The body of this article is long but detailed, so we will make the introduction as short as possible, directly starting with the question, “Why bother with gradient boosting?”
There are a number of excellent reasons:
- Gradient boosting is the best: its accuracy and performance are unmatched for tabular supervised learning tasks.
- Gradient boosting is highly versatile: it can be used in many important tasks such as regression, classification, ranking, and survival analysis.
- Gradient boosting is interpretable: unlike black-box algorithms like neural networks, gradient boosting does not sacrifice interpretability for performance. It works like a Swiss watch and yet, with patience, you can teach how it works to a school kid.
- Gradient boosting is well-implemented: it is not one of those algorithms that have little practical value. Various gradient boosting libraries like XGBoost and LightGBM in Python are used by hundreds of thousands of people.
- Gradient boosting wins: since 2015, professionals have used it to consistently win tabular competitions on platforms like Kaggle.
If any of these points are even remotely appealing, it's worth continuing to read this article.
So, let’s get started!
What Will You Learn in This Tutorial?
The most important takeaway of this article is that you leave with a very firm grasp of the inner workings of gradient boosting without much mathematical headache. After all, gradient boosting is for usage in practice not for analyzing mathematically.
What is Gradient Boosting in General?
Boosting is a powerful ensemble technique in machine learning. Unlike traditional models that learn from the data independently, boosting combines the predictions of multiple weak learners to create a single, more accurate strong learner.
I just wrote a bunch of new terms, so let me explain each, starting with weak learners.
A weak learner is a machine learning model that is slightly better than a random guessing model. For example, let’s say we are classifying mushrooms into edible and inedible. If a random guessing model is 40% accurate, a weak learner would be just above that: 50-60%.
Boosting combines dozens or hundreds of these weak learners to build a strong learner with the potential for over 95% accuracy on the same problem.
The most popular weak learner is a decision tree, chosen for their ability to work with almost any dataset. If you are not familiar with decision trees, check out this DataCamp Decision Tree Classification tutorial.
Real-World Applications of Gradient Boosting
Gradient boosting has become such a dominant force in machine learning that its applications now span various industries, from predicting customer churn to detecting asteroids. Here’s a glimpse into its success stories in Kaggle and real-world use cases:
Dominating Kaggle competitions:
- Otto Group Product Classification Challenge: all top 10 positions used XGBoost implementation of gradient boosting.
- Santander Customer Transaction Prediction: XGBoost-based solutions again secured the top spots for predicting customer behavior and financial transactions.
- Netflix Movie Recommendation Challenge: Gradient boosting played a crucial role in building recommendation systems for multi-billion companies like Netflix.
Transforming business and industry:
- Retail and e-commerce: personalized recommendations, inventory management, fraud detection
- Finance and insurance: credit risk assessment, churn prediction, algorithmic trading
- Healthcare and medicine: disease diagnosis, drug discovery, personalized medicine
- Search and online advertising: search ranking, ad targeting, click-through rate prediction
So, let’s finally peek under the hood of this legendary algorithm!
The Gradient Boosting Algorithm: A Step-by-Step Guide
Input
Gradient boosting algorithm works for tabular data with a set of features (X) and a target (y). Like other machine learning algorithms, the aim is to learn enough from the training data to generalize well to unseen data points.
To understand the underlying process of gradient boosting, we will use a simple sales dataset with four rows. Using three features — customer age, purchase category, and purchase weight, we want to predict the purchase amount:
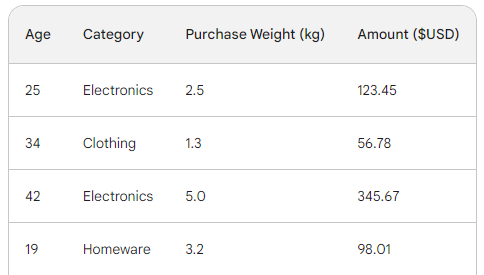
The loss function in gradient boosting
In machine learning, a loss function is a critical component that lets us quantify the difference between a model’s predictions and the actual values. In essence, it measures how a model is performing.
Here is a breakdown of its role:
- Calculates the error: Takes the predicted output of the model and compares it to the ground truth (actual observed values). How it compares, i.e., calculates the difference, varies from function to function.
- Guides model training: a model’s objective is to minimize the loss function. Throughout training, the model continually updates its internal architecture and configuration to make the loss as little as possible.
- Evaluation metric: By comparing the loss on training, validation, and test datasets, you can assess your model’s ability to generalize and avoid overfitting.
The two most common loss functions are:
- Mean Squared Error (MSE): This popular loss function for regression measures the sum of the squared differences between predicted and actual values. Gradient boosting often uses this variation of it:
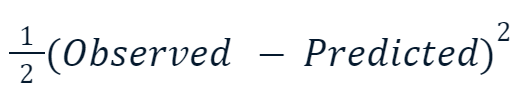
The reason the squared value is multiplied by one-half has got to do with differentiation. When we take the derivative of this loss function, one-half cancels out with the square because of the power rule. So, the final result would just be -(Observed - Predicted), making math much easier and less computationally expensive.
- Cross-entropy: This function measures the difference between two probability distributions. So, it is commonly used for classification tasks where the targets has discrete categories.
Since we are doing regression, we will use MSE.
Step 1: Make an initial prediction
Gradient boosting is an algorithm that gradually increases its accuracy. To start the process, we need an initial guess or prediction. The initial guess is always the average of the target. In other words, for the first round, our model predicts that all purchases were the same — 156 dollars:
![]()
The reason for choosing the average has to do with our chosen loss function and its derivative. Every step of the way, we are searching for a value to find the minimum of the loss function. In other words, we are looking for a value that makes the derivative (gradient) of the loss function 0.
And when we take the derivative of the loss function for each observed value with respect to the predicted and sum them up, we end up with the average of the target.
So, our initial prediction is the average — 156 dollars. Hold it in memory as we continue.
Step 2: Calculate the pseudo-residuals
The next step is to find the differences between each observed value and our initial prediction: 156 - Observed. For illustration, we will put those differences in a new column:
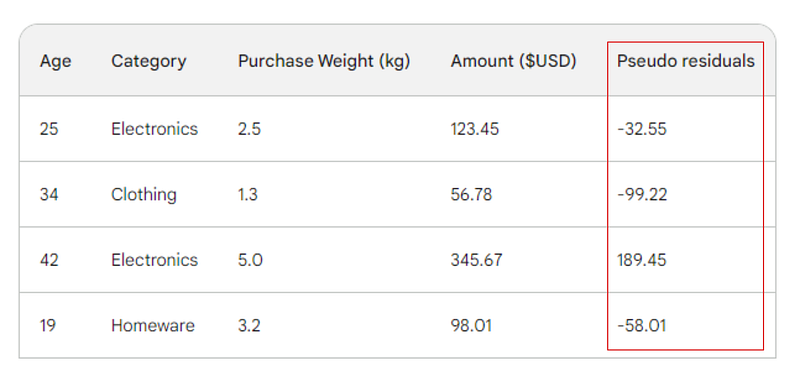
Remember that in linear regression, the difference between observed values and predicted values is called residuals. To differentiate linear regression and gradient boosting, we call them pseudo-residuals (there are other reasons they are named this way, but we won’t go into them in this article).
Step 3: Build a weak learner
Next, we will build a decision tree (weak learner) that predicts the residuals using the three features we have (age, category, purchase weight). For this problem, we will limit the decision tree to just four leaves (terminal nodes), but in practice, people usually choose leaves between 8 and 32.
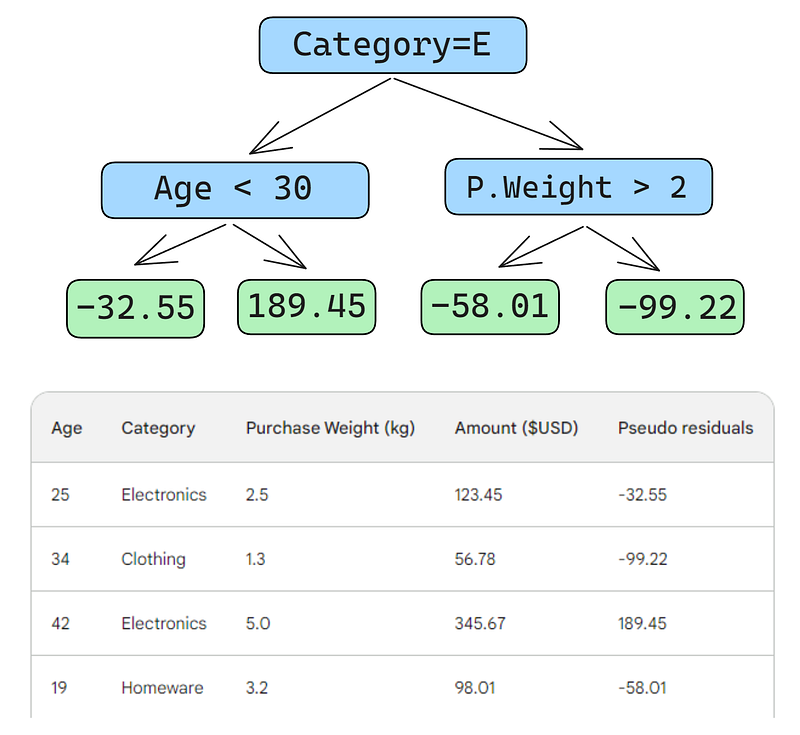
After the tree is fit to the data, we make a prediction for each row in the data. Here is how to do the first one:
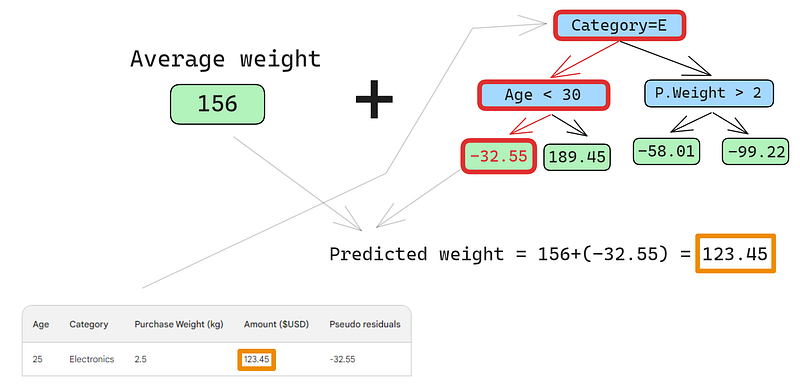
A small error in the images below: it should have been written “Predicted purchase amount,” not “Predicted weight”
The first row has the following features: a category of electronics (the left of the root node) and customer age below 30 (the left of the child node). This puts -32.55 into the leaf node. To make the final prediction, we add -32.55 to our first prediction, which is exactly the same as the observed value — 123.45 dollars!
We just made a perfect prediction, so why bother with building other trees? Well, right now, we are heavily overfitting to the training data. We want the model to generalize. So, to mitigate this problem, gradient boosting has a parameter called learning rate.
The learning rate in gradient boosting is simply a multiplier between 0 and 1 that scales the prediction of each weak learner (see the section below for details on learning rate). When we add an arbitrary learning rate of 0.1 into the mix, our prediction becomes 152.75, not the perfect 123.45.

Let’s predict on the second row as well:
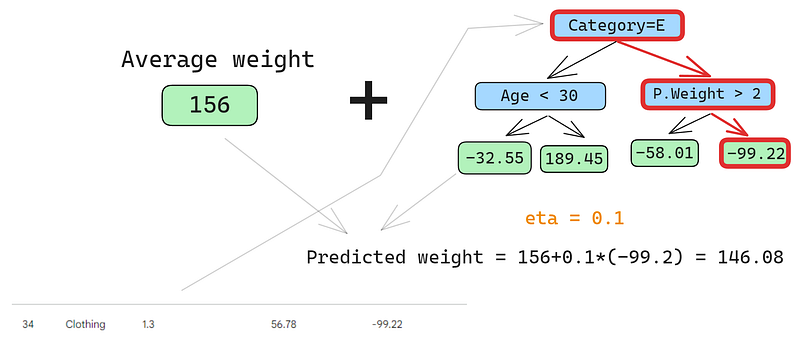
We run the row through the tree and get 146.08 as a prediction. We continue in this fashion for all rows until we have four predictions for four rows: 152.75, 146.08, 174.945, 150.2. Let’s add them as a new column for now:
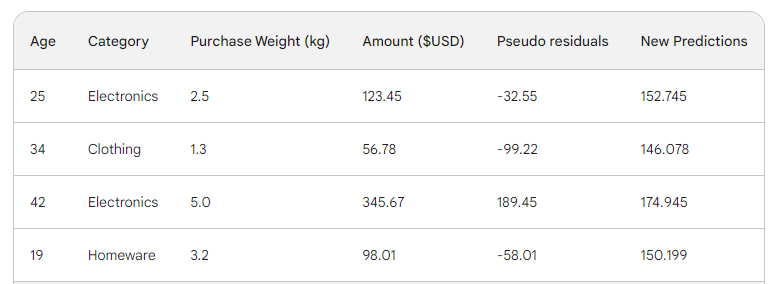
Next, we find the new pseudo-residuals by subtracting new predictions from the purchase amount. Let’s add them as a new column to the table and drop the last two:
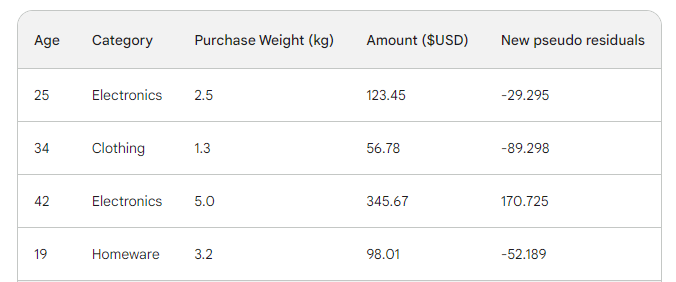
As you can see, our new pseudo residuals are smaller, which means our loss is going down.
Step 4: Iterate
In the next steps, we iterate on step 3, i.e. build more weak learners. The only thing to remember is that we have to keep adding the residuals of each tree to the initial prediction to generate the next.
For example, if we build 10 trees and the residuals of each tree are denoted as r_i (1 <= i <= 10), the next prediction would become p_10 = 156 + eta * (r_1 + r_2 + ... + r_10) where p_10 denotes prediction in the tenth round.
In practice, professionals often start with 100 trees, not just 10. In this case, the algorithm is said to train for 100 boosting rounds.
If you don’t know the exact number of trees you need for your specific problem, you can use a simple technique called early stopping.
In early stopping, we choose a large number of trees, like 1000 or 10000. Then, instead of waiting for the algorithm to finish building all those trees, we monitor the loss. If the loss doesn’t improve for a certain number of boosting rounds, for example, 50, we stop training earlier, saving time and computation resources.
Configuring Gradient Boosting Models
In machine learning, choosing the settings for a model is known as "hyperparameter tuning." These settings, called "hyperparameters," are options that the machine learning engineer must choose themselves. Unlike other parameters, the model cannot learn the best values for hyperparameters simply by being trained on data.
Gradient boosting models have many hyperparameters, some of which I will outline below.
Objective
This parameter sets the direction and the loss function of the algorithm. If the objective is regression, MSE is chosen as a loss function, whereas for classification, Cross-Entropy is the one to go. Python libraries like XGBoost offer other objectives for other types of tasks, such as ranking with corresponding loss functions.
Learning rate
The most important hyperparameter of gradient boosting is perhaps the learning rate. It controls the contribution of each weak learner by adjusting the shrinkage factor. Smaller values (towards 0) decreases how much say each weak learner has in the ensemble. This requires building more trees and, thus, more time to finish training. But, the final strong learner will indeed be strong and impervious to overfitting.
The number of trees
This parameter, also called the number of boosting rounds or n_es timators, controls the number of trees to build. The more trees you build, the stronger and more performant the ensemble becomes. It also becomes more complex as more trees allows the model to capture more patterns in the data. However, more trees significantly improve the chances of overfitting. To mitigate this, employ a combination of early stopping and low learning rate.
Max depth
This parameter controls the number of levels in each weak learner (decision tree). A max depth of 3 means there are three levels in the tree, counting the leaf level. The deeper the tree, the more complex and computationally expensive the model becomes. Choose a value close to 3 to prevent overfitting. Your maximum should be a depth of 10.
Minimum number of samples per leaf
This parameter controls how branches split in decision trees. Setting a low value for the number of samples in termination nodes (leaves) makes the overall algorithm sensitive to noise. A larger minimum number of samples helps to prevent overfitting by making it more difficult for the trees to create splits based on too few data points.
Subsampling rate
This parameter controls the proportion of the data used to train each tree. In the examples above, we used 100% of rows as there were only four rows in our dataset. But, real-world datasets often have much more and require sampling. So, if you set the subsampling rate to a value below 1, such as 0.7, each weak learner trains on the randomly sampled 70% of the rows. A smaller subsample rate can lead to faster training but can also lead to overfitting.
Feature sampling rate
This parameter is exactly like subsampling, but it samples rows. For datasets with hundreds of features, it is recommended to choose a feature sampling rate between 0.5 and 1 to lower the chance of overfitting.
Gradient boosting is the most capable model we have for tabular supervised learning tasks. So, most of the time, you don’t have to worry about it not being good enough for a task. When you use gradient boosting, your time is almost always spent on how to regularize it — to tame its power so that it doesn’t just swallow your dataset and become useless when it comes to unseen data.
The hyperparameters I’ve introduced all help you in this task and they are included into every implementation of gradient boosting in Python. Use them well.
Gradient Boosting Implemented in Python
As I mentioned before, gradient boosting is well-established through Python libraries. Here are the main four:
- XGBoost: eXtreme Gradient Boosting
- LightGBM: Light Gradient Boosting Machine
- CatBoost: Categorical Boosting
- Scikit-learn: Has two estimators for regression and classification
The first three libraries are similar to each other:
- Dominant performance
- GPU-support
- Rich set of hyperparameters (configuration-friendly)
- Very high community support
- Used extensively in industry
A popular alternative to all these three libraries is Scikit-learn, which has the disadvantage of being CPU-only. Since gradient boosting is a computation-heavy algorithm, running it on a CPU could be infeasible for large datasets (we are talking about hundreds of thousands of rows).
However, we have to remember that Scikit-learn, on its own, is more popular than the three libraries put together. Apart from the two gradient boosting estimators for classification and regression, Scikit-learn offers dozens of other models for a myriad of supervised and unsupervised learning tasks.
Besides, gradient boosting models built with Scikit-learn could be integrated into its rich ecosystem like pipelines, cross-validation estimators, data processors, etc.
Here is a step-by-step guide on how to do classification with GradientBoostingClassifier. We will predict the cut quality of diamonds based on their price and other physical measurements. This dataset is built into the Seaborn library.
Pro tip: Use the “Explain code” button of DataCamp code snippets editor to get a detailed line-by-line explanation of what’s going on.
1. Import Libraries
import pandas as pd
import seaborn as sns
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import cross_val_score, train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler2. Load data
# Load the diamonds dataset from Seaborn
diamonds = sns.load_dataset("diamonds")
# Split data into features and target
X = diamonds.drop("cut", axis=1)
y = diamonds["cut"]3. Split the data
# Split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)4. Define categorical and numerical features
# Define categorical and numerical features
categorical_features = X.select_dtypes(
include=["object"]
).columns.tolist()
numerical_features = X.select_dtypes(
include=["float64", "int64"]
).columns.tolist()5. Define preprocessing steps for categorical and numerical features
preprocessor = ColumnTransformer(
transformers=[
("cat", OneHotEncoder(), categorical_features),
("num", StandardScaler(), numerical_features),
]
)6. Create a Gradient Boosting Classifier pipeline
pipeline = Pipeline(
[
("preprocessor", preprocessor),
("classifier", GradientBoostingClassifier(random_state=42)),
]
)
7. CV and training
# Perform 5-fold cross-validation
cv_scores = cross_val_score(pipeline, X_train, y_train, cv=5)
# Fit the model on the training data
pipeline.fit(X_train, y_train)
# Predict on the test set
y_pred = pipeline.predict(X_test)
# Generate classification report
report = classification_report(y_test, y_pred)
8. Report the final results
print(f"Mean Cross-Validation Accuracy: {cv_scores.mean():.4f}")
print("\nClassification Report:")
print(report)
Mean Cross-Validation Accuracy: 0.7621
Classification Report:
precision recall f1-score support
Fair 0.90 0.91 0.91 335
Good 0.81 0.63 0.71 1004
Ideal 0.82 0.91 0.86 4292
Premium 0.70 0.86 0.77 2775
Very Good 0.66 0.41 0.51 2382
accuracy 0.76 10788
macro avg 0.78 0.74 0.75 10788
weighted avg 0.75 0.76 0.75 10788
The weighted accuracy is 75%, which is not bad for a baseline model with default parameters. So, as a challenge, I leave it to you to tune the hyperparameters of GradientBoostingClassifier to achieve over 95% performance. Yes, it is possible! (Hint: read the last section carefully and check out the Scikit-learn docs for the classifier).
Conclusion and further learning
Even though we’ve learned a ton, the main focus of the article was on the inner workings of the gradient boosting algorithm. Understanding how it works does not translate to being able to use it well in practice. However, intuitive understanding is always a huge help.
For further learning, I recommend the following resources:
- Using Gradient Boosting with XGBoost by DataCamp: #1 ranking article on XGBoost on Google
- Extreme Gradient Boosting With XGBoost Course: A comprehensive course on XGBoost
Thank you for reading!



