O corpo deste artigo é longo, mas detalhado, portanto, faremos a introdução o mais curta possível, começando diretamente com a pergunta: "Por que se preocupar com o aumento de gradiente?"
Há vários motivos excelentes:
- O Gradient boosting é o melhor: sua precisão e desempenho são incomparáveis para tarefas de aprendizado supervisionado tabular.
- O Gradient boosting é altamente versátil: pode ser usado em muitas tarefas importantes, como regressão, classificação, ranking e análise de sobrevivência.
- O aumento de gradiente é interpretável: ao contrário dos algoritmos de caixa preta, como as redes neurais, o aumento de gradiente não sacrifica a interpretabilidade em prol do desempenho. Ele funciona como um relógio suíço e, ainda assim, com paciência, você pode ensinar como ele funciona para uma criança em idade escolar.
- O aumento de gradiente é bem implementado: não é um daqueles algoritmos que têm pouco valor prático. Várias bibliotecas de aumento de gradiente, como XGBoost e LightGBM em Python, são usadas por centenas de milhares de pessoas.
- O Gradient Boosting vence: desde 2015, os profissionais têm usado esse recurso para vencer consistentemente competições tabulares em plataformas como a Kaggle.
Se algum desses pontos for minimamente atraente, vale a pena continuar lendo este artigo.
Então, vamos começar!
O que você aprenderá neste tutorial?
A conclusão mais importante deste artigo é que você terá uma compreensão muito sólida do funcionamento interno do aumento de gradiente sem muita dor de cabeça matemática. Afinal, o gradient boosting é para ser usado na prática, não para ser analisado matematicamente.
O que é Gradient Boosting em geral?
O reforço é uma poderosa técnica de conjunto no aprendizado de máquina. Diferentemente dos modelos tradicionais que aprendem com os dados de forma independente, o boosting combina as previsões de vários alunos fracos para criar um único aluno forte mais preciso.
Acabei de escrever vários termos novos, então vou explicar cada um deles, começando pelos alunos fracos.
Um aprendiz fraco é um modelo de aprendizado de máquina que é ligeiramente melhor do que um modelo de adivinhação aleatória. Por exemplo, digamos que estamos classificando os cogumelos em comestíveis e não comestíveis. Se um modelo de adivinhação aleatória tiver 40% de precisão, um aprendiz fraco estaria um pouco acima disso: 50-60%.
O reforço combina dezenas ou centenas desses alunos fracos para criar um aluno forte com potencial para mais de 95% de precisão no mesmo problema.
O aprendiz fraco mais popular é uma árvore de decisão, escolhida por sua capacidade de trabalhar com praticamente qualquer conjunto de dados. Se você não estiver familiarizado com árvores de decisão, confira este tutorial de classificação de árvores de decisão do DataCamp.
Aplicações reais do Gradient Boosting
O aumento de gradiente tornou-se uma força tão dominante no aprendizado de máquina que suas aplicações agora abrangem vários setores, desde a previsão da rotatividade de clientes até a detecção de asteroides. Aqui você tem uma visão geral de suas histórias de sucesso no Kaggle e de casos de uso no mundo real:
Dominar as competições da Kaggle:
- Desafio de Classificação de Produtos do Grupo Otto: todas as 10 primeiras posições usaram a implementação XGBoost de aumento de gradiente.
- Previsão de transações de clientes Santander: As soluções baseadas no XGBoost novamente garantiram os primeiros lugares na previsão do comportamento do cliente e das transações financeiras.
- Desafio de recomendação de filmes da Netflix: O Gradient Boosting desempenhou um papel fundamental na criação de sistemas de recomendação para empresas multibilionárias como a Netflix.
Transformando os negócios e o setor:
- Varejo e comércio eletrônico: recomendações personalizadas, gerenciamento de estoque, detecção de fraudes
- Finanças e seguros: avaliação de risco de crédito, previsão de rotatividade, negociação algorítmica
- Saúde e medicina: diagnóstico de doenças, descoberta de medicamentos, medicina personalizada
- Pesquisa e publicidade on-line: classificação de pesquisa, segmentação de anúncios, previsão da taxa de cliques
Então, vamos finalmente dar uma olhada nos bastidores desse lendário algoritmo!
O algoritmo Gradient Boosting: Um guia passo a passo
Entrada
O algoritmo de aumento de gradiente funciona para dados tabulares com um conjunto de recursos (X) e um alvo (y). Como outros algoritmos de aprendizado de máquina, o objetivo é aprender o suficiente com os dados de treinamento para generalizar bem para pontos de dados não vistos.
Para entender o processo subjacente do gradient boosting, usaremos um conjunto de dados de vendas simples com quatro linhas. Usando três recursos - idade do cliente, categoria de compra e peso da compra -, queremos prever o valor da compra:
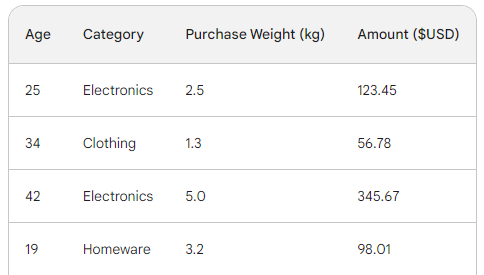
A função de perda no aumento de gradiente
No aprendizado de máquina, uma função de perda é um componente essencial que nos permite quantificar a diferença entre as previsões de um modelo e os valores reais. Em essência, ele mede o desempenho de um modelo.
Aqui está um detalhamento de sua função:
- Calcula o erro: Obtém a saída prevista do modelo e a compara com a verdade terrestre (valores reais observados). A forma como ele compara, ou seja, calcula a diferença, varia de função para função.
- Treinamento de modelos de guias: o objetivo de um modelo é minimizar a função de perda. Durante o treinamento, o modelo atualiza continuamente sua arquitetura e configuração internas para que a perda seja a menor possível.
- Métrica de avaliação: Ao comparar a perda nos conjuntos de dados de treinamento, validação e teste, você pode avaliar a capacidade de generalização do modelo e evitar o ajuste excessivo.
As duas funções de perda mais comuns são:
- Erro médio quadrático (MSE): Essa função de perda popular para regressão mede a soma das diferenças quadráticas entre os valores previstos e reais. O aumento de gradiente geralmente usa essa variação:
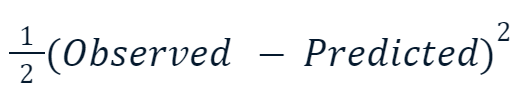
O motivo pelo qual o valor ao quadrado é multiplicado pela metade tem a ver com a diferenciação. Quando tomamos a derivada dessa função de perda, a metade se anula com o quadrado devido à regra da potência. Portanto, o resultado final seria apenas -(Observed - Predicted), tornando a matemática muito mais fácil e menos dispendiosa do ponto de vista computacional.
- Entropia cruzada: Essa função mede a diferença entre duas distribuições de probabilidade. Portanto, ele é comumente usado para tarefas de classificação em que os alvos têm categorias discretas.
Como estamos fazendo regressão, usaremos o MSE.
Etapa 1: Fazer uma previsão inicial
O Gradient boosting é um algoritmo que aumenta gradualmente sua precisão. Para iniciar o processo, precisamos de um palpite ou previsão inicial. O palpite inicial é sempre a média do alvo. Em outras palavras, na primeira rodada, nosso modelo prevê que todas as compras foram iguais - 156 dólares:
![]()
O motivo da escolha da média tem a ver com a função de perda que escolhemos e sua derivada. A cada passo do caminho, estamos buscando um valor para encontrar o mínimo da função de perda. Em outras palavras, estamos procurando um valor que faça com que a derivada (gradiente) da função de perda seja 0.
E quando tomamos a derivada da função de perda para cada valor observado em relação ao previsto e os somamos, obtemos a média do alvo.
Portanto, nossa previsão inicial é a média -156 dólares. Guarde-a na memória enquanto continuamos.
Etapa 2: Calcule os pseudo-resíduos
A próxima etapa é encontrar as diferenças entre cada valor observado e nossa previsão inicial: 156 - Observed. Para fins de ilustração, colocaremos essas diferenças em uma nova coluna:
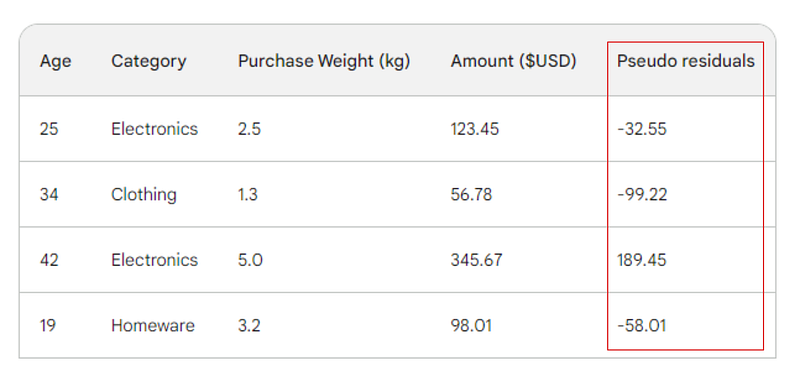
Lembre-se de que, na regressão linear, a diferença entre os valores observados e os valores previstos é chamada de resíduos. Para diferenciar a regressão linear e o gradient boosting, nós os chamamos de pseudo-residuais (há outros motivos para que sejam nomeados dessa forma, mas não vamos abordá-los neste artigo).
Etapa 3: Criar um aluno fraco
Em seguida, criaremos uma árvore de decisão (aprendiz fraco) que prevê os resíduos usando os três recursos que temos (idade, categoria, peso da compra). Para esse problema, limitaremos a árvore de decisão a apenas quatro folhas (nós terminais), mas, na prática, as pessoas geralmente escolhem folhas entre 8 e 32.
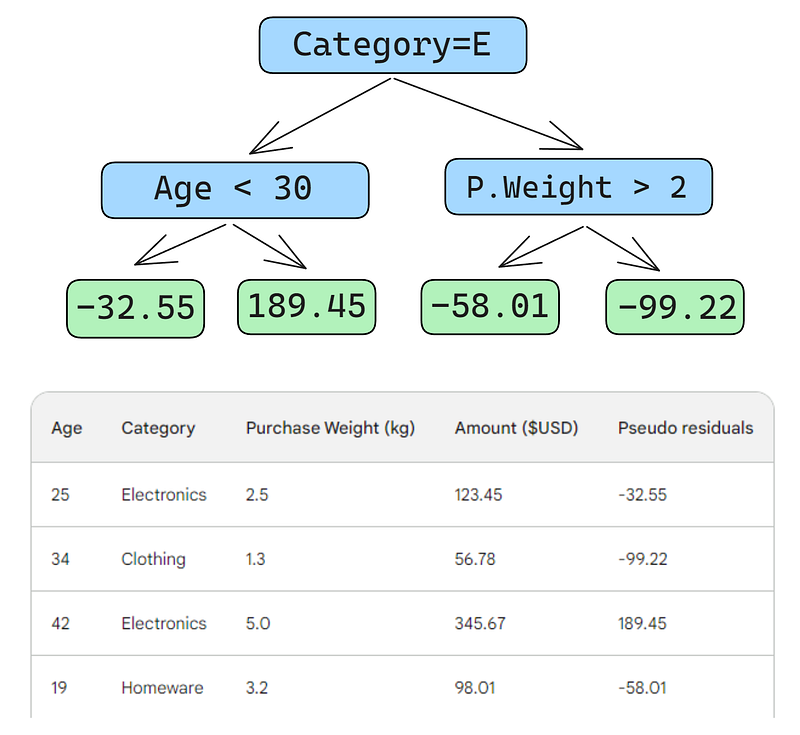
Depois que a árvore é ajustada aos dados, fazemos uma previsão para cada linha dos dados. Aqui está como você deve fazer a primeira:
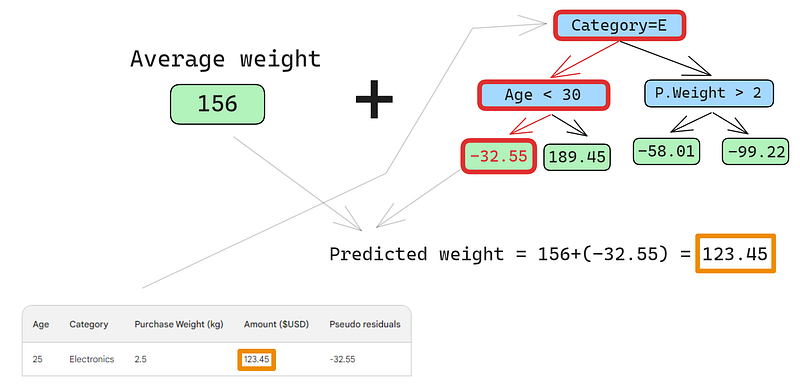
Um pequeno erro nas imagens abaixo: você deveria ter escrito "Predicted purchase amount" (valor de compra previsto), e não "Predicted weight" (peso previsto)
A primeira linha tem as seguintes características: uma categoria de eletrônicos (à esquerda do nó raiz) e a idade do cliente abaixo de 30 anos (à esquerda do nó filho). Isso coloca -32,55 no nó folha. Para fazer a previsão final, adicionamos -32,55 à nossa primeira previsão, que é exatamente igual ao valor observado - 123,45 dólares!
Acabamos de fazer uma previsão perfeita, então por que se preocupar em construir outras árvores? Bem, no momento, estamos nos ajustando excessivamente aos dados de treinamento. Queremos que o modelo seja generalizado. Portanto, para atenuar esse problema, o aumento do gradiente tem um parâmetro chamado taxa de aprendizado.
A taxa de aprendizagem no aumento do gradiente é simplesmente um multiplicador entre 0 e 1 que dimensiona a previsão de cada aluno fraco (consulte a seção abaixo para obter detalhes sobre a taxa de aprendizagem). Quando adicionamos uma taxa de aprendizado arbitrária de 0,1 à mistura, nossa previsão se torna 152,75, e não a perfeita 123,45.

Vamos prever a segunda linha também:
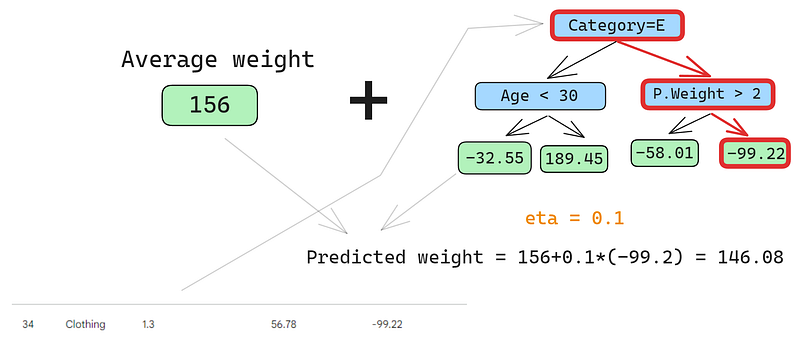
Executamos a linha na árvore e obtemos 146,08 como previsão. Continuamos dessa forma para todas as linhas até termos quatro previsões para quatro linhas: 152.75, 146.08, 174.945, 150.2. Por enquanto, vamos adicioná-los como uma nova coluna:
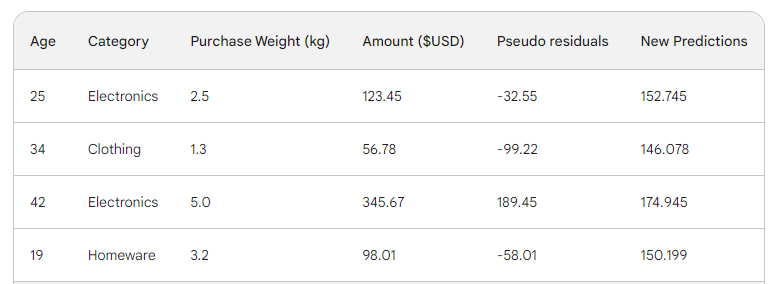
Em seguida, encontramos os novos pseudo-resíduos subtraindo as novas previsões do valor da compra. Vamos adicioná-las como uma nova coluna à tabela e eliminar as duas últimas:
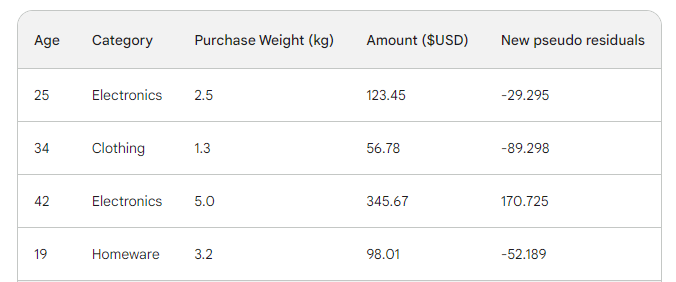
Como você pode ver, nossos novos pseudo-resíduos são menores, o que significa que nossa perda está diminuindo.
Etapa 4: Iterar
Nas próximas etapas, repetimos a etapa 3, ou seja, criamos mais alunos fracos. A única coisa que você deve lembrar é que precisamos continuar adicionando os resíduos de cada árvore à previsão inicial para gerar a próxima.
Por exemplo, se construirmos 10 árvores e os resíduos de cada árvore forem denotados como r_i (1 <= i <= 10), a próxima previsão será p_10 = 156 + eta * (r_1 + r_2 + ... + r_10), em que p_10 denota a previsão na décima rodada.
Na prática, os profissionais geralmente começam com 100 árvores, não apenas 10. Nesse caso, diz-se que o algoritmo é treinado para 100 rodadas de reforço.
Se você não souber o número exato de árvores necessárias para o seu problema específico, poderá usar uma técnica simples chamada interrupção antecipada.
Na parada inicial, escolhemos um grande número de árvores, como 1000 ou 10000. Então, em vez de esperar que o algoritmo termine de construir todas essas árvores, monitoramos a perda. Se a perda não melhorar em um determinado número de rodadas de reforço, por exemplo, 50, interrompemos o treinamento mais cedo, economizando tempo e recursos de computação.
Configuração de modelos de Gradient Boosting
No aprendizado de máquina, a escolha das configurações de um modelo é conhecida como "ajuste de hiperparâmetro". Essas configurações, chamadas de "hiperparâmetros", são opções que o próprio engenheiro de aprendizado de máquina deve escolher. Ao contrário de outros parâmetros, o modelo não pode aprender os melhores valores para os hiperparâmetros simplesmente por ser treinado com dados.
Os modelos de aumento de gradiente têm muitos hiperparâmetros, alguns dos quais descreverei a seguir.
Objetivo
Esse parâmetro define a direção e a função de perda do algoritmo. Se o objetivo for a regressão, o MSE será escolhido como uma função de perda, enquanto que, para a classificação, a entropia cruzada é a opção ideal. As bibliotecas Python, como a XGBoost, oferecem outros objetivos para outros tipos de tarefas, como classificação com funções de perda correspondentes.
Taxa de aprendizado
O hiperparâmetro mais importante do aumento de gradiente talvez seja a taxa de aprendizado. Ele controla a contribuição de cada aprendiz fraco, ajustando o fator de redução. Valores menores (em direção a 0) diminuem o quanto cada aluno fraco tem a dizer no conjunto. Isso requer a construção de mais árvores e, portanto, mais tempo para concluir o treinamento. No entanto, o aprendiz avançado final será, de fato, avançado e imune a ajustes excessivos.
O número de árvores
Esse parâmetro, também chamado de número de rodadas de reforço ou n_es timators, controla o número de árvores a serem construídas. Quanto mais árvores você construir, mais forte e mais eficiente será o conjunto. Ele também se torna mais complexo à medida que mais árvores permitem que o modelo capture mais padrões nos dados. No entanto, um número maior de árvores aumenta significativamente as chances de sobreajuste. Para atenuar isso, use uma combinação de parada antecipada e baixa taxa de aprendizado.
Profundidade máxima
Esse parâmetro controla o número de níveis em cada aprendiz fraco (árvore de decisão). Uma profundidade máxima de 3 significa que há três níveis na árvore, contando o nível da folha. Quanto mais profunda a árvore, mais complexo e computacionalmente caro o modelo se torna. Escolha um valor próximo a 3 para evitar o ajuste excessivo. Seu máximo deve ser uma profundidade de 10.
Número mínimo de amostras por folha
Esse parâmetro controla como os ramos se dividem nas árvores de decisão. A definição de um valor baixo para o número de amostras nos nós de terminação (folhas) torna o algoritmo geral sensível ao ruído. Um número mínimo maior de amostras ajuda a evitar o ajuste excessivo, dificultando que as árvores criem divisões com base em poucos pontos de dados.
Taxa de subamostragem
Esse parâmetro controla a proporção dos dados usados para treinar cada árvore. Nos exemplos acima, usamos 100% das linhas, pois havia apenas quatro linhas em nosso conjunto de dados. Porém, os conjuntos de dados do mundo real geralmente têm muito mais e exigem amostragem. Portanto, se você definir a taxa de subamostragem como um valor abaixo de 1, como 0,7, cada aprendiz fraco treinará em 70% das linhas amostradas aleatoriamente. Uma taxa de subamostragem menor pode levar a um treinamento mais rápido, mas também pode levar a um ajuste excessivo.
Taxa de amostragem de recursos
Esse parâmetro é exatamente como a subamostragem, mas faz a amostragem de linhas. Para conjuntos de dados com centenas de recursos, é recomendável escolher uma taxa de amostragem de recursos entre 0,5 e 1 para reduzir a chance de ajuste excessivo.
O Gradient Boosting é o modelo mais capaz que temos para tarefas de aprendizado supervisionado tabular. Portanto, na maioria das vezes, você não precisa se preocupar com o fato de ele não ser bom o suficiente para uma tarefa. Quando você usa o gradient boosting, quase sempre gasta seu tempo em como regularizá-lo - para domar seu poder de modo que ele não engula seu conjunto de dados e se torne inútil quando se trata de dados não vistos.
Todos os hiperparâmetros que apresentei ajudam você nessa tarefa e estão incluídos em todas as implementações de gradient boosting em Python. Use-os bem.
Gradient Boosting implementado em Python
Como mencionei anteriormente, o aumento do gradiente está bem estabelecido por meio de bibliotecas Python. Aqui estão os quatro principais:
- XGBoosteXtreme Gradient Boosting: aumento de gradiente extremo
- LightGBM: Máquina de aumento de gradiente de luz
- CatBoost: Boosting categórico
- Scikit-learn: Possui dois estimadores para regressão e classificação
As três primeiras bibliotecas são semelhantes umas às outras:
- Desempenho dominante
- Suporte a GPU
- Conjunto rico de hiperparâmetros (fácil de configurar)
- Apoio muito grande da comunidade
- Usado extensivamente no setor
Uma alternativa popular a todas essas três bibliotecas é o Scikit-learn, que tem a desvantagem de ser somente para CPU. Como o gradient boosting é um algoritmo de computação pesada, executá-lo em uma CPU pode ser inviável para grandes conjuntos de dados (estamos falando de centenas de milhares de linhas).
No entanto, devemos lembrar que o Scikit-learn, por si só, é mais popular do que as três bibliotecas juntas. Além dos dois estimadores de aumento de gradiente para classificação e regressão, o Scikit-learn oferece dezenas de outros modelos para uma infinidade de tarefas de aprendizado supervisionadas e não supervisionadas.
Além disso, os modelos de aumento de gradiente criados com o Scikit-learn podem ser integrados ao seu rico ecossistema, como pipelines, estimadores de validação cruzada, processadores de dados etc.
Aqui está um guia passo a passo sobre como fazer a classificação com o GradientBoostingClassifier. Prevemos a qualidade da lapidação dos diamantes com base em seu preço e em outras medidas físicas. Esse conjunto de dados está incorporado à biblioteca Seaborn.
Dica profissional: Use o botão "Explain code" (Explicar código) do editor de trechos de código do DataCamp para obter uma explicação detalhada, linha por linha, do que está acontecendo.
1. Importar bibliotecas
import pandas as pd
import seaborn as sns
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import cross_val_score, train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler2. Carregar dados
# Load the diamonds dataset from Seaborn
diamonds = sns.load_dataset("diamonds")
# Split data into features and target
X = diamonds.drop("cut", axis=1)
y = diamonds["cut"]3. Dividir os dados
# Split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)4. Definir características categóricas e numéricas
# Define categorical and numerical features
categorical_features = X.select_dtypes(
include=["object"]
).columns.tolist()
numerical_features = X.select_dtypes(
include=["float64", "int64"]
).columns.tolist()5. Definir etapas de pré-processamento para recursos categóricos e numéricos
preprocessor = ColumnTransformer(
transformers=[
("cat", OneHotEncoder(), categorical_features),
("num", StandardScaler(), numerical_features),
]
)6. Crie um pipeline do classificador Gradient Boosting
pipeline = Pipeline(
[
("preprocessor", preprocessor),
("classifier", GradientBoostingClassifier(random_state=42)),
]
)
7. Currículo e treinamento
# Perform 5-fold cross-validation
cv_scores = cross_val_score(pipeline, X_train, y_train, cv=5)
# Fit the model on the training data
pipeline.fit(X_train, y_train)
# Predict on the test set
y_pred = pipeline.predict(X_test)
# Generate classification report
report = classification_report(y_test, y_pred)
8. Relatar os resultados finais
print(f"Mean Cross-Validation Accuracy: {cv_scores.mean():.4f}")
print("\nClassification Report:")
print(report)
Mean Cross-Validation Accuracy: 0.7621
Classification Report:
precision recall f1-score support
Fair 0.90 0.91 0.91 335
Good 0.81 0.63 0.71 1004
Ideal 0.82 0.91 0.86 4292
Premium 0.70 0.86 0.77 2775
Very Good 0.66 0.41 0.51 2382
accuracy 0.76 10788
macro avg 0.78 0.74 0.75 10788
weighted avg 0.75 0.76 0.75 10788
A precisão ponderada é de 75%, o que não é ruim para um modelo de linha de base com parâmetros padrão. Portanto, como um desafio, deixo para você ajustar os hiperparâmetros do GradientBoostingClassifier para obter um desempenho superior a 95%. Sim, é possível! (Dica: leia a última seção com atenção e consulte a documentação do Scikit-learn para o classificador).
Conclusão e aprendizado adicional
Embora tenhamos aprendido muito, o foco principal do artigo foi o funcionamento interno do algoritmo de aumento de gradiente. O fato de você entender como ele funciona não significa que seja capaz de usá-lo bem na prática. No entanto, a compreensão intuitiva é sempre uma grande ajuda.
Para aprender mais, recomendo os seguintes recursos:
- Usando Gradient Boosting com XGBoost por DataCamp: #Artigo nº 1 no ranking sobre o XGBoost no Google
- Extreme Gradient Boosting com o curso XGBoost: Um curso abrangente sobre o XGBoost
Obrigado a você por ler!


