
Kursus
Pengantar Deep Learning dengan Python
4 Hr
264K
Jaringan saraf feedforward tradisional dapat sangat baik dalam melakukan tugas seperti klasifikasi dan regresi, tetapi bagaimana jika kita ingin menerapkan solusi seperti denoising sinyal atau deteksi anomali? Salah satu caranya adalah dengan menggunakan Autoencoder.
Tutorial ini memberikan pengantar praktis tentang Autoencoder, termasuk contoh hands-on di PyTorch dan beberapa potensi use case.
Anda dapat mengikuti di DataLab workbook ini yang berisi semua kode dari tutorial.
Autoencoder adalah jenis khusus jaringan saraf feedforward tanpa supervisi (tidak perlu label!). Aplikasi utama Autoencoder adalah menangkap secara akurat aspek-aspek kunci dari data yang disediakan untuk menghasilkan versi terkompresi dari data input, menghasilkan data sintetis yang realistis, atau menandai anomali.
Autoencoder tersusun dari 2 jaringan saraf feedforward berhubung penuh yang utama (Gambar 1):
Dengan mengulangi proses ini secara iteratif—meneruskan data melalui encoder dan decoder serta mengukur error untuk menyetel parameter melalui backpropagation—Autoencoder seiring waktu dapat bekerja dengan benar pada bentuk data yang sangat sulit.
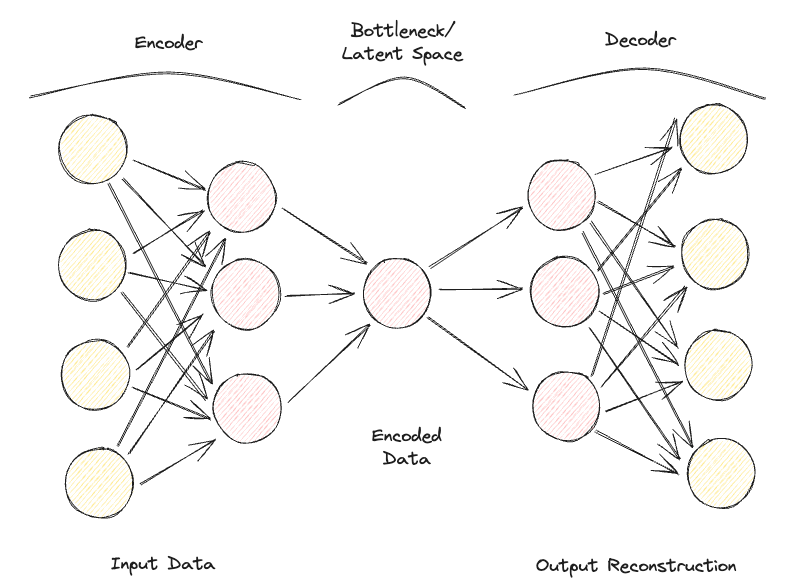
Gambar 1: Arsitektur Autoencoder (Gambar oleh Penulis).
Jika sebuah Autoencoder diberi sekumpulan fitur input yang sepenuhnya saling independen, maka model akan sangat sulit menemukan representasi berdimensi lebih rendah yang baik tanpa kehilangan banyak informasi (kompresi lossy).
Karena itu, Autoencoder juga dapat dianggap sebagai teknik reduksi dimensi yang, dibandingkan teknik tradisional seperti Principal Component Analysis (PCA), dapat memanfaatkan transformasi nonlinier untuk memproyeksikan data ke ruang berdimensi lebih rendah. Jika Anda tertarik mempelajari lebih lanjut teknik Feature Extraction lainnya, informasi tambahan tersedia dalam tutorial feature extraction ini..
Selain itu, dibandingkan algoritma kompresi data standar seperti gzpi, Autoencoder tidak dapat digunakan sebagai algoritma kompresi serbaguna, tetapi dirancang khusus agar bekerja paling baik pada data serupa dengan data yang digunakan saat pelatihan.
Beberapa hiperparameter paling umum yang dapat disetel ketika mengoptimalkan Autoencoder Anda adalah:
Terakhir, Autoencoder dapat dirancang untuk bekerja dengan berbagai jenis data, seperti data tabular, deret waktu, atau citra, dan karena itu dapat dirancang menggunakan berbagai jenis layer, seperti convolutional layer untuk analisis gambar.
Idealnya, Autoencoder yang terlatih dengan baik harus cukup responsif untuk beradaptasi dengan data input guna memberikan respons yang sesuai, namun tidak sampai sekadar meniru data input dan tidak mampu menggeneralisasi pada data yang belum pernah dilihat (overfitting).
Selama bertahun-tahun, berbagai jenis Autoencoder telah dikembangkan:
Mari kita bahas masing-masing secara lebih rinci.
Ini adalah versi paling sederhana dari autoencoder. Dalam hal ini, kita tidak memiliki mekanisme regularisasi eksplisit, tetapi kita memastikan ukuran bottleneck selalu lebih kecil daripada ukuran input asli untuk menghindari overfitting. Konfigurasi jenis ini biasanya digunakan sebagai teknik reduksi dimensi (lebih kuat daripada PCA karena juga mampu menangkap nonlinieritas dalam data).
Sparse Autoencoder cukup mirip dengan Undercomplete Autoencoder, tetapi perbedaan utamanya terletak pada cara regularisasi diterapkan. Dengan Sparse Autoencoder, kita tidak harus mengurangi dimensi bottleneck, melainkan menggunakan fungsi loss yang mencoba menghukum model ketika menggunakan semua neuronnya pada berbagai hidden layer (Gambar 2).
Penalti ini biasanya disebut sebagai fungsi sparsity, dan ini cukup berbeda dari teknik regularisasi tradisional karena tidak berfokus pada menghukum ukuran bobot, melainkan jumlah node yang diaktifkan.
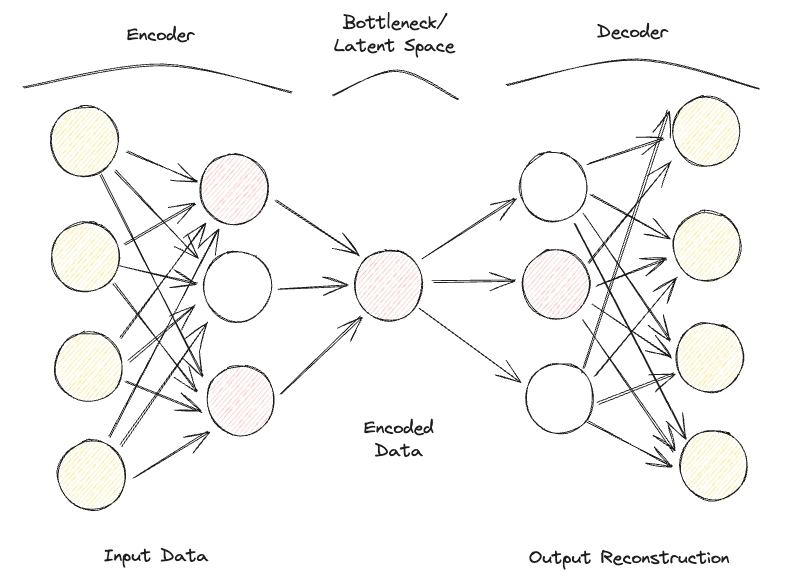
Dengan cara ini, node yang berbeda dapat berspesialisasi untuk jenis input yang berbeda dan diaktifkan/dinonaktifkan bergantung pada kekhususan data input. Kendala sparsity ini dapat diinduksi dengan menggunakan Regularisasi L1 dan KL divergence, sehingga efektif mencegah model overfitting.
Gagasan utama di balik Contractive Autoencoder adalah bahwa untuk beberapa input yang mirip, representasi terkompresinya seharusnya cukup mirip (lingkungan input harus “dikontraksi” menjadi lingkungan output yang kecil). Secara matematis, hal ini dapat dipaksakan dengan menjaga turunan aktivasi hidden layer terhadap input tetap kecil saat diberi input yang serupa.
Dengan Denoising Autoencoder, input dan output model tidak lagi sama. Misalnya, model dapat diberi gambar resolusi rendah yang terkorupsi dan bekerja untuk menghasilkan output yang meningkatkan kualitas gambar. Untuk menilai kinerja model dan meningkatkannya dari waktu ke waktu, kita kemudian perlu memiliki semacam citra bersih berlabel untuk dibandingkan dengan prediksi model.
Untuk bekerja dengan data citra, Convolutional Autoencoder mengganti jaringan saraf feedforward tradisional dengan Convolutional Neural Networks baik pada langkah encoder maupun decoder. Dengan memperbarui jenis fungsi loss, dan lain-lain, jenis Autoencoder ini juga dapat dibuat, misalnya, menjadi Sparse atau Denoising, tergantung kebutuhan use case Anda.
Pada setiap jenis Autoencoder yang dibahas sejauh ini, encoder menghasilkan satu nilai untuk setiap dimensi yang terlibat. Dengan Variational Autoencoder (VAE), proses ini dibuat bersifat probabilistik, dengan membentuk distribusi probabilitas untuk setiap dimensi. Decoder kemudian dapat melakukan sampling sebuah nilai dari setiap distribusi yang menggambarkan berbagai dimensi dan menyusun vektor input, yang kemudian dapat digunakan untuk merekonstruksi data input asli.
Salah satu aplikasi utama Variational Autoencoder adalah untuk tugas generatif. Melakukan sampling latent model dari distribusi memungkinkan decoder membuat bentuk output baru yang sebelumnya tidak mungkin dilakukan menggunakan pendekatan deterministik.
Jika Anda tertarik mencoba secara daring Variational Autoencoder yang dilatih pada dataset MNIST, Anda dapat menemukan contoh langsung.
Kini kita siap melalui demonstrasi praktis tentang bagaimana Autoencoder dapat digunakan untuk reduksi dimensi. Kerangka kerja Deep Learning pilihan kita untuk latihan ini adalah PyTorch.
Dataset Kaggle Rain in Australia akan digunakan untuk demonstrasi ini. Semua kode dalam artikel ini tersedia di DataLab workbook ini.
Pertama-tama, kita mengimpor semua pustaka yang diperlukan dan menghapus nilai yang hilang serta kolom non-numerik (Gambar 3).
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler, LabelEncoder
from mpl_toolkits.mplot3d import Axes3D
df = pd.read_csv("../input/weather-dataset-rattle-package/weatherAUS.csv")
df = df.drop(['Date', 'Location', 'WindDir9am',
'WindGustDir', 'WindDir3pm'], axis=1)
df = df.dropna(how = 'any')
df.loc[df['RainToday'] == 'No', 'RainToday'] = 0
df.loc[df['RainToday'] == 'Yes', 'RainToday'] = 1
df.head()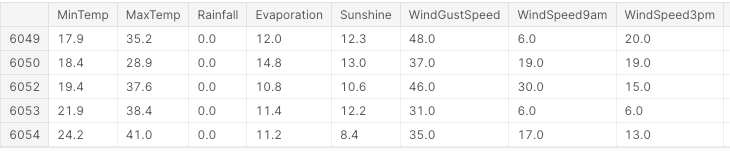
Gambar 3: Contoh Kolom Dataset (Gambar oleh Penulis).
Pada tahap ini, kita siap membagi data menjadi fitur dan label, menormalkan fitur, dan mengonversi label ke format numerik.
Dalam kasus ini, kita memiliki himpunan fitur awal yang terdiri dari 17 kolom. Tujuan keseluruhan analisis adalah memprediksi dengan benar apakah besok akan turun hujan atau tidak.
X, Y = df.drop('RainTomorrow', axis=1, inplace=False), df[['RainTomorrow']]
# Normalizing Data
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Converting to PyTorch tensor
X_tensor = torch.FloatTensor(X_scaled)
# Converting string labels to numerical labels
label_encoder = LabelEncoder()
Y_numerical = label_encoder.fit_transform(Y.values.ravel())Di PyTorch, kini kita dapat mendefinisikan model Autoencoder sebagai sebuah kelas dan menentukan model encoder dan decoder dengan dua layer linear.
# Defining Autoencoder model
class Autoencoder(nn.Module):
def __init__(self, input_size, encoding_dim):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(input_size, 16),
nn.ReLU(),
nn.Linear(16, encoding_dim),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.Linear(encoding_dim, 16),
nn.ReLU(),
nn.Linear(16, input_size),
nn.Sigmoid()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return xSekarang model telah disiapkan, kita dapat menentukan dimensi encoding sama dengan 3 (agar mudah dipetakan nanti) dan menjalankan proses pelatihan.
# Setting random seed for reproducibility
torch.manual_seed(42)
input_size = X.shape[1] # Number of input features
encoding_dim = 3 # Desired number of output dimensions
model = Autoencoder(input_size, encoding_dim)
# Loss function and optimizer
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.003)
# Training the autoencoder
num_epochs = 20
for epoch in range(num_epochs):
# Forward pass
outputs = model(X_tensor)
loss = criterion(outputs, X_tensor)
# Backward pass and optimization
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Loss for each epoch
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
# Encoding the data using the trained autoencoder
encoded_data = model.encoder(X_tensor).detach().numpy()Epoch [1/20], Loss: 1.2443
Epoch [2/20], Loss: 1.2410
Epoch [3/20], Loss: 1.2376
Epoch [4/20], Loss: 1.2342
Epoch [5/20], Loss: 1.2307
Epoch [6/20], Loss: 1.2271
Epoch [7/20], Loss: 1.2234
Epoch [8/20], Loss: 1.2196
Epoch [9/20], Loss: 1.2156
Epoch [10/20], Loss: 1.2114
Epoch [11/20], Loss: 1.2070
Epoch [12/20], Loss: 1.2023
Epoch [13/20], Loss: 1.1974
Epoch [14/20], Loss: 1.1923
Epoch [15/20], Loss: 1.1868
Epoch [16/20], Loss: 1.1811
Epoch [17/20], Loss: 1.1751
Epoch [18/20], Loss: 1.1688
Epoch [19/20], Loss: 1.1622
Epoch [20/20], Loss: 1.1554Akhirnya, kini kita dapat memetakan dimensi embedding yang dihasilkan (Gambar 4). Seperti terlihat pada gambar di bawah, kita berhasil mengurangi dimensi himpunan fitur dari 17 dimensi menjadi hanya 3, sambil tetap mampu, hingga tingkat yang cukup baik, memisahkan sampel antar kelas secara benar dalam ruang 3 dimensi.
# Plotting the encoded data in 3D space
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, projection='3d')
scatter = ax.scatter(encoded_data[:, 0], encoded_data[:, 1],
encoded_data[:, 2], c=Y_numerical, cmap='viridis')
# Mapping numerical labels back to original string labels for the legend
labels = label_encoder.inverse_transform(np.unique(Y_numerical))
legend_labels = {num: label for num, label in zip(np.unique(Y_numerical),
labels)}
# Creating a custom legend with original string labels
handles = [plt.Line2D([0], [0], marker='o', color='w',
markerfacecolor=scatter.to_rgba(num),
markersize=10,
label=legend_labels[num]) for num in np.unique(Y_numerical)]
ax.legend(handles=handles, title="Raining Tomorrow?")
# Adjusting the layout to provide more space for labels
ax.xaxis.labelpad = 20
ax.yaxis.labelpad = 20
ax.set_xticks([])
ax.set_yticks([])
ax.set_zticks([])
# Manually adding z-axis label for better visibility
ax.text2D(0.05, 0.95, 'Encoded Dimension 3', transform=ax.transAxes,
fontsize=12, color='black')
ax.set_xlabel('Encoded Dimension 1')
ax.set_ylabel('Encoded Dimension 2')
ax.set_title('Autoencoder Dimensionality Reduction')
plt.tight_layout()
plt.savefig('Rain_Prediction_Autoencoder.png')
plt.show()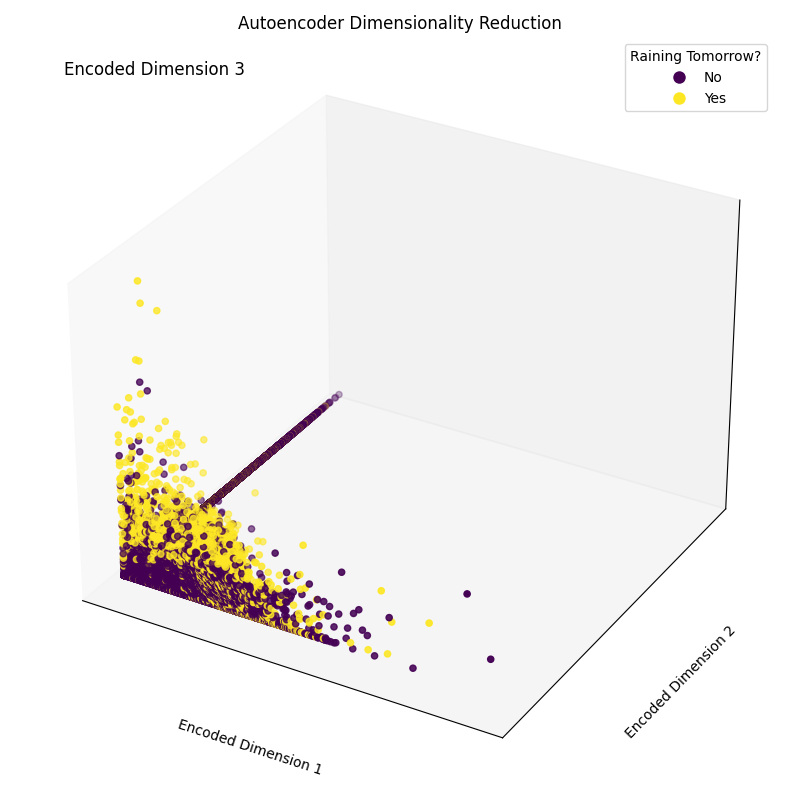
Gambar 4: Dimensi Terkode yang Dihasilkan (Gambar oleh Penulis).
Salah satu aplikasi utama Autoencoder adalah mengompresi gambar untuk mengurangi ukuran berkas keseluruhan sambil berusaha mempertahankan sebanyak mungkin informasi berharga, atau memulihkan gambar yang menurun kualitasnya seiring waktu.
Karena Autoencoder mahir membedakan karakteristik esensial data dari noise, ia dapat digunakan untuk mendeteksi anomali (misalnya, apakah sebuah gambar telah di-photoshop, apakah ada aktivitas tidak biasa di jaringan, dan lain-lain)
Variational Autoencoder dan Generative Adversarial Networks (GAN) sering digunakan untuk menghasilkan data sintetis (misalnya, gambar manusia yang realistis).
Sebagai penutup, Autoencoder dapat menjadi alat yang sangat fleksibel untuk memberdayakan berbagai bentuk use case. Secara khusus, Variational Autoencoder dan lahirnya GAN membuka jalan bagi perkembangan AI Generatif, memberi kita gambaran awal tentang bagaimana AI dapat digunakan untuk menghasilkan bentuk konten baru yang belum pernah ada sebelumnya.
Tutorial ini merupakan pengantar bidang Autoencoder, meskipun masih banyak yang bisa dipelajari! DataCamp memiliki beragam sumber daya tentang topik ini, seperti cara mengimplementasikan Autoencoder di Keras atau menggunakannya sebagai klasifier!
Mulai Perjalanan Deep Learning Anda Hari Ini!
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
