
Kurs
Einführung in Deep Learning mit Python
4 Std.
263.5K
Herkömmliche neuronale Netze mit Vorwärtskopplung eignen sich hervorragend für Aufgaben wie Klassifizierung und Regression, aber was ist, wenn wir Lösungen wie Signalentrauschung oder Anomalieerkennung umsetzen möchten? Eine Möglichkeit, dies zu tun, ist der Einsatz von Autoencodern.
Dieses Tutorial bietet eine praktische Einführung in Autoencoders, einschließlich eines praktischen Beispiels in PyTorch und einiger möglicher Anwendungsfälle.
Du kannst in dieser DataLab-Arbeitsmappe mit dem gesamten Code aus dem Lehrgang mitmachen.
Autoencoder sind eine besondere Art von unüberwachten neuronalen Netzen mit Vorwärtskopplung (keine Labels erforderlich!). Die Hauptanwendung von Autoencodern besteht darin, die wichtigsten Aspekte der bereitgestellten Daten genau zu erfassen, um eine komprimierte Version der Eingabedaten zu erstellen, realistische synthetische Daten zu erzeugen oder Anomalien zu erkennen.
Autoencoder bestehen aus 2 vollständig verbundenen neuronalen Netzen mit Vorwärtskopplung (Abbildung 1):
Wenn du diesen Prozess, bei dem die Daten durch den Encoder und den Decoder geleitet werden, iterativ wiederholst und den Fehler misst, um die Parameter durch Backpropagation zu optimieren, kann der Autoencoder mit der Zeit auch mit extrem schwierigen Daten arbeiten.
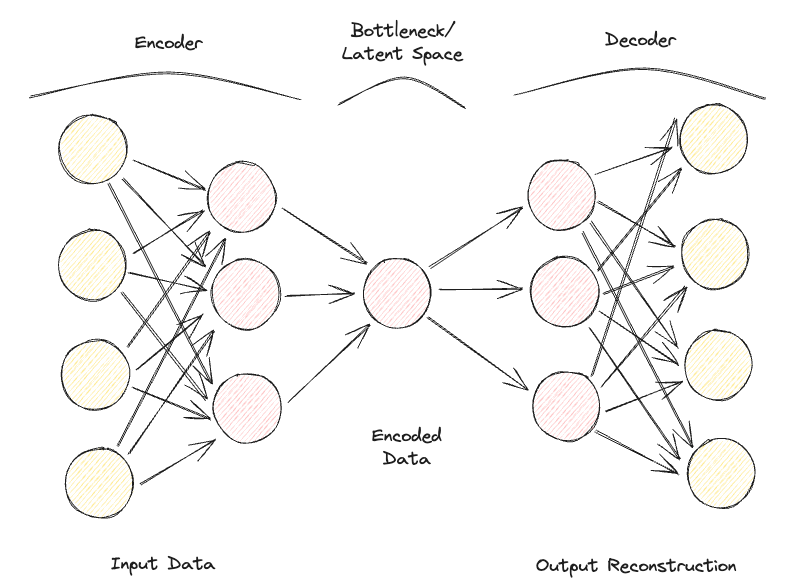
Abbildung 1: Autoencoder-Architektur (Bild vom Autor).
Wenn ein Autoencoder eine Reihe von völlig unabhängigen Eingangsmerkmalen erhält, wäre es für das Modell sehr schwierig, eine gute niederdimensionale Darstellung zu finden, ohne dabei viele Informationen zu verlieren (verlustbehaftete Kompression).
Autoencoder können daher auch als eine Technik zur Dimensionalitätsreduzierung betrachtet werden, die im Vergleich zu traditionellen Techniken wie der Hauptkomponentenanalyse (PCA) nichtlineare Transformationen nutzen kann, um Daten in einen weniger dimensionalen Raum zu projizieren. Wenn du mehr über andere Techniken der Merkmalsextraktion erfahren möchtest, findest du weitere Informationen in diesem Tutorial zur Merkmalsextraktion.
Im Gegensatz zu Standard-Komprimierungsalgorithmen wie gzpi können Autoencoder nicht als Allzweck-Komprimierungsalgorithmen verwendet werden, sondern sind so konzipiert, dass sie nur für ähnliche Daten, auf denen sie trainiert wurden, am besten funktionieren.
Einige der häufigsten Hyperparameter, die bei der Optimierung deines Autoencoders eingestellt werden können, sind:
Schließlich können Autoencoder für verschiedene Datentypen entwickelt werden, z. B. für Tabellen-, Zeitreihen- oder Bilddaten, und können daher eine Vielzahl von Schichten, wie z. B. Faltungsschichten, für die Bildanalyse verwenden.
Im Idealfall sollte ein gut trainierter Autoencoder so reaktionsschnell sein, dass er sich an die Eingabedaten anpasst, um eine maßgeschneiderte Antwort zu liefern, aber nicht so sehr, dass er die Eingabedaten nur nachahmt und nicht in der Lage ist, mit ungesehenen Daten zu verallgemeinern (daher Overfitting).
Im Laufe der Jahre sind verschiedene Arten von Autoencodern entwickelt worden:
Schauen wir uns die einzelnen Punkte genauer an.
Dies ist die einfachste Version eines Autoencoders. In diesem Fall haben wir keinen expliziten Regularisierungsmechanismus, aber wir stellen sicher, dass die Größe des Engpasses immer kleiner ist als die ursprüngliche Eingabegröße, um eine Überanpassung zu vermeiden. Diese Art der Konfiguration wird in der Regel zur Dimensionalitätsreduktion eingesetzt (sie ist leistungsfähiger als PCA, da sie auch Nichtlinearitäten in den Daten erfassen kann).
Ein Sparse Autoencoder ist einem Undercomplete Autoencoder sehr ähnlich, aber der Hauptunterschied liegt darin, wie die Regularisierung angewendet wird. Bei Sparse Autoencodern müssen wir nicht unbedingt die Dimensionen des Engpasses reduzieren, sondern wir verwenden eine Verlustfunktion, die versucht, das Modell dafür zu bestrafen, dass es alle Neuronen in den verschiedenen versteckten Schichten nutzt (Abbildung 2).
Diese Strafe wird gemeinhin als Sparsamkeitsfunktion bezeichnet und unterscheidet sich deutlich von traditionellen Regularisierungsverfahren, da sie nicht die Größe der Gewichte, sondern die Anzahl der aktivierten Knoten bestraft.
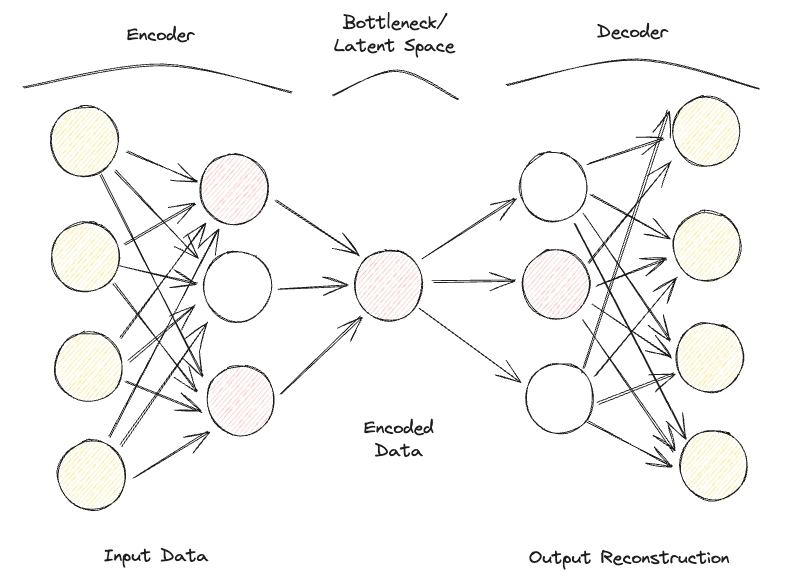
Auf diese Weise könnten sich verschiedene Knotenpunkte auf unterschiedliche Eingabearten spezialisieren und je nach den Besonderheiten der Eingabedaten aktiviert/deaktiviert werden. Diese Sparsamkeitsbeschränkung kann mit Hilfe der L1-Regularisierung und der KL-Divergenz herbeigeführt werden, wodurch eine Überanpassung des Modells effektiv verhindert wird.
Die Hauptidee hinter den kontraktiven Autoencodern ist, dass bei ähnlichen Eingaben ihre komprimierte Darstellung ziemlich ähnlich sein sollte (Nachbarschaften von Eingaben sollten in kleinen Nachbarschaften von Ausgaben kontrahiert werden). Mathematisch gesehen kann dies dadurch erreicht werden, dass die Aktivierungen der versteckten Eingabeschichten klein gehalten werden, wenn ähnliche Eingaben eingegeben werden.
Bei Denoising-Autoencodern sind der Eingang und der Ausgang des Modells nicht mehr identisch. Das Modell könnte z.B. mit beschädigten Bildern mit niedriger Auflösung gefüttert werden und darauf hinarbeiten, die Qualität der Bilder zu verbessern. Um die Leistung des Modells zu bewerten und es im Laufe der Zeit zu verbessern, bräuchten wir dann eine Art beschriftetes, sauberes Bild, das wir mit der Modellvorhersage vergleichen können.
Um mit Bilddaten zu arbeiten, ersetzen Convolutional Autoencoders herkömmliche neuronale Feedforward-Netzwerke durch Convolutional Neural Networks sowohl für den Encoder- als auch für den Decoder-Schritt. Diese Art von Autoencoder kann je nach den Anforderungen deines Anwendungsfalls z. B. als Sparse oder Denoising ausgeführt werden.
Bei allen bisher betrachteten Arten von Autoencodern gibt der Encoder einen einzigen Wert für jede beteiligte Dimension aus. Mit Variationalen Autoencodern (VAE) machen wir diesen Prozess stattdessen probabilistisch, indem wir eine Wahrscheinlichkeitsverteilung für jede Dimension erstellen. Der Decoder kann dann aus jeder Verteilung, die die verschiedenen Dimensionen beschreibt, einen Wert entnehmen und den Eingangsvektor konstruieren, der dann zur Rekonstruktion der ursprünglichen Eingangsdaten verwendet werden kann.
Eine der Hauptanwendungen von Variational Autoencodern sind generative Aufgaben. Durch das Sampling des latenten Modells aus Verteilungen kann der Decoder neue Formen von Ausgaben erzeugen, die mit einem deterministischen Ansatz bisher nicht möglich waren.
Wenn du daran interessiert bist, einen Online-Variations-Autoencoder zu testen, der mit dem MNIST-Datensatz trainiert wurde, findest du hier ein Live-Beispiel.
Wir können nun anhand einer praktischen Demonstration zeigen, wie Autoencoder zur Dimensionalitätsreduktion eingesetzt werden können. Unser Deep Learning-Framework der Wahl für diese Übung ist PyTorch.
Der Kaggle-Datensatz "Rain in Australia" wird für diese Demonstration verwendet. Der gesamte Code dieses Artikels ist in dieser DataLab-Arbeitsmappe verfügbar.
Zunächst importieren wir alle notwendigen Bibliotheken und entfernen alle fehlenden Werte und nicht-numerischen Spalten (Abbildung 3).
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler, LabelEncoder
from mpl_toolkits.mplot3d import Axes3D
df = pd.read_csv("../input/weather-dataset-rattle-package/weatherAUS.csv")
df = df.drop(['Date', 'Location', 'WindDir9am',
'WindGustDir', 'WindDir3pm'], axis=1)
df = df.dropna(how = 'any')
df.loc[df['RainToday'] == 'No', 'RainToday'] = 0
df.loc[df['RainToday'] == 'Yes', 'RainToday'] = 1
df.head()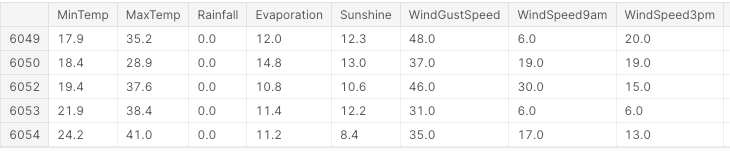
Abbildung 3: Beispiel für Datensatzspalten (Bild vom Autor).
Jetzt können wir die Daten in Merkmale und Bezeichnungen unterteilen, die Merkmale normalisieren und die Bezeichnungen in ein numerisches Format umwandeln.
In diesem Fall haben wir ein Start-Feature-Set, das aus 17 Spalten besteht. Das übergeordnete Ziel der Analyse wäre es dann, richtig vorherzusagen, ob es am nächsten Tag regnen wird oder nicht.
X, Y = df.drop('RainTomorrow', axis=1, inplace=False), df[['RainTomorrow']]
# Normalizing Data
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Converting to PyTorch tensor
X_tensor = torch.FloatTensor(X_scaled)
# Converting string labels to numerical labels
label_encoder = LabelEncoder()
Y_numerical = label_encoder.fit_transform(Y.values.ravel())In PyTorch können wir nun das Autoencoder-Modell als Klasse definieren und die Encoder- und Decoder-Modelle mit zwei linearen Schichten angeben.
# Defining Autoencoder model
class Autoencoder(nn.Module):
def __init__(self, input_size, encoding_dim):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(input_size, 16),
nn.ReLU(),
nn.Linear(16, encoding_dim),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.Linear(encoding_dim, 16),
nn.ReLU(),
nn.Linear(16, input_size),
nn.Sigmoid()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return xJetzt, wo das Modell eingerichtet ist, können wir unsere Kodierungsdimensionen auf 3 festlegen (damit wir sie später leichter aufzeichnen können) und den Trainingsprozess durchlaufen.
# Setting random seed for reproducibility
torch.manual_seed(42)
input_size = X.shape[1] # Number of input features
encoding_dim = 3 # Desired number of output dimensions
model = Autoencoder(input_size, encoding_dim)
# Loss function and optimizer
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.003)
# Training the autoencoder
num_epochs = 20
for epoch in range(num_epochs):
# Forward pass
outputs = model(X_tensor)
loss = criterion(outputs, X_tensor)
# Backward pass and optimization
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Loss for each epoch
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
# Encoding the data using the trained autoencoder
encoded_data = model.encoder(X_tensor).detach().numpy()Epoch [1/20], Loss: 1.2443
Epoch [2/20], Loss: 1.2410
Epoch [3/20], Loss: 1.2376
Epoch [4/20], Loss: 1.2342
Epoch [5/20], Loss: 1.2307
Epoch [6/20], Loss: 1.2271
Epoch [7/20], Loss: 1.2234
Epoch [8/20], Loss: 1.2196
Epoch [9/20], Loss: 1.2156
Epoch [10/20], Loss: 1.2114
Epoch [11/20], Loss: 1.2070
Epoch [12/20], Loss: 1.2023
Epoch [13/20], Loss: 1.1974
Epoch [14/20], Loss: 1.1923
Epoch [15/20], Loss: 1.1868
Epoch [16/20], Loss: 1.1811
Epoch [17/20], Loss: 1.1751
Epoch [18/20], Loss: 1.1688
Epoch [19/20], Loss: 1.1622
Epoch [20/20], Loss: 1.1554Abschließend können wir nun die resultierenden Einbettungsdimensionen aufzeichnen (Abbildung 4). Wie in der Abbildung unten zu sehen ist, ist es uns gelungen, die Dimensionalität unseres Merkmalsatzes von 17 Dimensionen auf nur 3 zu reduzieren, während wir immer noch in der Lage sind, in unserem dreidimensionalen Raum die verschiedenen Klassen korrekt zu unterscheiden.
# Plotting the encoded data in 3D space
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, projection='3d')
scatter = ax.scatter(encoded_data[:, 0], encoded_data[:, 1],
encoded_data[:, 2], c=Y_numerical, cmap='viridis')
# Mapping numerical labels back to original string labels for the legend
labels = label_encoder.inverse_transform(np.unique(Y_numerical))
legend_labels = {num: label for num, label in zip(np.unique(Y_numerical),
labels)}
# Creating a custom legend with original string labels
handles = [plt.Line2D([0], [0], marker='o', color='w',
markerfacecolor=scatter.to_rgba(num),
markersize=10,
label=legend_labels[num]) for num in np.unique(Y_numerical)]
ax.legend(handles=handles, title="Raining Tomorrow?")
# Adjusting the layout to provide more space for labels
ax.xaxis.labelpad = 20
ax.yaxis.labelpad = 20
ax.set_xticks([])
ax.set_yticks([])
ax.set_zticks([])
# Manually adding z-axis label for better visibility
ax.text2D(0.05, 0.95, 'Encoded Dimension 3', transform=ax.transAxes,
fontsize=12, color='black')
ax.set_xlabel('Encoded Dimension 1')
ax.set_ylabel('Encoded Dimension 2')
ax.set_title('Autoencoder Dimensionality Reduction')
plt.tight_layout()
plt.savefig('Rain_Prediction_Autoencoder.png')
plt.show()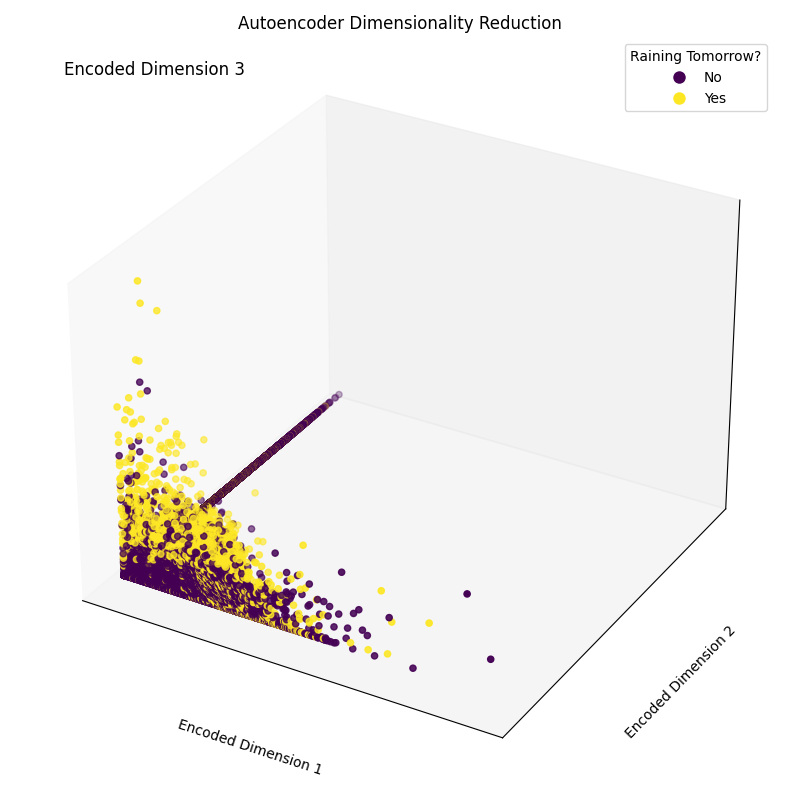
Abbildung 4: Ergebnis der kodierten Dimensionen (Bild vom Autor).
Eine der Hauptanwendungen von Autoencodern ist es, Bilder zu komprimieren, um ihre Dateigröße zu verringern und dabei so viele wertvolle Informationen wie möglich zu erhalten oder Bilder wiederherzustellen, die im Laufe der Zeit beschädigt wurden.
Da Autoencoder gut darin sind, wesentliche Merkmale von Daten von Rauschen zu unterscheiden, können sie eingesetzt werden, um Anomalien zu erkennen (z. B. ob ein Bild mit Photoshop bearbeitet wurde, ob es ungewöhnliche Aktivitäten in einem Netzwerk gibt usw.)
Variationale Autoencoder und Generative Adversarial Networks (GAN) werden häufig eingesetzt, um synthetische Daten zu erzeugen (z. B. realistische Bilder von Menschen).
Zusammenfassend lässt sich sagen, dass Autoencoder ein sehr flexibles Werkzeug für verschiedene Anwendungsfälle sein können. Insbesondere Variational Autoencoders und die Entwicklung von GANs öffneten die Tür zur Entwicklung der Generativen KI und gaben uns erste Einblicke, wie KI genutzt werden kann, um neue, noch nie dagewesene Formen von Inhalten zu erzeugen.
Dieses Tutorial war eine Einführung in das Gebiet der Autoencoder, obwohl es noch viel zu lernen gibt! DataCamp hat eine Vielzahl von Ressourcen zu diesem Thema, z. B. wie man Autoencoder in Keras implementiert oder sie als Klassifikator einsetzt!
Beginne deine Deep Learning-Reise noch heute!
Kurs
Kurs
Kurs
Tutorial
Matt Crabtree
Tutorial
Mark Pedigo
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team
Tutorial
Javier Canales Luna
Tutorial
Satyabrata Pal
