
Kursus
Prapemrosesan untuk Machine Learning di Python
4 Hr
67.4K
Normalisasi dan standardisasi sama-sama termasuk dalam gagasan atau kategori penskalaan fitur. Penskalaan fitur adalah langkah penting dalam menyiapkan data untuk model machine learning. Ini melibatkan transformasi nilai fitur dalam suatu dataset ke skala yang serupa, memastikan semua fitur berkontribusi secara setara pada proses pembelajaran model.
Penskalaan fitur penting karena, ketika fitur berada pada skala yang sangat berbeda, seperti satu fitur berkisar 1 hingga 10 dan lainnya 1.000 hingga 10.000, model dapat memprioritaskan nilai yang lebih besar, sehingga menimbulkan bias dalam prediksi. Hal ini dapat menyebabkan kinerja model yang buruk dan konvergensi yang lebih lambat selama pelatihan.
Penskalaan fitur mengatasi masalah ini dengan menyesuaikan rentang data tanpa mendistorsi perbedaan nilainya. Ada beberapa teknik penskalaan, dengan normalisasi dan standardisasi sebagai yang paling umum digunakan. Kedua metode membantu model machine learning berkinerja optimal dengan menyeimbangkan dampak fitur, mengurangi pengaruh pencilan, dan, dalam beberapa kasus, meningkatkan laju konvergensi.
Normalisasi adalah gagasan yang luas, dan ada berbagai cara untuk menormalisasi data. Secara umum, normalisasi mengacu pada proses menyesuaikan nilai yang diukur pada skala berbeda ke skala yang sama. Kadang-kadang, paling baik dijelaskan dengan contoh. Untuk setiap jenis normalisasi di bawah ini, kita akan mempertimbangkan sebuah model untuk memahami hubungan antara harga rumah dan ukurannya.
Mari kita lihat beberapa jenis utama. Perlu diingat, ini bukan daftar yang lengkap:
Dengan normalisasi min-maks, kita dapat menskalakan ulang ukuran rumah agar berada dalam rentang 0 hingga 1. Ini berarti ukuran rumah terkecil akan direpresentasikan sebagai 0, dan ukuran rumah terbesar direpresentasikan sebagai 1.
Normalisasi log adalah teknik normalisasi lainnya. Dengan menggunakan normalisasi log, kita menerapkan transformasi logaritmik pada harga rumah. Teknik ini membantu mengurangi dampak harga yang lebih besar, terutama jika terdapat perbedaan yang signifikan di antaranya.
Skala desimal adalah teknik normalisasi lainnya. Untuk contoh ini, kita dapat menyesuaikan ukuran rumah dengan menggeser titik desimal untuk membuat nilainya lebih kecil. Ini berarti ukuran rumah diubah ke skala yang lebih mudah dikelola sambil menjaga perbedaan relatifnya tetap utuh.
Normalisasi mean, dalam konteks ini, melibatkan penyesuaian harga rumah dengan mengurangkan harga rata-rata dari harga setiap rumah. Proses ini memusatkan harga di nol, menunjukkan bagaimana ukuran setiap rumah dibandingkan dengan rata-rata. Dengan melakukan ini, kita dapat menganalisis ukuran rumah mana yang lebih besar atau lebih kecil dari rata-rata, sehingga memudahkan interpretasi harga relatifnya.
Seperti yang mungkin Anda simpulkan dari contoh di atas, normalisasi sangat berguna ketika distribusi data tidak diketahui atau tidak mengikuti distribusi Gaussian. Harga rumah adalah contoh yang baik karena beberapa rumah sangat, sangat mahal, dan model tidak selalu menangani pencilan dengan baik.
Jadi, tujuan normalisasi adalah untuk membuat model yang lebih baik. Kita mungkin menormalisasi variabel dependen agar galat lebih terdistribusi merata, atau kita menormalisasi variabel masukan untuk memastikan fitur dengan skala lebih besar tidak mendominasi yang berskala lebih kecil.
Normalisasi paling efektif dalam skenario berikut:
Sementara normalisasi menskalakan fitur ke rentang tertentu, standardisasi, yang juga disebut penskalaan z-score, mentransformasi data agar memiliki mean 0 dan standar deviasi 1. Proses ini menyesuaikan nilai fitur dengan mengurangkan mean dan membaginya dengan standar deviasi. Anda mungkin pernah mendengar tentang \"centering and scaling\" data. Nah, standardisasi merujuk pada hal yang sama: pertama memusatkan, lalu menskalakan.
Rumus standardisasi adalah:
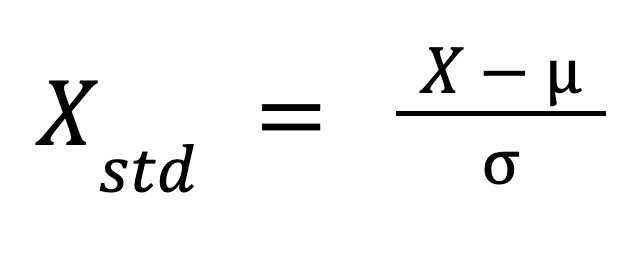
Di mana:
Rumus ini menskalakan ulang data sedemikian rupa sehingga distribusinya memiliki mean 0 dan standar deviasi 1.
Standardisasi paling tepat dalam kasus berikut:
Terkadang, sulit membedakan antara normalisasi dan standardisasi. Di satu sisi, normalisasi kadang digunakan sebagai istilah yang lebih umum, sementara standardisasi memiliki makna yang sedikit lebih spesifik atau teknis. Selain itu, analis data dan data scientist yang akrab dengan istilah tersebut mungkin tetap kesulitan membedakan kasus penggunaannya.
Meskipun keduanya adalah teknik penskalaan fitur, pendekatan dan penerapannya berbeda. Memahami perbedaan ini adalah kunci untuk memilih teknik yang tepat bagi model machine learning Anda.
Normalisasi menskalakan ulang nilai fitur dalam rentang yang telah ditentukan, sering kali antara 0 dan 1, yang sangat berguna untuk model dengan skala fitur yang sangat bervariasi. Sebaliknya, standardisasi memusatkan data di sekitar mean (0) dan menskalakannya sesuai standar deviasi (1).
Berbagai teknik normalisasi berbeda efektivitasnya dalam menangani pencilan. Normalisasi mean dapat berhasil menyesuaikan pencilan pada beberapa skenario, tetapi teknik lain mungkin tidak seefektif itu. Secara umum, teknik normalisasi tidak menangani masalah pencilan seefektif standardisasi karena standardisasi secara eksplisit bergantung pada mean dan standar deviasi.
Normalisasi banyak digunakan dalam algoritma berbasis jarak seperti k-Nearest Neighbors (k-NN), di mana fitur harus berada pada skala yang sama untuk memastikan akurasi dalam perhitungan jarak. Standardisasi, di sisi lain, penting untuk algoritma berbasis gradien seperti Support Vector Machines (SVM) dan sering diterapkan dalam teknik reduksi dimensi seperti PCA, di mana menjaga varians fitur yang benar itu penting.
Mari kita lihat semua perbedaan utama ini dalam tabel ringkasan untuk memudahkan membandingkan normalisasi dan standardisasi:
| Kategori | Normalisasi | Standardisasi |
|---|---|---|
| Metode Penskalaan Ulang | Menskalakan data ke suatu rentang (biasanya 0 hingga 1) berdasarkan nilai minimum dan maksimum. | Memusatkan data di sekitar mean (0) dan menskalakannya dengan standar deviasi (1). |
| Sensitivitas terhadap pencilan | Normalisasi dapat membantu menyesuaikan pencilan jika digunakan dengan benar, tergantung pada tekniknya. | Standardisasi merupakan pendekatan yang lebih konsisten untuk mengatasi masalah pencilan. |
| Algoritma Umum | Sering diterapkan pada algoritma seperti k-NN dan neural network yang memerlukan data berada pada skala yang konsisten. | Paling cocok untuk algoritma yang memerlukan fitur pada skala umum, seperti regresi logistik, SVM, dan PCA. |
Untuk memahami perbedaan antara normalisasi dan standardisasi, akan membantu jika melihat dampaknya secara visual dan dalam hal kinerja model. Di sini, saya sertakan boxplot untuk menunjukkan teknik penskalaan fitur yang berbeda. Di sini, saya menggunakan normalisasi min-maks pada setiap variabel dalam dataset saya. Kita dapat melihat bahwa tidak ada nilai yang lebih rendah dari 0 atau lebih besar dari 1.
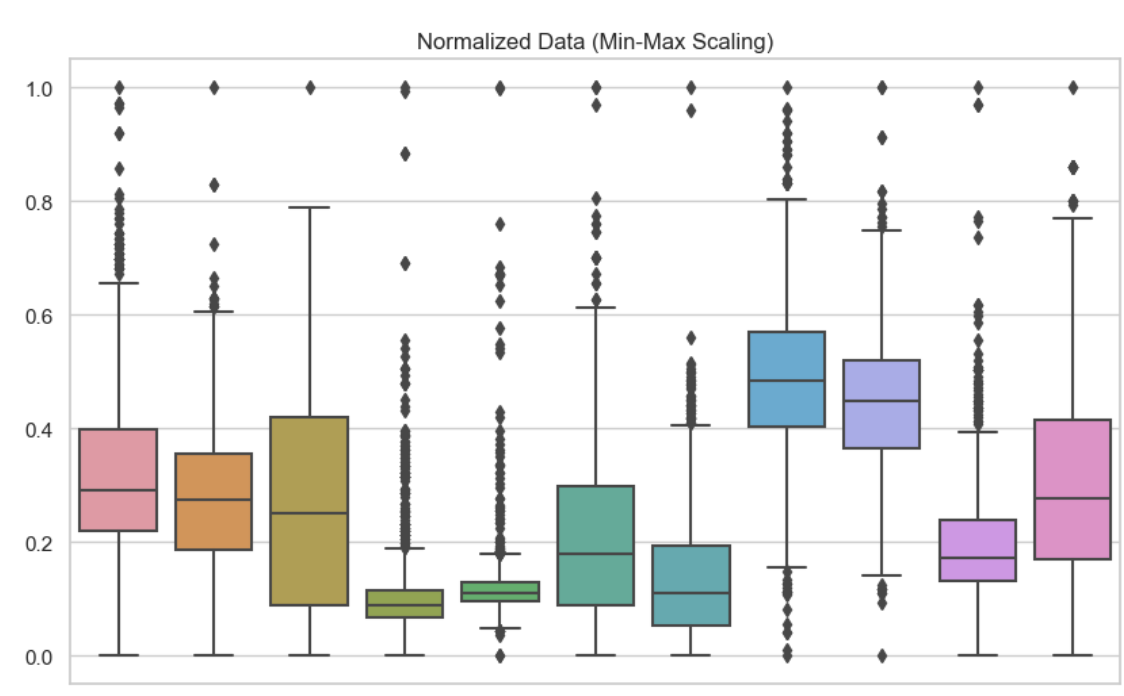
Data yang dinormalisasi. Gambar oleh Penulis
Pada visual kedua ini, saya menggunakan standardisasi pada setiap variabel. Kita dapat melihat bahwa data dipusatkan pada nol.
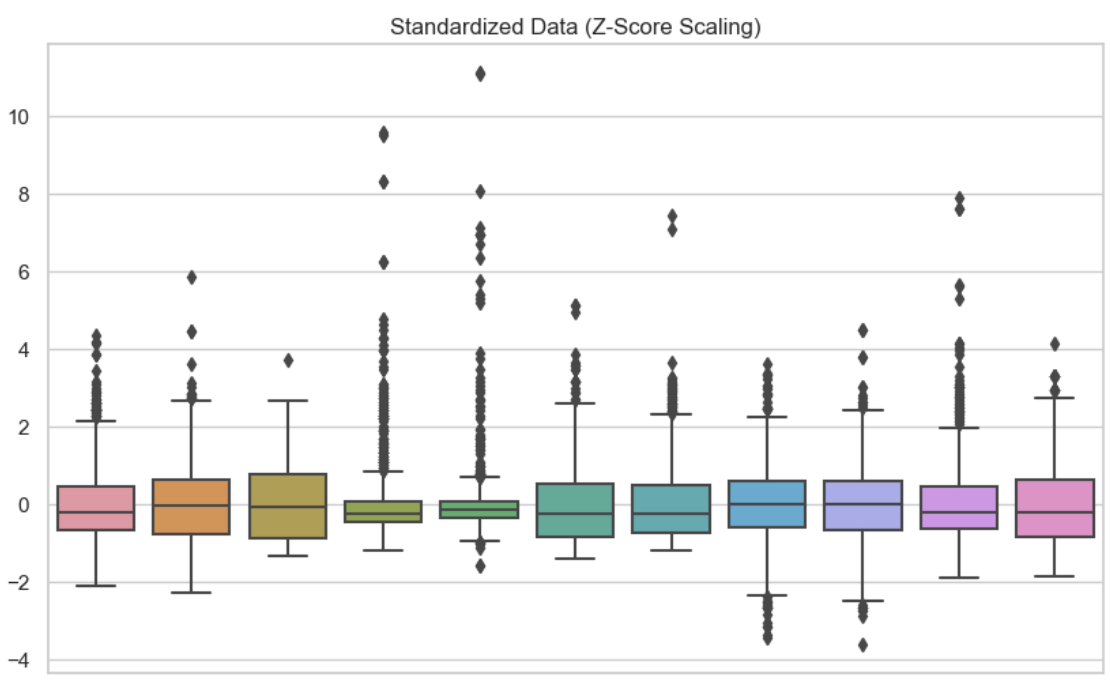 Data yang distandardisasi. Gambar oleh Penulis
Data yang distandardisasi. Gambar oleh Penulis
Kelebihannya termasuk peningkatan kinerja model dan kontribusi fitur yang seimbang. Namun, normalisasi dapat membatasi keterjelasan interpretasi karena skala yang tetap, sementara standardisasi juga dapat membuat interpretasi lebih sulit karena nilainya tidak lagi mencerminkan satuan aslinya. Selalu ada pertukaran antara kompleksitas model dan akurasi model.
Mari pertimbangkan bagaimana normalisasi (dalam hal ini, normalisasi mean) dan standardisasi dapat mengubah interpretasi model regresi linear sederhana. Nilai R-squared atau adjusted R-squared akan sama untuk setiap model, sehingga penskalaan fitur di sini hanya menyangkut interpretasi model kita.
| Transformasi Diterapkan | Variabel Independen (Ukuran Rumah) | Variabel Dependen (Harga Rumah) | Interpretasi |
|---|---|---|---|
| Normalisasi Mean | Dinormalisasi Mean | Asli | Anda memprediksi harga rumah asli untuk setiap perubahan ukuran rumah relatif terhadap rata-rata. |
| Standardisasi | Distandardisasi | Asli | Anda memprediksi harga rumah asli untuk setiap perubahan satu standar deviasi pada ukuran rumah. |
| Normalisasi Mean | Asli | Dinormalisasi Mean | Anda memprediksi harga rumah relatif terhadap rata-rata untuk setiap kenaikan satu satuan pada ukuran rumah asli. |
| Standardisasi | Asli | Distandardisasi | Anda memprediksi harga rumah yang distandardisasi untuk setiap kenaikan satu satuan pada ukuran rumah asli. |
| Normalisasi Mean (Kedua Variabel) | Dinormalisasi Mean | Dinormalisasi Mean | Anda memprediksi harga rumah relatif terhadap rata-rata untuk setiap perubahan ukuran rumah relatif terhadap rata-rata. |
| Standardisasi (Kedua Variabel) | Distandardisasi | Distandardisasi | Anda memprediksi harga rumah yang distandardisasi untuk setiap perubahan satu standar deviasi pada ukuran rumah. |
Sebagai catatan penting lainnya, dalam regresi linear, jika Anda menstandardisasi variabel independen dan dependen, nilai r-squared akan tetap sama. Ini karena r-squared mengukur proporsi varians pada y yang dijelaskan oleh x, dan proporsi ini tetap sama terlepas dari apakah variabelnya distandardisasi atau tidak. Namun, menstandarkan variabel dependen akan mengubah RMSE, karena RMSE diukur dalam satuan yang sama dengan variabel dependen. Karena y kini distandardisasi, RMSE akan lebih rendah setelah standardisasi. Secara khusus, ini akan mencerminkan galat dalam hal standar deviasi dari variabel yang distandardisasi, bukan satuan asli. Jika regresi sangat menarik bagi Anda, ikuti kursus Introduction to Regression with statsmodels in Python kami untuk menjadi ahli.
Penskalaan fitur, yang mencakup normalisasi dan standardisasi, adalah komponen krusial dari pra-pemrosesan data dalam machine learning. Memahami konteks yang tepat untuk menerapkan masing-masing teknik dapat secara signifikan meningkatkan kinerja dan akurasi model Anda.
Jika Anda ingin memperluas dan memperdalam pemahaman tentang penskalaan fitur dan perannya dalam machine learning, kami memiliki beberapa sumber daya unggulan di DataCamp untuk memulai. Anda dapat menjelajahi artikel kami tentang Normalisasi dalam Machine Learning untuk konsep dasar, atau mempertimbangkan kursus End-to-End Machine Learning kami yang membahas penerapan nyata.
Belajar bersama DataCamp
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Javier Canales Luna
14 mnt
