Der Hauptteil dieses Artikels ist lang, aber detailliert, deshalb werden wir die Einleitung so kurz wie möglich halten und direkt mit der Frage beginnen: "Warum sollte man sich mit Gradient Boosting beschäftigen?"
Dafür gibt es eine Reihe von guten Gründen:
- Gradient Boosting ist das Beste: Seine Genauigkeit und Leistung sind bei tabellarischen, überwachten Lernaufgaben unübertroffen.
- Gradient Boosting ist sehr vielseitig: Es kann bei vielen wichtigen Aufgaben wie Regression, Klassifizierung, Ranking und Überlebensanalyse eingesetzt werden.
- Gradient Boosting ist interpretierbar: Im Gegensatz zu Black-Box-Algorithmen wie neuronalen Netzen wird beim Gradient Boosting die Interpretierbarkeit nicht der Leistung geopfert. Es funktioniert wie ein Schweizer Uhrwerk, und mit etwas Geduld kannst du einem Schulkind beibringen, wie es funktioniert.
- Gradient Boosting ist gut implementiert: Es gehört nicht zu den Algorithmen, die wenig praktischen Nutzen haben. Verschiedene Gradient-Boosting-Bibliotheken wie XGBoost und LightGBM in Python werden von Hunderttausenden von Menschen genutzt.
- Gradient Boosting gewinnt: Seit 2015 haben Profis damit immer wieder Tabellenwettbewerbe auf Plattformen wie Kaggle gewonnen.
Wenn einer dieser Punkte auch nur im Entferntesten ansprechend ist, lohnt es sich, diesen Artikel weiterzulesen.
Also, lass uns loslegen!
Was wirst du in diesem Tutorial lernen?
Das Wichtigste an diesem Artikel ist, dass du die Funktionsweise des Gradient Boosting ohne viel mathematisches Kopfzerbrechen verstehst. Schließlich ist Gradient Boosting für den Einsatz in der Praxis gedacht und nicht für die mathematische Analyse.
Was ist Gradient Boosting im Allgemeinen?
Boosting ist eine leistungsstarke Ensemble-Technik beim maschinellen Lernen. Im Gegensatz zu traditionellen Modellen, die unabhängig voneinander aus den Daten lernen, kombiniert Boosting die Vorhersagen mehrerer schwacher Lerner, um einen einzigen, genaueren starken Lerner zu erstellen.
Ich habe gerade einen Haufen neuer Begriffe geschrieben, also lass mich jeden einzelnen erklären, angefangen mit den schwachen Lernenden.
Ein schwacher Lerner ist ein maschinelles Lernmodell, das geringfügig besser ist als ein zufällig erratenes Modell. Nehmen wir zum Beispiel an, wir klassifizieren Pilze in essbar und ungenießbar. Wenn ein Modell, das nach dem Zufallsprinzip rät, eine Genauigkeit von 40 % hat, würde ein schwacher Lerner knapp darüber liegen: 50-60%.
Beim Boosting werden Dutzende oder Hunderte dieser schwachen Lerner kombiniert, um einen starken Lerner mit dem Potenzial für über 95 % Genauigkeit bei demselben Problem zu bilden.
Der beliebteste schwache Lerner ist der Entscheidungsbaum, weil er mit fast jedem Datensatz arbeiten kann. Wenn du dich mit Entscheidungsbäumen nicht auskennst, schau dir das DataCamp-Tutorial zur Klassifizierung von Entscheidungsbäumen an.
Praktische Anwendungen von Gradient Boosting
Gradient Boosting hat sich im Bereich des maschinellen Lernens so stark durchgesetzt, dass es mittlerweile in verschiedenen Branchen eingesetzt wird - von der Vorhersage der Kundenabwanderung bis hin zur Erkennung von Asteroiden. Hier bekommst du einen Einblick in seine Erfolgsgeschichten bei Kaggle und in reale Anwendungsfälle:
Kaggle-Wettbewerbe dominieren:
- Otto Group Product Classification Challenge: Für alle Top-10-Positionen wurde die XGBoost-Implementierung von Gradient Boosting verwendet.
- Santander Kundentransaktionsprognose: XGBoost-basierte Lösungen sicherten sich erneut die Spitzenplätze bei der Vorhersage von Kundenverhalten und finanziellen Transaktionen.
- Netflix Filmempfehlungs-Challenge: Gradient Boosting spielte eine entscheidende Rolle beim Aufbau von Empfehlungssystemen für milliardenschwere Unternehmen wie Netflix.
Wirtschaft und Industrie umgestalten:
- Einzelhandel und E-Commerce: personalisierte Empfehlungen, Bestandsmanagement, Betrugserkennung
- Finanz- und Versicherungswesen: Kreditrisikobewertung, Abwanderungsprognosen, algorithmischer Handel
- Gesundheitswesen und Medizin: Krankheitsdiagnose, Arzneimittelforschung, personalisierte Medizin
- Suche und Online-Werbung: Such-Ranking, Anzeigen-Targeting, Vorhersage der Klickrate
Lass uns also endlich einen Blick unter die Haube dieses legendären Algorithmus werfen!
Der Gradient Boosting Algorithmus: Eine Schritt-für-Schritt-Anleitung
Eingabe
Der Gradient-Boosting-Algorithmus funktioniert für tabellarische Daten mit einer Reihe von Merkmalen (X) und einem Ziel (y). Wie bei anderen Algorithmen des maschinellen Lernens besteht das Ziel darin, aus den Trainingsdaten so viel zu lernen, dass eine gute Generalisierung auf ungesehene Datenpunkte möglich ist.
Um den zugrunde liegenden Prozess des Gradient Boosting zu verstehen, verwenden wir einen einfachen Verkaufsdatensatz mit vier Zeilen. Anhand von drei Merkmalen - Alter des Kunden, Kaufkategorie und Kaufgewicht - wollen wir den Kaufbetrag vorhersagen:
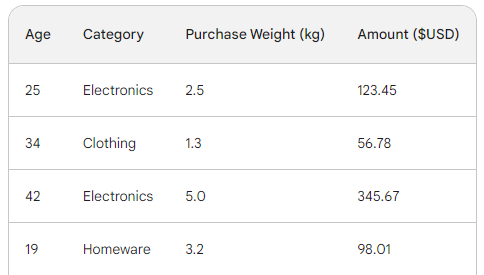
Die Verlustfunktion beim Gradient Boosting
Beim maschinellen Lernen ist eine Verlustfunktion eine wichtige Komponente, mit der wir den Unterschied zwischen den Vorhersagen eines Modells und den tatsächlichen Werten quantifizieren können. Im Wesentlichen misst es, wie ein Modell funktioniert.
Hier ist eine Aufschlüsselung seiner Rolle:
- Berechnet den Fehler: Vergleicht den vorhergesagten Output des Modells mit der Basiswahrheit (tatsächlich beobachtete Werte). Wie er vergleicht, d.h. die Differenz berechnet, ist von Funktion zu Funktion unterschiedlich.
- Führt Modelltraining durch: Das Ziel eines Modells ist es, die Verlustfunktion zu minimieren. Während des Trainings aktualisiert das Modell ständig seine interne Architektur und Konfiguration, um den Verlust so gering wie möglich zu halten.
- Bewertungsmaßstab: Indem du den Verlust in Trainings-, Validierungs- und Testdatensätzen vergleichst, kannst du die Fähigkeit deines Modells zur Generalisierung beurteilen und eine Überanpassung vermeiden.
Die beiden häufigsten Verlustfunktionen sind:
- Mittlerer quadratischer Fehler (MSE): Diese beliebte Verlustfunktion für die Regression misst die Summe der quadratischen Differenzen zwischen vorhergesagten und tatsächlichen Werten. Beim Gradient Boosting wird diese Variante häufig verwendet:
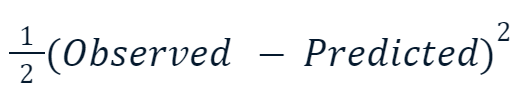
Der Grund, warum der quadrierte Wert mit der Hälfte multipliziert wird, hat mit der Differenzierung zu tun. Wenn wir die Ableitung dieser Verlustfunktion nehmen, hebt sich die eine Hälfte aufgrund der Potenzregel mit dem Quadrat auf. Das Endergebnis wäre also einfach -(Observed - Predicted), was das Rechnen viel einfacher und weniger rechenintensiv macht.
- Kreuzentropie: Diese Funktion misst die Differenz zwischen zwei Wahrscheinlichkeitsverteilungen. Sie wird daher häufig für Klassifizierungsaufgaben verwendet, bei denen die Ziele diskrete Kategorien haben.
Da wir eine Regression durchführen, werden wir den MSE verwenden.
Schritt 1: Mach eine erste Vorhersage
Gradient Boosting ist ein Algorithmus, der seine Genauigkeit schrittweise erhöht. Um den Prozess zu starten, brauchen wir eine erste Schätzung oder Vorhersage. Die erste Schätzung ist immer der Durchschnitt des Ziels. Mit anderen Worten: In der ersten Runde sagt unser Modell voraus, dass alle Käufe gleich hoch waren - 156 Dollar:
![]()
Der Grund für die Wahl des Durchschnitts hat mit der von uns gewählten Verlustfunktion und ihrer Ableitung zu tun. Bei jedem Schritt suchen wir nach einem Wert, um das Minimum der Verlustfunktion zu finden. Mit anderen Worten: Wir suchen nach einem Wert, bei dem die Ableitung (Steigung) der Verlustfunktion 0 ist.
Und wenn wir die Ableitung der Verlustfunktion für jeden beobachteten Wert in Bezug auf den vorhergesagten nehmen und sie zusammenzählen, erhalten wir den Durchschnitt des Ziels.
Unsere erste Vorhersage ist also der Durchschnitt -156 Dollar. Behalte es im Gedächtnis, während wir fortfahren.
Schritt 2: Berechne die Pseudorückstände
Der nächste Schritt besteht darin, die Unterschiede zwischen jedem beobachteten Wert und unserer ursprünglichen Vorhersage zu ermitteln: 156 - Observed. Zur Veranschaulichung fügen wir diese Unterschiede in eine neue Spalte ein:
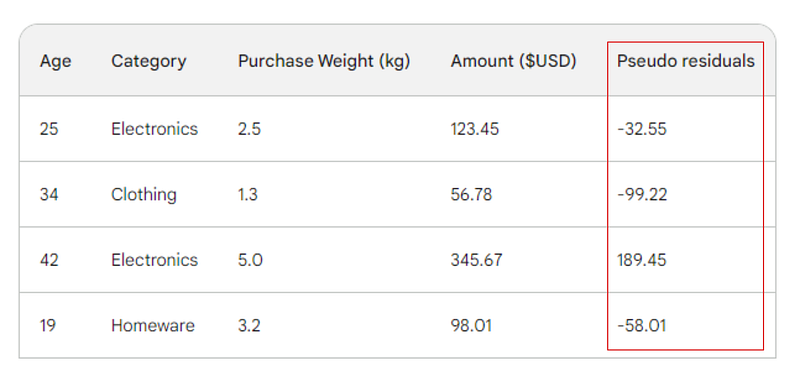
Erinnere dich daran, dass bei der linearen Regression die Differenz zwischen den beobachteten Werten und den vorhergesagten Werten als Residuen bezeichnet wird. Um die lineare Regression und das Gradient Boosting zu unterscheiden, nennen wir sie Pseudo-Residuen (es gibt noch andere Gründe, warum sie so genannt werden, aber wir werden in diesem Artikel nicht darauf eingehen).
Schritt 3: Einen schwachen Lerner aufbauen
Als Nächstes erstellen wir einen Entscheidungsbaum (weak learner), der die Residuen anhand der drei Merkmale (Alter, Kategorie, Kaufgewicht) vorhersagt. Für dieses Problem beschränken wir den Entscheidungsbaum auf nur vier Blätter (Endknoten), aber in der Praxis wählt man normalerweise Blätter zwischen 8 und 32.
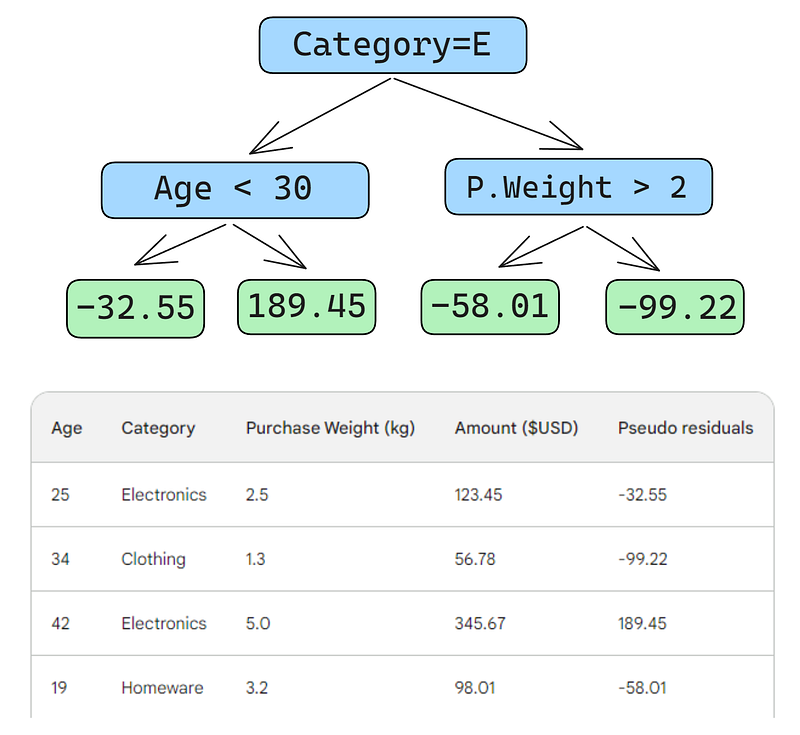
Nachdem der Baum an die Daten angepasst wurde, machen wir eine Vorhersage für jede Zeile in den Daten. Hier siehst du, wie du den ersten Schritt machst:
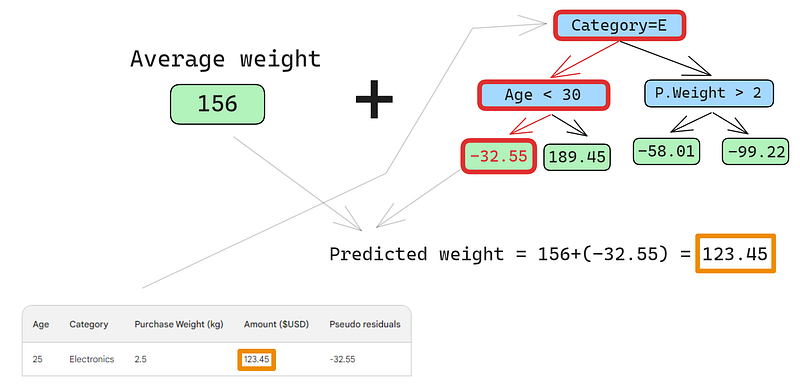
Ein kleiner Fehler in den Bildern unten: Es sollte heißen "Voraussichtlicher Einkaufsbetrag", nicht "Voraussichtliches Gewicht".
Die erste Zeile hat folgende Merkmale: die Kategorie Elektronik (links vom Stammknoten) und das Alter des Kunden unter 30 Jahren (links vom Kindknoten). Dies setzt -32,55 in den Blattknoten. Um die endgültige Vorhersage zu treffen, addieren wir -32,55 zu unserer ersten Vorhersage, was genau dem beobachteten Wert entspricht - 123,45 Dollar!
Wir haben gerade eine perfekte Vorhersage gemacht, also warum sich die Mühe machen, andere Bäume zu bauen? Nun, im Moment passen wir die Trainingsdaten stark übermäßig an. Wir wollen, dass das Modell verallgemeinert. Um dieses Problem zu entschärfen, gibt es beim Gradient Boosting einen Parameter namens Lernrate.
Die Lernrate beim Gradient Boosting ist einfach ein Multiplikator zwischen 0 und 1, der die Vorhersage jedes schwachen Lerners skaliert (Details zur Lernrate findest du im folgenden Abschnitt). Wenn wir eine willkürliche Lernrate von 0,1 in den Mix einbringen, wird unsere Vorhersage 152,75 und nicht die perfekte 123,45.

Lass uns auch die zweite Reihe vorhersagen:
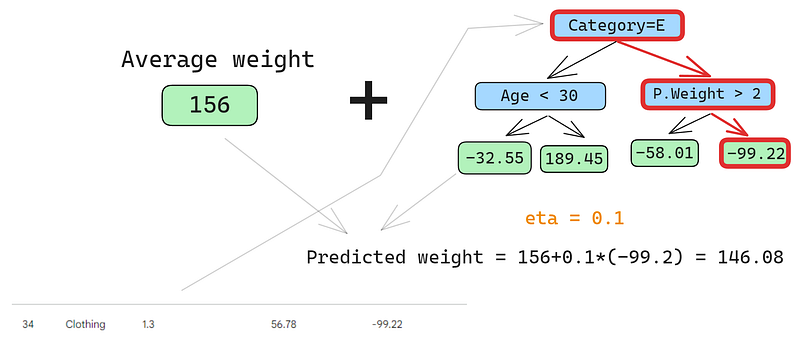
Wir lassen die Zeile durch den Baum laufen und erhalten 146,08 als Vorhersage. So machen wir für alle Zeilen weiter, bis wir vier Vorhersagen für vier Zeilen haben: 152.75, 146.08, 174.945, 150.2. Fügen wir sie erst einmal als neue Spalte hinzu:
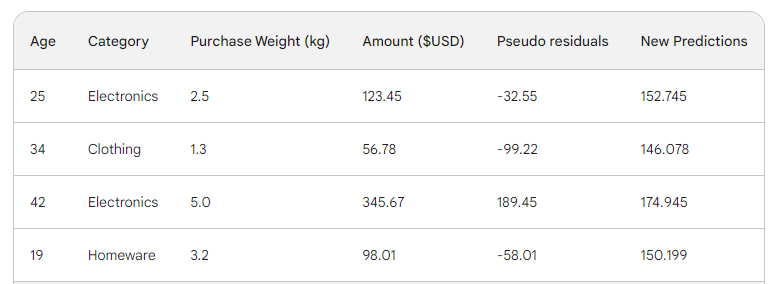
Als Nächstes ermitteln wir die neuen Pseudorückstände, indem wir die neuen Vorhersagen vom Kaufbetrag abziehen. Fügen wir sie als neue Spalte zur Tabelle hinzu und lassen die letzten beiden weg:
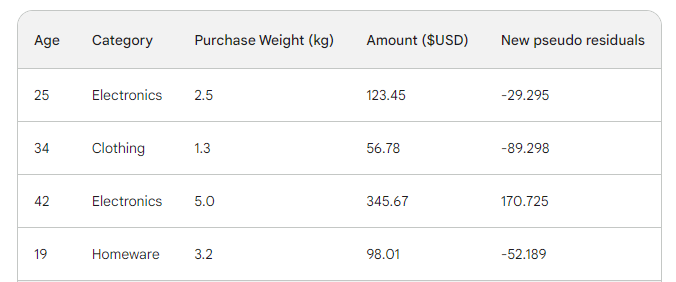
Wie du sehen kannst, sind unsere neuen Pseudo-Residuen kleiner, was bedeutet, dass unser Verlust geringer wird.
Schritt 4: Iterieren
In den nächsten Schritten wiederholen wir Schritt 3, d.h. wir bauen weitere schwache Lernende auf. Das Einzige, was du dir merken musst, ist, dass wir die Residuen jedes Baumes zur ersten Vorhersage addieren müssen, um die nächste zu erstellen.
Wenn wir zum Beispiel 10 Bäume erstellen und die Residuen jedes Baumes als r_i (1 <= i <= 10) bezeichnet werden, würde die nächste Vorhersage p_10 = 156 + eta * (r_1 + r_2 + ... + r_10) werden, wobei p_10 die Vorhersage in der zehnten Runde bezeichnet.
In der Praxis beginnen Fachleute oft mit 100 Bäumen, nicht nur mit 10. In diesem Fall soll der Algorithmus 100 Boosting-Runden lang trainieren.
Wenn du nicht genau weißt, wie viele Bäume du für dein spezielles Problem brauchst, kannst du eine einfache Technik anwenden, die man Early Stopping nennt.
Beim frühen Stoppen wählen wir eine große Anzahl von Bäumen, etwa 1000 oder 10000. Anstatt darauf zu warten, dass der Algorithmus alle Bäume fertig baut, überwachen wir den Verlust. Wenn sich der Verlust nach einer bestimmten Anzahl von Boosting-Runden, z. B. 50, nicht verbessert, brechen wir das Training früher ab und sparen so Zeit und Rechenressourcen.
Konfigurieren von Gradient-Boosting-Modellen
Beim maschinellen Lernen wird die Wahl der Einstellungen für ein Modell als "Hyperparameter-Tuning" bezeichnet. Diese Einstellungen, "Hyperparameter" genannt, sind Optionen, die der Ingenieur für maschinelles Lernen selbst wählen muss. Im Gegensatz zu anderen Parametern kann das Modell die besten Werte für die Hyperparameter nicht einfach durch das Training mit Daten lernen.
Gradient-Boosting-Modelle haben viele Hyperparameter, von denen ich einige im Folgenden erläutern werde.
Zielsetzung
Dieser Parameter legt die Richtung und die Verlustfunktion des Algorithmus fest. Wenn das Ziel die Regression ist, wird MSE als Verlustfunktion gewählt, während für die Klassifizierung die Cross-Entropie die richtige Wahl ist. Python-Bibliotheken wie XGBoost bieten weitere Ziele für andere Aufgabentypen, wie z.B. das Ranking mit entsprechenden Verlustfunktionen.
Lernrate
Der wichtigste Hyperparameter des Gradient Boosting ist vielleicht die Lernrate. Er steuert den Beitrag der einzelnen schwachen Lernenden, indem er den Schrumpfungsfaktor anpasst. Kleinere Werte (gegen 0) verringern das Mitspracherecht jedes schwachen Lerners im Ensemble. Das erfordert mehr Bäume und damit mehr Zeit, um die Ausbildung abzuschließen. Aber der endgültige starke Lerner wird tatsächlich stark und unempfindlich gegen Überanpassung sein.
Die Anzahl der Bäume
Dieser Parameter, der auch als Anzahl der Boosting-Runden oder n_es timators bezeichnet wird, bestimmt die Anzahl der zu bildenden Bäume. Je mehr Bäume du baust, desto stärker und leistungsfähiger wird das Ensemble. Es wird auch komplexer, da das Modell durch mehr Bäume mehr Muster in den Daten erfassen kann. Je mehr Bäume, desto höher ist die Wahrscheinlichkeit einer Überanpassung. Um dies abzumildern, solltest du eine Kombination aus frühem Stoppen und niedriger Lernrate verwenden.
Maximale Tiefe
Dieser Parameter steuert die Anzahl der Ebenen in jedem weak learner (Entscheidungsbaum). Eine maximale Tiefe von 3 bedeutet, dass es drei Ebenen im Baum gibt, wenn man die Blattebene mitzählt. Je tiefer der Baum, desto komplexer und rechenaufwändiger wird das Modell. Wähle einen Wert nahe bei 3, um eine Überanpassung zu vermeiden. Dein Maximum sollte eine Tiefe von 10 sein.
Mindestanzahl von Proben pro Blatt
Dieser Parameter steuert, wie Zweige in Entscheidungsbäumen aufgeteilt werden. Wenn du einen niedrigen Wert für die Anzahl der Stichproben in den Endknoten (Blättern) festlegst, ist der gesamte Algorithmus empfindlich gegenüber Rauschen. Eine größere Mindestanzahl von Stichproben hilft, Overfitting zu verhindern, da es für die Bäume schwieriger ist, Splits auf der Grundlage von zu wenigen Datenpunkten zu erstellen.
Unterabtastrate
Dieser Parameter bestimmt den Anteil der Daten, die zum Trainieren jedes Baums verwendet werden. In den obigen Beispielen haben wir 100% der Zeilen verwendet, da es nur vier Zeilen in unserem Datensatz gab. Aber reale Datensätze haben oft viel mehr und erfordern Stichproben. Wenn du also die Unterabtastungsrate auf einen Wert unter 1 setzt, z. B. 0,7, trainiert jeder schwache Lerner auf den zufällig abgetasteten 70% der Zeilen. Eine kleinere Teilstichprobe kann zu einem schnelleren Training, aber auch zu einer Überanpassung führen.
Merkmal Abtastrate
Dieser Parameter ist genau wie das Subsampling, nur dass er Zeilen abtastet. Bei Datensätzen mit Hunderten von Merkmalen empfiehlt es sich, eine Sampling-Rate zwischen 0,5 und 1 zu wählen, um die Wahrscheinlichkeit einer Überanpassung zu verringern.
Gradient Boosting ist das leistungsfähigste Modell, das wir für tabellarische überwachte Lernaufgaben haben. Meistens musst du dir also keine Sorgen machen, dass sie nicht gut genug für eine Aufgabe ist. Wenn du Gradient Boosting verwendest, verbringst du deine Zeit fast immer damit, es zu regularisieren - seine Leistung zu zähmen, damit es deinen Datensatz nicht einfach verschluckt und unbrauchbar wird, wenn es um ungesehene Daten geht.
Die Hyperparameter, die ich dir vorgestellt habe, helfen dir bei dieser Aufgabe und sind in jeder Implementierung von Gradient Boosting in Python enthalten. Nutze sie gut.
Gradient Boosting in Python implementiert
Wie ich bereits erwähnt habe, ist Gradient Boosting durch Python-Bibliotheken gut etabliert. Hier sind die vier wichtigsten:
- XGBoost: eXtreme Gradient Boosting
- LightGBM: Licht-Gradient-Boosting-Maschine
- CatBoost: Kategorisches Boosting
- Scikit-learn: Hat zwei Schätzer für Regression und Klassifizierung
Die ersten drei Bibliotheken sind einander ähnlich:
- Beherrschende Leistung
- GPU-support
- Reichhaltiger Satz von Hyperparametern (konfigurationsfreundlich)
- Sehr hohe Unterstützung durch die Gemeinschaft
- In der Industrie weit verbreitet
Eine beliebte Alternative zu diesen drei Bibliotheken ist Scikit-learn, das den Nachteil hat, dass es nur auf der CPU läuft. Da Gradient Boosting ein sehr rechenintensiver Algorithmus ist, kann es bei großen Datensätzen (wir sprechen hier von Hunderttausenden von Zeilen) unpraktikabel sein, ihn auf einer CPU auszuführen.
Wir dürfen aber nicht vergessen, dass Scikit-learn allein schon beliebter ist als die drei Bibliotheken zusammen. Neben den beiden Gradient-Boosting-Schätzern für Klassifizierung und Regression bietet Scikit-learn Dutzende anderer Modelle für eine Vielzahl von überwachten und nicht überwachten Lernaufgaben.
Außerdem können mit Scikit-learn erstellte Gradient-Boosting-Modelle in das reichhaltige Ökosystem von Scikit-learn integriert werden, z. B. in Pipelines, Cross-Validation-Schätzer, Datenprozessoren usw.
Hier ist eine Schritt-für-Schritt-Anleitung, wie du mit GradientBoostingClassifier klassifizieren kannst. Wir sagen die Schliffqualität von Diamanten auf der Grundlage ihres Preises und anderer physischer Maße voraus. Dieser Datensatz ist in der Seaborn-Bibliothek enthalten.
Profi-Tipp: Benutze die Schaltfläche "Code erklären" im DataCamp Code-Snippets-Editor, um eine detaillierte, zeilenweise Erklärung zu erhalten, was passiert.
1. Bibliotheken importieren
import pandas as pd
import seaborn as sns
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import cross_val_score, train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler2. Daten laden
# Load the diamonds dataset from Seaborn
diamonds = sns.load_dataset("diamonds")
# Split data into features and target
X = diamonds.drop("cut", axis=1)
y = diamonds["cut"]3. Die Daten aufteilen
# Split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)4. Definiere kategorische und numerische Merkmale
# Define categorical and numerical features
categorical_features = X.select_dtypes(
include=["object"]
).columns.tolist()
numerical_features = X.select_dtypes(
include=["float64", "int64"]
).columns.tolist()5. Definiere Vorverarbeitungsschritte für kategoriale und numerische Merkmale
preprocessor = ColumnTransformer(
transformers=[
("cat", OneHotEncoder(), categorical_features),
("num", StandardScaler(), numerical_features),
]
)6. Erstellen einer Gradient-Boosting-Klassifikator-Pipeline
pipeline = Pipeline(
[
("preprocessor", preprocessor),
("classifier", GradientBoostingClassifier(random_state=42)),
]
)
7. Lebenslauf und Ausbildung
# Perform 5-fold cross-validation
cv_scores = cross_val_score(pipeline, X_train, y_train, cv=5)
# Fit the model on the training data
pipeline.fit(X_train, y_train)
# Predict on the test set
y_pred = pipeline.predict(X_test)
# Generate classification report
report = classification_report(y_test, y_pred)
8. Berichte die Endergebnisse
print(f"Mean Cross-Validation Accuracy: {cv_scores.mean():.4f}")
print("\nClassification Report:")
print(report)
Mean Cross-Validation Accuracy: 0.7621
Classification Report:
precision recall f1-score support
Fair 0.90 0.91 0.91 335
Good 0.81 0.63 0.71 1004
Ideal 0.82 0.91 0.86 4292
Premium 0.70 0.86 0.77 2775
Very Good 0.66 0.41 0.51 2382
accuracy 0.76 10788
macro avg 0.78 0.74 0.75 10788
weighted avg 0.75 0.76 0.75 10788
Die gewichtete Genauigkeit beträgt 75%, was für ein Basismodell mit Standardparametern nicht schlecht ist. Ich überlasse es also dir, die Hyperparameter des GradientBoostingClassifier so einzustellen, dass du eine Leistung von über 95 % erreichst. Ja, es ist möglich! (Tipp: Lies den letzten Abschnitt aufmerksam durch und sieh dir die Scikit-learn-Dokumente für den Klassifikator an).
Fazit und weiteres Lernen
Auch wenn wir eine Menge gelernt haben, lag der Schwerpunkt des Artikels auf der Funktionsweise des Gradient-Boosting-Algorithmus. Wenn du verstehst, wie es funktioniert, heißt das noch lange nicht, dass du es auch in der Praxis gut anwenden kannst. Aber intuitives Verständnis ist immer eine große Hilfe.
Zum Weiterlernen empfehle ich die folgenden Ressourcen:
- Gradient Boosting mit XGBoost von DataCamp: #Platz 1 der Artikel über XGBoost bei Google
- Extreme Gradient Boosting mit XGBoost Kurs: Ein umfassender Kurs über XGBoost
Danke fürs Lesen!


