Il corpo di questo articolo è lungo ma dettagliato, quindi terremo l’introduzione il più breve possibile, partendo subito dalla domanda: «Perché preoccuparsi del gradient boosting?»
Ci sono diversi ottimi motivi:
- Il gradient boosting è il migliore: la sua accuratezza e le sue prestazioni sono impareggiabili per i task supervisionati su dati tabellari.
- Il gradient boosting è estremamente versatile: può essere usato in molti task importanti come regressione, classificazione, ranking e analisi di sopravvivenza.
- Il gradient boosting è interpretabile: a differenza di algoritmi black-box come le reti neurali, non sacrifica l’interpretabilità per le prestazioni. Funziona come un orologio svizzero e, con pazienza, puoi spiegarne il funzionamento anche a uno scolaretto.
- Il gradient boosting è ben implementato: non è uno di quegli algoritmi con scarso valore pratico. Diverse librerie di gradient boosting come XGBoost e LightGBM in Python sono usate da centinaia di migliaia di persone.
- Il gradient boosting vince: dal 2015, i professionisti lo usano per vincere con costanza le competizioni su dati tabellari su piattaforme come Kaggle.
Se anche solo uno di questi punti ti sembra interessante, vale la pena continuare a leggere questo articolo.
Allora, iniziamo!
Cosa imparerai in questo tutorial?
Il risultato più importante di questo articolo è farti uscire con una comprensione molto solida del funzionamento interno del gradient boosting senza troppi mal di testa matematici. In fin dei conti, il gradient boosting è fatto per essere usato in pratica, non per essere analizzato matematicamente.
Che cos’è in generale il Gradient Boosting?
Boosting è una potente tecnica di ensemble nel machine learning. Diversamente dai modelli tradizionali che apprendono dai dati in modo indipendente, il boosting combina le previsioni di molteplici weak learner per creare un singolo strong learner più accurato.
Ho appena introdotto un po’ di termini nuovi, quindi lascia che li spieghi, partendo dai weak learner.
Un weak learner è un modello di machine learning che è solo leggermente migliore di un modello che indovina a caso. Per esempio, supponiamo di classificare funghi in commestibili e non commestibili. Se un modello a caso è accurato al 40%, un weak learner starebbe appena sopra: 50-60%.
Il boosting combina dozzine o centinaia di questi weak learner per costruire uno strong learner con il potenziale di superare il 95% di accuratezza sullo stesso problema.
Il weak learner più popolare è l’albero decisionale, scelto per la sua capacità di lavorare con quasi qualsiasi dataset. Se non hai familiarità con gli alberi decisionali, dai un’occhiata a questo tutorial di DataCamp Decision Tree Classification.
Applicazioni reali del Gradient Boosting
Il gradient boosting è diventato una forza così dominante nel machine learning che le sue applicazioni spaziano ormai in vari settori, dalla previsione del churn dei clienti al rilevamento di asteroidi. Ecco uno sguardo alle sue storie di successo su Kaggle e ai casi d’uso nel mondo reale:
Dominare le competizioni su Kaggle:
- Otto Group Product Classification Challenge: tutte le prime 10 posizioni hanno usato l’implementazione XGBoost del gradient boosting.
- Santander Customer Transaction Prediction: soluzioni basate su XGBoost hanno nuovamente conquistato i primi posti per prevedere il comportamento dei clienti e le transazioni finanziarie.
- Netflix Movie Recommendation Challenge: il gradient boosting ha avuto un ruolo cruciale nella costruzione di sistemi di raccomandazione per aziende da miliardi di dollari come Netflix.
Trasformare business e industria:
- Retail ed e-commerce: raccomandazioni personalizzate, gestione dell’inventario, rilevamento frodi
- Finanza e assicurazioni: valutazione del rischio di credito, previsione del churn, trading algoritmico
- Sanità e medicina: diagnosi di malattie, scoperta di farmaci, medicina personalizzata
- Ricerca e pubblicità online: ranking di ricerca, targeting degli annunci, previsione del click-through rate
Dunque, diamo finalmente un’occhiata sotto il cofano di questo algoritmo leggendario!
L’algoritmo di Gradient Boosting: guida passo passo
Input
L’algoritmo di gradient boosting funziona con dati tabellari con un insieme di feature (X) e un target (y). Come altri algoritmi di machine learning, l’obiettivo è imparare abbastanza dai dati di training da generalizzare bene su punti dati mai visti.
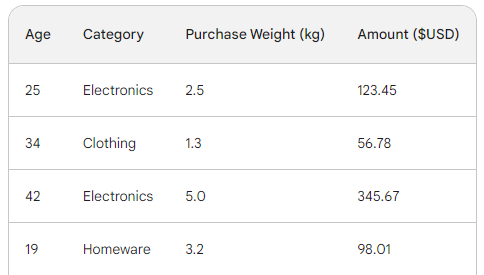
Per capire il processo alla base del gradient boosting, useremo un semplice dataset di vendite con quattro righe. Usando tre feature — età del cliente, categoria d’acquisto e peso dell’acquisto — vogliamo prevedere l’importo dell’acquisto:
La funzione di loss nel gradient boosting
Nel machine learning, una funzione di loss è una componente fondamentale che ci permette di quantificare la differenza tra le previsioni di un modello e i valori reali. In sostanza, misura come si sta comportando un modello.
Ecco il suo ruolo in sintesi:
- Calcola l’errore: prende l’output previsto del modello e lo confronta con la verità a terra (valori osservati reali). Il modo in cui confronta, cioè calcola la differenza, varia da funzione a funzione.
- Guida l’addestramento del modello: l’obiettivo di un modello è minimizzare la funzione di loss. Durante l’addestramento, il modello aggiorna continuamente la sua architettura interna e la sua configurazione per ridurre la loss il più possibile.
- Metrica di valutazione: confrontando la loss su training, validation e test set, puoi valutare la capacità del tuo modello di generalizzare ed evitare l’overfitting.
Le due funzioni di loss più comuni sono:
- Mean Squared Error (MSE): questa popolare funzione di loss per la regressione misura la somma dei quadrati delle differenze tra valori previsti e reali. Il gradient boosting usa spesso questa sua variante:
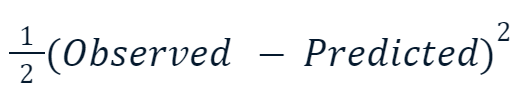
Il motivo per cui il valore al quadrato è moltiplicato per un mezzo ha a che fare con la differenziazione. Quando prendiamo la derivata di questa funzione di loss, il mezzo si semplifica con il quadrato per via della power rule. Quindi, il risultato finale diventa semplicemente -(Observed - Predicted), rendendo la matematica molto più semplice e meno costosa dal punto di vista computazionale.
- Entropia incrociata: questa funzione misura la differenza tra due distribuzioni di probabilità. Quindi è comunemente usata per task di classificazione in cui i target hanno categorie discrete.
Dato che stiamo facendo regressione, useremo l’MSE.
Passo 1: fai una previsione iniziale
Il gradient boosting è un algoritmo che aumenta gradualmente la sua accuratezza. Per iniziare il processo, ci serve un’ipotesi o previsione iniziale. L’ipotesi iniziale è sempre la media del target. In altre parole, per il primo round, il nostro modello prevede che tutti gli acquisti siano uguali — 156 dollari:
![]()
La ragione della scelta della media ha a che fare con la funzione di loss scelta e la sua derivata. A ogni passo, cerchiamo un valore che minimizzi la funzione di loss. In altre parole, cerchiamo un valore che renda la derivata (gradiente) della funzione di loss pari a 0.
E quando prendiamo la derivata della funzione di loss per ciascun valore osservato rispetto al previsto e le sommiamo, otteniamo la media del target.
Quindi, la nostra previsione iniziale è la media — 156 dollari. Tienila a mente mentre proseguiamo.
Passo 2: calcola i pseudoresidui
Il passo successivo è trovare le differenze tra ciascun valore osservato e la nostra previsione iniziale: 156 - Observed. Per illustrazione, metteremo queste differenze in una nuova colonna:
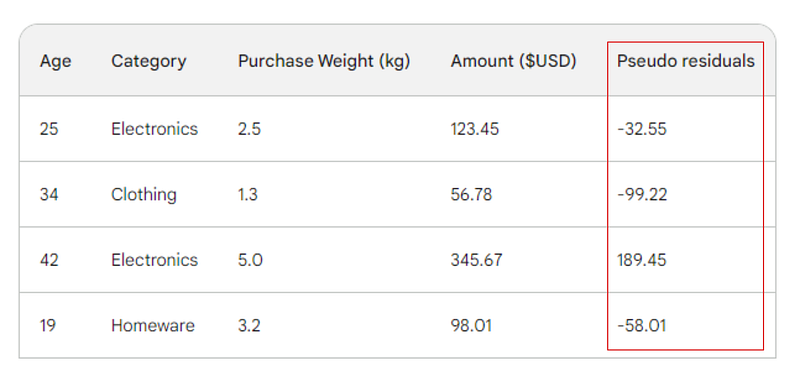
Ricorda che nella regressione lineare, la differenza tra valori osservati e previsti si chiama residui. Per differenziarli dalla regressione lineare, nel gradient boosting li chiamiamo pseudoresidui (ci sono altri motivi per cui si chiamano così, ma in questo articolo non li tratteremo).
Passo 3: costruisci un weak learner
Ora costruiamo un albero decisionale (weak learner) che preveda i residui usando le tre feature che abbiamo (età, categoria, peso dell’acquisto). Per questo problema, limiteremo l’albero decisionale a sole quattro foglie (nodi terminali), ma in pratica si scelgono di solito tra 8 e 32 foglie.
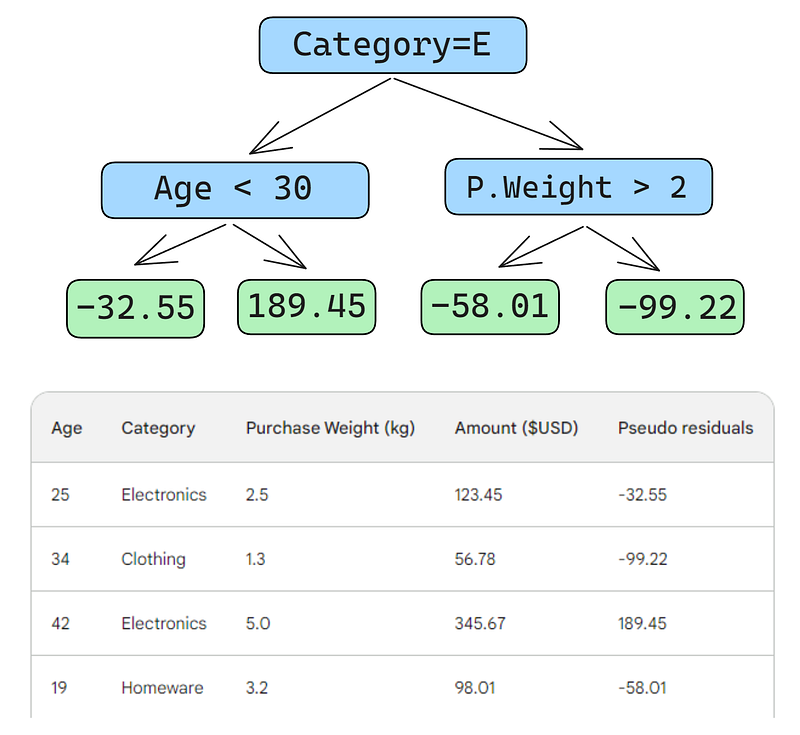
Dopo aver adattato l’albero ai dati, facciamo una previsione per ciascuna riga. Ecco come fare per la prima:
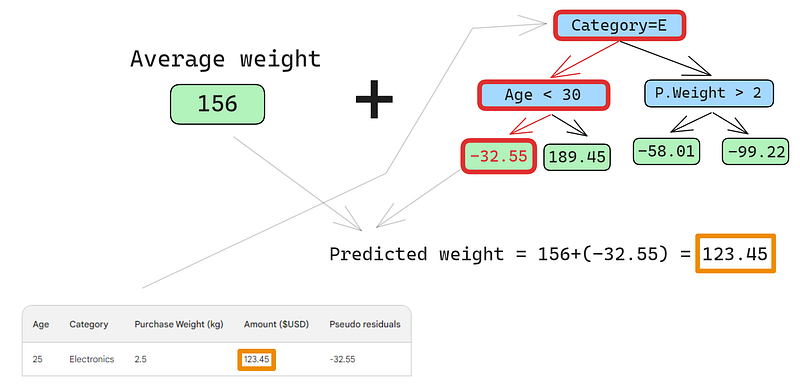
Un piccolo errore nelle immagini qui sotto: avrebbe dovuto essere scritto «Predicted purchase amount», non «Predicted weight»
La prima riga ha le seguenti feature: una categoria elettronica (a sinistra del nodo radice) ed età del cliente sotto i 30 anni (a sinistra del nodo figlio). Questo inserisce -32,55 nel nodo foglia. Per fare la previsione finale, aggiungiamo -32,55 alla nostra prima previsione, che è esattamente uguale al valore osservato — 123,45 dollari!
Abbiamo appena fatto una previsione perfetta, quindi perché preoccuparsi di costruire altri alberi? Beh, al momento stiamo overfittando pesantemente ai dati di training. Vogliamo che il modello generalizzi. Per mitigare questo problema, il gradient boosting ha un parametro chiamato learning rate.
Il learning rate nel gradient boosting è semplicemente un moltiplicatore tra 0 e 1 che ridimensiona la previsione di ciascun weak learner (vedi la sezione sotto per i dettagli sul learning rate). Quando aggiungiamo un learning rate arbitrario di 0,1 alla miscela, la nostra previsione diventa 152,75, non il perfetto 123,45.

Prevediamo anche sulla seconda riga:
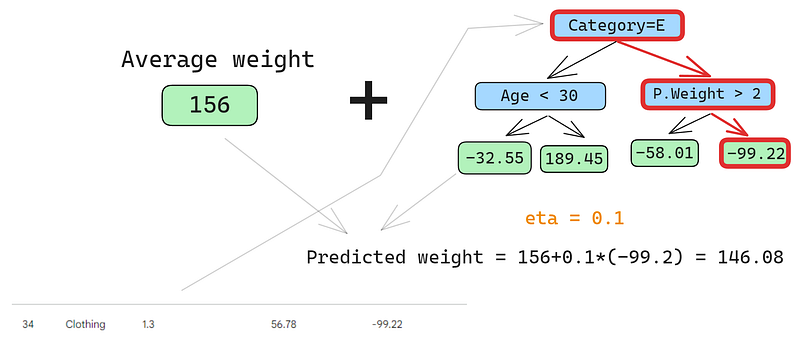
Facciamo passare la riga nell’albero e otteniamo 146,08 come previsione. Continuiamo così per tutte le righe finché non abbiamo quattro previsioni per quattro righe: 152,75, 146,08, 174,945, 150,2. Aggiungiamole per ora come nuova colonna:
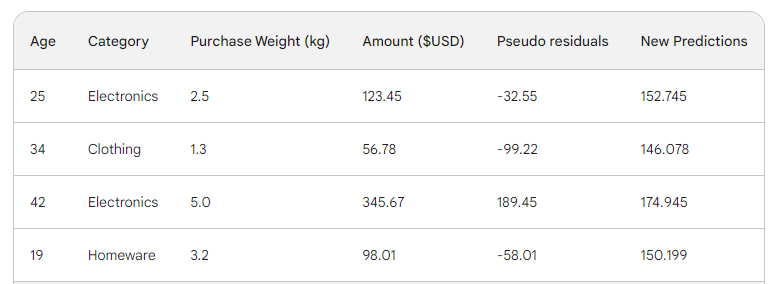
Poi troviamo i nuovi pseudoresidui sottraendo le nuove previsioni dall’importo dell’acquisto. Aggiungiamoli come nuova colonna alla tabella e rimuoviamo le ultime due:
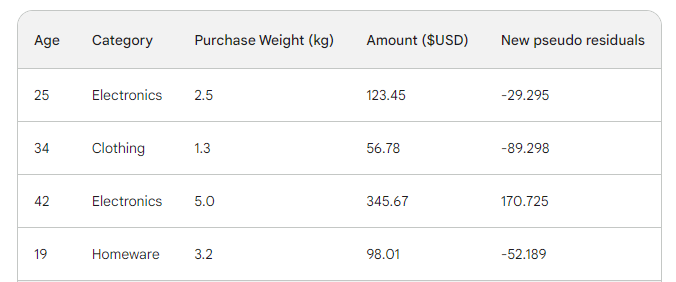
Come puoi vedere, i nostri nuovi pseudoresidui sono più piccoli, il che significa che la nostra loss sta diminuendo.
Passo 4: itera
Nei passaggi successivi, iteriamo il passo 3, cioè costruiamo altri weak learner. L’unica cosa da ricordare è che dobbiamo continuare ad aggiungere i residui di ciascun albero alla previsione iniziale per generare la successiva.
Per esempio, se costruiamo 10 alberi e i residui di ciascun albero sono indicati come r_i (1 <= i <= 10), la prossima previsione diventerà p_10 = 156 + eta * (r_1 + r_2 + ... + r_10) dove p_10 indica la previsione al decimo round.
In pratica, i professionisti spesso partono con 100 alberi, non solo 10. In questo caso, si dice che l’algoritmo si alleni per 100 boosting round.
Se non conosci il numero esatto di alberi di cui hai bisogno per il tuo problema specifico, puoi usare una tecnica semplice chiamata early stopping.
Con l’early stopping, scegliamo un numero elevato di alberi, come 1000 o 10000. Poi, invece di aspettare che l’algoritmo finisca di costruire tutti quegli alberi, monitoriamo la loss. Se la loss non migliora per un certo numero di boosting round, per esempio 50, interrompiamo l’addestramento prima, risparmiando tempo e risorse computazionali.
Configurare i modelli di Gradient Boosting
Nel machine learning, la scelta delle impostazioni di un modello è nota come "tuning degli iperparametri". Queste impostazioni, chiamate "iperparametri", sono opzioni che l’ingegnere di machine learning deve scegliere manualmente. A differenza di altri parametri, il modello non può imparare i valori migliori per gli iperparametri semplicemente addestrandosi sui dati.
I modelli di gradient boosting hanno molti iperparametri, alcuni dei quali elenco qui sotto.
Objective
Questo parametro imposta la direzione e la funzione di loss dell’algoritmo. Se l’obiettivo è la regressione, si sceglie l’MSE come funzione di loss, mentre per la classificazione si usa l’entropia incrociata. Librerie Python come XGBoost offrono altri objective per altri tipi di task, come il ranking, con le relative funzioni di loss.
Learning rate
L’iperparametro forse più importante del gradient boosting è il learning rate. Controlla il contributo di ciascun weak learner regolando il fattore di shrinkage. Valori più piccoli (verso 0) riducono quanto peso ha ciascun weak learner nell’ensemble. Questo richiede di costruire più alberi e, quindi, più tempo per finire l’addestramento. Tuttavia, lo strong learner finale sarà davvero forte e resistente all’overfitting.
Numero di alberi
Questo parametro, chiamato anche numero di boosting round o n_es timators, controlla quanti alberi costruire. Più alberi costruisci, più forte e performante diventa l’ensemble. Diventa anche più complesso poiché più alberi permettono al modello di catturare più pattern nei dati. Tuttavia, più alberi aumentano sensibilmente le probabilità di overfitting. Per mitigare, usa una combinazione di early stopping e learning rate basso.
Profondità massima
Questo parametro controlla il numero di livelli in ciascun weak learner (albero decisionale). Una profondità massima di 3 significa tre livelli nell’albero, contando il livello delle foglie. Più l’albero è profondo, più il modello diventa complesso e costoso computazionalmente. Scegli un valore vicino a 3 per prevenire l’overfitting. Il tuo massimo dovrebbe essere una profondità di 10.
Numero minimo di campioni per foglia
Questo parametro controlla come si dividono i rami negli alberi decisionali. Impostare un valore basso per il numero di campioni nei nodi terminali (foglie) rende l’algoritmo sensibile al rumore. Un numero minimo più grande di campioni aiuta a prevenire l’overfitting rendendo più difficile per gli alberi creare split basati su troppo pochi punti dati.
Tasso di sottocampionamento
Questo parametro controlla la proporzione di dati usata per addestrare ciascun albero. Negli esempi sopra, abbiamo usato il 100% delle righe perché il nostro dataset aveva solo quattro righe. Ma i dataset reali spesso ne hanno molti di più e richiedono campionamento. Quindi, se imposti il tasso di sottocampionamento a un valore inferiore a 1, ad esempio 0,7, ciascun weak learner si addestra su un 70% di righe campionate casualmente. Un sottocampionamento più piccolo può portare ad addestramenti più veloci ma anche a overfitting.
Tasso di campionamento delle feature
Questo parametro è esattamente come il sottocampionamento, ma campiona le righe. Per dataset con centinaia di feature, è consigliato scegliere un tasso di campionamento delle feature tra 0,5 e 1 per ridurre la probabilità di overfitting.
Il gradient boosting è il modello più capace che abbiamo per i task supervisionati su dati tabellari. Quindi, nella maggior parte dei casi, non devi preoccuparti che non sia abbastanza buono per un task. Quando usi il gradient boosting, il tuo tempo è quasi sempre speso su come regolarizzarlo — domarne la potenza in modo che non si limiti a ingoiare il tuo dataset diventando inutile sui dati mai visti.
Gli iperparametri che ho introdotto ti aiutano proprio in questo compito e sono inclusi in ogni implementazione del gradient boosting in Python. Usali bene.
Gradient Boosting implementato in Python
Come accennato, il gradient boosting è ben consolidato tramite librerie Python. Ecco le quattro principali:
- XGBoost: eXtreme Gradient Boosting
- LightGBM: Light Gradient Boosting Machine
- CatBoost: Categorical Boosting
- Scikit-learn: ha due stimatori per regressione e classificazione
Le prime tre librerie sono simili tra loro:
- Prestazioni dominanti
- Supporto GPU
- Set ricco di iperparametri (facili da configurare)
- Supporto comunitario molto ampio
- Usate estesamente nell’industria
Un’alternativa popolare a tutte e tre è Scikit-learn, che ha lo svantaggio di essere solo su CPU. Poiché il gradient boosting è un algoritmo pesante dal punto di vista computazionale, eseguirlo su CPU può risultare impraticabile per dataset di grandi dimensioni (parliamo di centinaia di migliaia di righe).
Tuttavia, va ricordato che Scikit-learn, da sola, è più popolare delle tre librerie messe insieme. Oltre ai due stimatori di gradient boosting per classificazione e regressione, Scikit-learn offre dozzine di altri modelli per una miriade di task supervisionati e non supervisionati.
Inoltre, i modelli di gradient boosting costruiti con Scikit-learn possono essere integrati nel suo ricco ecosistema come pipeline, stimatori di cross-validation, processori di dati, ecc.
Ecco una guida passo passo su come fare classificazione con GradientBoostingClassifier. Prevedremo la qualità del taglio dei diamanti in base al loro prezzo e ad altre misurazioni fisiche. Questo dataset è incluso nella libreria Seaborn.
Consiglio pro: usa il pulsante “Explain code” dell’editor di snippet di codice di DataCamp per ottenere una spiegazione dettagliata riga per riga di ciò che sta succedendo.
1. Importa le librerie
import pandas as pd
import seaborn as sns
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import cross_val_score, train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler2. Carica i dati
# Load the diamonds dataset from Seaborn
diamonds = sns.load_dataset("diamonds")
# Split data into features and target
X = diamonds.drop("cut", axis=1)
y = diamonds["cut"]3. Suddividi i dati
# Split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)4. Definisci feature categoriche e numeriche
# Define categorical and numerical features
categorical_features = X.select_dtypes(
include=["object"]
).columns.tolist()
numerical_features = X.select_dtypes(
include=["float64", "int64"]
).columns.tolist()5. Definisci i passaggi di preprocessing per feature categoriche e numeriche
preprocessor = ColumnTransformer(
transformers=[
("cat", OneHotEncoder(), categorical_features),
("num", StandardScaler(), numerical_features),
]
)6. Crea una pipeline con Gradient Boosting Classifier
pipeline = Pipeline(
[
("preprocessor", preprocessor),
("classifier", GradientBoostingClassifier(random_state=42)),
]
)
7. CV e training
# Perform 5-fold cross-validation
cv_scores = cross_val_score(pipeline, X_train, y_train, cv=5)
# Fit the model on the training data
pipeline.fit(X_train, y_train)
# Predict on the test set
y_pred = pipeline.predict(X_test)
# Generate classification report
report = classification_report(y_test, y_pred)
8. Riporta i risultati finali
print(f"Mean Cross-Validation Accuracy: {cv_scores.mean():.4f}")
print("\nClassification Report:")
print(report)
Mean Cross-Validation Accuracy: 0.7621
Classification Report:
precision recall f1-score support
Fair 0.90 0.91 0.91 335
Good 0.81 0.63 0.71 1004
Ideal 0.82 0.91 0.86 4292
Premium 0.70 0.86 0.77 2775
Very Good 0.66 0.41 0.51 2382
accuracy 0.76 10788
macro avg 0.78 0.74 0.75 10788
weighted avg 0.75 0.76 0.75 10788
L’accuratezza pesata è del 75%, niente male per un modello baseline con parametri di default. Quindi, come sfida, lascio a te il compito di regolare gli iperparametri di GradientBoostingClassifier per superare il 95% di prestazioni. Sì, è possibile! (Suggerimento: leggi attentamente l’ultima sezione e consulta la documentazione di Scikit-learn per il classifier).
Conclusione e approfondimenti
Anche se abbiamo imparato tantissimo, il focus principale dell’articolo era sul funzionamento interno dell’algoritmo di gradient boosting. Capire come funziona non si traduce automaticamente nella capacità di usarlo bene in pratica. Tuttavia, una comprensione intuitiva è sempre di grande aiuto.
Per approfondire, consiglio le seguenti risorse:
- Usare il Gradient Boosting con XGBoost di DataCamp: articolo #1 su XGBoost su Google
- Extreme Gradient Boosting With XGBoost Course: un corso completo su XGBoost
Grazie per la lettura!


