
Curso
Pré-processamento para Machine Learning em Python
4 h
66.5K
A normalização e a padronização pertencem à ideia ou categoria de escalonamento de recursos. O dimensionamento de recursos é uma etapa importante na preparação de dados para modelos de aprendizado de máquina. Isso envolve a transformação dos valores dos recursos em um conjunto de dados em uma escala semelhante, garantindo que todos os recursos contribuam igualmente para o processo de aprendizado do modelo.
O escalonamento de recursos é importante porque, quando os recursos estão em escalas muito diferentes, como um recurso que varia de 1 a 10 e outro de 1.000 a 10.000, os modelos podem priorizar os valores maiores, o que leva a um viés nas previsões. Isso pode resultar em um desempenho ruim do modelo e em uma convergência mais lenta durante o treinamento.
A escala de recursos aborda esses problemas ajustando o intervalo dos dados sem distorcer as diferenças nos valores. Há várias técnicas de dimensionamento, sendo a normalização e a padronização as mais comumente usadas. Ambos os métodos ajudam os modelos de aprendizado de máquina a ter um desempenho ideal, equilibrando o impacto dos recursos, reduzindo a influência de outliers e, em alguns casos, melhorando as taxas de convergência.
A normalização é uma ideia ampla, e há diferentes maneiras de normalizar os dados. De modo geral, a normalização refere-se ao processo de ajuste de valores medidos em escalas diferentes para uma escala comum. Às vezes, é melhor ilustrar com um exemplo. Para cada tipo de normalização abaixo, consideraremos um modelo para entender a relação entre o preço de uma casa e seu tamanho.
Vamos dar uma olhada em alguns dos principais tipos. Lembre-se de que esta não é uma lista completa:
Com a normalização min-max, podemos redimensionar os tamanhos das casas para que se encaixem em um intervalo de 0 a 1. Isso significa que o menor tamanho de casa seria representado por 0, e o maior tamanho de casa seria representado por 1.
A normalização de logs é outra técnica de normalização. Ao usar a normalização logarítmica, aplicamos uma transformação logarítmica aos preços dos imóveis. Essa técnica ajuda a reduzir o impacto de preços maiores, especialmente se houver diferenças significativas entre eles.
A escala decimal é outra técnica de normailzação. Para este exemplo, podemos ajustar os tamanhos das casas deslocando o ponto decimal para tornar os valores menores. Isso significa que os tamanhos das casas são transformados em uma escala mais gerenciável, mantendo suas diferenças relativas intactas.
A normalização da média, nesse contexto, envolveria o ajuste dos preços dos imóveis, subtraindo o preço médio do preço de cada imóvel. Esse processo centraliza os preços em zero, mostrando como o tamanho de cada casa se compara à média. Ao fazer isso, podemos analisar quais tamanhos de casas são maiores ou menores do que a média, facilitando a interpretação de seus preços relativos.
Como você deve ter deduzido dos exemplos acima, a normalização é particularmente útil quando a distribuição dos dados é desconhecida ou não segue uma distribuição gaussiana. Os preços das casas são um bom exemplo, porque algumas casas são muito, muito caras, e os modelos nem sempre lidam bem com exceções.
Portanto, o objetivo da normalização é criar um modelo melhor. Podemos normalizar a variável dependente para que os erros sejam distribuídos de forma mais uniforme, ou então podemos normalizar as variáveis de entrada para garantir que os recursos com escalas maiores não dominem aqueles com escalas menores.
A normalização é mais eficaz nos seguintes cenários:
Enquanto a normalização dimensiona os recursos para um intervalo específico, a padronização, que também é chamada de dimensionamento de pontuação z, transforma os dados para que tenham uma média de 0 e um desvio padrão de 1. Esse processo ajusta os valores dos recursos subtraindo a média e dividindo pelo desvio padrão. Você já deve ter ouvido falar em "centralização e dimensionamento" de dados. Bem, a padronização se refere à mesma coisa: primeiro a centralização, depois o dimensionamento.
A fórmula para a padronização é:
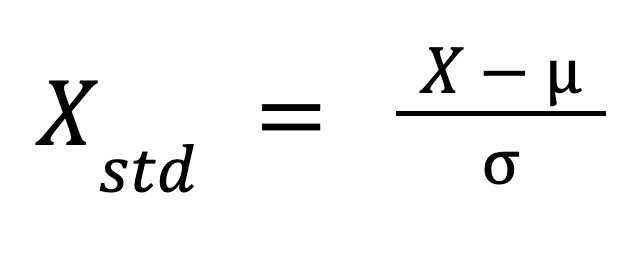
Onde:
Essa fórmula redimensiona os dados de forma que sua distribuição tenha uma média de 0 e um desvio padrão de 1.
A padronização é mais adequada nos seguintes casos:
Às vezes, é difícil distinguir entre normalização e padronização. Por um lado, a normalização às vezes é usada como um termo mais geral, enquanto a padronização tem um significado um pouco mais específico ou especificamente técnico. Além disso, os analistas e cientistas de dados que estão familiarizados com os termos ainda podem ter dificuldades para distinguir os casos de uso.
Embora ambas sejam técnicas de dimensionamento de recursos, elas diferem em suas abordagens e aplicações. Entender essas diferenças é fundamental para que você escolha a técnica certa para o seu modelo de aprendizado de máquina.
A normalização redimensiona os valores dos recursos em um intervalo predefinido, geralmente entre 0 e 1, o que é particularmente útil para modelos em que a escala dos recursos varia muito. Em contrapartida, a padronização centraliza os dados em torno da média (0) e os dimensiona de acordo com o desvio padrão (1).
Diferentes técnicas de normalização variam em sua eficácia no tratamento de outliers. A normalização da média pode ajustar com sucesso os valores discrepantes em alguns cenários, mas outras técnicas podem não ser tão eficazes. Em geral, as técnicas de normalização não lidam com o problema de outlier de forma tão eficaz quanto a padronização, porque a padronização se baseia explicitamente na média e no desvio padrão.
A normalização é amplamente usada em algoritmos baseados em distância, como o k-Nearest Neighbors (k-NN), em que os recursos devem estar na mesma escala para garantir a precisão dos cálculos de distância. A padronização, por outro lado, é essencial para algoritmos baseados em gradiente, como o Support Vector Machines (SVM), e é frequentemente aplicada em técnicas de redução de dimensionalidade, como o PCA, em que é importante manter a variação correta dos recursos.
Vamos analisar todas essas diferenças importantes em uma tabela de resumo para facilitar a comparação entre normalização e padronização:
| Categoria | Normalização | Padronização |
|---|---|---|
| Método de redimensionamento | Dimensiona os dados para um intervalo (geralmente de 0 a 1) com base nos valores mínimo e máximo. | Centraliza os dados em torno da média (0) e os dimensiona pelo desvio padrão (1). |
| Sensibilidade a valores discrepantes | A normalização pode ajudar a ajustar os valores discrepantes se for usada corretamente, dependendo da técnica. | A padronização é uma abordagem mais consistente para corrigir problemas de outlier. |
| Algoritmos comuns | Geralmente aplicado em algoritmos como k-NN e redes neurais que exigem que os dados estejam em uma escala consistente. | Mais adequado para algoritmos que exigem que os recursos tenham uma escala comum, como regressão logística, SVM e PCA. |
Para entender as diferenças entre normalização e padronização, é útil ver seus efeitos visualmente e em termos de desempenho do modelo. Aqui, incluí boxplots para mostrar essas diferentes técnicas de dimensionamento de recursos. Aqui, usei a normalização min-max em cada uma das variáveis do meu conjunto de dados. Podemos ver que nenhum valor é menor que 0 ou maior que 1.
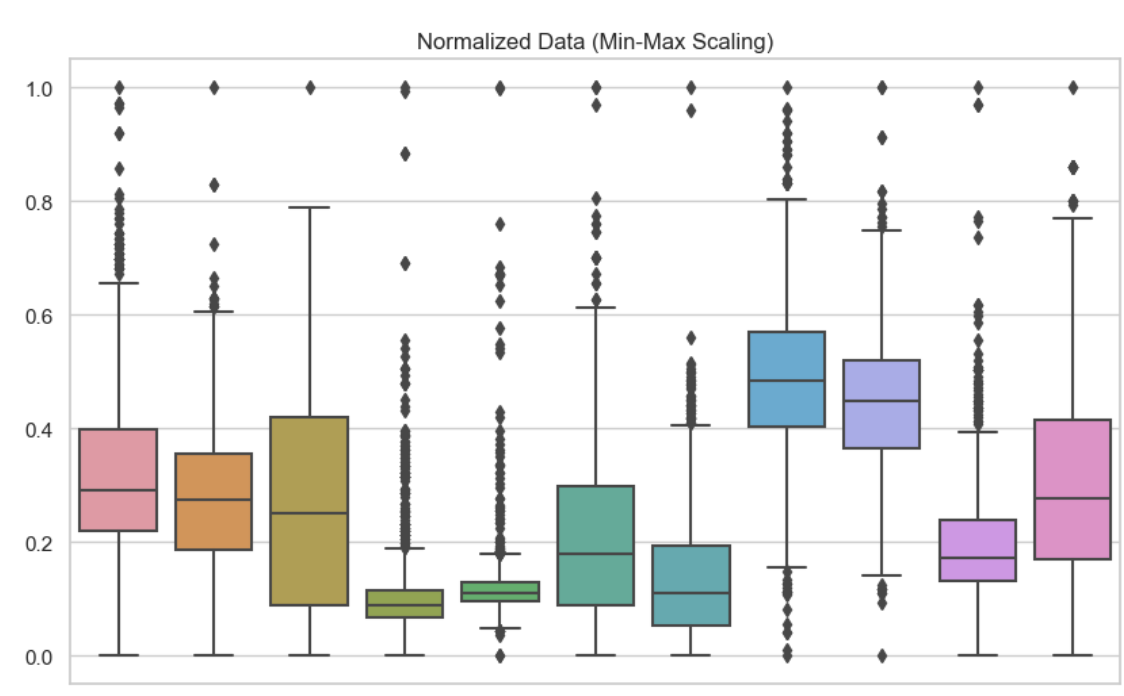
Dados normalizados. Imagem do autor
Nesse segundo visual, usei a padronização em cada uma das variáveis. Podemos ver que os dados estão centralizados em zero.
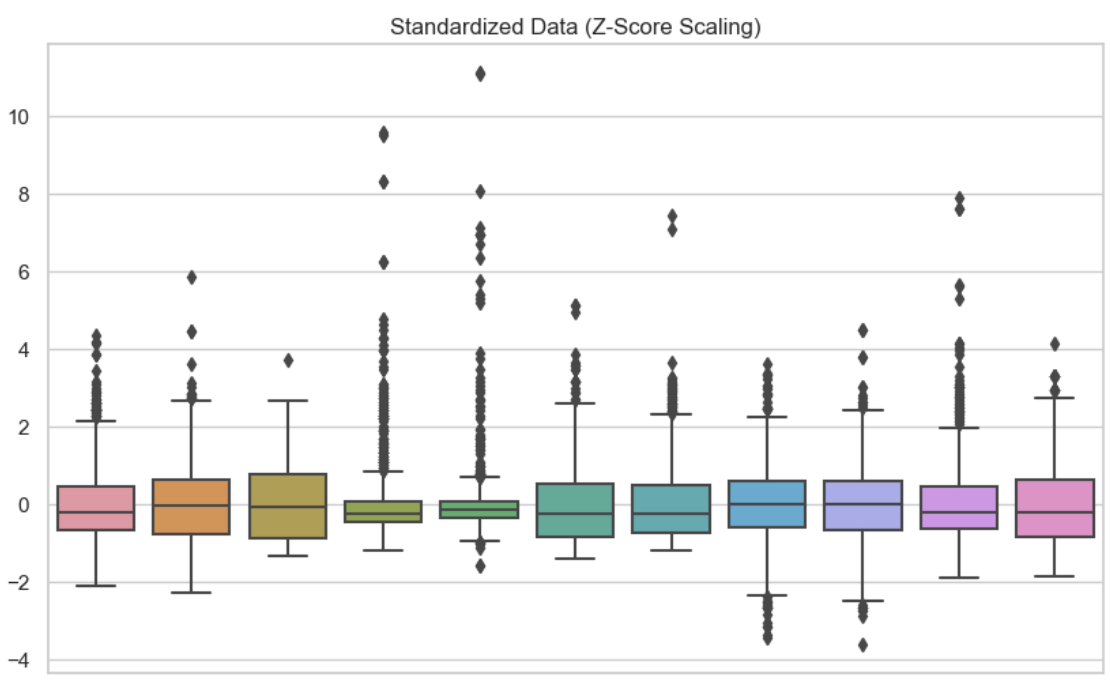 Dados padronizados. Imagem do autor
Dados padronizados. Imagem do autor
As vantagens incluem melhor desempenho do modelo e contribuições equilibradas de recursos. No entanto, a normalização pode limitar a interpretabilidade devido à escala fixa, enquanto a padronização também pode dificultar a interpretação, pois os valores não refletem mais suas unidades originais. Há sempre uma compensação entre a complexidade e a precisão do modelo.
Vamos considerar como a normalização (neste caso, a normalização da média) e a padronização podem alterar a interpretação de um modelo de regressão linear simples. O R-quadrado ou o R-quadrado ajustado seria o mesmo para cada modelo, portanto, a escala de recursos aqui se refere apenas à interpretação do nosso modelo.
| Transformação aplicada | Variável independente (tamanho da casa) | Variável dependente (preço da casa) | Interpretação |
|---|---|---|---|
| Normalização da média | Média normalizada | Original | Você está prevendo o preço original da casa para cada mudança no tamanho da casa em relação à média. |
| Padronização | Padronizado | Original | Você está prevendo o preço original da casa para cada mudança de um desvio padrão no tamanho da casa. |
| Normalização da média | Original | Média normalizada | Você está prevendo o preço da casa em relação à média para cada aumento de uma unidade no tamanho original da casa. |
| Padronização | Original | Padronizado | Você está prevendo o preço padronizado da casa para cada aumento de uma unidade no tamanho original da casa. |
| Normalização média (ambas as variáveis) | Média normalizada | Média normalizada | Você está prevendo o preço da casa em relação à média para cada mudança no tamanho da casa em relação à média. |
| Padronização (ambas as variáveis) | Padronizado | Padronizado | Você está prevendo o preço padronizado da casa para cada mudança de um desvio padrão no tamanho da casa. |
Outra observação importante é que, na regressão linear, se você padronizar as variáveis independentes e dependentes, o r-quadrado permanecerá o mesmo. Isso ocorre porque o r-quadrado mede a proporção da variação em y que é explicada por x, e essa proporção permanece a mesma, independentemente de as variáveis serem padronizadas ou não. No entanto, a padronização da variável dependente alterará o RMSE, pois o RMSE é medido nas mesmas unidades que a variável dependente. Como y agora está padronizado, o RMSE será menor após a padronização. Especificamente, ele refletirá o erro em termos do desvio padrão da variável padronizada, e não das unidades originais. Se a regressão for especialmente interessante para você, faça nosso curso Introduction to Regression with statsmodels in Python para se tornar um especialista.
O dimensionamento de recursos, que inclui normalização e padronização, é um componente essencial do pré-processamento de dados no aprendizado de máquina. Compreender os contextos apropriados para aplicar cada técnica pode melhorar significativamente o desempenho e a precisão de seus modelos.
Se você deseja expandir e aprofundar seu conhecimento sobre o dimensionamento de recursos e sua função no aprendizado de máquina, temos vários recursos excelentes no DataCamp que podem ajudá-lo a começar. Você pode explorar nosso artigo sobre normalização no aprendizado de máquina para conhecer os conceitos básicos ou considerar nosso curso de aprendizado de máquina de ponta a ponta, que abrange aplicativos reais.
Aprenda com a DataCamp
Curso
Curso
Curso
blog
Austin Chia
8 min
blog
Tim Lu
11 min
blog
Matt Crabtree
11 min
blog
Javier Canales Luna
14 min
blog
Matt Crabtree
10 min
blog
Arun Nanda
15 min

