
Corso
Preprocessing per il Machine Learning in Python
4 h
67.4K
Normalizzazione e standardizzazione appartengono entrambe alla categoria dello scaling delle feature. Lo scaling delle feature è uno step importante nella preparazione dei dati per i modelli di machine learning. Consiste nel trasformare i valori delle feature in un intervallo simile, assicurando che tutte contribuiscano in modo equilibrato al processo di apprendimento del modello.
Lo scaling delle feature è importante perché, quando le feature hanno scale molto diverse, ad esempio una tra 1 e 10 e un’altra tra 1.000 e 10.000, i modelli possono dare priorità ai valori più grandi, portando a bias nelle previsioni. Questo può causare scarse prestazioni del modello e una convergenza più lenta durante l’addestramento.
Lo scaling affronta questi problemi regolando l’intervallo dei dati senza distorcere le differenze nei valori. Esistono diverse tecniche di scaling, tra cui le più comuni sono normalizzazione e standardizzazione. Entrambi i metodi aiutano i modelli di machine learning a dare il meglio bilanciando l’impatto delle feature, riducendo l’influenza degli outlier e, in alcuni casi, migliorando i tassi di convergenza.
La normalizzazione è un concetto ampio e ci sono diversi modi per normalizzare i dati. In generale, si riferisce al processo di adattamento di valori misurati su scale differenti a una scala comune. A volte è meglio illustrarlo con un esempio. Per ciascun tipo di normalizzazione qui sotto, considereremo un modello per capire la relazione tra il prezzo di una casa e la sua dimensione.
Diamo un’occhiata ad alcuni dei principali tipi. Tieni presente che non è un elenco esaustivo:
Con la normalizzazione min-max, potremmo riscalare le dimensioni delle case per farle rientrare nell’intervallo 0–1. Questo significa che la casa più piccola sarebbe rappresentata da 0 e la più grande da 1.
La normalizzazione logaritmica è un’altra tecnica di normalizzazione. Applicando una trasformazione logaritmica ai prezzi delle case, si riduce l’impatto dei prezzi più elevati, soprattutto quando ci sono differenze notevoli tra loro.
Lo scaling decimale è un’altra tecnica di normalizzazione. In questo esempio, potremmo regolare le dimensioni delle case spostando la virgola per rendere i valori più piccoli. In questo modo le dimensioni vengono trasformate su una scala più gestibile mantenendo intatte le differenze relative.
La normalizzazione rispetto alla media, in questo contesto, consiste nel regolare i prezzi sottraendo da ciascun prezzo la media dei prezzi. Questo processo centra i prezzi su zero, mostrando come la dimensione di ciascuna casa si confronta con la media. Così possiamo analizzare quali dimensioni sono sopra o sotto la media, rendendo più facile interpretarne i prezzi relativi.
Come avrai intuito dagli esempi sopra, la normalizzazione è particolarmente utile quando la distribuzione dei dati è sconosciuta o non segue una distribuzione gaussiana. I prezzi delle case sono un buon esempio perché alcune abitazioni sono molto, molto costose e i modelli non sempre gestiscono bene gli outlier.
Quindi, l’obiettivo della normalizzazione è costruire un modello migliore. Potremmo normalizzare la variabile dipendente per distribuire in modo più uniforme gli errori, oppure normalizzare le variabili in input per evitare che le feature con scale maggiori dominino su quelle con scale minori.
La normalizzazione è più efficace nei seguenti scenari:
Mentre la normalizzazione ridimensiona le feature a un intervallo specifico, la standardizzazione, detta anche z-score scaling, trasforma i dati per avere media 0 e deviazione standard 1. Questo processo regola i valori delle feature sottraendo la media e dividendo per la deviazione standard. Forse hai sentito parlare di “centratura e scalatura” dei dati. Ecco, la standardizzazione si riferisce proprio a questo: prima centrare, poi scalare.
La formula della standardizzazione è:
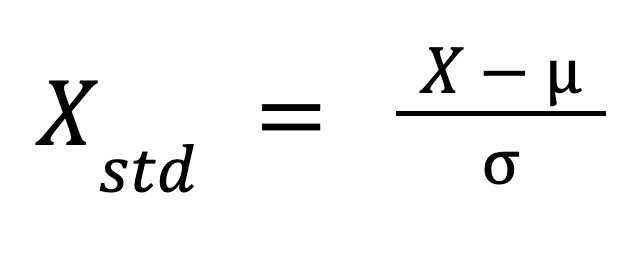
Dove:
Questa formula riscalare i dati in modo che la loro distribuzione abbia media 0 e deviazione standard 1.
La standardizzazione è più appropriata nei seguenti casi:
A volte è difficile distinguere tra normalizzazione e standardizzazione. Per cominciare, normalizzazione viene talvolta usato come termine più generale, mentre standardizzazione ha un significato un po’ più specifico e tecnico. Inoltre, anche analisti e data scientist che conoscono i termini possono faticare a distinguerne i casi d’uso.
Sebbene siano entrambe tecniche di scaling, differiscono per approccio e applicazioni. Capire queste differenze è fondamentale per scegliere la tecnica giusta per il tuo modello di machine learning.
La normalizzazione riscalare i valori delle feature entro un intervallo predefinito, spesso tra 0 e 1, particolarmente utile quando la scala delle feature varia molto. Al contrario, la standardizzazione centra i dati attorno alla media (0) e li scala in base alla deviazione standard (1).
Le diverse tecniche di normalizzazione variano in efficacia nella gestione degli outlier. La normalizzazione rispetto alla media può correggere con successo gli outlier in alcuni scenari, ma altre tecniche potrebbero non essere altrettanto efficaci. In generale, la normalizzazione non gestisce gli outlier in modo efficace quanto la standardizzazione, perché quest’ultima si basa esplicitamente sia sulla media sia sulla deviazione standard.
La normalizzazione è ampiamente usata in algoritmi basati sulla distanza come k-Nearest Neighbors (k-NN), in cui le feature devono trovarsi sulla stessa scala per garantire accuratezza nei calcoli di distanza. La standardizzazione, invece, è vitale per algoritmi basati sul gradiente come le Support Vector Machines (SVM) ed è spesso applicata in tecniche di riduzione della dimensionalità come la PCA, dove è importante mantenere la corretta varianza delle feature.
Rivediamo queste differenze chiave in una tabella riassuntiva per rendere più facile confrontare normalizzazione e standardizzazione:
| Categoria | Normalizzazione | Standardizzazione |
|---|---|---|
| Metodo di riscaling | Ridimensiona i dati a un intervallo (di solito 0–1) in base ai valori minimo e massimo. | Centra i dati sulla media (0) e li scala in base alla deviazione standard (1). |
| Sensibilità agli outlier | La normalizzazione può aiutare a correggere gli outlier se usata correttamente, a seconda della tecnica. | La standardizzazione è un approccio più coerente per affrontare i problemi di outlier. |
| Algoritmi comuni | Spesso applicata in algoritmi come k-NN e reti neurali che richiedono dati su una scala coerente. | Più adatta ad algoritmi che richiedono feature su una scala comune, come regressione logistica, SVM e PCA. |
Per capire le differenze tra normalizzazione e standardizzazione, è utile vederne gli effetti in modo visivo e in termini di prestazioni del modello. Qui ho incluso boxplot per mostrare queste tecniche di scaling. In questo caso ho usato la normalizzazione min-max su ciascuna variabile del dataset. Possiamo vedere che nessun valore è inferiore a 0 o superiore a 1.
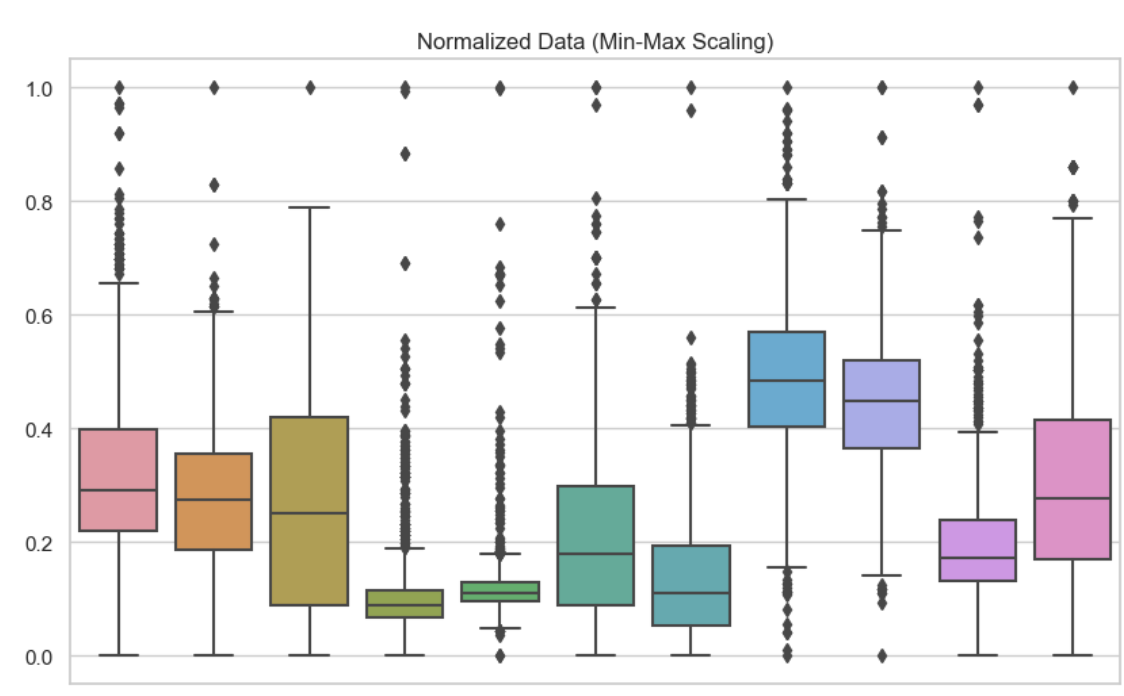
Dati normalizzati. Immagine dell’autore
In questa seconda visualizzazione ho usato la standardizzazione su ciascuna variabile. Possiamo vedere che i dati sono centrati su zero.
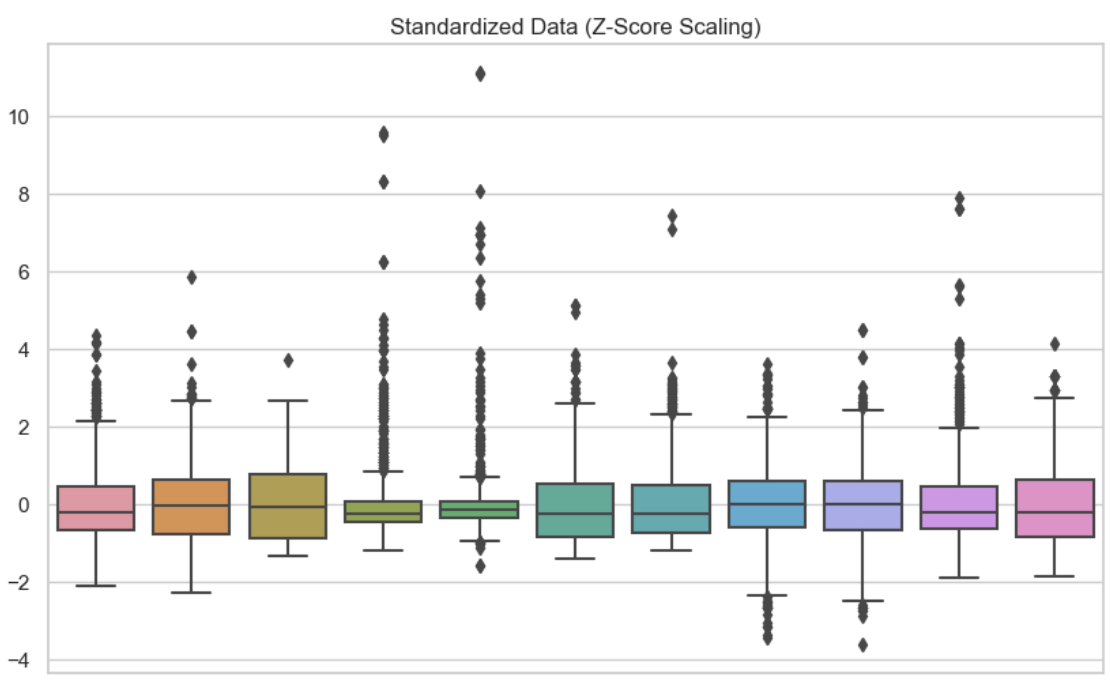 Dati standardizzati. Immagine dell’autore
Dati standardizzati. Immagine dell’autore
I vantaggi includono prestazioni del modello migliorate e contributi bilanciati delle feature. Tuttavia, la normalizzazione può limitare l’interpretabilità a causa della scala fissa, mentre la standardizzazione può comunque rendere l’interpretazione più difficile perché i valori non riflettono più le unità originali. C’è sempre un trade-off tra complessità e accuratezza del modello.
Vediamo come la normalizzazione (in questo caso, rispetto alla media) e la standardizzazione possano cambiare l’interpretazione di un modello di regressione lineare semplice. L’R-quadrato o l’R-quadrato corretto sarebbero gli stessi per ciascun modello, quindi lo scaling qui riguarda solo l’interpretazione del modello.
| Trasformazione applicata | Variabile indipendente (dimensione della casa) | Variabile dipendente (prezzo della casa) | Interpretazione |
|---|---|---|---|
| Normalizzazione rispetto alla media | Normalizzata rispetto alla media | Originale | Stai prevedendo il prezzo originale della casa per ogni variazione della dimensione rispetto alla media. |
| Standardizzazione | Standardizzata | Originale | Stai prevedendo il prezzo originale della casa per ogni variazione di una deviazione standard nella dimensione. |
| Normalizzazione rispetto alla media | Originale | Normalizzata rispetto alla media | Stai prevedendo il prezzo della casa relativo alla media per ogni incremento di un’unità della dimensione originale. |
| Standardizzazione | Originale | Standardizzata | Stai prevedendo il prezzo standardizzato della casa per ogni incremento di un’unità della dimensione originale. |
| Normalizzazione (entrambe le variabili) | Normalizzata rispetto alla media | Normalizzata rispetto alla media | Stai prevedendo il prezzo della casa relativo alla media per ogni variazione della dimensione relativa alla media. |
| Standardizzazione (entrambe le variabili) | Standardizzata | Standardizzata | Stai prevedendo il prezzo standardizzato della casa per ogni variazione di una deviazione standard nella dimensione. |
Un’ulteriore nota importante: nella regressione lineare, se standardizzi le variabili indipendenti e dipendenti, l’R-quadrato rimarrà invariato. Questo perché l’R-quadrato misura la quota di varianza in y spiegata da x, e questa quota resta la stessa indipendentemente dalla standardizzazione. Tuttavia, standardizzare la variabile dipendente cambierà la RMSE, perché la RMSE è misurata nelle stesse unità della variabile dipendente. Poiché ora y è standardizzata, la RMSE sarà più bassa dopo la standardizzazione. In particolare, rifletterà l’errore in termini della deviazione standard della variabile standardizzata, non nelle unità originali. Se la regressione ti interessa in modo particolare, segui il corso Introduction to Regression with statsmodels in Python per diventare un esperto.
Lo scaling delle feature, che include normalizzazione e standardizzazione, è un elemento fondamentale del preprocessing dei dati nel machine learning. Capire quando applicare ciascuna tecnica può migliorare notevolmente le prestazioni e l’accuratezza dei tuoi modelli.
Se vuoi ampliare e approfondire la tua comprensione dello scaling delle feature e del suo ruolo nel machine learning, su DataCamp abbiamo diverse ottime risorse per iniziare. Puoi esplorare il nostro articolo su Normalization in Machine Learning per i concetti di base, oppure il corso End-to-End Machine Learning, con applicazioni reali.
Impara con DataCamp
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

