
Cursus
Introductie tot Deep Learning in Python
4 Hr
264K
Traditionele feedforward-neurale netwerken zijn uitstekend voor taken als classificatie en regressie, maar wat als je oplossingen wilt implementeren zoals signaalontruising of anomaliedetectie? Een manier om dit te doen is met auto-encoders.
Deze tutorial biedt een praktische introductie tot auto-encoders, inclusief een hands-on voorbeeld in PyTorch en enkele mogelijke use-cases.
Je kunt meekijken in deze DataLab-workbook met alle code uit de tutorial.
Auto-encoders zijn een speciaal type onbewaakt feedforward-neuraal netwerk (geen labels nodig!). De belangrijkste toepassing van auto-encoders is het nauwkeurig vastleggen van de kerneigenschappen van de aangeleverde data om zo een gecomprimeerde versie van de invoerdata te leveren, realistische synthetische data te genereren of anomalieën te signaleren.
Auto-encoders bestaan uit 2 cruciale volledig verbonden feedforward-neurale netwerken (Figuur 1):
Door dit proces van data door de encoder en decoder sturen en de fout meten om de parameters via backpropagatie bij te stellen iteratief te herhalen, kan de auto-encoder na verloop van tijd correct omgaan met zeer complexe vormen van data.
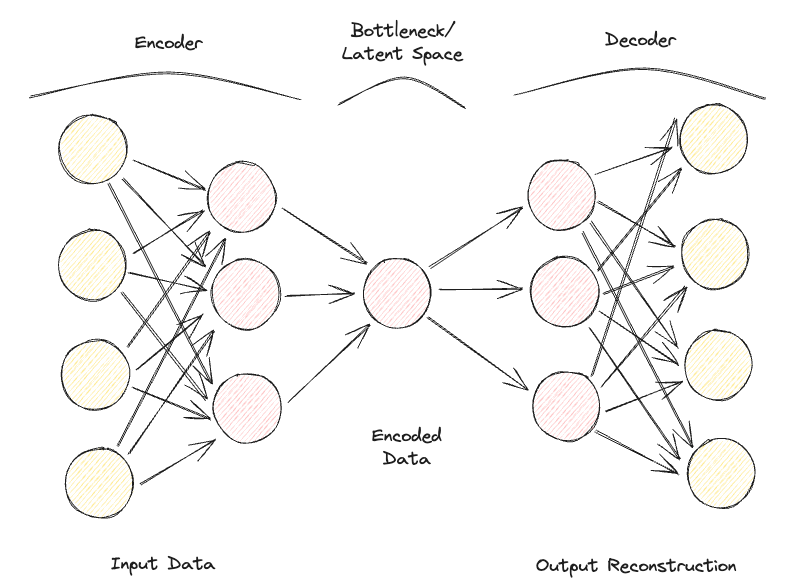
Figuur 1: Architectuur van een auto-encoder (afbeelding door auteur).
Als een auto-encoder een set invoerkenmerken krijgt die volledig onafhankelijk van elkaar zijn, dan is het voor het model erg moeilijk om een goede lager-dimensionale representatie te vinden zonder veel informatie te verliezen (lossy compressie).
Auto-encoders kunnen daarom ook worden beschouwd als een techniek voor dimensionale reductie, die, vergeleken met traditionele technieken zoals Principal Component Analysis (PCA), gebruik kan maken van niet-lineaire transformaties om data naar een lagere-dimensionale ruimte te projecteren. Als je meer wilt leren over andere feature-extractietechnieken, is er extra informatie in deze tutorial over feature-extractie.
Daarnaast kunnen auto-encoders, in tegenstelling tot standaard compressie-algoritmen zoals gzip, niet worden gebruikt als algemene compressie-algoritmen, maar zijn ze met de hand ontworpen om optimaal te werken op vergelijkbare data als waarop ze zijn getraind.
Enkele van de meest gangbare hyperparameters die je kunt afstemmen bij het optimaliseren van je auto-encoder zijn:
Tot slot kunnen auto-encoders worden ontworpen voor verschillende soorten data, zoals tabel-, tijdreeks- of beelddata, en kunnen ze dus ook verschillende lagen gebruiken, zoals convolutionele lagen voor beeldanalyse.
Idealiter is een goed getrainde auto-encoder responsief genoeg om zich aan te passen aan de invoerdata om een maatwerkantwoord te geven, maar niet zózeer dat hij de invoerdata slechts napapegaait en niet kan generaliseren naar onzichtbare data (overfitting).
In de loop der jaren zijn er verschillende typen auto-encoders ontwikkeld:
Laten we ze elk wat nader bekijken.
Dit is de simpelste versie van een auto-encoder. In dit geval hebben we geen expliciet regularisatiemechanisme, maar we zorgen ervoor dat de grootte van de bottleneck altijd kleiner is dan de oorspronkelijke invoergrootte om overfitting te voorkomen. Dit type configuratie wordt meestal gebruikt als techniek voor dimensionale reductie (krachtiger dan PCA omdat het ook niet-lineariteiten in de data kan vastleggen).
Een sparse auto-encoder lijkt sterk op een undercomplete auto-encoder, maar het belangrijkste verschil zit in hoe regularisatie wordt toegepast. Bij sparse auto-encoders hoeven we namelijk niet per se de dimensies van de bottleneck te verkleinen; we gebruiken een verliesfunctie die het model probeert te bestraffen voor het benutten van al zijn neuronen in de verschillende verborgen lagen (Figuur 2).
Deze straf wordt vaak een sparsiteitsfunctie genoemd en verschilt behoorlijk van traditionele regularisatietechnieken, omdat hij niet focust op het straffen van de grootte van de gewichten maar op het aantal geactiveerde nodes.
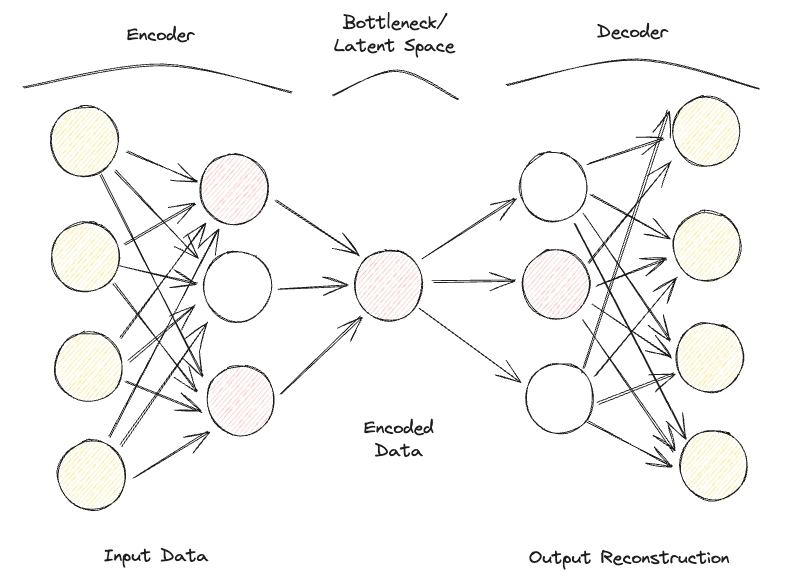
Zo kunnen verschillende nodes zich specialiseren in verschillende invoertypen en geactiveerd/gedeactiveerd worden afhankelijk van de specificaties van de invoerdata. Deze sparsiteitsrestrictie kan worden opgelegd met L1-regularisatie en KL-divergentie en voorkomt effectief dat het model overfit.
Het hoofdidée achter contractive auto-encoders is dat, gegeven enkele vergelijkbare invoeren, hun gecomprimeerde representaties ook behoorlijk vergelijkbaar moeten zijn (buren in de invoerruimte moeten samentrekken tot kleine buurten in de uitvoerruimte). In wiskundige termen kan dit worden afgedwongen door de afgeleiden van de activaties in de verborgen laag klein te houden wanneer vergelijkbare invoeren worden aangeboden.
Bij denoising auto-encoders zijn de invoer en uitvoer van het model niet langer hetzelfde. Zo kan het model bijvoorbeeld lage-resolutie, corrupte afbeeldingen krijgen en als uitvoer de kwaliteit van de afbeeldingen proberen te verbeteren. Om de prestaties van het model te beoordelen en het in de tijd te verbeteren, hebben we dan een vorm van gelabelde, schone afbeelding nodig om met de modelvoorspelling te vergelijken.
Om met beelddata te werken, vervangen convolutionele auto-encoders traditionele feedforward-neurale netwerken door convolutionele neurale netwerken voor zowel de encoder- als decoderstap. Met aanpassing van de verliesfunctie, enzovoort, kan dit type auto-encoder bijvoorbeeld ook sparse of denoising worden gemaakt, afhankelijk van de eisen van je use-case.
In alle typen auto-encoders die tot nu toe zijn besproken, geeft de encoder één enkele waarde voor elke betrokken dimensie. Bij variational auto-encoders (VAE) maken we dit proces probabilistisch en creëren we een kansverdeling voor elke dimensie. De decoder kan vervolgens een waarde samplen uit elke verdeling die de verschillende dimensies beschrijft en zo de invoervector construeren, die vervolgens kan worden gebruikt om de oorspronkelijke invoerdata te reconstrueren.
Een van de belangrijkste toepassingen van variational auto-encoders is voor generatieve taken. Door te sampelen uit de latente modelverdelingen kan de decoder namelijk nieuwe vormen van output creëren die eerder niet mogelijk waren met een deterministische aanpak.
Als je online een variational auto-encoder wilt testen die getraind is op de MNIST-dataset, vind je hier een livevoorbeeld.
We zijn nu klaar voor een praktische demonstratie van hoe auto-encoders kunnen worden gebruikt voor dimensionale reductie. Ons deep learning-framework voor deze oefening is PyTorch.
Voor deze demonstratie gebruiken we de Kaggle Rain in Australia-dataset. Alle code uit dit artikel is beschikbaar in deze DataLab-workbook.
Allereerst importeren we alle benodigde libraries en verwijderen we missende waarden en niet-numerieke kolommen (Figuur 3).
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler, LabelEncoder
from mpl_toolkits.mplot3d import Axes3D
df = pd.read_csv("../input/weather-dataset-rattle-package/weatherAUS.csv")
df = df.drop(['Date', 'Location', 'WindDir9am',
'WindGustDir', 'WindDir3pm'], axis=1)
df = df.dropna(how = 'any')
df.loc[df['RainToday'] == 'No', 'RainToday'] = 0
df.loc[df['RainToday'] == 'Yes', 'RainToday'] = 1
df.head()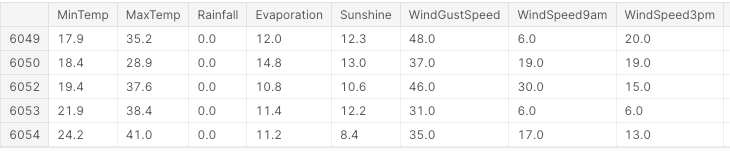
Figuur 3: Voorbeeld van datasetkolommen (afbeelding door auteur).
Op dit punt kunnen we de data opdelen in features en labels, de features normaliseren en de labels naar een numeriek formaat omzetten.
In dit geval starten we met een featureset van 17 kolommen. Het overkoepelende doel van de analyse is vervolgens om correct te voorspellen of het de volgende dag gaat regenen of niet.
X, Y = df.drop('RainTomorrow', axis=1, inplace=False), df[['RainTomorrow']]
# Normalizing Data
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Converting to PyTorch tensor
X_tensor = torch.FloatTensor(X_scaled)
# Converting string labels to numerical labels
label_encoder = LabelEncoder()
Y_numerical = label_encoder.fit_transform(Y.values.ravel())In PyTorch kunnen we nu het auto-encodermodel als een klasse definiëren en de encoder- en decoder-modellen specificeren met twee lineaire lagen.
# Defining Autoencoder model
class Autoencoder(nn.Module):
def __init__(self, input_size, encoding_dim):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(input_size, 16),
nn.ReLU(),
nn.Linear(16, encoding_dim),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.Linear(encoding_dim, 16),
nn.ReLU(),
nn.Linear(16, input_size),
nn.Sigmoid()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return xNu het model staat, kunnen we onze encoding-dimensies instellen op 3 (zodat we ze later makkelijk kunnen plotten) en het trainingsproces doorlopen.
# Setting random seed for reproducibility
torch.manual_seed(42)
input_size = X.shape[1] # Number of input features
encoding_dim = 3 # Desired number of output dimensions
model = Autoencoder(input_size, encoding_dim)
# Loss function and optimizer
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.003)
# Training the autoencoder
num_epochs = 20
for epoch in range(num_epochs):
# Forward pass
outputs = model(X_tensor)
loss = criterion(outputs, X_tensor)
# Backward pass and optimization
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Loss for each epoch
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
# Encoding the data using the trained autoencoder
encoded_data = model.encoder(X_tensor).detach().numpy()Epoch [1/20], Loss: 1.2443
Epoch [2/20], Loss: 1.2410
Epoch [3/20], Loss: 1.2376
Epoch [4/20], Loss: 1.2342
Epoch [5/20], Loss: 1.2307
Epoch [6/20], Loss: 1.2271
Epoch [7/20], Loss: 1.2234
Epoch [8/20], Loss: 1.2196
Epoch [9/20], Loss: 1.2156
Epoch [10/20], Loss: 1.2114
Epoch [11/20], Loss: 1.2070
Epoch [12/20], Loss: 1.2023
Epoch [13/20], Loss: 1.1974
Epoch [14/20], Loss: 1.1923
Epoch [15/20], Loss: 1.1868
Epoch [16/20], Loss: 1.1811
Epoch [17/20], Loss: 1.1751
Epoch [18/20], Loss: 1.1688
Epoch [19/20], Loss: 1.1622
Epoch [20/20], Loss: 1.1554Tot slot kunnen we nu de resulterende embedding-dimensies plotten (Figuur 4). Zoals te zien is in de afbeelding hieronder, is het ons gelukt om de dimensionaliteit van onze featureset terug te brengen van 17 dimensies naar slechts 3, terwijl we nog steeds in zekere mate de verschillende klassen correct kunnen scheiden in onze 3D-ruimte.
# Plotting the encoded data in 3D space
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, projection='3d')
scatter = ax.scatter(encoded_data[:, 0], encoded_data[:, 1],
encoded_data[:, 2], c=Y_numerical, cmap='viridis')
# Mapping numerical labels back to original string labels for the legend
labels = label_encoder.inverse_transform(np.unique(Y_numerical))
legend_labels = {num: label for num, label in zip(np.unique(Y_numerical),
labels)}
# Creating a custom legend with original string labels
handles = [plt.Line2D([0], [0], marker='o', color='w',
markerfacecolor=scatter.to_rgba(num),
markersize=10,
label=legend_labels[num]) for num in np.unique(Y_numerical)]
ax.legend(handles=handles, title="Raining Tomorrow?")
# Adjusting the layout to provide more space for labels
ax.xaxis.labelpad = 20
ax.yaxis.labelpad = 20
ax.set_xticks([])
ax.set_yticks([])
ax.set_zticks([])
# Manually adding z-axis label for better visibility
ax.text2D(0.05, 0.95, 'Encoded Dimension 3', transform=ax.transAxes,
fontsize=12, color='black')
ax.set_xlabel('Encoded Dimension 1')
ax.set_ylabel('Encoded Dimension 2')
ax.set_title('Autoencoder Dimensionality Reduction')
plt.tight_layout()
plt.savefig('Rain_Prediction_Autoencoder.png')
plt.show()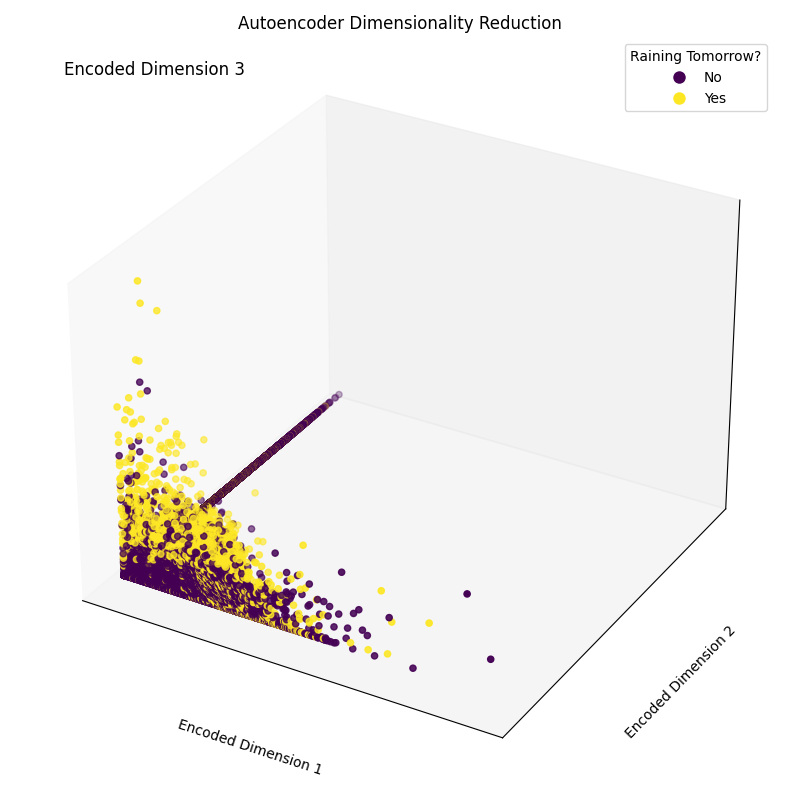
Figuur 4: Resulterende gecodeerde dimensies (afbeelding door auteur).
Een van de belangrijkste toepassingen van auto-encoders is het comprimeren van afbeeldingen om de totale bestandsgrootte te verkleinen, terwijl je zoveel mogelijk waardevolle informatie behoudt, of het herstellen van afbeeldingen die in de tijd zijn gedegradeerd.
Omdat auto-encoders goed zijn in het onderscheiden van essentiële kenmerken van data en ruis, kunnen ze worden gebruikt om anomalieën te detecteren (bijv. of een afbeelding is gefotoshopt, of er ongebruikelijke activiteiten in een netwerk zijn, enz.).
Variational auto-encoders en Generative Adversarial Networks (GAN) worden vaak gebruikt om synthetische data te genereren (bijv. realistische beelden van mensen).
Kortom, auto-encoders zijn een zeer flexibele tool voor uiteenlopende use-cases. In het bijzonder hebben variational auto-encoders en de ontwikkeling van GAN’s de deur geopend naar Generative AI en ons de eerste glimp gegeven van hoe AI nieuwe vormen van content kan genereren die we nog niet eerder zagen.
Deze tutorial was een introductie tot het veld van auto-encoders, al valt er nog veel te leren! DataCamp heeft een breed scala aan bronnen over dit onderwerp, zoals hoe je auto-encoders in Keras implementeert of hoe je ze gebruikt als classifier!
Begin vandaag nog aan je deep learning-reis!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
