
Cursus
Preprocessing voor Machine Learning in Python
4 Hr
67.4K
Normaliseren en standaardiseren vallen beide onder het idee of de categorie featurescaling. Featurescaling is een belangrijke stap in het voorbereiden van data voor machinelearningmodellen. Het houdt in dat je de waarden van features in een dataset naar een vergelijkbare schaal transformeert, zodat alle features evenveel bijdragen aan het leerproces van het model.
Featurescaling is belangrijk omdat, wanneer features sterk van schaal verschillen, zoals een feature die loopt van 1 tot 10 en een andere van 1.000 tot 10.000, modellen de grotere waarden kunnen prioriteren, wat leidt tot bias in voorspellingen. Dit kan resulteren in slechte modelprestaties en langzamere convergentie tijdens training.
Featurescaling pakt deze problemen aan door het bereik van de data aan te passen zonder de verschillen in waarden te vervormen. Er zijn verschillende scalingtechnieken, waarbij normaliseren en standaardiseren het meest gebruikt worden. Beide methoden helpen machinelearningmodellen optimaal te presteren door de impact van features in balans te brengen, de invloed van uitschieters te verminderen en in sommige gevallen de convergentiesnelheid te verbeteren.
Normaliseren is een breed begrip en er zijn verschillende manieren om data te normaliseren. In het algemeen verwijst normaliseren naar het aanpassen van waarden die op verschillende schalen zijn gemeten naar een gemeenschappelijke schaal. Soms is het het beste om dit met een voorbeeld te illustreren. Voor elk type normalisatie hieronder bekijken we een model om de relatie tussen de prijs van een huis en de grootte ervan te begrijpen.
Laten we enkele van de belangrijkste typen bekijken. Houd er rekening mee dat dit geen volledige lijst is:
Met min-max-normalisatie zouden we de groottes van de huizen herschalen zodat ze binnen een bereik van 0 tot 1 vallen. Dit betekent dat de kleinste huisgrootte wordt weergegeven als 0 en de grootste als 1.
Log-normalisatie is een andere normalisatietechniek. Door log-normalisatie toe te passen, voeren we een logaritmische transformatie uit op de huizenprijzen. Deze techniek helpt de impact van hogere prijzen te verminderen, vooral als er grote verschillen tussen zitten.
Decimale schaling is een andere normalisatietechniek. In dit voorbeeld zouden we de groottes van de huizen aanpassen door het decimale punt te verschuiven om de waarden kleiner te maken. Dit betekent dat de huisgroottes worden getransformeerd naar een beter hanteerbare schaal, terwijl hun onderlinge verhoudingen intact blijven.
Gemiddeldenormalisatie houdt in deze context in dat we de huizenprijzen aanpassen door de gemiddelde prijs van elke huizenprijs af te trekken. Dit centreert de prijzen rond nul en laat zien hoe de grootte van elk huis zich verhoudt tot het gemiddelde. Zo kunnen we analyseren welke huisgroottes groter of kleiner dan gemiddeld zijn, wat de interpretatie van hun relatieve prijzen makkelijker maakt.
Zoals je uit de bovenstaande voorbeelden kunt afleiden, is normaliseren vooral nuttig wanneer de verdeling van de data onbekend is of niet een Gauss-verdeling volgt. Huizenprijzen zijn hier een goed voorbeeld, omdat sommige huizen héél erg duur zijn, en modellen gaan niet altijd even goed om met uitschieters.
Het doel van normaliseren is dus een beter model te maken. We kunnen de afhankelijke variabele normaliseren zodat de fouten gelijkmatiger verdeeld zijn, of we normaliseren de invoervariabelen om te voorkomen dat features met grotere schalen die met kleinere schalen domineren.
Normaliseren is het meest effectief in de volgende scenario's:
Waar normaliseren features schaalt naar een specifiek bereik, transformeert standaardiseren, ook wel z-scoreschaling genoemd, data zodat het gemiddelde 0 is en de standaardafwijking 1. Dit proces past de featurewaarden aan door het gemiddelde af te trekken en door de standaardafwijking te delen. Misschien heb je wel eens gehoord van ‘centeren en schalen’ van data. Standaardiseren verwijst naar hetzelfde: eerst centeren, dan schalen.
De formule voor standaardiseren is:
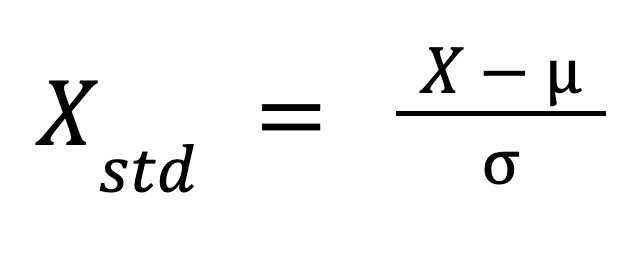
Waarbij:
Deze formule herschaalt de data zodanig dat de verdeling een gemiddelde van 0 en een standaardafwijking van 1 heeft.
Standaardiseren is het meest geschikt in de volgende gevallen:
Soms is het lastig om onderscheid te maken tussen normaliseren en standaardiseren. Normaliseren wordt om te beginnen soms gebruikt als meer overkoepelende term, terwijl standaardiseren een wat specifiekere of technischere betekenis heeft. Ook data-analisten en data scientists die met de termen bekend zijn, kunnen nog worstelen met de toepassingsgevallen.
Hoewel het beide featurescalingtechnieken zijn, verschillen ze in aanpak en toepassing. Deze verschillen begrijpen is de sleutel tot het kiezen van de juiste techniek voor je machinelearningmodel.
Normaliseren herschaalt featurewaarden binnen een vooraf gedefinieerd bereik, vaak tussen 0 en 1, wat vooral nuttig is voor modellen waarbij de schaal van features sterk verschilt. Standaardiseren daarentegen centreert data rond het gemiddelde (0) en schaalt het volgens de standaardafwijking (1).
Verschillende normalisatietechnieken variëren in hun effectiviteit bij het omgaan met uitschieters. Gemiddeldenormalisatie kan in sommige scenario's uitschieters goed corrigeren, maar andere technieken zijn mogelijk minder effectief. In het algemeen lossen normalisatietechnieken het uitschieterprobleem minder doeltreffend op dan standaardiseren, omdat standaardiseren expliciet berust op zowel het gemiddelde als de standaardafwijking.
Normaliseren wordt veel gebruikt in afstand-gebaseerde algoritmen zoals k-Nearest Neighbors (k-NN), waarbij features op dezelfde schaal moeten staan om nauwkeurige afstandsberekeningen te garanderen. Standaardiseren daarentegen is essentieel voor gradient-gebaseerde algoritmen zoals Support Vector Machines (SVM) en wordt vaak toegepast bij dimensiereductietechnieken zoals PCA, waar het behoud van de juiste featurevariantie belangrijk is.
Laten we al deze belangrijke verschillen in een overzichtstabel bekijken om normaliseren en standaardiseren makkelijker te kunnen vergelijken:
| Categorie | Normaliseren | Standaardiseren |
|---|---|---|
| Herschalingsmethode | Schaalt data naar een bereik (meestal 0 tot 1) op basis van minimum- en maximumwaarden. | Centreert data rond het gemiddelde (0) en schaalt het met de standaardafwijking (1). |
| Gevoeligheid voor uitschieters | Normaliseren kan, afhankelijk van de techniek, helpen om uitschieters te corrigeren als het correct wordt toegepast. | Standaardiseren is een consequenter aanpak om uitschieterproblemen op te lossen. |
| Veelgebruikte algoritmen | Wordt vaak toegepast in algoritmen zoals k-NN en neurale netwerken die vereisen dat data op een consistente schaal staat. | Het best geschikt voor algoritmen die vereisen dat features een gemeenschappelijke schaal hebben, zoals logistische regressie, SVM en PCA. |
Om de verschillen tussen normaliseren en standaardiseren te begrijpen, is het handig om hun effecten visueel en qua modelprestaties te zien. Hier heb ik boxplots opgenomen om deze verschillende featurescalingtechnieken te tonen. Hier heb ik min-max-normalisatie gebruikt op elk van de variabelen in mijn dataset. We zien dat geen enkele waarde lager is dan 0 of groter dan 1.
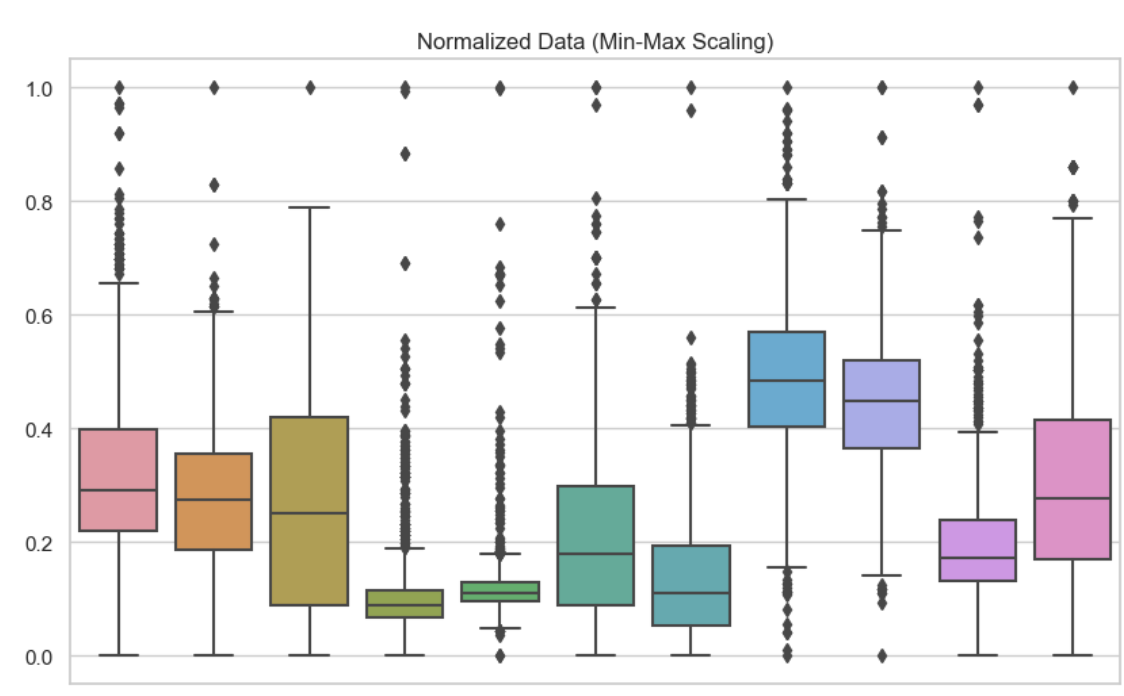
Genormaliseerde data. Afbeelding door de auteur
In deze tweede visual heb ik standaardisatie toegepast op elk van de variabelen. We zien dat de data rond nul is gecentreerd.
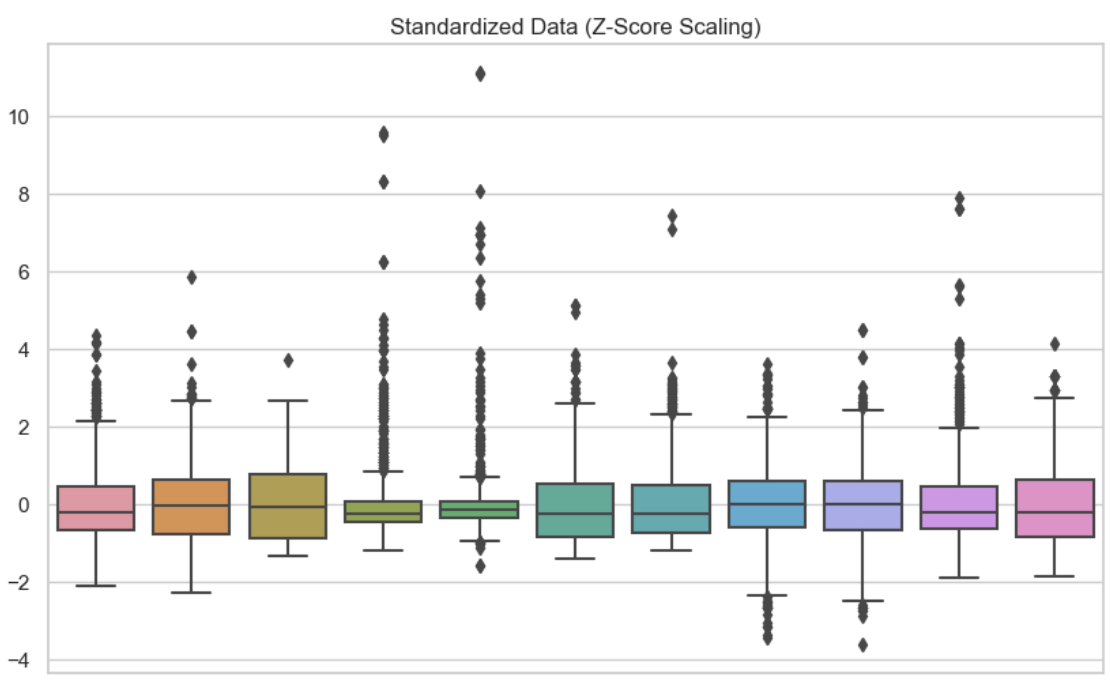 Gestandaardiseerde data. Afbeelding door de auteur
Gestandaardiseerde data. Afbeelding door de auteur
De voordelen zijn onder meer verbeterde modelprestaties en evenwichtige featurebijdragen. Normaliseren kan de interpretatie echter beperken door de vaste schaal, terwijl standaardiseren de interpretatie ook moeilijker kan maken omdat de waarden niet langer hun oorspronkelijke eenheden weerspiegelen. Er is altijd een trade-off tussen modelcomplexiteit en modelnauwkeurigheid.
Laten we bekijken hoe normaliseren (in dit geval gemiddeldenormalisatie) en standaardiseren de interpretatie van een model voor eenvoudige lineaire regressie kunnen veranderen. De R-kwadraat of aangepaste R-kwadraat zou voor elk model hetzelfde zijn, dus de featurescaling hier gaat alleen over de interpretatie van ons model.
| Toegepaste transformatie | Onafhankelijke variabele (huisgrootte) | Afhankelijke variabele (huisprijs) | Interpretatie |
|---|---|---|---|
| Gemiddeldenormalisatie | Gemiddeldegenormaliseerd | Origineel | Je voorspelt de oorspronkelijke huizenprijs voor elke verandering in huisgrootte ten opzichte van het gemiddelde. |
| Standaardisatie | Gestandaardiseerd | Origineel | Je voorspelt de oorspronkelijke huizenprijs voor elke verandering van één standaardafwijking in huisgrootte. |
| Gemiddeldenormalisatie | Origineel | Gemiddeldegenormaliseerd | Je voorspelt de huizenprijs ten opzichte van het gemiddelde voor elke toename van één eenheid in de oorspronkelijke huisgrootte. |
| Standaardisatie | Origineel | Gestandaardiseerd | Je voorspelt de gestandaardiseerde huizenprijs voor elke toename van één eenheid in de oorspronkelijke huisgrootte. |
| Gemiddeldenormalisatie (beide variabelen) | Gemiddeldegenormaliseerd | Gemiddeldegenormaliseerd | Je voorspelt de huizenprijs ten opzichte van het gemiddelde voor elke verandering in huisgrootte ten opzichte van het gemiddelde. |
| Standaardisatie (beide variabelen) | Gestandaardiseerd | Gestandaardiseerd | Je voorspelt de gestandaardiseerde huizenprijs voor elke verandering van één standaardafwijking in huisgrootte. |
Nog een belangrijke opmerking: bij lineaire regressie blijft de R-kwadraat hetzelfde als je de onafhankelijke en afhankelijke variabelen standaardiseert. Dit komt doordat R-kwadraat het aandeel van de variantie in y meet dat wordt verklaard door x, en dit aandeel blijft hetzelfde, of de variabelen nu gestandaardiseerd zijn of niet. Het standaardiseren van de afhankelijke variabele zal echter de RMSE veranderen, omdat RMSE wordt gemeten in dezelfde eenheden als de afhankelijke variabele. Omdat y nu gestandaardiseerd is, zal de RMSE lager zijn na standaardisatie. Concreet weerspiegelt die dan de fout in termen van de standaardafwijking van de gestandaardiseerde variabele, niet de oorspronkelijke eenheden. Als regressie je speciaal interesseert, volg dan onze cursus Introduction to Regression with statsmodels in Python om expert te worden.
Featurescaling, waaronder normaliseren en standaardiseren, is een cruciaal onderdeel van datavoorbewerking in machine learning. Het begrijpen van de juiste contexten voor het toepassen van elke techniek kan de prestaties en nauwkeurigheid van je modellen aanzienlijk verbeteren.
Als je je begrip van featurescaling en de rol ervan in machine learning wilt uitbreiden en verdiepen, hebben we bij DataCamp verschillende uitstekende resources om mee te beginnen. Je kunt ons artikel over Normalization in Machine Learning verkennen voor fundamentele concepten, of onze cursus End-to-End Machine Learning volgen, met aandacht voor toepassingen in de praktijk.
Leren met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
