
Curso
Introdução a Deep Learning em Python
4 h
263.5K
As redes neurais feedforward tradicionais podem ser ótimas para realizar tarefas como classificação e regressão, mas e se quisermos implementar soluções como redução de ruído de sinal ou detecção de anomalias? Uma maneira de fazer isso é usar Autoencoders.
Este tutorial oferece uma introdução prática aos Autoencoders, incluindo um exemplo prático no PyTorch e alguns casos de uso em potencial.
Você pode acompanhar esta pasta de trabalho do DataLab com todo o código do tutorial.
Os autoencoders são um tipo especial de rede neural feedforward não supervisionada (não são necessários rótulos!). A principal aplicação dos Autoencoders é capturar com precisão os principais aspectos dos dados fornecidos para fornecer uma versão compactada dos dados de entrada, gerar dados sintéticos realistas ou sinalizar anomalias.
Os autoencodificadores são compostos por duas redes neurais feedforward totalmente conectadas (Figura 1):
Repetindo iterativamente esse processo de passagem de dados pelo codificador e decodificador e medindo o erro para ajustar os parâmetros por meio da retropropagação, o Autoencoder pode, com o tempo, trabalhar corretamente com formas de dados extremamente difíceis.
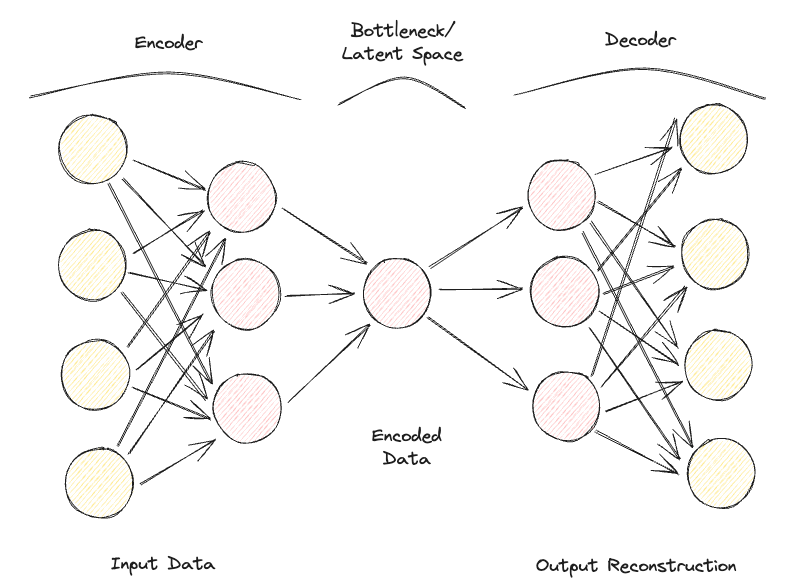
Figura 1: Arquitetura do codificador automático (imagem do autor).
Se um codificador automático receber um conjunto de recursos de entrada completamente independentes uns dos outros, será muito difícil para o modelo encontrar uma boa representação de dimensão inferior sem perder uma grande quantidade de informações (compactação com perdas).
Portanto, os autoencodificadores também podem ser considerados uma técnica de redução de dimensionalidade que, comparada às técnicas tradicionais, como a análise de componentes principais (PCA), pode usar transformações não lineares para projetar dados em um espaço de menor dimensão. Se você estiver interessado em saber mais sobre outras técnicas de extração de recursos, há informações adicionais disponíveis neste tutorial de extração de recursos.
Além disso, em comparação com os algoritmos de compactação de dados padrão, como o gzpi, os Autoencoders não podem ser usados como algoritmos de compactação de uso geral, mas são feitos à mão para funcionar melhor apenas em dados semelhantes nos quais foram treinados.
Alguns dos hiperparâmetros mais comuns que podem ser ajustados ao otimizar o Autoencoder são:
Por fim, os Autoencoders podem ser projetados para trabalhar com diferentes tipos de dados, como tabulares, séries temporais ou dados de imagem, e podem, portanto, ser projetados para usar uma variedade de camadas, como camadas convolucionais, para análise de imagens.
Idealmente, um autocodificador bem treinado deve ser responsivo o suficiente para se adaptar aos dados de entrada a fim de fornecer uma resposta personalizada, mas não tanto a ponto de apenas imitar os dados de entrada e não conseguir generalizar com dados não vistos (portanto, superajuste).
Ao longo dos anos, foram desenvolvidos diferentes tipos de Autoencoders:
Vamos explorar cada um deles com mais detalhes.
Essa é a versão mais simples de um codificador automático. Nesse caso, não temos um mecanismo de regularização explícito, mas garantimos que o tamanho do gargalo seja sempre menor do que o tamanho da entrada original para evitar o ajuste excessivo. Esse tipo de configuração é normalmente usado como uma técnica de redução de dimensionalidade (mais poderosa do que a PCA, pois também é capaz de capturar não linearidades nos dados).
Um autocodificador esparso é bastante semelhante a um autocodificador subcompleto, mas sua principal diferença está na forma como a regularização é aplicada. Na verdade, com os Autoencoders esparsos, não precisamos necessariamente reduzir as dimensões do gargalo, mas usamos uma função de perda que tenta penalizar o modelo por usar todos os seus neurônios nas diferentes camadas ocultas (Figura 2).
Essa penalidade é comumente chamada de função de esparsidade e é bem diferente das técnicas de regularização tradicionais, pois não se concentra em penalizar o tamanho dos pesos, mas o número de nós ativados.
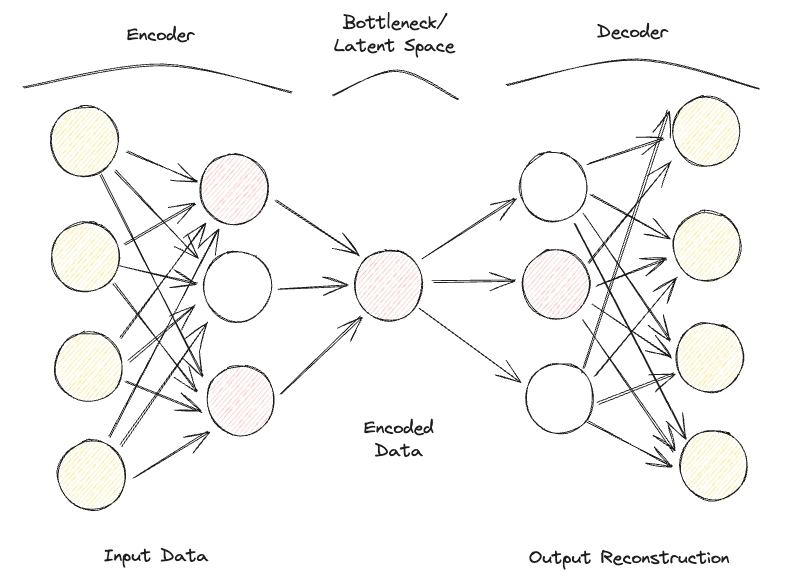
Dessa forma, diferentes nós poderiam se especializar em diferentes tipos de entrada e ser ativados/desativados dependendo das especificidades dos dados de entrada. Essa restrição de esparsidade pode ser induzida pelo uso da regularização L1 e da divergência KL, impedindo efetivamente que o modelo se ajuste demais.
A principal ideia por trás dos Autoencodificadores Contractivos é que, dadas algumas entradas semelhantes, sua representação comprimida deve ser bastante semelhante (as vizinhanças das entradas devem ser contraídas em pequenas vizinhanças das saídas). Em termos matemáticos, isso pode ser reforçado mantendo as ativações da camada oculta de entrada derivadas pequenas quando alimentadas com entradas semelhantes.
Com os Autoencoders de Denoising, a entrada e a saída do modelo não são mais as mesmas. Por exemplo, o modelo pode ser alimentado com algumas imagens corrompidas de baixa resolução e trabalhar para que a saída melhore a qualidade das imagens. Para avaliar o desempenho do modelo e melhorá-lo ao longo do tempo, precisaríamos ter alguma forma de imagem limpa rotulada para comparar com a previsão do modelo.
Para trabalhar com dados de imagem, os Autoencodificadores Convolucionais substituem as redes neurais feedforward tradicionais por Redes Neurais Convolucionais para as etapas de codificador e decodificador. Atualizando o tipo de função de perda, etc., esse tipo de Autoencoder também pode ser feito, por exemplo, Sparse ou Denoising, dependendo dos requisitos do seu caso de uso.
Em cada tipo de codificador automático considerado até agora, o codificador gera um único valor para cada dimensão envolvida. Com os Autoencodificadores Variacionais (VAE), tornamos esse processo mais probabilístico, criando uma distribuição de probabilidade para cada dimensão. O decodificador pode, então, amostrar um valor de cada distribuição que descreve as diferentes dimensões e construir o vetor de entrada, que pode ser usado para reconstruir os dados de entrada originais.
Uma das principais aplicações dos Autoencodificadores Variacionais é para tarefas generativas. De fato, a amostragem do modelo latente a partir de distribuições pode permitir que o decodificador crie novas formas de saídas que antes não eram possíveis usando uma abordagem determinística.
Se estiver interessado em testar um Autoencoder Variacional on-line treinado no conjunto de dados MNIST, você poderá encontrar um exemplo ao vivo.
Agora estamos prontos para fazer uma demonstração prática de como os Autoencoders podem ser usados para redução de dimensionalidade. Nossa estrutura de aprendizagem profunda escolhida para este exercício será o PyTorch.
O conjunto de dados do Kaggle Rain in Australia será usado para essa demonstração. Todo o código deste artigo está disponível nesta pasta de trabalho do DataLab.
Em primeiro lugar, importamos todas as bibliotecas necessárias e removemos todos os valores ausentes e colunas não numéricas (Figura 3).
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler, LabelEncoder
from mpl_toolkits.mplot3d import Axes3D
df = pd.read_csv("../input/weather-dataset-rattle-package/weatherAUS.csv")
df = df.drop(['Date', 'Location', 'WindDir9am',
'WindGustDir', 'WindDir3pm'], axis=1)
df = df.dropna(how = 'any')
df.loc[df['RainToday'] == 'No', 'RainToday'] = 0
df.loc[df['RainToday'] == 'Yes', 'RainToday'] = 1
df.head()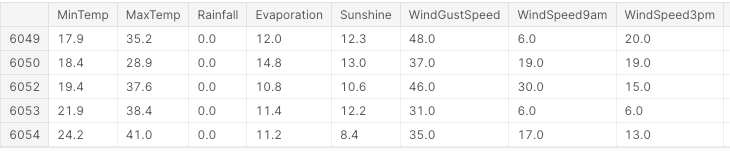
Figura 3: Amostra de colunas do conjunto de dados (imagem do autor).
Neste ponto, estamos prontos para dividir os dados em recursos e rótulos, normalizar os recursos e converter os rótulos em um formato numérico.
Nesse caso, temos um conjunto de recursos inicial composto de 17 colunas. O objetivo geral da análise seria então prever corretamente se vai chover no dia seguinte ou não.
X, Y = df.drop('RainTomorrow', axis=1, inplace=False), df[['RainTomorrow']]
# Normalizing Data
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Converting to PyTorch tensor
X_tensor = torch.FloatTensor(X_scaled)
# Converting string labels to numerical labels
label_encoder = LabelEncoder()
Y_numerical = label_encoder.fit_transform(Y.values.ravel())No PyTorch, agora podemos definir o modelo Autoencoder como uma classe e especificar os modelos de codificador e decodificador com duas camadas lineares.
# Defining Autoencoder model
class Autoencoder(nn.Module):
def __init__(self, input_size, encoding_dim):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(input_size, 16),
nn.ReLU(),
nn.Linear(16, encoding_dim),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.Linear(encoding_dim, 16),
nn.ReLU(),
nn.Linear(16, input_size),
nn.Sigmoid()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return xAgora que o modelo está configurado, podemos especificar nossas dimensões de codificação como sendo iguais a 3 (para facilitar a plotagem posterior) e executar o processo de treinamento.
# Setting random seed for reproducibility
torch.manual_seed(42)
input_size = X.shape[1] # Number of input features
encoding_dim = 3 # Desired number of output dimensions
model = Autoencoder(input_size, encoding_dim)
# Loss function and optimizer
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.003)
# Training the autoencoder
num_epochs = 20
for epoch in range(num_epochs):
# Forward pass
outputs = model(X_tensor)
loss = criterion(outputs, X_tensor)
# Backward pass and optimization
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Loss for each epoch
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
# Encoding the data using the trained autoencoder
encoded_data = model.encoder(X_tensor).detach().numpy()Epoch [1/20], Loss: 1.2443
Epoch [2/20], Loss: 1.2410
Epoch [3/20], Loss: 1.2376
Epoch [4/20], Loss: 1.2342
Epoch [5/20], Loss: 1.2307
Epoch [6/20], Loss: 1.2271
Epoch [7/20], Loss: 1.2234
Epoch [8/20], Loss: 1.2196
Epoch [9/20], Loss: 1.2156
Epoch [10/20], Loss: 1.2114
Epoch [11/20], Loss: 1.2070
Epoch [12/20], Loss: 1.2023
Epoch [13/20], Loss: 1.1974
Epoch [14/20], Loss: 1.1923
Epoch [15/20], Loss: 1.1868
Epoch [16/20], Loss: 1.1811
Epoch [17/20], Loss: 1.1751
Epoch [18/20], Loss: 1.1688
Epoch [19/20], Loss: 1.1622
Epoch [20/20], Loss: 1.1554Por fim, agora podemos plotar as dimensões de incorporação resultantes (Figura 4). Como pode ser visto na imagem abaixo, conseguimos reduzir a dimensionalidade do nosso conjunto de recursos de 17 dimensões para apenas 3, e ainda conseguimos, em boa medida, separar corretamente as amostras do nosso espaço tridimensional entre as diferentes classes.
# Plotting the encoded data in 3D space
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, projection='3d')
scatter = ax.scatter(encoded_data[:, 0], encoded_data[:, 1],
encoded_data[:, 2], c=Y_numerical, cmap='viridis')
# Mapping numerical labels back to original string labels for the legend
labels = label_encoder.inverse_transform(np.unique(Y_numerical))
legend_labels = {num: label for num, label in zip(np.unique(Y_numerical),
labels)}
# Creating a custom legend with original string labels
handles = [plt.Line2D([0], [0], marker='o', color='w',
markerfacecolor=scatter.to_rgba(num),
markersize=10,
label=legend_labels[num]) for num in np.unique(Y_numerical)]
ax.legend(handles=handles, title="Raining Tomorrow?")
# Adjusting the layout to provide more space for labels
ax.xaxis.labelpad = 20
ax.yaxis.labelpad = 20
ax.set_xticks([])
ax.set_yticks([])
ax.set_zticks([])
# Manually adding z-axis label for better visibility
ax.text2D(0.05, 0.95, 'Encoded Dimension 3', transform=ax.transAxes,
fontsize=12, color='black')
ax.set_xlabel('Encoded Dimension 1')
ax.set_ylabel('Encoded Dimension 2')
ax.set_title('Autoencoder Dimensionality Reduction')
plt.tight_layout()
plt.savefig('Rain_Prediction_Autoencoder.png')
plt.show()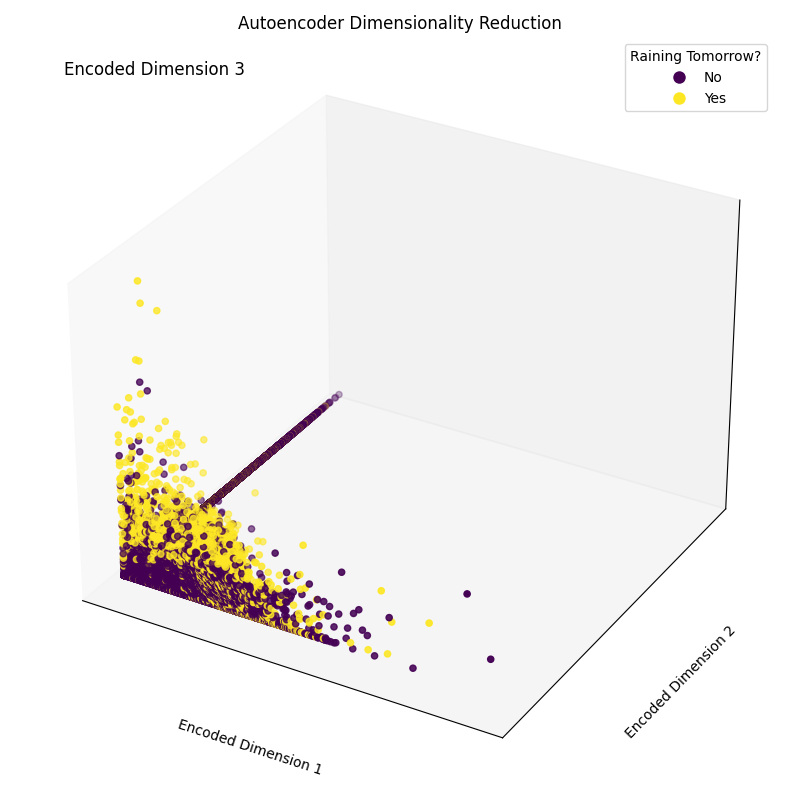
Figura 4: Dimensões codificadas resultantes (imagem do autor).
Uma das principais aplicações dos codificadores automáticos é compactar imagens para reduzir o tamanho geral do arquivo e, ao mesmo tempo, tentar manter o máximo possível de informações valiosas ou restaurar imagens que foram degradadas com o tempo.
Como os Autoencoders são bons em distinguir as características essenciais dos dados dos ruídos, eles podem ser usados para detectar anomalias (por exemplo, se uma imagem foi photoshopada, se há atividades incomuns em uma rede etc.).
Os Autoencoders Variacionais e as Redes Adversárias Generativas (GAN) são usados com frequência para gerar dados sintéticos (por exemplo, imagens realistas de pessoas).
Concluindo, os codificadores automáticos podem ser uma ferramenta realmente flexível para alimentar diferentes formas de casos de uso. Em especial, os Autoencodificadores Variacionais e a criação de GANs abriram as portas para o desenvolvimento da IA Generativa, oferecendo-nos os primeiros vislumbres de como a IA pode ser usada para gerar novas formas de conteúdo nunca antes vistas.
Este tutorial foi uma introdução ao campo dos Autoencoders, embora você ainda tenha muito a aprender! O DataCamp tem uma grande variedade de recursos sobre esse tópico, por exemplo, como implementar Autoencoders no Keras ou usá-los como um classificador!
Comece sua jornada de aprendizagem profunda hoje mesmo!
Curso
Curso
Curso
Tutorial
Kurtis Pykes
Tutorial
Arjun Sarkar
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
Tutorial
Bex Tuychiev
Tutorial
Bharath K



