
Kurs
Python ile Deep Learning'e Giriş
4 sa
263.6K
Geleneksel ileri beslemeli yapay sinir ağları sınıflandırma ve regresyon gibi görevlerde oldukça başarılı olabilir, peki ya sinyal gürültü giderme veya anomali tespiti gibi çözümler uygulamak istersek? Bunu yapmanın bir yolu Otokodlayıcılar kullanmaktır.
Bu eğitim, PyTorch ile uygulamalı bir örnek ve bazı olası kullanım senaryoları dahil olmak üzere Otokodlayıcılara pratik bir giriş sunar.
Eğitimdeki tüm kodların yer aldığı bu DataLab çalışma kitabını takip edebilirsiniz.
Otokodlayıcılar, özel bir tür gözetimsiz ileri beslemeli sinir ağıdır (etiket gerekmez!). Otokodlayıcıların başlıca uygulaması, sağlanan verilerin temel özelliklerini doğru bir şekilde yakalayarak girdinin sıkıştırılmış bir sürümünü elde etmek, gerçekçi sentetik veriler üretmek veya anomalileri işaretlemektir.
Otokodlayıcılar, 2 temel tam bağlantılı ileri beslemeli sinir ağından oluşur (Şekil 1):
Veriyi kodlayıcı ve kod çözücüden geçirip hatayı ölçerek geri yayılım yoluyla parametreleri ayarlama sürecini yinelemeli olarak tekrarlayarak, Otokodlayıcı zamanla son derece zor veri biçimleriyle doğru şekilde çalışabilir.
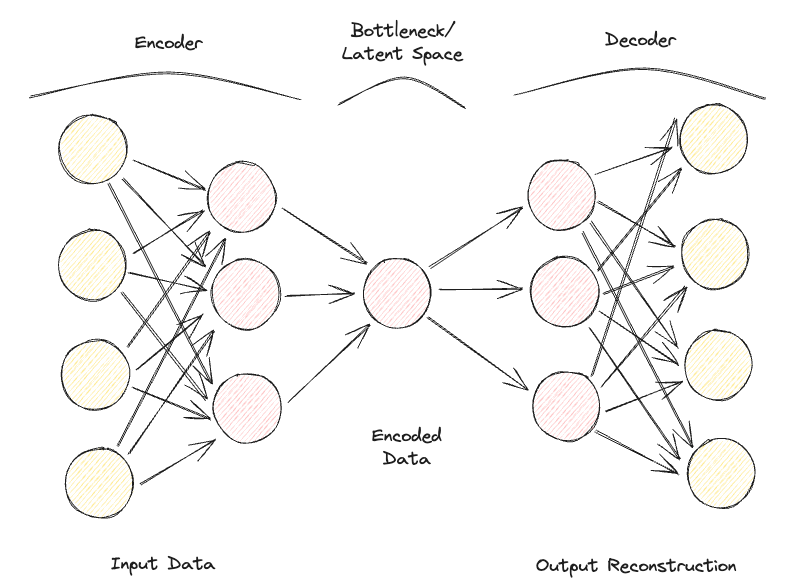
Şekil 1: Otokodlayıcı Mimarisi (Görsel: Yazar).
Bir Otokodlayıcıya tamamen birbirinden bağımsız bir dizi girdi özelliği verilirse, modelin çok fazla bilgi kaybetmeden iyi bir düşük boyutlu temsil bulması gerçekten zor olur (kayıplı sıkıştırma).
Bu nedenle Otokodlayıcılar, geleneksel tekniklere kıyasla, örneğin Temel Bileşen Analizine (PCA) göre veriyi daha düşük boyutlu bir uzaya yansıtmak için doğrusal olmayan dönüşümlerden yararlanabilen bir boyut indirgeme tekniği olarak da değerlendirilebilir. Diğer Özellik Çıkarımı teknikleri hakkında daha fazla bilgi edinmek isterseniz, bu özellik çıkarımı eğitiminde ek bilgiler mevcuttur.
Ayrıca, gzpi gibi standart veri sıkıştırma algoritmalarıyla karşılaştırıldığında, Otokodlayıcılar genel amaçlı sıkıştırma algoritmaları olarak kullanılamaz; yalnızca eğitildikleri benzer veriler üzerinde en iyi çalışacak şekilde elde hazırlanırlar.
Otokodlayıcınızı optimize ederken ayarlanabilecek en yaygın hiperparametrelerden bazıları şunlardır:
Son olarak, Otokodlayıcılar, tablo, zaman serisi veya görüntü verileri gibi farklı veri türleriyle çalışacak şekilde tasarlanabilir ve bu nedenle, görüntü analizi için evrişimli katmanlar gibi çeşitli katmanları kullanacak şekilde kurgulanabilir.
İdeal olarak, iyi eğitilmiş bir Otokodlayıcı, girdiye uyum sağlayacak kadar duyarlı olmalı ve kişiye özel bir çıktı sunmalı; ancak sadece girdiyi birebir taklit edecek kadar da uyum sağlamamalı ve görülmemiş verilerde genelleme yapamayacak düzeye gelmemelidir (aşırı uyum).
Yıllar içinde farklı Otokodlayıcı türleri geliştirilmiştir:
Her birini biraz daha yakından inceleyelim.
Bu, bir otokodlayıcının en basit sürümüdür. Bu durumda açık bir düzenlileştirme mekanizmamız yoktur; ancak aşırı uyumu önlemek için dar boğazın boyutunun her zaman orijinal girdi boyutundan küçük olmasını sağlarız. Bu yapılandırma türü genellikle bir boyut indirgeme tekniği olarak kullanılır (verideki doğrusal olmayanlıkları da yakalayabildiği için PCA’dan daha güçlüdür).
Bir Seyrek Otokodlayıcı, Eksik Otokodlayıcıya oldukça benzer; ancak temel farkları düzenlileştirmenin uygulanma şeklindedir. Nitekim, Seyrek Otokodlayıcılarda dar boğazın boyutunu mutlaka azaltmamız gerekmez; bunun yerine, modelin farklı gizli katmanlardaki tüm nöronlarını kullanmasını cezalandırmaya çalışan bir kayıp fonksiyonu kullanırız (Şekil 2).
Bu ceza genellikle bir seyreklik fonksiyonu olarak adlandırılır ve geleneksel düzenlileştirme tekniklerinden oldukça farklıdır; zira ağırlıkların büyüklüğünü değil, etkinleşen düğüm sayısını cezalandırmaya odaklanır.
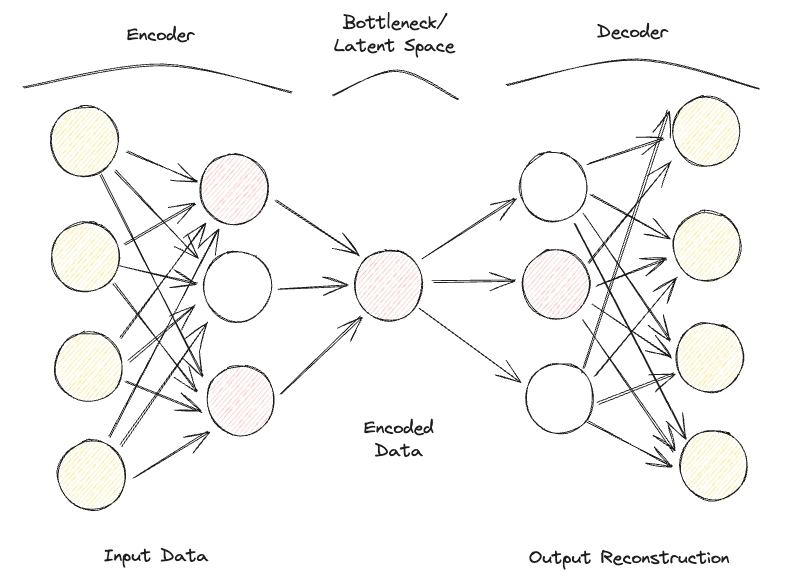
Bu şekilde, farklı düğümler farklı girdi türlerinde uzmanlaşabilir ve girdi verisinin özelliklerine bağlı olarak etkinleşebilir/devre dışı kalabilir. Bu seyreklik kısıtı, L1 Düzenlileştirme ve KL ayrışımı kullanılarak sağlanabilir ve modelin aşırı uyum yapmasını etkin biçimde engeller.
Büzücü Otokodlayıcıların arkasındaki temel fikir şudur: Benzer girdiler verildiğinde, bunların sıkıştırılmış temsilleri de oldukça benzer olmalıdır (girdi mahalleleri, çıktıların küçük mahallelerine büzülmelidir). Matematiksel olarak bu, benzer girdiler verildiğinde, girdi gizli katman aktivasyonlarının türevlerini küçük tutarak zorlanabilir.
Gürültü Giderici Otokodlayıcılarda, modelin girdisi ve çıktısı artık aynı değildir. Örneğin, modele düşük çözünürlüklü, bozulmuş görüntüler verilebilir ve çıktı olarak görüntü kalitesini iyileştirmesi beklenir. Modelin performansını değerlendirmek ve zamanla iyileştirmek için, model tahminiyle karşılaştırılacak etiketli temiz görüntülere ihtiyaç duyarız.
Görüntü verileriyle çalışmak için Evrişimli Otokodlayıcılar, hem kodlayıcı hem de kod çözücü adımlarında geleneksel ileri beslemeli sinir ağları yerine Evrişimli Sinir Ağları kullanır. Kayıp fonksiyonunu vb. güncelleyerek, bu tür bir Otokodlayıcı kullanım senaryosu gereksinimlerinize bağlı olarak örneğin Seyrek veya Gürültü Giderici hale de getirilebilir.
Şimdiye kadar ele alınan her Otokodlayıcı türünde, kodlayıcı ilgili her boyut için tek bir değer üretir. Varyasyonel Otokodlayıcılarda (VAE) ise bu süreç olasılıksal hale getirilir ve her boyut için bir olasılık dağılımı oluşturulur. Kod çözücü daha sonra farklı boyutları tanımlayan her dağılımdan bir değer örnekleyebilir ve girdi vektörünü oluşturabilir; bu da orijinal girdi verisini yeniden kurmak için kullanılabilir.
Varyasyonel Otokodlayıcıların başlıca uygulamalarından biri üretimsel (generative) görevlerdir. Nitekim, gizil modeli dağılımlardan örneklemek, kod çözücünün, deterministik bir yaklaşımla mümkün olmayan yeni çıktı biçimleri oluşturmasını sağlayabilir.
MNIST veri kümesi üzerinde eğitilmiş çevrimiçi bir Varyasyonel Otokodlayıcıyı denemekle ilgileniyorsanız, canlı bir örnek bulabilirsiniz.
Şimdi, Otokodlayıcıların boyut indirgeme için nasıl kullanılabileceğine dair pratik bir gösterime hazırız. Bu alıştırmada tercih edeceğimiz Derin Öğrenme çerçevesi PyTorch olacaktır.
Kaggle Rain in Australia veri kümesi bu gösterimde kullanılacaktır. Bu makaledeki tüm kodlar bu DataLab çalışma kitabında mevcuttur.
Öncelikle gerekli tüm kütüphaneleri içe aktarıyor, eksik değerleri ve sayısal olmayan sütunları kaldırıyoruz (Şekil 3).
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler, LabelEncoder
from mpl_toolkits.mplot3d import Axes3D
df = pd.read_csv("../input/weather-dataset-rattle-package/weatherAUS.csv")
df = df.drop(['Date', 'Location', 'WindDir9am',
'WindGustDir', 'WindDir3pm'], axis=1)
df = df.dropna(how = 'any')
df.loc[df['RainToday'] == 'No', 'RainToday'] = 0
df.loc[df['RainToday'] == 'Yes', 'RainToday'] = 1
df.head()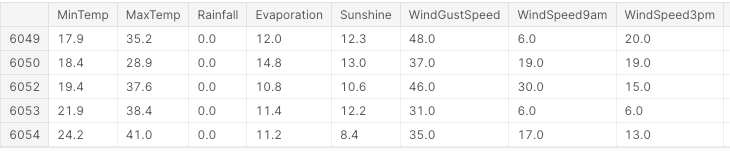
Şekil 3: Veri Kümesi Sütunlarından Örnek (Görsel: Yazar).
Bu noktada veriyi özellikler ve etiketler olarak ayırmaya, özellikleri normalize etmeye ve etiketleri sayısal biçime dönüştürmeye hazırız.
Bu örnekte, 17 sütundan oluşan bir başlangıç özellik kümesine sahibiz. Analizin genel hedefi ise ertesi gün yağmur yağıp yağmayacağını doğru şekilde tahmin etmektir.
X, Y = df.drop('RainTomorrow', axis=1, inplace=False), df[['RainTomorrow']]
# Normalizing Data
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Converting to PyTorch tensor
X_tensor = torch.FloatTensor(X_scaled)
# Converting string labels to numerical labels
label_encoder = LabelEncoder()
Y_numerical = label_encoder.fit_transform(Y.values.ravel())PyTorch’ta artık Otokodlayıcı modelini bir sınıf olarak tanımlayabilir ve kodlayıcı ile kod çözücü modellerini iki doğrusal katmanla belirtebiliriz.
# Defining Autoencoder model
class Autoencoder(nn.Module):
def __init__(self, input_size, encoding_dim):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(input_size, 16),
nn.ReLU(),
nn.Linear(16, encoding_dim),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.Linear(encoding_dim, 16),
nn.ReLU(),
nn.Linear(16, input_size),
nn.Sigmoid()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return xModeli kurduğumuza göre, kodlama boyutlarımızı 3 olarak belirleyebilir (ileride kolayca görselleştirebilmek için) ve eğitim sürecini çalıştırabiliriz.
# Setting random seed for reproducibility
torch.manual_seed(42)
input_size = X.shape[1] # Number of input features
encoding_dim = 3 # Desired number of output dimensions
model = Autoencoder(input_size, encoding_dim)
# Loss function and optimizer
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.003)
# Training the autoencoder
num_epochs = 20
for epoch in range(num_epochs):
# Forward pass
outputs = model(X_tensor)
loss = criterion(outputs, X_tensor)
# Backward pass and optimization
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Loss for each epoch
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
# Encoding the data using the trained autoencoder
encoded_data = model.encoder(X_tensor).detach().numpy()Epoch [1/20], Loss: 1.2443
Epoch [2/20], Loss: 1.2410
Epoch [3/20], Loss: 1.2376
Epoch [4/20], Loss: 1.2342
Epoch [5/20], Loss: 1.2307
Epoch [6/20], Loss: 1.2271
Epoch [7/20], Loss: 1.2234
Epoch [8/20], Loss: 1.2196
Epoch [9/20], Loss: 1.2156
Epoch [10/20], Loss: 1.2114
Epoch [11/20], Loss: 1.2070
Epoch [12/20], Loss: 1.2023
Epoch [13/20], Loss: 1.1974
Epoch [14/20], Loss: 1.1923
Epoch [15/20], Loss: 1.1868
Epoch [16/20], Loss: 1.1811
Epoch [17/20], Loss: 1.1751
Epoch [18/20], Loss: 1.1688
Epoch [19/20], Loss: 1.1622
Epoch [20/20], Loss: 1.1554Son olarak, ortaya çıkan gömme (embedding) boyutlarını görselleştirebiliriz (Şekil 4). Aşağıdaki görselde görülebileceği gibi, özellik kümemizin boyutunu 17’den sadece 3’e düşürmeyi başardık ve 3 boyutlu uzayımızda örnekleri farklı sınıflar arasında büyük ölçüde doğru biçimde ayırabildik.
# Plotting the encoded data in 3D space
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, projection='3d')
scatter = ax.scatter(encoded_data[:, 0], encoded_data[:, 1],
encoded_data[:, 2], c=Y_numerical, cmap='viridis')
# Mapping numerical labels back to original string labels for the legend
labels = label_encoder.inverse_transform(np.unique(Y_numerical))
legend_labels = {num: label for num, label in zip(np.unique(Y_numerical),
labels)}
# Creating a custom legend with original string labels
handles = [plt.Line2D([0], [0], marker='o', color='w',
markerfacecolor=scatter.to_rgba(num),
markersize=10,
label=legend_labels[num]) for num in np.unique(Y_numerical)]
ax.legend(handles=handles, title="Raining Tomorrow?")
# Adjusting the layout to provide more space for labels
ax.xaxis.labelpad = 20
ax.yaxis.labelpad = 20
ax.set_xticks([])
ax.set_yticks([])
ax.set_zticks([])
# Manually adding z-axis label for better visibility
ax.text2D(0.05, 0.95, 'Encoded Dimension 3', transform=ax.transAxes,
fontsize=12, color='black')
ax.set_xlabel('Encoded Dimension 1')
ax.set_ylabel('Encoded Dimension 2')
ax.set_title('Autoencoder Dimensionality Reduction')
plt.tight_layout()
plt.savefig('Rain_Prediction_Autoencoder.png')
plt.show()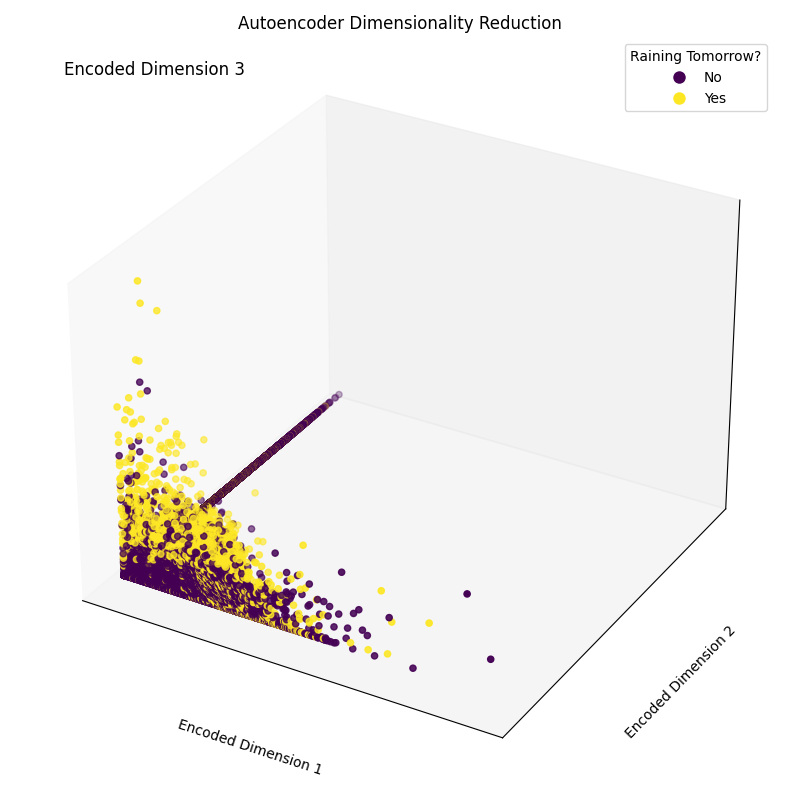
Şekil 4: Ortaya Çıkan Kodlanmış Boyutlar (Görsel: Yazar).
Otokodlayıcıların başlıca uygulamalarından biri, mümkün olduğunca fazla değerli bilgiyi koruyarak görüntüleri sıkıştırıp toplam dosya boyutlarını azaltmak veya zamanla bozulmuş görüntüleri onarmaktır.
Otokodlayıcılar verilerin temel özelliklerini gürültüden ayırmada başarılı oldukları için, anomalileri tespit etmek amacıyla kullanılabilirler (örneğin bir görüntünün photoshoplanıp photoshoplanmadığı, bir ağda olağandışı etkinlikler olup olmadığı vb.).
Varyasyonel Otokodlayıcılar ve Generative Adversarial Networks (GAN) sıkça sentetik veri üretmek için kullanılır (örneğin gerçekçi insan görüntüleri).
Sonuç olarak, Otokodlayıcılar farklı kullanım senaryolarını desteklemek için oldukça esnek bir araç olabilir. Özellikle Varyasyonel Otokodlayıcılar ve GAN’lerin ortaya çıkışı, Generative AI’ın gelişiminin önünü açarak, yapay zekânın daha önce hiç görülmemiş yeni içerik türleri üretmek için nasıl kullanılabileceğine dair ilk örnekleri sundu.
Bu eğitim, Otokodlayıcılar alanına bir giriş niteliğindeydi; öğrenilecek daha çok şey var! DataCamp, bu konuyla ilgili Keras ile Otokodlayıcı nasıl uygulanır ya da onları bir sınıflandırıcı olarak nasıl kullanırsınız gibi pek çok kaynak sunar!
Derin Öğrenme Yolculuğunuza Bugün Başlayın!
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
