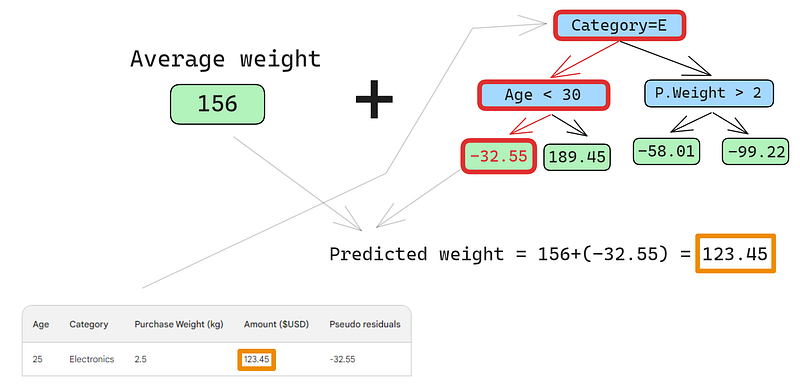
Aşağıdaki görsellerde küçük bir hata var: “Tahmin edilen ağırlık” değil, “Tahmin edilen satın alma tutarı” yazmalıydı
İlk satırın şu özellikleri var: elektronik kategorisi (kök düğümün solu) ve müşteri yaşı 30’un altında (alt düğümün solu). Bu, yaprak düğümüne -32.55 koyar. Nihai tahmini yapmak için -32.55’i ilk tahminimize ekleriz ve bu, gözlenen değerle birebir aynı olur — 123.45 dolar!
Az önce kusursuz bir tahmin yaptık; o zaman neden başka ağaçlar inşa etmekle uğraşalım? Şu anda eğitimi veriye aşırı uydurmuş durumdayız. Modelin genelleme yapmasını istiyoruz. Bu sorunu hafifletmek için gradyan artırmanın öğrenme oranı adlı bir parametresi vardır.
Gradyan artırmadaki öğrenme oranı, her bir zayıf öğrenicinin tahminini ölçeklendiren, 0 ile 1 arasında basit bir çarpandır (öğrenme oranı hakkında ayrıntılar için aşağıdaki bölüme bakın). Karışıma keyfi olarak 0.1’lik bir öğrenme oranı eklediğimizde, tahminimiz mükemmel 123.45 değil, 152.75 olur.

İkinci satırı da tahmin edelim:
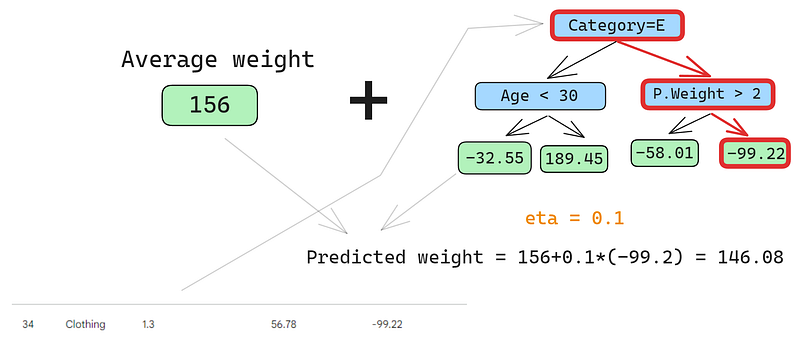
Satırı ağaçtan geçirir ve 146.08 tahminini elde ederiz. Bu şekilde tüm satırlar için devam ederiz ve dört satır için dört tahmin elde ederiz: 152.75, 146.08, 174.945, 150.2. Şimdilik bunları yeni bir sütun olarak ekleyelim:
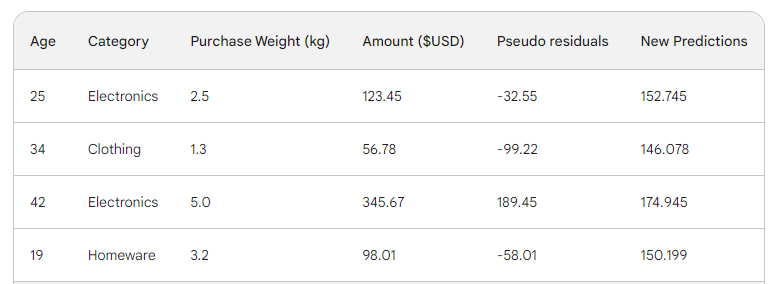
Ardından, yeni tahminleri satın alma tutarından çıkararak yeni psödo artıkları buluruz. Bunları tabloya yeni bir sütun olarak ekleyelim ve son ikisini bırakalım:
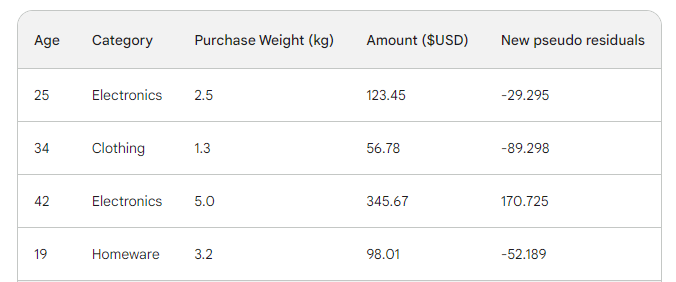
Gördüğünüz gibi, yeni psödo artıklarımız daha küçük; bu da kaybımızın düştüğü anlamına gelir.
Adım 4: Yineleyin
Sonraki adımlarda 3. adımı yineleriz, yani daha fazla zayıf öğrenici kurarız. Tek hatırlanması gereken, her ağacın artığını bir sonraki tahmini oluşturmak için ilk tahmine eklemeye devam etmemiz gerektiğidir.
Örneğin, 10 ağaç kurar ve her ağacın artıklarını r_i (1 <= i <= 10) ile gösterirsek, bir sonraki tahmin p_10 = 156 + eta * (r_1 + r_2 + ... + r_10) olur; burada p_10 onuncu turdaki tahmini ifade eder.
Pratikte, profesyoneller genellikle sadece 10 değil, 100 ağaçla başlar. Bu durumda algoritmanın 100 artırma turu için eğitildiği söylenir.
Belirli probleminiz için tam olarak kaç ağaca ihtiyacınız olduğunu bilmiyorsanız, erken durdurma (early stopping) adlı basit bir teknik kullanabilirsiniz.
Erken durdurmada, 1000 veya 10000 gibi büyük bir ağaç sayısı seçeriz. Ardından, algoritmanın tüm bu ağaçları bitirmesini beklemek yerine kaybı izleriz. Kayıp belirli sayıda artırma turu boyunca, örneğin 50 tur, iyileşmezse eğitimi daha erken durdururuz; böylece zaman ve hesaplama kaynakları tasarrufu sağlanır.
Gradyan Artırma Modellerini Yapılandırma
Makine öğreniminde, bir model için ayarları seçmeye "hiperparametre ayarlama" denir. Bu ayarlar, "hiperparametreler" olarak adlandırılır ve makine öğrenimi mühendisi tarafından seçilmelidir. Diğer parametrelerin aksine, model en iyi hiperparametre değerlerini yalnızca verilere eğitilerek öğrenemez.
Gradyan artırma modellerinin birçok hiperparametresi vardır; bunların bazılarını aşağıda özetleyeceğim.
Amaç
Bu parametre, algoritmanın yönünü ve kayıp fonksiyonunu belirler. Amaç regresyon ise kayıp fonksiyonu olarak MSE seçilir; sınıflandırma içinse Çapraz Entropi kullanılır. XGBoost gibi Python kütüphaneleri, sıralama gibi diğer görev türleri için karşılık gelen kayıp fonksiyonlarıyla başka amaçlar da sunar.
Öğrenme oranı
Gradyan artırmanın belki de en önemli hiperparametresi öğrenme oranıdır. Her zayıf öğrenicinin katkısını küçülme katsayısını ayarlayarak kontrol eder. Daha küçük değerler (0’a doğru) her zayıf öğrenicinin topluluk içindeki söz hakkını azaltır. Bu, daha fazla ağaç kurmayı ve dolayısıyla eğitimin daha uzun sürmesini gerektirir. Ancak nihai güçlü öğrenici gerçekten güçlü olur ve aşırı uyuma karşı direnç kazanır.
Ağaç sayısı
Artırma turu sayısı veya n_es timators olarak da adlandırılan bu parametre, inşa edilecek ağaç sayısını kontrol eder. Ne kadar çok ağaç kurarsanız, topluluk o kadar güçlü ve performanslı olur. Ayrıca daha karmaşık hale gelir; daha fazla ağaç, modelin verideki daha fazla deseni yakalamasına olanak tanır. Ancak daha fazla ağaç, aşırı uyum ihtimalini de önemli ölçüde artırır. Bunu hafifletmek için erken durdurma ile düşük öğrenme oranını birlikte kullanın.
Maksimum derinlik
Bu parametre, her zayıf öğrenicideki (karar ağacı) seviye sayısını kontrol eder. Maksimum derinlik 3 demek, yaprak düzeyi de sayılarak ağaçta üç seviye olduğu anlamına gelir. Ağaç derinleştikçe model daha karmaşık ve hesaplama olarak daha maliyetli hale gelir. Aşırı uyumu önlemek için 3’e yakın bir değer seçin. Üst sınırınız 10 derinlik olmalıdır.
Yaprak başına minimum örnek sayısı
Bu parametre, karar ağaçlarında dalların nasıl bölüneceğini kontrol eder. Sonlanım düğümlerindeki (yapraklardaki) örnek sayısı için düşük bir değer belirlemek, genel algoritmayı gürültüye karşı hassas kılar. Daha büyük bir minimum örnek sayısı, ağaçların çok az veri noktasına dayalı bölünmeler yapmasını zorlaştırarak aşırı uyumu önlemeye yardımcı olur.
Alt örnekleme oranı
Bu parametre, her ağacı eğitmek için kullanılan veri oranını kontrol eder. Yukarıdaki örneklerde, veri kümemizde yalnızca dört satır olduğu için satırların %100’ünü kullandık. Ancak gerçek dünya veri kümelerinde genellikle çok daha fazla satır bulunur ve örnekleme gerekir. Dolayısıyla alt örnekleme oranını 1’in altındaki bir değere, örneğin 0.7’ye ayarlarsanız, her zayıf öğrenici satırların rasgele örneklenmiş %70’i üzerinde eğitilir. Daha küçük alt örnekleme oranı daha hızlı eğitime yol açabilir, ancak aşırı uyuma da neden olabilir.
Özellik örnekleme oranı
Bu parametre, alt örnekleme ile aynıdır ancak satırları değil, özellikleri örnekler. Yüzlerce özelliğe sahip veri kümeleri için, aşırı uyum riskini azaltmak amacıyla 0.5 ile 1 arasında bir özellik örnekleme oranı seçilmesi önerilir.
Gradyan artırma, tablo biçimli denetimli öğrenme görevleri için elimizdeki en yetenekli modeldir. Bu yüzden çoğu zaman bir görev için yeterince iyi olmayacağından endişe etmenize gerek yoktur. Gradyan artırmayı kullandığınızda, zamanınızın neredeyse tamamı onu nasıl düzenleyeceğinize — gücünü ehlileştirip veri kümenizi yutup, görülmemiş veriler söz konusu olduğunda işe yaramaz hâle gelmesini engellemeye — harcanır.
Tanıttığım hiperparametrelerin tümü bu işte size yardımcı olur ve Python’daki her gradyan artırma uygulamasında bulunur. Onları iyi kullanın.
Python’da Uygulanan Gradyan Artırma
Daha önce belirttiğim gibi, gradyan artırma Python kütüphaneleriyle sağlam şekilde yerleşiktir. İşte başlıca dördü:
- XGBoost: eXtreme Gradient Boosting
- LightGBM: Light Gradient Boosting Machine
- CatBoost: Categorical Boosting
- Scikit-learn: Regresyon ve sınıflandırma için iki kestiriciye sahiptir
İlk üç kütüphane birbirine benzer:
- Baskın performans
- GPU desteği
- Zengin hiperparametre seti (yapılandırma dostu)
- Çok yüksek topluluk desteği
- Endüstride yaygın kullanım
Bu üç kütüphanenin popüler bir alternatifi, yalnızca CPU destekli olma dezavantajına sahip Scikit-learn’dür. Gradyan artırma hesaplama açısından ağır bir algoritma olduğundan, onu CPU’da çalıştırmak büyük veri kümeleri için (yüz binlerce satırdan bahsediyoruz) uygulanabilir olmayabilir.
Yine de unutmamak gerekir ki Scikit-learn tek başına, bu üç kütüphanenin toplamından daha popülerdir. Sınıflandırma ve regresyon için iki gradyan artırma kestiricisinin yanı sıra, Scikit-learn çok sayıda denetimli ve denetimsiz öğrenme görevi için onlarca başka model sunar.
Ayrıca, Scikit-learn ile kurulan gradyan artırma modelleri, ardışık düzenler (pipeline), çapraz doğrulama kestiricileri, veri işleyiciler vb. gibi zengin ekosistemine entegre edilebilir.
İşte GradientBoostingClassifier ile nasıl sınıflandırma yapılacağına dair adım adım bir rehber. Fiyatı ve diğer fiziksel ölçümlerine dayanarak elmasların kesim kalitesini tahmin edeceğiz. Bu veri kümesi Seaborn kütüphanesinde yerleşik olarak bulunur.
İpucu: DataCamp kod parçacığı düzenleyicisindeki “Kodu açıkla” düğmesini kullanarak satır satır ayrıntılı bir açıklama alın.
1. Kütüphaneleri içe aktarın
import pandas as pd
import seaborn as sns
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import cross_val_score, train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler2. Veriyi yükleyin
# Load the diamonds dataset from Seaborn
diamonds = sns.load_dataset("diamonds")
# Split data into features and target
X = diamonds.drop("cut", axis=1)
y = diamonds["cut"]3. Veriyi bölün
# Split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)4. Kategorik ve sayısal özellikleri tanımlayın
# Define categorical and numerical features
categorical_features = X.select_dtypes(
include=["object"]
).columns.tolist()
numerical_features = X.select_dtypes(
include=["float64", "int64"]
).columns.tolist()5. Kategorik ve sayısal özellikler için ön işleme adımlarını tanımlayın
preprocessor = ColumnTransformer(
transformers=[
("cat", OneHotEncoder(), categorical_features),
("num", StandardScaler(), numerical_features),
]
)6. Bir Gradyan Artırma Sınıflandırıcı ardışık düzeni oluşturun
pipeline = Pipeline(
[
("preprocessor", preprocessor),
("classifier", GradientBoostingClassifier(random_state=42)),
]
)
7. Çapraz doğrulama ve eğitim
# Perform 5-fold cross-validation
cv_scores = cross_val_score(pipeline, X_train, y_train, cv=5)
# Fit the model on the training data
pipeline.fit(X_train, y_train)
# Predict on the test set
y_pred = pipeline.predict(X_test)
# Generate classification report
report = classification_report(y_test, y_pred)
8. Nihai sonuçları raporlayın
print(f"Mean Cross-Validation Accuracy: {cv_scores.mean():.4f}")
print("\nClassification Report:")
print(report)
Mean Cross-Validation Accuracy: 0.7621
Classification Report:
precision recall f1-score support
Fair 0.90 0.91 0.91 335
Good 0.81 0.63 0.71 1004
Ideal 0.82 0.91 0.86 4292
Premium 0.70 0.86 0.77 2775
Very Good 0.66 0.41 0.51 2382
accuracy 0.76 10788
macro avg 0.78 0.74 0.75 10788
weighted avg 0.75 0.76 0.75 10788
Ağırlıklı doğruluk %75, bu da varsayılan parametrelerle kurulan bir başlangıç model için fena değil. Bu nedenle, bir meydan okuma olarak, GradientBoostingClassifier’ın hiperparametrelerini %95’in üzerinde performans elde edecek şekilde ayarlamayı size bırakıyorum. Evet, mümkün! (İpucu: son bölümü dikkatlice okuyun ve sınıflandırıcı için Scikit-learn belgelerine göz atın.).
Sonuç ve ileri okuma
Çok şey öğrenmiş olsak da, makalenin ana odağı gradyan artırma algoritmasının iç işleyişiydi. Nasıl çalıştığını anlamak, pratikte onu iyi kullanabileceğiniz anlamına gelmez. Ancak sezgisel anlayış her zaman büyük bir yardımcıdır.
Daha fazla öğrenme için şu kaynakları öneririm:
- DataCamp’ten XGBoost ile Gradyan Artırma Kullanımı: Google’da XGBoost konusunda 1 numaralı makale
- XGBoost ile Aşırı Gradyan Artırma Kursu: XGBoost üzerine kapsamlı bir kurs
Okuduğunuz için teşekkürler!

