De body van dit artikel is lang maar gedetailleerd, dus we houden de introductie zo kort mogelijk en beginnen direct met de vraag: “Waarom zou je moeite doen voor gradient boosting?”
Daar zijn een aantal uitstekende redenen voor:
- Gradient boosting is de beste: de nauwkeurigheid en prestaties zijn ongeëvenaard voor tabelvormige supervised learning-taken.
- Gradient boosting is zeer veelzijdig: het kan worden gebruikt voor veel belangrijke taken zoals regressie, classificatie, ranking en survivalanalyse.
- Gradient boosting is interpreteerbaar: in tegenstelling tot blackbox-algoritmen zoals neurale netwerken, levert gradient boosting geen interpretatie in voor prestaties. Het werkt als een Zwitsers horloge en toch kun je met wat geduld een scholier uitleggen hoe het werkt.
- Gradient boosting is goed geïmplementeerd: het is niet een van die algoritmen met weinig praktische waarde. Verschillende gradient boosting-bibliotheken zoals XGBoost en LightGBM in Python worden door honderdduizenden mensen gebruikt.
- Gradient boosting wint: sinds 2015 wordt het door professionals gebruikt om consequent tabelcompetities te winnen op platforms als Kaggle.
Als een van deze punten ook maar enigszins aantrekkelijk klinkt, is het de moeite waard om door te lezen.
Laten we beginnen!
Wat ga je leren in deze tutorial?
De belangrijkste boodschap van dit artikel is dat je een zeer stevige grip krijgt op de interne werking van gradient boosting, zonder veel wiskundige hoofdpijn. Uiteindelijk is gradient boosting bedoeld voor gebruik in de praktijk, niet voor puur wiskundige analyse.
Wat is gradient boosting in het algemeen?
Boosting is een krachtige ensembletechniek in machine learning. In tegenstelling tot traditionele modellen die onafhankelijk van de data leren, combineert boosting de voorspellingen van meerdere zwakke leerders tot één enkele, nauwkeurigere sterke learner.
Ik heb zojuist een reeks nieuwe termen gebruikt, dus laat me elk ervan uitleggen, te beginnen met zwakke leerders.
Een zwakke learner is een machinelearningmodel dat net iets beter presteert dan willekeurig gokken. Stel dat we paddenstoelen classificeren in eetbaar en oneetbaar. Als een model dat raadt 40% nauwkeurig is, dan zit een zwakke learner daar net boven: 50-60%.
Boosting combineert tientallen of honderden van deze zwakke leerders om een sterke learner te bouwen met potentieel voor meer dan 95% nauwkeurigheid op hetzelfde probleem.
De populairste zwakke learner is een beslisboom, gekozen vanwege het vermogen om met vrijwel elke dataset te werken. Als je niet bekend bent met beslisbomen, bekijk dan deze DataCamp-tutorial Decision Tree Classification.
Toepassingen van gradient boosting in de echte wereld
Gradient boosting is zo dominant geworden in machine learning dat de toepassingen zich uitstrekken over diverse sectoren, van het voorspellen van klantverloop tot het detecteren van asteroïden. Hier is een glimp van succesverhalen op Kaggle en in echte use-cases:
Dominantie in Kaggle-competities:
- Otto Group Product Classification Challenge: alle top 10-posities gebruikten de XGBoost-implementatie van gradient boosting.
- Santander Customer Transaction Prediction: oplossingen op basis van XGBoost veroverden opnieuw de topposities voor het voorspellen van klantgedrag en financiële transacties.
- Netflix Movie Recommendation Challenge: Gradient boosting speelde een cruciale rol bij het bouwen van aanbevelingssystemen voor miljardenbedrijven zoals Netflix.
Transformatie van business en industrie:
- Retail en e-commerce: gepersonaliseerde aanbevelingen, voorraadbeheer, fraudedetectie
- Financiën en verzekeringen: kredietrisicobeoordeling, churnvoorspelling, algoritmische handel
- Gezondheidszorg en geneeskunde: ziekte-diagnose, medicijnontdekking, gepersonaliseerde geneeskunde
- Zoek en online advertenties: zoekranking, advertentietargeting, klikfrequentievoorspelling
Laten we nu eindelijk onder de motorkap kijken van dit legendarische algoritme!
Het gradient boosting-algoritme: een stapsgewijze gids
Input
Het gradient boosting-algoritme werkt voor tabeldata met een set features (X) en een target (y). Net als andere machinelearningalgoritmen is het doel om genoeg te leren van de trainingsdata om goed te generaliseren naar ongeziene datapunten.
Om het onderliggende proces van gradient boosting te begrijpen, gebruiken we een eenvoudige sales-dataset met vier rijen. Met drie features — leeftijd van de klant, aankoopcategorie en aankoopgewicht — willen we het aankoopbedrag voorspellen:
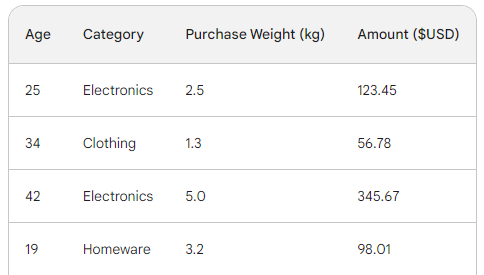
De verliesfunctie in gradient boosting
In machine learning is een verliesfunctie een cruciaal onderdeel waarmee we het verschil kunnen kwantificeren tussen de voorspellingen van een model en de werkelijke waarden. In wezen meet het hoe een model presteert.
Hier is een overzicht van de rol ervan:
- Bereken de fout: Neemt de voorspelde output van het model en vergelijkt die met de grondwaarheid (feitelijk geobserveerde waarden). Hoe er wordt vergeleken, dus hoe het verschil wordt berekend, verschilt per functie.
- Stuurt het trainen van het model: het doel van een model is om de verliesfunctie te minimaliseren. Tijdens het trainen past het model voortdurend zijn interne architectuur en configuratie aan om het verlies zo klein mogelijk te maken.
- Evaluatiemaatstaf: Door het verlies op train-, validatie- en testset te vergelijken, kun je het generaliserend vermogen van je model inschatten en overfitting vermijden.
De twee meest voorkomende verliesfuncties zijn:
- Mean Squared Error (MSE): Deze populaire verliesfunctie voor regressie meet de som van de gekwadrateerde verschillen tussen voorspelde en werkelijke waarden. Gradient boosting gebruikt vaak deze variant ervan:
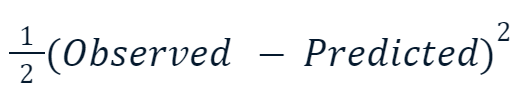
De reden dat de kwadraatterm met een half wordt vermenigvuldigd, heeft te maken met differentiëren. Wanneer we de afgeleide van deze verliesfunctie nemen, valt die helft weg tegen het kwadraat vanwege de machtsregel. Het eindresultaat wordt dan gewoon -(Observed - Predicted), waardoor de wiskunde veel eenvoudiger en minder rekenintensief wordt.
- Cross-entropy: Deze functie meet het verschil tussen twee kansverdelingen. Daarom wordt ze vaak gebruikt voor classificatietaken waarbij de targets uit discrete categorieën bestaan.
Aangezien we regressie doen, gebruiken we MSE.
Stap 1: Maak een initiële voorspelling
Gradient boosting is een algoritme dat zijn nauwkeurigheid geleidelijk verhoogt. Om het proces te starten, hebben we een eerste gok of voorspelling nodig. De initiële gok is altijd het gemiddelde van de target. Met andere woorden, voor de eerste ronde voorspelt ons model dat alle aankopen hetzelfde waren — 156 dollar:
![]()
De reden om het gemiddelde te kiezen heeft te maken met onze gekozen verliesfunctie en de afgeleide ervan. Elke stap zijn we op zoek naar een waarde die het minimum van de verliesfunctie vindt. Met andere woorden, we zoeken een waarde die de afgeleide (gradiënt) van de verliesfunctie 0 maakt.
En wanneer we de afgeleide van de verliesfunctie voor elke geobserveerde waarde nemen ten opzichte van de voorspelde en ze optellen, komen we uit op het gemiddelde van de target.
Dus, onze initiële voorspelling is het gemiddelde — 156 dollar. Houd dat in het geheugen terwijl we doorgaan.
Stap 2: Bereken de pseudo-residuen
De volgende stap is het verschil te vinden tussen elke geobserveerde waarde en onze initiële voorspelling: 156 - Observed. Ter illustratie zetten we die verschillen in een nieuwe kolom:
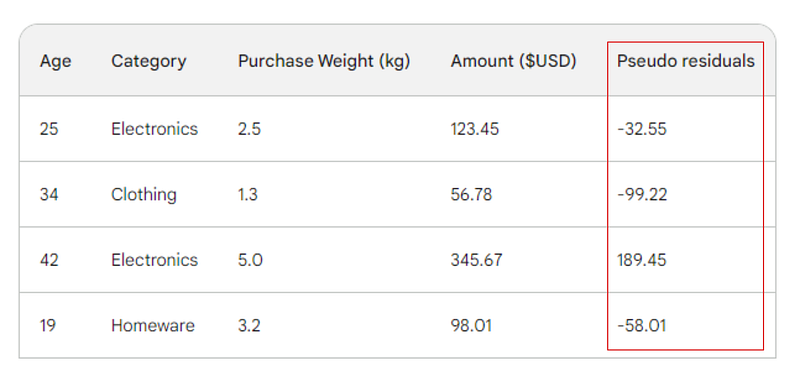
Onthoud dat in lineaire regressie het verschil tussen geobserveerde en voorspelde waarden residuen wordt genoemd. Om lineaire regressie en gradient boosting te onderscheiden, noemen we ze pseudo-residuen (er zijn nog andere redenen voor die naam, maar daar gaan we in dit artikel niet op in).
Stap 3: Bouw een zwakke learner
Vervolgens bouwen we een beslisboom (zwakke learner) die de residuen voorspelt met behulp van de drie features die we hebben (leeftijd, categorie, aankoopgewicht). Voor dit probleem beperken we de beslisboom tot slechts vier bladeren (terminal nodes), maar in de praktijk kiezen mensen meestal 8 tot 32 bladeren.
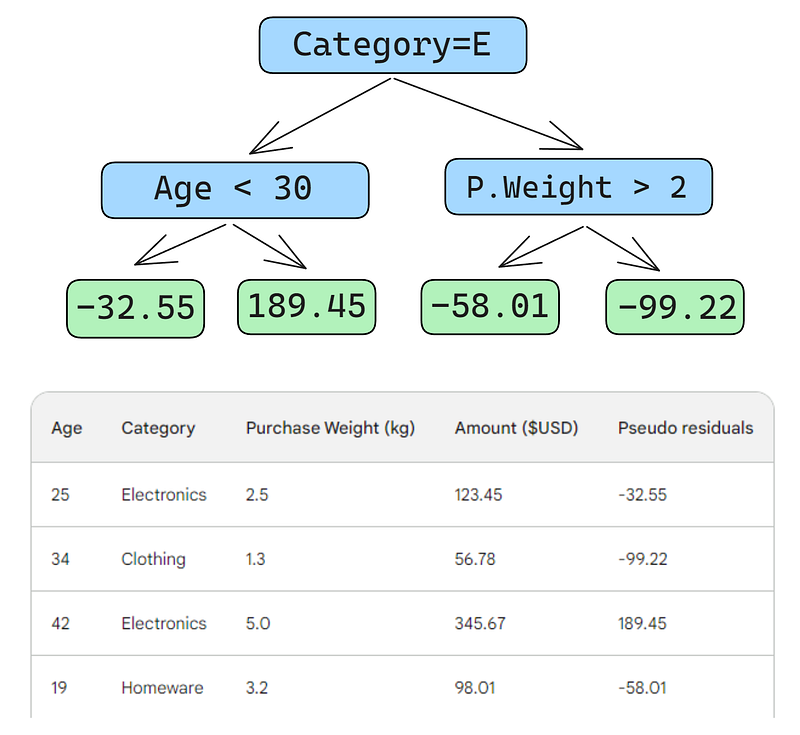
Nadat de boom op de data is gefit, maken we voor elke rij in de data een voorspelling. Zo doe je de eerste:
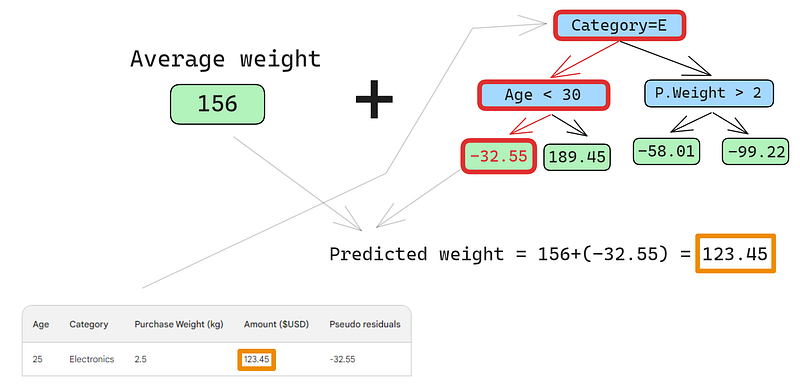
Een kleine fout in de onderstaande afbeeldingen: er had “Predicted purchase amount” moeten staan, niet “Predicted weight”
De eerste rij heeft de volgende features: een categorie electronics (links van de rootnode) en een klantleeftijd onder de 30 (links van de childnode). Dit levert -32,55 op in het blad. Voor de uiteindelijke voorspelling tellen we -32,55 op bij onze eerste voorspelling, die exact gelijk is aan de geobserveerde waarde — 123,45 dollar!
We hebben zojuist een perfecte voorspelling gemaakt, dus waarom nog andere bomen bouwen? Nou, op dit moment overfitten we zwaar op de trainingsdata. We willen dat het model generaliseert. Om dit te mitigeren heeft gradient boosting een parameter die learning rate heet.
De learning rate in gradient boosting is simpelweg een vermenigvuldigingsfactor tussen 0 en 1 die de voorspelling van elke zwakke learner schaalt (zie de onderstaande sectie voor details over de learning rate). Wanneer we een willekeurige learning rate van 0,1 toevoegen, wordt onze voorspelling 152,75, niet de perfecte 123,45.

Laten we ook op de tweede rij voorspellen:
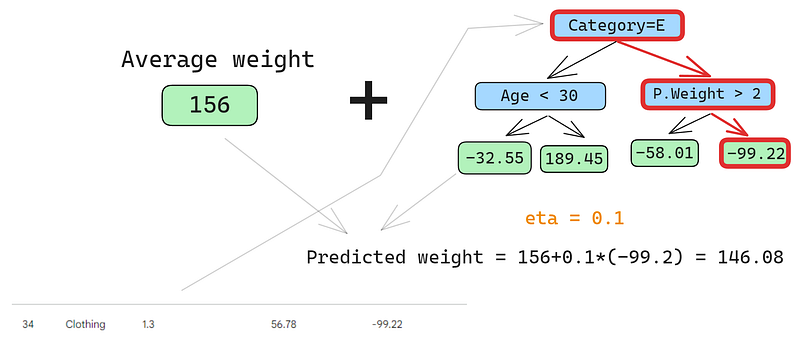
We halen de rij door de boom en krijgen 146,08 als voorspelling. We gaan zo door voor alle rijen totdat we vier voorspellingen voor vier rijen hebben: 152,75, 146,08, 174,945, 150,2. Laten we ze voorlopig als nieuwe kolom toevoegen:
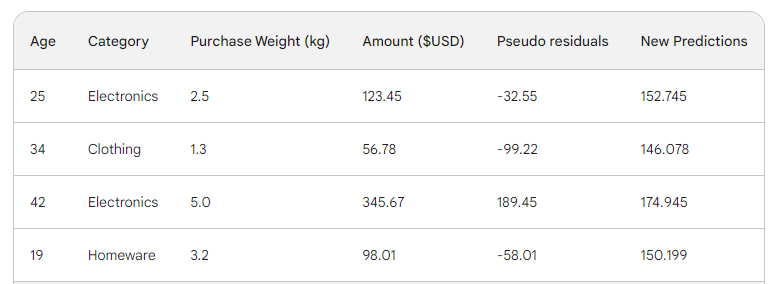
Vervolgens vinden we de nieuwe pseudo-residuen door de nieuwe voorspellingen van het aankoopbedrag af te trekken. Laten we ze als nieuwe kolom aan de tabel toevoegen en de laatste twee laten vallen:
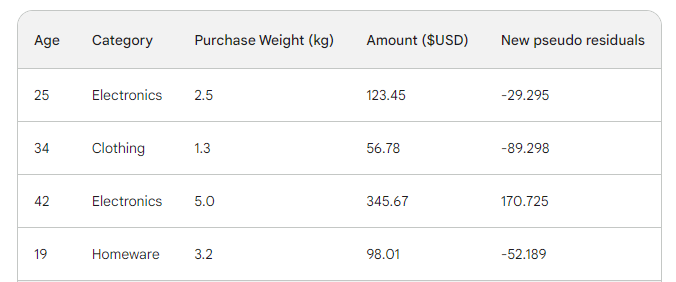
Zoals je ziet zijn onze nieuwe pseudo-residuen kleiner, wat betekent dat ons verlies omlaag gaat.
Stap 4: Itereren
In de volgende stappen itereren we op stap 3, oftewel we bouwen meer zwakke leerders. Het enige om te onthouden is dat we de residuen van elke boom moeten blijven optellen bij de initiële voorspelling om de volgende te genereren.
Als we bijvoorbeeld 10 bomen bouwen en de residuen van elke boom worden aangeduid als r_i (1 <= i <= 10), dan wordt de volgende voorspelling p_10 = 156 + eta * (r_1 + r_2 + ... + r_10) waarbij p_10 de voorspelling in de tiende ronde aangeeft.
In de praktijk beginnen professionals vaak met 100 bomen, niet slechts 10. In dat geval zeggen we dat het algoritme traint voor 100 boostingrondes.
Als je het exacte aantal bomen dat je nodig hebt voor jouw specifieke probleem niet weet, kun je een eenvoudige techniek gebruiken die early stopping heet.
Bij early stopping kiezen we een groot aantal bomen, zoals 1000 of 10000. In plaats van te wachten tot het algoritme al die bomen heeft gebouwd, monitoren we het verlies. Als het verlies niet verbetert gedurende een bepaald aantal boostingrondes, bijvoorbeeld 50, stoppen we eerder met trainen, wat tijd en rekenkracht bespaart.
Gradient boosting-modellen configureren
In machine learning noemen we het kiezen van de instellingen voor een model "hyperparametertuning". Deze instellingen, "hyperparameters" genoemd, zijn opties die de machinelearning-engineer zelf moet kiezen. In tegenstelling tot andere parameters kan het model de beste waarden voor hyperparameters niet simpelweg leren door te trainen op data.
Gradient boosting-modellen hebben veel hyperparameters, waarvan ik er hieronder een aantal uiteenzet.
Objective
Deze parameter bepaalt de richting en de verliesfunctie van het algoritme. Als het doel regressie is, wordt MSE als verliesfunctie gekozen, terwijl voor classificatie Cross-Entropy de juiste keuze is. Python-bibliotheken zoals XGBoost bieden andere objectives voor andere soorten taken, zoals ranking met bijbehorende verliesfuncties.
Learning rate
De belangrijkste hyperparameter van gradient boosting is wellicht de learning rate. Die bepaalt de bijdrage van elke zwakke learner door de shrinkagefactor aan te passen. Kleinere waarden (richting 0) verkleinen hoeveel zeggenschap elke zwakke learner heeft in het ensemble. Dit vereist het bouwen van meer bomen en dus meer tijd om het trainen te voltooien. Maar de uiteindelijke sterke learner zal inderdaad sterk zijn en bestand tegen overfitting.
Het aantal bomen
Deze parameter, ook wel het aantal boostingrondes of n_es timators genoemd, bepaalt het aantal te bouwen bomen. Hoe meer bomen je bouwt, hoe sterker en performanter het ensemble wordt. Het wordt ook complexer, omdat meer bomen het model in staat stellen meer patronen in de data te vangen. Meer bomen vergroten echter de kans op overfitting aanzienlijk. Verminder dit risico met een combinatie van early stopping en een lage learning rate.
Max depth
Deze parameter bepaalt het aantal niveaus in elke zwakke learner (beslisboom). Een max depth van 3 betekent dat er drie niveaus in de boom zijn, waarbij het bladniveau wordt meegeteld. Hoe dieper de boom, hoe complexer en rekenintensiever het model wordt. Kies een waarde in de buurt van 3 om overfitting te voorkomen. Je maximum zou een diepte van 10 moeten zijn.
Minimum aantal samples per blad
Deze parameter stuurt hoe takken splitsen in beslisbomen. Een lage waarde instellen voor het aantal samples in terminale nodes (bladeren) maakt het totale algoritme gevoelig voor ruis. Een groter minimum aantal samples helpt overfitting te voorkomen door het lastiger te maken voor bomen om splitsingen te maken op basis van te weinig datapunten.
Subsamplingrate
Deze parameter bepaalt het aandeel van de data dat wordt gebruikt om elke boom te trainen. In de voorbeelden hierboven gebruikten we 100% van de rijen omdat er slechts vier rijen in onze dataset zaten. Maar echte datasets zijn vaak veel groter en vereisen sampling. Stel je de subsamplingrate in op een waarde onder 1, zoals 0,7, dan traint elke zwakke learner op een willekeurig getrokken 70% van de rijen. Een kleinere subsample-rate kan tot snellere training leiden, maar ook tot overfitting.
Featuresamplingrate
Deze parameter is precies zoals subsampling, maar dan voor het samplen van rijen. Voor datasets met honderden features is het aan te raden een featuresamplingrate tussen 0,5 en 1 te kiezen om de kans op overfitting te verkleinen.
Gradient boosting is het meest capabele model dat we hebben voor tabelvormige supervised learning-taken. Dus meestal hoef je je geen zorgen te maken dat het niet goed genoeg is voor een taak. Wanneer je gradient boosting gebruikt, besteed je tijd bijna altijd aan hoe je het moet regulariseren — de kracht temmen zodat het je dataset niet simpelweg opslokt en nutteloos wordt voor ongeziene data.
De hyperparameters die ik heb geïntroduceerd, helpen je allemaal bij deze taak en zijn opgenomen in elke implementatie van gradient boosting in Python. Gebruik ze verstandig.
Gradient boosting geïmplementeerd in Python
Zoals ik eerder al zei, is gradient boosting stevig verankerd in Python-bibliotheken. Dit zijn de belangrijkste vier:
- XGBoost: eXtreme Gradient Boosting
- LightGBM: Light Gradient Boosting Machine
- CatBoost: Categorical Boosting
- Scikit-learn: heeft twee estimators voor regressie en classificatie
De eerste drie bibliotheken lijken op elkaar:
- Dominante prestaties
- GPU-ondersteuning
- Rijke set hyperparameters (configuratievriendelijk)
- Zeer veel community-ondersteuning
- Extensief gebruikt in de industrie
Een populair alternatief voor deze drie is Scikit-learn, met het nadeel dat het alleen CPU gebruikt. Omdat gradient boosting een rekenintensief algoritme is, kan het draaien op een CPU onhaalbaar zijn voor grote datasets (we hebben het over honderdduizenden rijen).
We moeten echter niet vergeten dat Scikit-learn op zichzelf populairder is dan de drie bibliotheken samen. Naast de twee gradient boosting-estimators voor classificatie en regressie biedt Scikit-learn tientallen andere modellen voor een scala aan supervised en unsupervised learning-taken.
Bovendien kunnen gradient boosting-modellen die met Scikit-learn zijn gebouwd, worden geïntegreerd in het rijke ecosysteem zoals pipelines, cross-validatie-estimators, datapreprocessors, enzovoort.
Hier is een stapsgewijze gids voor classificatie met GradientBoostingClassifier. We voorspellen de kwaliteit van de cut van diamanten op basis van hun prijs en andere fysieke metingen. Deze dataset is ingebouwd in de Seaborn-bibliotheek.
Pro tip: Gebruik de knop “Explain code” in de DataCamp-codefragmenteditor voor een gedetailleerde uitleg regel voor regel van wat er gebeurt.
1. Libraries importeren
import pandas as pd
import seaborn as sns
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import cross_val_score, train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler2. Data laden
# Load the diamonds dataset from Seaborn
diamonds = sns.load_dataset("diamonds")
# Split data into features and target
X = diamonds.drop("cut", axis=1)
y = diamonds["cut"]3. De data splitsen
# Split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)4. Categorische en numerieke features definiëren
# Define categorical and numerical features
categorical_features = X.select_dtypes(
include=["object"]
).columns.tolist()
numerical_features = X.select_dtypes(
include=["float64", "int64"]
).columns.tolist()5. Voorbewerking voor categorische en numerieke features definiëren
preprocessor = ColumnTransformer(
transformers=[
("cat", OneHotEncoder(), categorical_features),
("num", StandardScaler(), numerical_features),
]
)6. Maak een Gradient Boosting Classifier-pijplijn
pipeline = Pipeline(
[
("preprocessor", preprocessor),
("classifier", GradientBoostingClassifier(random_state=42)),
]
)
7. CV en training
# Perform 5-fold cross-validation
cv_scores = cross_val_score(pipeline, X_train, y_train, cv=5)
# Fit the model on the training data
pipeline.fit(X_train, y_train)
# Predict on the test set
y_pred = pipeline.predict(X_test)
# Generate classification report
report = classification_report(y_test, y_pred)
8. Rapporteer de eindresultaten
print(f"Mean Cross-Validation Accuracy: {cv_scores.mean():.4f}")
print("\nClassification Report:")
print(report)
Mean Cross-Validation Accuracy: 0.7621
Classification Report:
precision recall f1-score support
Fair 0.90 0.91 0.91 335
Good 0.81 0.63 0.71 1004
Ideal 0.82 0.91 0.86 4292
Premium 0.70 0.86 0.77 2775
Very Good 0.66 0.41 0.51 2382
accuracy 0.76 10788
macro avg 0.78 0.74 0.75 10788
weighted avg 0.75 0.76 0.75 10788
De gewogen nauwkeurigheid is 75%, wat niet slecht is voor een basismodel met standaardparameters. Dus, als uitdaging laat ik het aan jou over om de hyperparameters van GradientBoostingClassifier te tunen om boven de 95% prestatie te komen. Ja, het is mogelijk! (Hint: lees de laatste sectie zorgvuldig en bekijk de Scikit-learn-docs voor de classifier).
Conclusie en verder leren
Hoewel we een hoop hebben geleerd, lag de focus van het artikel op de interne werking van het gradient boosting-algoritme. Begrijpen hoe het werkt, betekent niet automatisch dat je het in de praktijk ook goed kunt gebruiken. Toch helpt een intuïtief begrip altijd enorm.
Voor verdere verdieping raad ik de volgende bronnen aan:
- Using Gradient Boosting with XGBoost door DataCamp: #1 gerankt artikel over XGBoost op Google
- Extreme Gradient Boosting With XGBoost Course: een uitgebreide cursus over XGBoost
Bedankt voor het lezen!

