
Courses
Nhập môn Deep Learning với Python
4 giờ
264K
Các mạng nơ-ron truyền thẳng truyền thống có thể rất giỏi trong các tác vụ như phân loại và hồi quy, nhưng nếu chúng ta muốn triển khai các giải pháp như khử nhiễu tín hiệu hoặc phát hiện bất thường thì sao? Một cách để làm điều này là sử dụng Autoencoder.
Hướng dẫn này cung cấp phần giới thiệu thực tiễn về Autoencoder, bao gồm ví dụ thực hành bằng PyTorch và một số trường hợp sử dụng tiềm năng.
Bạn có thể làm theo trong sổ tay DataLab này với toàn bộ mã nguồn từ bài hướng dẫn.
Autoencoder là một loại mạng nơ-ron truyền thẳng không giám sát đặc biệt (không cần nhãn!). Ứng dụng chính của Autoencoder là nắm bắt chính xác các khía cạnh then chốt của dữ liệu được cung cấp để tạo ra phiên bản nén của dữ liệu đầu vào, tạo dữ liệu tổng hợp chân thực hoặc gắn cờ các điểm bất thường.
Autoencoder bao gồm 2 mạng nơ-ron truyền thẳng kết nối đầy đủ chính (Hình 1):
Lặp đi lặp lại quá trình đưa dữ liệu qua encoder và decoder, đo lỗi để tinh chỉnh tham số thông qua lan truyền ngược, Autoencoder theo thời gian có thể xử lý đúng cả những dạng dữ liệu cực kỳ khó.
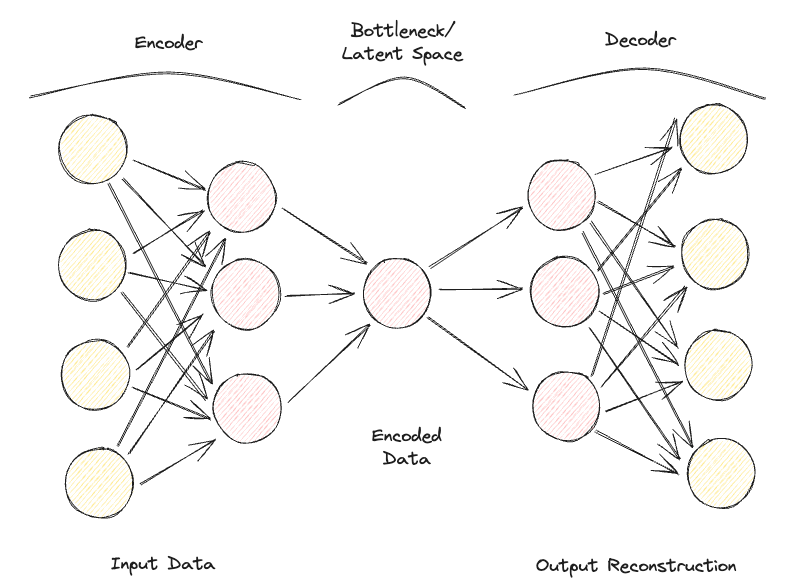
Hình 1: Kiến trúc Autoencoder (Ảnh của tác giả).
Nếu một Autoencoder được cung cấp tập đặc trưng đầu vào hoàn toàn độc lập với nhau, mô hình sẽ rất khó tìm được biểu diễn chiều thấp tốt mà không làm mất rất nhiều thông tin (nén mất dữ liệu).
Vì vậy, Autoencoder cũng có thể được xem là một kỹ thuật giảm chiều dữ liệu; so với các kỹ thuật truyền thống như Phân tích Thành phần Chính (PCA), chúng có thể sử dụng các phép biến đổi phi tuyến để chiếu dữ liệu vào không gian có số chiều thấp hơn. Nếu bạn muốn tìm hiểu thêm về các kỹ thuật Trích xuất Đặc trưng khác, có thêm thông tin trong bài hướng dẫn trích xuất đặc trưng này.
Ngoài ra, so với các thuật toán nén dữ liệu tiêu chuẩn như gzpi, Autoencoder không thể dùng như thuật toán nén mục đích chung mà được “chế tác thủ công” để hoạt động tốt nhất trên các dữ liệu tương tự với dữ liệu đã dùng để huấn luyện.
Một số siêu tham số phổ biến có thể tinh chỉnh khi tối ưu Autoencoder gồm:
Cuối cùng, Autoencoder có thể được thiết kế để làm việc với nhiều loại dữ liệu khác nhau như bảng, chuỗi thời gian hoặc ảnh và vì vậy có thể sử dụng đa dạng các tầng, chẳng hạn như các tầng tích chập cho phân tích ảnh.
Lý tưởng nhất, một Autoencoder được huấn luyện tốt nên đủ linh hoạt để thích ứng với dữ liệu đầu vào nhằm đưa ra phản hồi phù hợp, nhưng không đến mức chỉ bắt chước dữ liệu đầu vào và không thể khái quát hóa với dữ liệu chưa từng thấy (dẫn đến overfitting).
Qua nhiều năm, đã có nhiều loại Autoencoder khác nhau được phát triển:
Hãy khám phá chi tiết từng loại.
Đây là phiên bản đơn giản nhất của autoencoder. Trong trường hợp này, chúng ta không có cơ chế regularization tường minh, nhưng đảm bảo kích thước nút thắt cổ chai luôn nhỏ hơn kích thước đầu vào gốc để tránh overfitting. Cấu hình này thường dùng như một kỹ thuật giảm chiều dữ liệu (mạnh hơn PCA vì cũng có thể nắm bắt tính phi tuyến trong dữ liệu).
Sparse Autoencoder khá giống Undercomplete Autoencoder, nhưng khác biệt chính nằm ở cách áp dụng regularization. Với Sparse Autoencoder, chúng ta không nhất thiết phải giảm số chiều của nút thắt cổ chai, mà dùng hàm mất mát nhằm phạt mô hình khi sử dụng tất cả neuron ở các tầng ẩn khác nhau (Hình 2).
Hình phạt này thường được gọi là hàm thưa (sparsity function), và khá khác với các kỹ thuật regularization truyền thống vì nó không tập trung phạt độ lớn trọng số mà tập trung vào số lượng nút được kích hoạt.
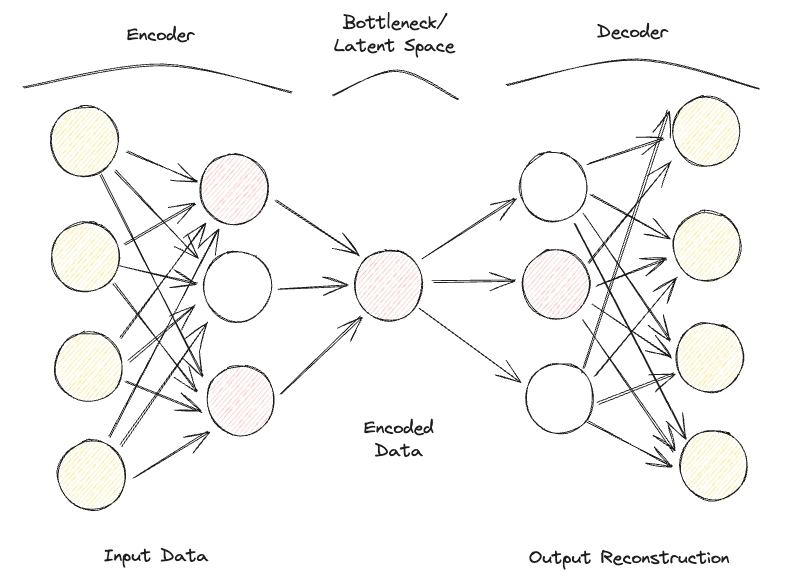
Theo cách này, các nút khác nhau có thể chuyên biệt cho các kiểu đầu vào khác nhau và được kích hoạt/tắt tùy thuộc vào đặc thù của dữ liệu đầu vào. Ràng buộc độ thưa này có thể được tạo ra bằng cách dùng Regularization L1 và phân kỳ KL, hiệu quả trong việc ngăn mô hình overfit.
Ý tưởng chính của Contractive Autoencoder là với các đầu vào tương tự nhau, biểu diễn nén của chúng cũng nên khá giống nhau (lân cận của đầu vào được “co” lại thành lân cận nhỏ ở đầu ra). Về mặt toán học, điều này có thể được thực thi bằng cách giữ cho đạo hàm theo đầu vào của các kích hoạt tầng ẩn nhỏ khi cho các đầu vào tương tự.
Với Denoising Autoencoder, đầu vào và đầu ra của mô hình không còn giống nhau. Ví dụ, mô hình có thể được cung cấp ảnh bị hỏng độ phân giải thấp và tạo đầu ra nhằm cải thiện chất lượng ảnh. Để đánh giá hiệu năng mô hình và cải thiện theo thời gian, chúng ta cần có dạng ảnh sạch đã gán nhãn để so sánh với dự đoán của mô hình.
Để làm việc với dữ liệu ảnh, Convolutional Autoencoder thay thế các mạng truyền thẳng truyền thống bằng Mạng Nơ-ron Tích chập cho cả bước encoder và decoder. Bằng cách cập nhật loại hàm mất mát, v.v., kiểu Autoencoder này cũng có thể được biến thành, ví dụ, Sparse hoặc Denoising, tùy yêu cầu bài toán.
Trong mọi loại Autoencoder đã xét tới giờ, encoder xuất ra một giá trị đơn cho mỗi chiều liên quan. Với Variational Autoencoder (VAE), chúng ta biến quá trình này thành xác suất, tạo ra một phân phối xác suất cho mỗi chiều. Decoder sau đó có thể lấy mẫu một giá trị từ mỗi phân phối mô tả các chiều khác nhau và xây dựng vector đầu vào, từ đó dùng để tái tạo dữ liệu đầu vào gốc.
Một trong những ứng dụng chính của Variational Autoencoder là cho các tác vụ sinh dữ liệu. Thực tế, việc lấy mẫu từ các phân phối trong không gian tiềm ẩn cho phép decoder tạo ra những dạng đầu ra mới mà trước đây không thể có với cách tiếp cận tất định.
Nếu bạn muốn thử trực tuyến một Variational Autoencoder được huấn luyện trên bộ dữ liệu MNIST, bạn có thể xem ví dụ trực tiếp.
Giờ chúng ta sẵn sàng đi qua một minh họa thực tế về cách Autoencoder có thể dùng để giảm chiều dữ liệu. Khung Deep Learning được chọn cho bài tập này là PyTorch.
Bộ dữ liệu Kaggle Rain in Australia sẽ được dùng cho minh họa. Toàn bộ mã trong bài viết có trong sổ tay DataLab này.
Trước hết, chúng ta nhập các thư viện cần thiết và loại bỏ mọi giá trị thiếu cũng như các cột không phải số (Hình 3).
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler, LabelEncoder
from mpl_toolkits.mplot3d import Axes3D
df = pd.read_csv("../input/weather-dataset-rattle-package/weatherAUS.csv")
df = df.drop(['Date', 'Location', 'WindDir9am',
'WindGustDir', 'WindDir3pm'], axis=1)
df = df.dropna(how = 'any')
df.loc[df['RainToday'] == 'No', 'RainToday'] = 0
df.loc[df['RainToday'] == 'Yes', 'RainToday'] = 1
df.head()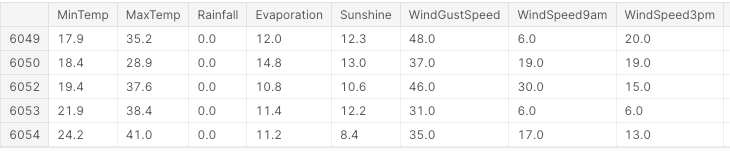
Hình 3: Mẫu các cột của bộ dữ liệu (Ảnh của tác giả).
Tại thời điểm này, chúng ta sẵn sàng chia dữ liệu thành đặc trưng và nhãn, chuẩn hóa các đặc trưng và chuyển nhãn sang định dạng số.
Trong trường hợp này, chúng ta bắt đầu với tập đặc trưng gồm 17 cột. Mục tiêu tổng thể của phân tích là dự đoán chính xác liệu ngày mai có mưa hay không.
X, Y = df.drop('RainTomorrow', axis=1, inplace=False), df[['RainTomorrow']]
# Normalizing Data
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Converting to PyTorch tensor
X_tensor = torch.FloatTensor(X_scaled)
# Converting string labels to numerical labels
label_encoder = LabelEncoder()
Y_numerical = label_encoder.fit_transform(Y.values.ravel())Trong PyTorch, giờ chúng ta có thể định nghĩa mô hình Autoencoder như một lớp và chỉ định các mô hình encoder và decoder với hai tầng tuyến tính.
# Defining Autoencoder model
class Autoencoder(nn.Module):
def __init__(self, input_size, encoding_dim):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(input_size, 16),
nn.ReLU(),
nn.Linear(16, encoding_dim),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.Linear(encoding_dim, 16),
nn.ReLU(),
nn.Linear(16, input_size),
nn.Sigmoid()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return xBây giờ mô hình đã được thiết lập, chúng ta có thể chỉ định số chiều mã hóa bằng 3 (để dễ vẽ sau này) và chạy quá trình huấn luyện.
# Setting random seed for reproducibility
torch.manual_seed(42)
input_size = X.shape[1] # Number of input features
encoding_dim = 3 # Desired number of output dimensions
model = Autoencoder(input_size, encoding_dim)
# Loss function and optimizer
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.003)
# Training the autoencoder
num_epochs = 20
for epoch in range(num_epochs):
# Forward pass
outputs = model(X_tensor)
loss = criterion(outputs, X_tensor)
# Backward pass and optimization
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Loss for each epoch
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
# Encoding the data using the trained autoencoder
encoded_data = model.encoder(X_tensor).detach().numpy()Epoch [1/20], Loss: 1.2443
Epoch [2/20], Loss: 1.2410
Epoch [3/20], Loss: 1.2376
Epoch [4/20], Loss: 1.2342
Epoch [5/20], Loss: 1.2307
Epoch [6/20], Loss: 1.2271
Epoch [7/20], Loss: 1.2234
Epoch [8/20], Loss: 1.2196
Epoch [9/20], Loss: 1.2156
Epoch [10/20], Loss: 1.2114
Epoch [11/20], Loss: 1.2070
Epoch [12/20], Loss: 1.2023
Epoch [13/20], Loss: 1.1974
Epoch [14/20], Loss: 1.1923
Epoch [15/20], Loss: 1.1868
Epoch [16/20], Loss: 1.1811
Epoch [17/20], Loss: 1.1751
Epoch [18/20], Loss: 1.1688
Epoch [19/20], Loss: 1.1622
Epoch [20/20], Loss: 1.1554Cuối cùng, giờ chúng ta có thể vẽ các chiều nhúng thu được (Hình 4). Như có thể thấy ở hình bên dưới, chúng ta đã giảm thành công số chiều của tập đặc trưng từ 17 xuống chỉ còn 3, trong khi vẫn có thể, ở mức độ tốt, tách biệt đúng trong không gian 3 chiều giữa các mẫu thuộc các lớp khác nhau.
# Plotting the encoded data in 3D space
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, projection='3d')
scatter = ax.scatter(encoded_data[:, 0], encoded_data[:, 1],
encoded_data[:, 2], c=Y_numerical, cmap='viridis')
# Mapping numerical labels back to original string labels for the legend
labels = label_encoder.inverse_transform(np.unique(Y_numerical))
legend_labels = {num: label for num, label in zip(np.unique(Y_numerical),
labels)}
# Creating a custom legend with original string labels
handles = [plt.Line2D([0], [0], marker='o', color='w',
markerfacecolor=scatter.to_rgba(num),
markersize=10,
label=legend_labels[num]) for num in np.unique(Y_numerical)]
ax.legend(handles=handles, title="Raining Tomorrow?")
# Adjusting the layout to provide more space for labels
ax.xaxis.labelpad = 20
ax.yaxis.labelpad = 20
ax.set_xticks([])
ax.set_yticks([])
ax.set_zticks([])
# Manually adding z-axis label for better visibility
ax.text2D(0.05, 0.95, 'Encoded Dimension 3', transform=ax.transAxes,
fontsize=12, color='black')
ax.set_xlabel('Encoded Dimension 1')
ax.set_ylabel('Encoded Dimension 2')
ax.set_title('Autoencoder Dimensionality Reduction')
plt.tight_layout()
plt.savefig('Rain_Prediction_Autoencoder.png')
plt.show()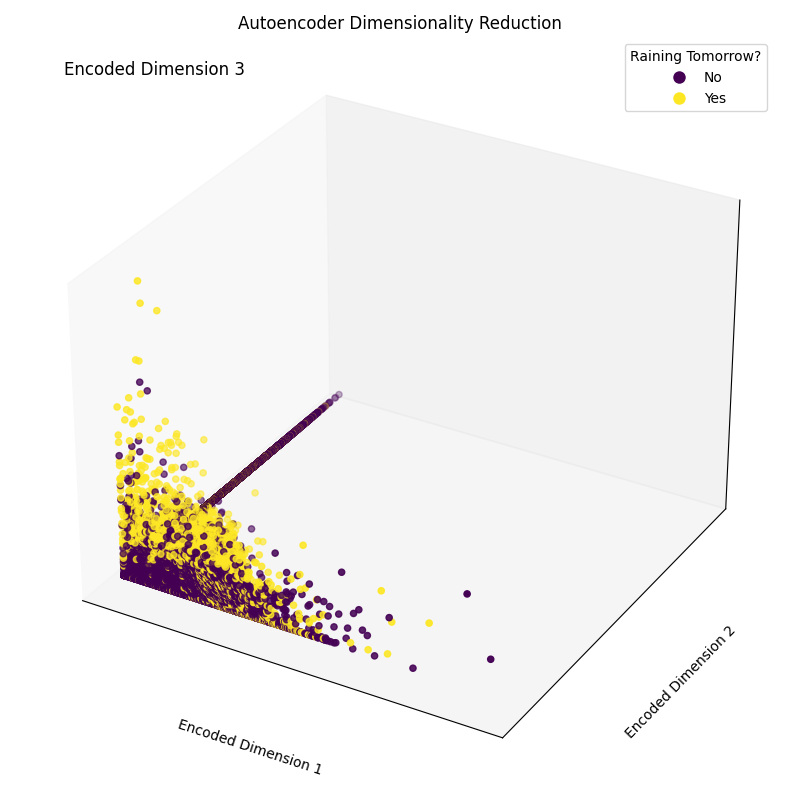
Hình 4: Các chiều mã hóa thu được (Ảnh của tác giả).
Một trong những ứng dụng chính của Autoencoder là nén ảnh để giảm kích thước tệp tổng thể trong khi cố gắng giữ lại tối đa thông tin giá trị, hoặc khôi phục những ảnh bị suy giảm theo thời gian.
Vì Autoencoder giỏi trong việc phân biệt đặc trưng cốt lõi của dữ liệu khỏi nhiễu, chúng có thể được dùng để phát hiện bất thường (ví dụ: ảnh bị chỉnh sửa, hoạt động bất thường trên mạng, v.v.).
Variational Autoencoder và Mạng đối sinh (GAN) thường được dùng để tạo dữ liệu tổng hợp (ví dụ: ảnh người chân thực).
Tóm lại, Autoencoder có thể là một công cụ rất linh hoạt để phục vụ nhiều dạng bài toán khác nhau. Đặc biệt, Variational Autoencoder và việc tạo ra GAN đã mở cánh cửa cho sự phát triển của AI sinh nội dung, cho chúng ta thấy những hình dung đầu tiên về cách AI có thể tạo ra những dạng nội dung chưa từng có.
Hướng dẫn này là phần giới thiệu về lĩnh vực Autoencoder, và vẫn còn rất nhiều điều để học! DataCamp có nhiều tài nguyên về chủ đề này, như cách triển khai Autoencoder trong Keras hoặc dùng chúng như một bộ phân loại!
Bắt đầu hành trình Deep Learning của bạn ngay hôm nay!
Courses
Courses
Courses