
Corso
Introduzione al Deep Learning in Python
4 h
264K
Le tradizionali reti neurali feedforward sono ottime per compiti come classificazione e regressione, ma cosa succede se vuoi implementare soluzioni come la rimozione del rumore da un segnale o il rilevamento di anomalie? Un modo per farlo è usare gli Autoencoder.
Questo tutorial offre un'introduzione pratica agli Autoencoder, con un esempio hands-on in PyTorch e alcuni possibili casi d'uso.
Puoi seguire il tutorial in questo workbook DataLab con tutto il codice del tutorial.
Gli Autoencoder sono un tipo speciale di rete neurale feedforward non supervisionata (non servono etichette!). La loro applicazione principale è catturare con precisione gli aspetti chiave dei dati forniti per offrire una versione compressa dei dati di input, generare dati sintetici realistici o segnalare anomalie.
Gli Autoencoder sono composti da 2 reti neurali feedforward completamente connesse (Figura 1):
Ripetendo iterativamente questo processo di passaggio dei dati attraverso encoder e decoder e misurando l'errore per tarare i parametri tramite backpropagation, con il tempo l'Autoencoder può arrivare a gestire correttamente forme di dati estremamente difficili.
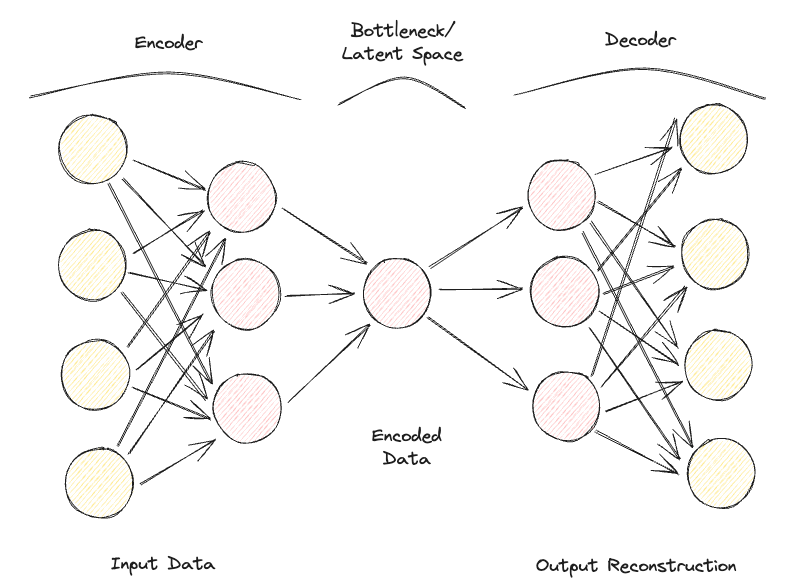
Figura 1: Architettura di un Autoencoder (immagine dell'autore).
Se a un Autoencoder viene fornito un set di feature di input completamente indipendenti tra loro, sarà molto difficile per il modello trovare una buona rappresentazione a bassa dimensionalità senza perdere una grande quantità di informazioni (compressione con perdita).
Gli Autoencoder possono quindi essere considerati anche una tecnica di riduzione della dimensionalità che, rispetto a tecniche tradizionali come l'Analisi delle Componenti Principali (PCA), può sfruttare trasformazioni non lineari per proiettare i dati in uno spazio a dimensionalità inferiore. Se vuoi saperne di più su altre tecniche di estrazione delle feature, trovi informazioni aggiuntive in questo tutorial sull'estrazione delle feature.
Inoltre, rispetto ad algoritmi standard di compressione dei dati come gzpi, gli Autoencoder non possono essere usati come algoritmi di compressione generici, ma sono realizzati ad hoc per funzionare al meglio su dati simili a quelli su cui sono stati addestrati.
Alcuni tra gli iperparametri più comuni che puoi ottimizzare nel tuo Autoencoder sono:
Infine, gli Autoencoder possono essere progettati per lavorare con diversi tipi di dati, come dati tabellari, serie temporali o immagini, e possono quindi essere progettati per usare una varietà di layer, come i layer convoluzionali, per l'analisi di immagini.
Idealmente, un Autoencoder ben addestrato dovrebbe essere abbastanza reattivo da adattarsi ai dati di input per fornire una risposta su misura, ma non al punto da limitarsi a imitare i dati di input e non riuscire a generalizzare su dati mai visti (overfitting).
Nel corso degli anni sono stati sviluppati diversi tipi di Autoencoder:
Esploriamoli più nel dettaglio.
Questa è la versione più semplice di un autoencoder. In questo caso non abbiamo un meccanismo esplicito di regolarizzazione, ma ci assicuriamo che la dimensione del collo di bottiglia sia sempre inferiore alla dimensione dell'input originale per evitare l'overfitting. Questo tipo di configurazione è tipicamente usato come tecnica di riduzione della dimensionalità (più potente della PCA perché è in grado di catturare anche le non linearità nei dati).
Uno Sparse Autoencoder è piuttosto simile a un Undercomplete Autoencoder, ma la principale differenza sta nel modo in cui viene applicata la regolarizzazione. Infatti, con gli Sparse Autoencoder non è necessariamente necessario ridurre le dimensioni del collo di bottiglia, ma si usa una funzione di perdita che cerca di penalizzare il modello quando usa tutti i suoi neuroni nei diversi layer nascosti (Figura 2).
Questa penalizzazione è comunemente chiamata funzione di sparsità ed è piuttosto diversa dalle tecniche di regolarizzazione tradizionali, poiché non si concentra nel penalizzare la dimensione dei pesi, ma il numero di nodi attivati.
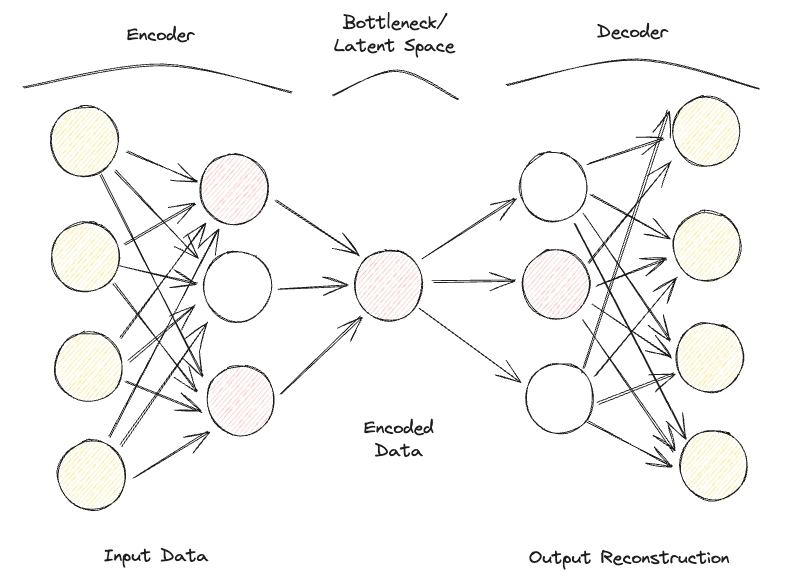
In questo modo, nodi diversi possono specializzarsi per differenti tipi di input ed essere attivati/disattivati a seconda delle caratteristiche specifiche dei dati di input. Questo vincolo di sparsità può essere indotto usando la regolarizzazione L1 e la divergenza di KL, prevenendo di fatto l'overfitting del modello.
L'idea principale alla base dei Contractive Autoencoder è che, dati alcuni input simili, la loro rappresentazione compressa dovrebbe essere piuttosto simile (i dintorni degli input dovrebbero contrarsi in piccoli dintorni degli output). In termini matematici, questo può essere imposto mantenendo piccole le derivate delle attivazioni del layer nascosto rispetto all'input quando si forniscono input simili.
Con i Denoising Autoencoder, l'input e l'output del modello non sono più gli stessi. Per esempio, il modello potrebbe ricevere immagini corrotte a bassa risoluzione e lavorare per migliorare la qualità delle immagini in output. Per valutare le prestazioni del modello e migliorarlo nel tempo, avremmo quindi bisogno di qualche forma di immagine pulita etichettata con cui confrontare la previsione del modello.
Per lavorare con dati di immagini, i Convolutional Autoencoder sostituiscono le tradizionali reti neurali feedforward con Reti Neurali Convoluzionali sia per la fase di encoder che per quella di decoder. Aggiornando tipo di funzione di perdita, ecc., questo tipo di Autoencoder può anche essere reso, ad esempio, Sparse o Denoising, a seconda dei requisiti del tuo caso d'uso.
In ogni tipo di Autoencoder considerato finora, l'encoder restituisce un singolo valore per ciascuna dimensione coinvolta. Con i Variational Autoencoder (VAE), rendiamo invece questo processo probabilistico, creando una distribuzione di probabilità per ogni dimensione. Il decoder può quindi campionare un valore da ciascuna distribuzione che descrive le diverse dimensioni e costruire il vettore di input, che può poi essere usato per ricostruire i dati di input originali.
Una delle principali applicazioni dei Variational Autoencoder è nei compiti generativi. Infatti, campionare il modello latente da distribuzioni può consentire al decoder di creare nuove forme di output che non erano possibili in precedenza con un approccio deterministico.
Se vuoi provare online un Variational Autoencoder addestrato sul dataset MNIST, puoi trovare un esempio live.
Siamo ora pronti per una dimostrazione pratica di come gli Autoencoder possano essere usati per la riduzione della dimensionalità. Il nostro framework di Deep Learning per questo esercizio sarà PyTorch.
Per questa dimostrazione useremo il dataset Kaggle Rain in Australia. Tutto il codice di questo articolo è disponibile in questo workbook DataLab.
Per prima cosa importiamo tutte le librerie necessarie e rimuoviamo eventuali valori mancanti e colonne non numeriche (Figura 3).
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler, LabelEncoder
from mpl_toolkits.mplot3d import Axes3D
df = pd.read_csv("../input/weather-dataset-rattle-package/weatherAUS.csv")
df = df.drop(['Date', 'Location', 'WindDir9am',
'WindGustDir', 'WindDir3pm'], axis=1)
df = df.dropna(how = 'any')
df.loc[df['RainToday'] == 'No', 'RainToday'] = 0
df.loc[df['RainToday'] == 'Yes', 'RainToday'] = 1
df.head()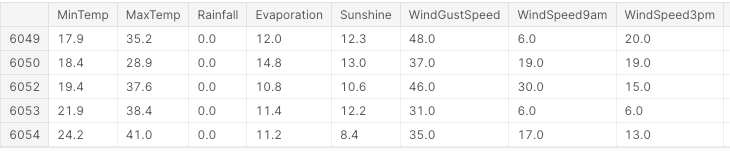
Figura 3: Esempio di colonne del dataset (immagine dell'autore).
A questo punto, siamo pronti per dividere i dati in feature ed etichette, normalizzare le feature e convertire le etichette in formato numerico.
In questo caso, partiamo da un set di feature composto da 17 colonne. L'obiettivo complessivo dell'analisi sarà quindi prevedere correttamente se pioverà il giorno successivo oppure no.
X, Y = df.drop('RainTomorrow', axis=1, inplace=False), df[['RainTomorrow']]
# Normalizing Data
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Converting to PyTorch tensor
X_tensor = torch.FloatTensor(X_scaled)
# Converting string labels to numerical labels
label_encoder = LabelEncoder()
Y_numerical = label_encoder.fit_transform(Y.values.ravel())In PyTorch, ora possiamo definire il modello di Autoencoder come una classe e specificare i modelli di encoder e decoder con due layer lineari.
# Defining Autoencoder model
class Autoencoder(nn.Module):
def __init__(self, input_size, encoding_dim):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(input_size, 16),
nn.ReLU(),
nn.Linear(16, encoding_dim),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.Linear(encoding_dim, 16),
nn.ReLU(),
nn.Linear(16, input_size),
nn.Sigmoid()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return xOra che il modello è impostato, possiamo specificare la dimensione dell'embedding pari a 3 (così sarà più semplice tracciarla in seguito) ed eseguire il processo di training.
# Setting random seed for reproducibility
torch.manual_seed(42)
input_size = X.shape[1] # Number of input features
encoding_dim = 3 # Desired number of output dimensions
model = Autoencoder(input_size, encoding_dim)
# Loss function and optimizer
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.003)
# Training the autoencoder
num_epochs = 20
for epoch in range(num_epochs):
# Forward pass
outputs = model(X_tensor)
loss = criterion(outputs, X_tensor)
# Backward pass and optimization
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Loss for each epoch
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
# Encoding the data using the trained autoencoder
encoded_data = model.encoder(X_tensor).detach().numpy()Epoch [1/20], Loss: 1.2443
Epoch [2/20], Loss: 1.2410
Epoch [3/20], Loss: 1.2376
Epoch [4/20], Loss: 1.2342
Epoch [5/20], Loss: 1.2307
Epoch [6/20], Loss: 1.2271
Epoch [7/20], Loss: 1.2234
Epoch [8/20], Loss: 1.2196
Epoch [9/20], Loss: 1.2156
Epoch [10/20], Loss: 1.2114
Epoch [11/20], Loss: 1.2070
Epoch [12/20], Loss: 1.2023
Epoch [13/20], Loss: 1.1974
Epoch [14/20], Loss: 1.1923
Epoch [15/20], Loss: 1.1868
Epoch [16/20], Loss: 1.1811
Epoch [17/20], Loss: 1.1751
Epoch [18/20], Loss: 1.1688
Epoch [19/20], Loss: 1.1622
Epoch [20/20], Loss: 1.1554Infine, possiamo tracciare le dimensioni dell'embedding risultanti (Figura 4). Come si vede nell'immagine qui sotto, siamo riusciti a ridurre la dimensionalità del nostro set di feature da 17 dimensioni a sole 3, riuscendo comunque, in buona misura, a separare correttamente nel nostro spazio tridimensionale i campioni tra le diverse classi.
# Plotting the encoded data in 3D space
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, projection='3d')
scatter = ax.scatter(encoded_data[:, 0], encoded_data[:, 1],
encoded_data[:, 2], c=Y_numerical, cmap='viridis')
# Mapping numerical labels back to original string labels for the legend
labels = label_encoder.inverse_transform(np.unique(Y_numerical))
legend_labels = {num: label for num, label in zip(np.unique(Y_numerical),
labels)}
# Creating a custom legend with original string labels
handles = [plt.Line2D([0], [0], marker='o', color='w',
markerfacecolor=scatter.to_rgba(num),
markersize=10,
label=legend_labels[num]) for num in np.unique(Y_numerical)]
ax.legend(handles=handles, title="Raining Tomorrow?")
# Adjusting the layout to provide more space for labels
ax.xaxis.labelpad = 20
ax.yaxis.labelpad = 20
ax.set_xticks([])
ax.set_yticks([])
ax.set_zticks([])
# Manually adding z-axis label for better visibility
ax.text2D(0.05, 0.95, 'Encoded Dimension 3', transform=ax.transAxes,
fontsize=12, color='black')
ax.set_xlabel('Encoded Dimension 1')
ax.set_ylabel('Encoded Dimension 2')
ax.set_title('Autoencoder Dimensionality Reduction')
plt.tight_layout()
plt.savefig('Rain_Prediction_Autoencoder.png')
plt.show()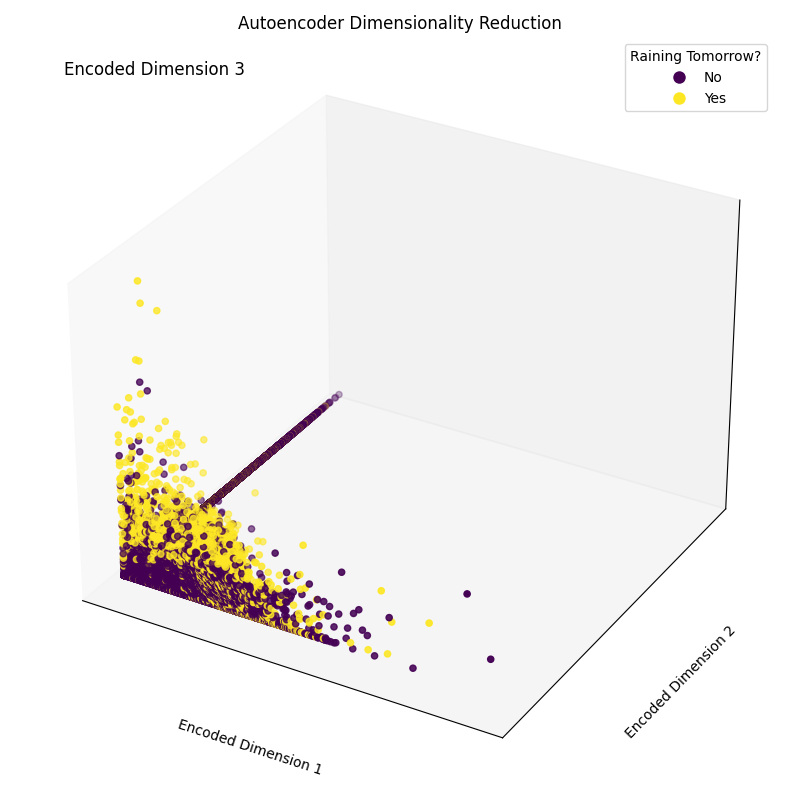
Figura 4: Dimensioni codificate risultanti (immagine dell'autore).
Una delle principali applicazioni degli Autoencoder è comprimere le immagini per ridurne la dimensione del file cercando di mantenere quante più informazioni preziose possibili, oppure ripristinare immagini degradate nel tempo.
Poiché gli Autoencoder sanno distinguere le caratteristiche essenziali dei dati dal rumore, possono essere usati per rilevare anomalie (ad es., se un'immagine è stata photoshoppata, se ci sono attività insolite in una rete, ecc.).
I Variational Autoencoder e le Generative Adversarial Network (GAN) sono spesso usati per generare dati sintetici (ad es., immagini realistiche di persone).
In conclusione, gli Autoencoder possono essere uno strumento davvero flessibile per supportare diverse tipologie di casi d'uso. In particolare, i Variational Autoencoder e la creazione delle GAN hanno aperto la strada allo sviluppo della Generative AI, offrendoci le prime avvisaglie di come l'IA possa essere usata per generare nuove forme di contenuto mai viste prima.
Questo tutorial è stato un'introduzione al campo degli Autoencoder, ma c'è ancora molto da imparare! DataCamp ha a disposizione tante risorse su questo argomento, come come implementare gli Autoencoder in Keras o usarli come classificatore!
Inizia oggi il tuo percorso nel Deep Learning!
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min

