Le corps de cet article est long mais détaillé, nous allons donc rendre l'introduction aussi courte que possible, en commençant directement par la question "Pourquoi s'embêter avec le gradient boosting ?".
Il y a plusieurs excellentes raisons à cela :
- Le renforcement du gradient est le meilleur: sa précision et ses performances sont inégalées pour les tâches d'apprentissage supervisé tabulaire.
- Le boosting de gradient est très polyvalent: il peut être utilisé dans de nombreuses tâches importantes telles que la régression, la classification, le classement et l'analyse de survie.
- L'amplification du gradient est interprétable: contrairement aux algorithmes de boîte noire tels que les réseaux neuronaux, l'amplification du gradient ne sacrifie pas l'interprétabilité à la performance. Il fonctionne comme une montre suisse et pourtant, avec de la patience, vous pouvez apprendre son fonctionnement à un écolier.
- Le renforcement du gradient est bien mis en œuvre: il ne s'agit pas d'un de ces algorithmes qui n'ont que peu de valeur pratique. Diverses bibliothèques de gradient boosting comme XGBoost et LightGBM en Python sont utilisées par des centaines de milliers de personnes.
- Le gradient boosting gagne: depuis 2015, les professionnels l'ont utilisé pour gagner régulièrement des compétitions tabulaires sur des plateformes comme Kaggle.
Si l'un de ces points vous intéresse, ne serait-ce que de loin, cela vaut la peine de continuer à lire cet article.
Alors, c'est parti !
Qu'allez-vous apprendre dans ce tutoriel ?
L'essentiel de cet article est que vous en sortiez avec une très bonne compréhension du fonctionnement interne de l'augmentation de gradient sans trop de casse-tête mathématique. Après tout, le renforcement du gradient est destiné à être utilisé dans la pratique et non à être analysé mathématiquement.
Qu'est-ce que le renforcement du gradient en général ?
Le boosting est une technique d'ensemble puissante dans le domaine de l'apprentissage automatique. Contrairement aux modèles traditionnels qui apprennent indépendamment des données, le boosting combine les prédictions de plusieurs apprenants faibles pour créer un apprenant fort unique et plus précis.
Je viens d'écrire un tas de nouveaux termes, alors laissez-moi expliquer chacun d'entre eux, en commençant par les apprenants faibles.
Un apprenant faible est un modèle d'apprentissage automatique qui est légèrement meilleur qu'un modèle de devinettes aléatoires. Par exemple, disons que nous classons les champignons en comestibles et non comestibles. Si un modèle de devinettes aléatoires a une précision de 40 %, un apprenant faible se situerait juste au-dessus : 50-60%.
Le boosting combine des dizaines ou des centaines de ces apprenants faibles pour construire un apprenant fort avec un potentiel de précision de plus de 95 % sur le même problème.
L'apprenant faible le plus répandu est un arbre de décision, choisi pour sa capacité à travailler avec presque tous les ensembles de données. Si vous n'êtes pas familier avec les arbres de décision, consultez ce tutoriel de DataCamp sur la classification par arbre de décision.
Applications concrètes du renforcement du gradient
Le renforcement du gradient est devenu une telle force dominante dans l'apprentissage automatique que ses applications s'étendent désormais à divers secteurs, de la prédiction du désabonnement des clients à la détection des astéroïdes. Voici un aperçu de ses succès dans Kaggle et de ses cas d'utilisation dans le monde réel :
Dominer les compétitions Kaggle :
- Défi de classification des produits du groupe Otto: toutes les 10 premières positions ont utilisé l'implémentation XGBoost du gradient boosting.
- Prévisions de transactions des clients de Santander: Les solutions basées sur XGBoost ont à nouveau obtenu les meilleures places pour prédire le comportement des clients et les transactions financières.
- Défi de recommandation de films Netflix: Le gradient boosting a joué un rôle crucial dans l'élaboration de systèmes de recommandation pour des entreprises multimilliardaires comme Netflix.
Transformer les entreprises et l'industrie :
- Commerce de détail et commerce électronique: recommandations personnalisées, gestion des stocks, détection des fraudes
- Finance et assurance: évaluation du risque de crédit, prédiction du taux de désabonnement, trading algorithmique
- Soins de santé et médecine: diagnostic des maladies, découverte de médicaments, médecine personnalisée
- Recherche et publicité en ligne: classement des recherches, ciblage des annonces, prédiction du taux de clics
Alors, jetons enfin un coup d'œil sous le capot de cet algorithme légendaire !
L'algorithme de renforcement du gradient : Un guide pas à pas
Entrée
L'algorithme de renforcement du gradient fonctionne pour les données tabulaires avec un ensemble de caractéristiques (X) et une cible (y). Comme d'autres algorithmes d'apprentissage automatique, l'objectif est de tirer suffisamment d'enseignements des données d'apprentissage pour pouvoir les généraliser à des points de données inédits.
Pour comprendre le processus sous-jacent du renforcement du gradient, nous utiliserons un simple ensemble de données de vente comportant quatre lignes. En utilisant trois caractéristiques - l'âge du client, la catégorie d'achat et le poids de l'achat - nous voulons prédire le montant de l'achat :
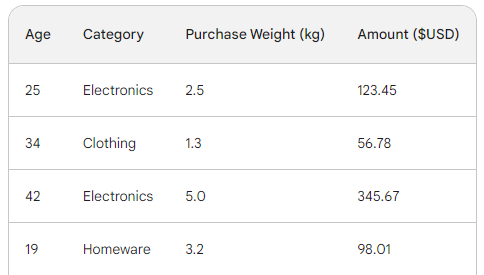
La fonction de perte dans le renforcement du gradient
Dans l'apprentissage automatique, une fonction de perte est un élément essentiel qui nous permet de quantifier la différence entre les prédictions d'un modèle et les valeurs réelles. Essentiellement, il mesure la performance d'un modèle.
Voici un aperçu de son rôle :
- Calcule l'erreur : Prend la sortie prédite du modèle et la compare à la vérité de terrain (valeurs réelles observées). La façon dont il compare, c'est-à-dire calcule la différence, varie d'une fonction à l'autre.
- Formation de modèles de guides: l'objectif d'un modèle est de minimiser la fonction de perte. Tout au long de la formation, le modèle met continuellement à jour son architecture interne et sa configuration afin de réduire au maximum les pertes.
- Mesure d'évaluation: En comparant la perte sur les ensembles de données de formation, de validation et de test, vous pouvez évaluer la capacité de votre modèle à se généraliser et à éviter l'adaptation excessive.
Les deux fonctions de perte les plus courantes sont les suivantes :
- Erreur quadratique moyenne (EQM): Cette fonction de perte populaire pour la régression mesure la somme des différences au carré entre les valeurs prédites et les valeurs réelles. Le renforcement du gradient utilise souvent cette variante :
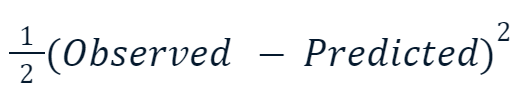
La raison pour laquelle la valeur au carré est multipliée par la moitié est liée à la différenciation. Lorsque nous prenons la dérivée de cette fonction de perte, la moitié s'annule avec le carré en raison de la règle de puissance. Le résultat final serait donc simplement -(Observed - Predicted), ce qui rend les calculs beaucoup plus faciles et moins coûteux.
- L'entropie croisée: Cette fonction mesure la différence entre deux distributions de probabilité. Elle est donc couramment utilisée pour les tâches de classification dans lesquelles les cibles ont des catégories discrètes.
Puisque nous effectuons une régression, nous utiliserons l'EQM.
Étape 1 : Faire une première prédiction
Le renforcement du gradient est un algorithme qui augmente progressivement sa précision. Pour démarrer le processus, nous avons besoin d'une première estimation ou prédiction. L'estimation initiale est toujours la moyenne de la cible. En d'autres termes, pour le premier tour, notre modèle prédit que tous les achats sont identiques - 156 dollars :
![]()
La raison du choix de la moyenne est liée à la fonction de perte que nous avons choisie et à sa dérivée. À chaque étape, nous recherchons une valeur pour trouver le minimum de la fonction de perte. En d'autres termes, nous recherchons une valeur qui fait que la dérivée (gradient) de la fonction de perte est égale à 0.
Et lorsque nous prenons la dérivée de la fonction de perte pour chaque valeur observée par rapport à la valeur prédite et que nous les additionnons, nous obtenons la moyenne de la cible.
Notre prévision initiale est donc la moyenne -156 dollars. Gardez-le en mémoire pendant que nous continuons.
Étape 2 : Calculer les pseudo-résidus
L'étape suivante consiste à trouver les différences entre chaque valeur observée et notre prédiction initiale : 156 - Observed. À titre d'illustration, nous placerons ces différences dans une nouvelle colonne :
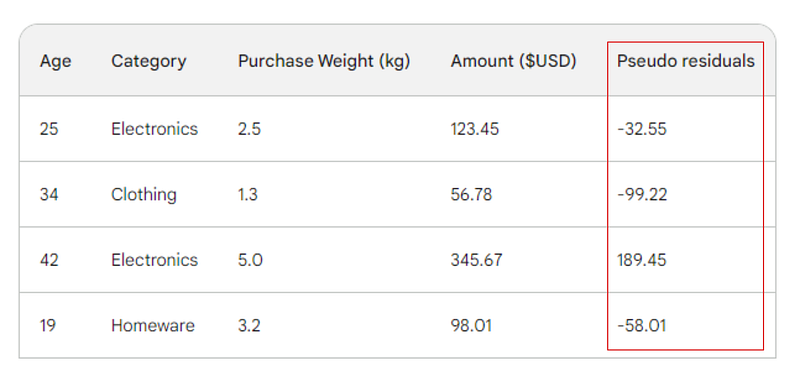
Rappelez-vous que dans la régression linéaire, la différence entre les valeurs observées et les valeurs prédites est appelée résidus. Pour différencier la régression linéaire et le gradient boosting, nous les appelons pseudo-résidus (il y a d'autres raisons pour lesquelles ils sont nommés ainsi, mais nous n'y reviendrons pas dans cet article).
Étape 3 : Construire un apprenant faible
Ensuite, nous construirons un arbre de décision (apprenant faible) qui prédit les résidus en utilisant les trois caractéristiques dont nous disposons (âge, catégorie, poids de l'achat). Pour ce problème, nous limiterons l'arbre de décision à quatre feuilles (nœuds terminaux), mais dans la pratique, les gens choisissent généralement des feuilles entre 8 et 32.
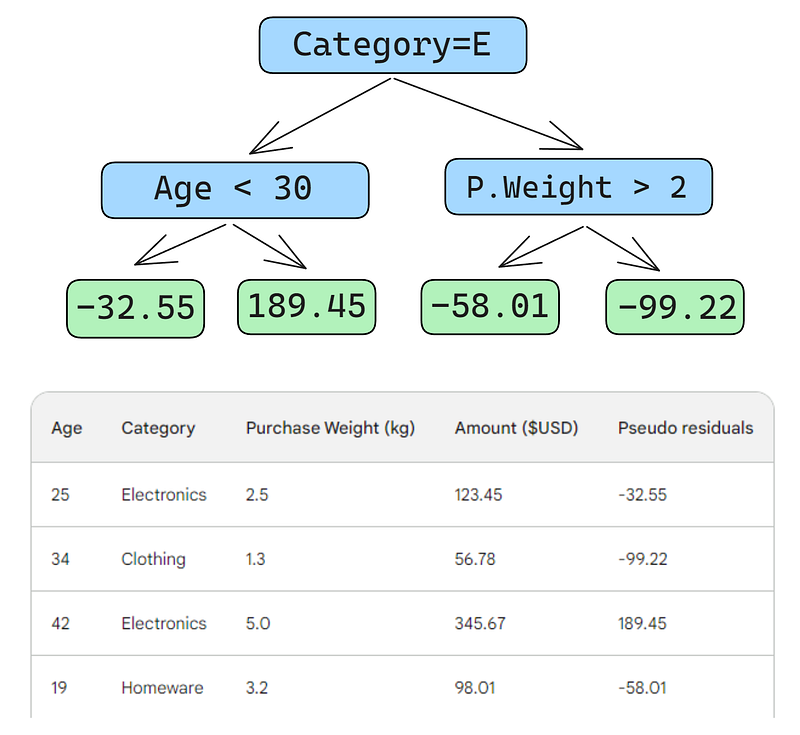
Une fois l'arbre adapté aux données, nous faisons une prédiction pour chaque ligne des données. Voici comment faire le premier :
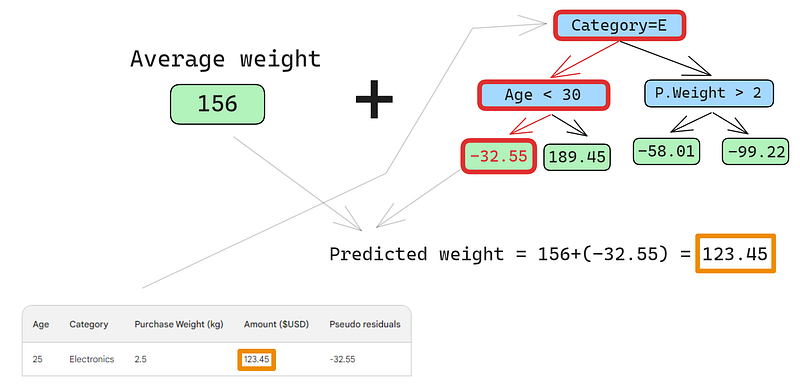
Une petite erreur dans les images ci-dessous : il aurait fallu écrire "Montant d'achat prédit", et non "Poids prédit"
La première ligne présente les caractéristiques suivantes : une catégorie de produits électroniques (à gauche du nœud racine) et un client âgé de moins de 30 ans (à gauche du nœud enfant). Cela place -32,55 dans le nœud feuille. Pour obtenir la prédiction finale, nous ajoutons -32,55 à notre première prédiction, qui est exactement la même que la valeur observée - 123,45 dollars !
Nous venons de faire une prédiction parfaite, alors pourquoi s'embêter à construire d'autres arbres ? Pour l'instant, nous surajoutons fortement les données d'apprentissage. Nous voulons que le modèle se généralise. Ainsi, pour atténuer ce problème, le renforcement du gradient dispose d'un paramètre appelé taux d'apprentissage.
Le taux d'apprentissage dans le cadre du renforcement du gradient est simplement un multiplicateur compris entre 0 et 1 qui permet d'échelonner la prédiction de chaque apprenant faible (voir la section ci-dessous pour plus de détails sur le taux d'apprentissage). Si nous ajoutons un taux d'apprentissage arbitraire de 0,1, notre prédiction devient 152,75, et non 123,45 comme prévu.

Prévoyons également sur la deuxième ligne :
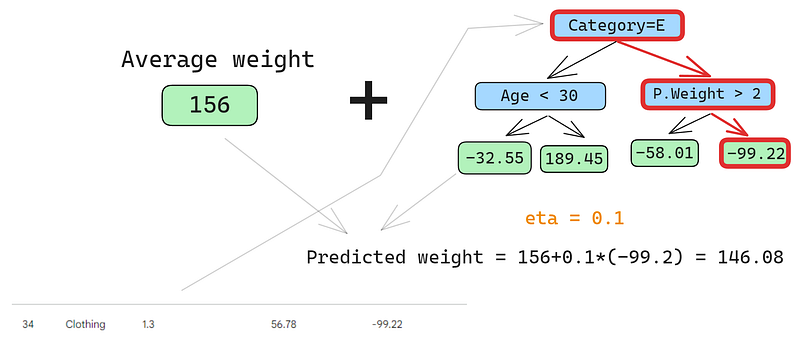
Nous passons la ligne dans l'arbre et obtenons 146,08 comme prédiction. Nous continuons ainsi pour toutes les lignes jusqu'à ce que nous ayons quatre prédictions pour quatre lignes : 152.75, 146.08, 174.945, 150.2. Ajoutons-les dans une nouvelle colonne pour l'instant :
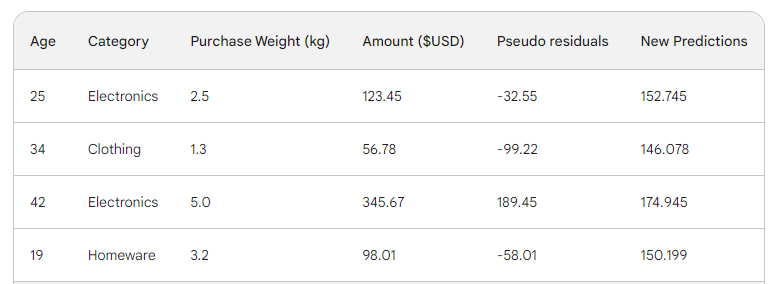
Ensuite, nous trouvons les nouveaux pseudo-résidus en soustrayant les nouvelles prédictions du montant de l'achat. Ajoutons-les en tant que nouvelle colonne au tableau et supprimons les deux dernières :
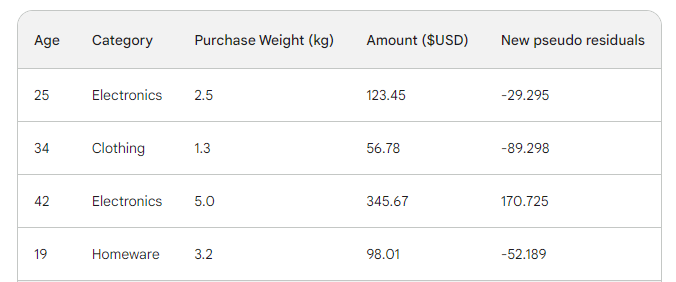
Comme vous pouvez le constater, nos nouveaux pseudo-résidus sont plus petits, ce qui signifie que notre perte diminue.
Étape 4 : Itérer
Dans les étapes suivantes, nous itérons sur l'étape 3, c'est-à-dire que nous construisons davantage d'apprenants faibles. La seule chose à retenir est que nous devons continuer à ajouter les résidus de chaque arbre à la prédiction initiale pour générer le suivant.
Par exemple, si nous construisons 10 arbres et que les résidus de chaque arbre sont désignés par r_i (1 <= i <= 10), la prédiction suivante deviendra p_10 = 156 + eta * (r_1 + r_2 + ... + r_10) où p_10 désigne la prédiction au dixième tour.
Dans la pratique, les professionnels commencent souvent avec 100 arbres, et pas seulement 10. Dans ce cas, on dit que l'algorithme s'entraîne pendant 100 cycles de stimulation.
Si vous ne connaissez pas le nombre exact d'arbres dont vous avez besoin pour votre problème spécifique, vous pouvez utiliser une technique simple appelée arrêt anticipé.
Lors des premiers arrêts, nous choisissons un grand nombre d'arbres, comme 1000 ou 10000. Ensuite, au lieu d'attendre que l'algorithme ait fini de construire tous ces arbres, nous surveillons la perte. Si la perte ne s'améliore pas après un certain nombre de tours de stimulation, par exemple 50, nous arrêtons la formation plus tôt, ce qui permet d'économiser du temps et des ressources de calcul.
Configuration des modèles de boosting de gradient
Dans le domaine de l'apprentissage automatique, le choix des paramètres d'un modèle est appelé "réglage des hyperparamètres". Ces paramètres, appelés "hyperparamètres", sont des options que l'ingénieur en apprentissage automatique doit choisir lui-même. Contrairement à d'autres paramètres, le modèle ne peut pas apprendre les meilleures valeurs pour les hyperparamètres simplement en étant entraîné sur des données.
Les modèles de gradient boosting disposent de nombreux hyperparamètres, dont certains sont décrits ci-dessous.
Objectif
Ce paramètre définit la direction et la fonction de perte de l'algorithme. Si l'objectif est la régression, la fonction de perte MSE est choisie, tandis que pour la classification, c'est l'entropie croisée qui est retenue. Les bibliothèques Python comme XGBoost proposent d'autres objectifs pour d'autres types de tâches, comme le classement avec les fonctions de perte correspondantes.
Taux d'apprentissage
L'hyperparamètre le plus important du renforcement du gradient est sans doute le taux d'apprentissage. Il contrôle la contribution de chaque apprenant faible en ajustant le facteur de réduction. Des valeurs plus faibles (vers 0) diminuent le poids de chaque apprenant faible dans l'ensemble. Cela nécessite la construction d'un plus grand nombre d'arbres et donc plus de temps pour terminer la formation. Mais l'apprenant fort final sera effectivement fort et imperméable à l'adaptation excessive.
Le nombre d'arbres
Ce paramètre, également appelé nombre de tours de stimulation ou n_es timators, contrôle le nombre d'arbres à construire. Plus vous construisez d'arbres, plus l'ensemble devient solide et performant. Il devient également plus complexe, car un plus grand nombre d'arbres permet au modèle de saisir davantage de modèles dans les données. Cependant, un plus grand nombre d'arbres augmente considérablement les risques de surajustement. Pour atténuer ce phénomène, vous pouvez combiner un arrêt précoce et un faible taux d'apprentissage.
Profondeur maximale
Ce paramètre contrôle le nombre de niveaux de chaque apprenant faible (arbre de décision). Une profondeur maximale de 3 signifie qu'il y a trois niveaux dans l'arbre, en comptant le niveau de la feuille. Plus l'arbre est profond, plus le modèle est complexe et coûteux en calculs. Choisissez une valeur proche de 3 pour éviter un surajustement. Votre maximum devrait être une profondeur de 10.
Nombre minimum d'échantillons par feuille
Ce paramètre contrôle la manière dont les branches se divisent dans les arbres de décision. La fixation d'une valeur faible pour le nombre d'échantillons dans les nœuds de terminaison (feuilles) rend l'algorithme global sensible au bruit. Un nombre minimum d'échantillons plus élevé permet d'éviter l'ajustement excessif en empêchant les arbres de créer des scissions sur la base d'un nombre insuffisant de points de données.
Taux de sous-échantillonnage
Ce paramètre contrôle la proportion des données utilisées pour former chaque arbre. Dans les exemples ci-dessus, nous avons utilisé 100 % des lignes car il n'y avait que quatre lignes dans notre ensemble de données. Cependant, les ensembles de données du monde réel sont souvent beaucoup plus nombreux et nécessitent un échantillonnage. Ainsi, si vous fixez le taux de sous-échantillonnage à une valeur inférieure à 1, par exemple 0,7, chaque apprenant faible s'entraîne sur un échantillon aléatoire de 70 % des lignes. Un taux de sous-échantillon plus faible peut conduire à une formation plus rapide, mais aussi à un surajustement.
Taux d'échantillonnage des caractéristiques
Ce paramètre est exactement comme le sous-échantillonnage, mais il échantillonne des lignes. Pour les ensembles de données comportant des centaines de caractéristiques, il est recommandé de choisir un taux d'échantillonnage des caractéristiques compris entre 0,5 et 1 afin de réduire le risque de surajustement.
Le gradient boosting est le modèle le plus performant dont nous disposons pour les tâches d'apprentissage supervisé tabulaire. La plupart du temps, vous n'avez donc pas à craindre qu'il ne soit pas assez performant pour une tâche donnée. Lorsque vous utilisez le renforcement du gradient, vous consacrez presque toujours du temps à la régularisation de ce processus, c'est-à-dire à l'apprivoiser afin qu'il n'engloutisse pas votre ensemble de données et ne devienne pas inutile lorsqu'il s'agit de données inédites.
Les hyperparamètres que j'ai présentés vous aident tous dans cette tâche et ils sont inclus dans chaque implémentation du gradient boosting en Python. Utilisez-les à bon escient.
Boosting de gradient implémenté en Python
Comme je l'ai déjà mentionné, le gradient boosting est bien établi grâce aux bibliothèques Python. Voici les quatre principaux :
- XGBoosteXtreme Gradient Boosting : renforcement du gradient de l'extrême
- LightGBM: Machine à renforcer le gradient de lumière
- CatBoost: Renforcement catégorique
- Scikit-learn: Dispose de deux estimateurs pour la régression et la classification
Les trois premières bibliothèques sont similaires :
- Performance dominante
- Prise en charge du GPU
- Un ensemble riche d'hyperparamètres (facile à configurer)
- Soutien communautaire très élevé
- Largement utilisé dans l'industrie
Une alternative populaire à ces trois bibliothèques est Scikit-learn, qui présente l'inconvénient de n'utiliser que l'unité centrale. Le renforcement du gradient étant un algorithme à forte capacité de calcul, son exécution sur une unité centrale pourrait s'avérer impossible pour les grands ensembles de données (nous parlons ici de centaines de milliers de lignes).
Cependant, nous devons nous rappeler que Scikit-learn, à elle seule, est plus populaire que les trois bibliothèques réunies. Outre les deux estimateurs de gradient boosting pour la classification et la régression, Scikit-learn propose des dizaines d'autres modèles pour une myriade de tâches d'apprentissage supervisé et non supervisé.
En outre, les modèles de gradient boosting construits avec Scikit-learn peuvent être intégrés dans son riche écosystème comme les pipelines, les estimateurs de validation croisée, les processeurs de données, etc.
Voici un guide étape par étape sur la manière d'effectuer une classification avec GradientBoostingClassifier. Nous prévoyons la qualité de la taille des diamants sur la base de leur prix et d'autres mesures physiques. Cet ensemble de données est intégré à la bibliothèque Seaborn.
Conseil de pro: Utilisez le bouton "Expliquer le code" de l'éditeur d'extraits de code de DataCamp pour obtenir une explication détaillée ligne par ligne de ce qui se passe.
1. Importer des bibliothèques
import pandas as pd
import seaborn as sns
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import cross_val_score, train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler2. Données de chargement
# Load the diamonds dataset from Seaborn
diamonds = sns.load_dataset("diamonds")
# Split data into features and target
X = diamonds.drop("cut", axis=1)
y = diamonds["cut"]3. Diviser les données
# Split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)4. Définir les caractéristiques catégorielles et numériques
# Define categorical and numerical features
categorical_features = X.select_dtypes(
include=["object"]
).columns.tolist()
numerical_features = X.select_dtypes(
include=["float64", "int64"]
).columns.tolist()5. Définir les étapes de prétraitement pour les caractéristiques catégorielles et numériques
preprocessor = ColumnTransformer(
transformers=[
("cat", OneHotEncoder(), categorical_features),
("num", StandardScaler(), numerical_features),
]
)6. Créez un pipeline de classification Gradient Boosting
pipeline = Pipeline(
[
("preprocessor", preprocessor),
("classifier", GradientBoostingClassifier(random_state=42)),
]
)
7. CV et formation
# Perform 5-fold cross-validation
cv_scores = cross_val_score(pipeline, X_train, y_train, cv=5)
# Fit the model on the training data
pipeline.fit(X_train, y_train)
# Predict on the test set
y_pred = pipeline.predict(X_test)
# Generate classification report
report = classification_report(y_test, y_pred)
8. Rapport sur les résultats finaux
print(f"Mean Cross-Validation Accuracy: {cv_scores.mean():.4f}")
print("\nClassification Report:")
print(report)
Mean Cross-Validation Accuracy: 0.7621
Classification Report:
precision recall f1-score support
Fair 0.90 0.91 0.91 335
Good 0.81 0.63 0.71 1004
Ideal 0.82 0.91 0.86 4292
Premium 0.70 0.86 0.77 2775
Very Good 0.66 0.41 0.51 2382
accuracy 0.76 10788
macro avg 0.78 0.74 0.75 10788
weighted avg 0.75 0.76 0.75 10788
La précision pondérée est de 75 %, ce qui n'est pas mal pour un modèle de base avec des paramètres par défaut. Je vous laisse donc le soin d'ajuster les hyperparamètres du GradientBoostingClassifier pour obtenir une performance supérieure à 95 %. Oui, c'est possible ! (Conseil: lisez attentivement la dernière section et consultez la documentation Scikit-learn pour le classificateur).
Conclusion et formation continue
Même si nous avons appris beaucoup de choses, l'article portait principalement sur le fonctionnement interne de l'algorithme de renforcement du gradient. Comprendre son fonctionnement ne signifie pas être capable de l'utiliser correctement dans la pratique. Cependant, la compréhension intuitive est toujours une aide précieuse.
Pour en savoir plus, je vous recommande les ressources suivantes :
- Utiliser le Gradient Boosting avec XGBoost par DataCamp: #Article n°1 sur XGBoost sur Google
- Boosting de gradient extrême avec le cours XGBoost: Un cours complet sur XGBoost
Merci de votre lecture !


