Kursus
Menggabungkan Data dengan Pandas untuk Pengguna Spreadsheet
4 Hr
4.5K
Sebelum membaca file CSV ke dalam pandas dataframe, sebaiknya Anda memiliki gambaran tentang isi data tersebut. Jadi, disarankan untuk menelusuri sekilas file tersebut sebelum mencoba memuatnya ke memori: ini akan memberi Anda wawasan tentang kolom mana yang diperlukan dan mana yang bisa diabaikan.
Sekarang, mari kita tulis sedikit kode untuk mengimpor file menggunakan read_csv(). Lalu, kita bisa membahas apa yang terjadi dan bagaimana kita bisa menyesuaikan keluaran yang kita terima saat membaca data ke memori.
# Tip: For faster performance on large files in pandas 2.0+, use the pyarrow engine
# airbnb_data = pd.read_csv("data/listings_austin.csv", engine="pyarrow")
import pandas as pd
# Read the CSV file
airbnb_data = pd.read_csv("data/listings_austin.csv")
# View the first 5 rows
airbnb_data.head()
Yang terjadi pada kode di atas adalah kita telah:
read_csv() untuk membaca data ke memori sebagai pandas dataframe.Tapi masih banyak lagi yang bisa dilakukan dengan fungsi read_csv().
Perilaku standar pandas adalah menambahkan indeks awal ke dataframe yang dikembalikan dari file CSV yang dimuat ke memori. Namun, Anda dapat secara eksplisit menentukan kolom mana yang akan dijadikan indeks pada fungsi read_csv() dengan menyetel parameter index_col.
Perhatikan bahwa nilai yang Anda tetapkan untuk index_col dapat diberikan sebagai nama string, indeks kolom, atau urutan nama string atau indeks kolom. Memberikan parameter berupa sebuah urutan akan menghasilkan multiIndex (pengelompokan data berdasarkan beberapa tingkat).
Mari kita baca lagi datanya dan tetapkan kolom id sebagai indeks.
# Menetapkan kolom id sebagai indeks
airbnb_data = pd.read_csv("data/listings_austin.csv", index_col="id")
# airbnb_data = pd.read_csv("data/listings_austin.csv", index_col=0)
# Pratinjau 5 baris pertama
airbnb_data.head()
Bagaimana jika Anda hanya ingin membaca kolom-kolom tertentu ke memori karena tidak semuanya penting? Ini adalah skenario umum di dunia nyata. Dengan menggunakan fungsi read_csv(), Anda dapat memilih hanya kolom yang Anda perlukan setelah memuat file, tetapi ini berarti Anda harus mengetahui kolom apa yang dibutuhkan sebelum memuat data jika ingin melakukan operasi ini dari dalam fungsi read_csv().
Jika Anda sudah mengetahui kolom yang dibutuhkan, Anda beruntung; Anda bisa menghemat waktu dan memori dengan memberikan objek mirip daftar ke parameter usecols dari fungsi read_csv().
# Mendefinisikan kolom yang akan dibaca
usecols = ["id", "name", "host_id", "neighbourhood", "room_type", "price", "minimum_nights"]
# Baca data dengan subset kolom
airbnb_data = pd.read_csv("data/listings_austin.csv", index_col="id", usecols=usecols)
# Pratinjau 5 baris pertama
airbnb_data.head()
Kita baru menyentuh permukaan dari berbagai cara untuk menyesuaikan keluaran fungsi read_csv(), tetapi membahas lebih dalam tentu akan berlebihan informasinya. Untuk itu, Anda dapat menggunakan tabel berikut sebagai referensi:
| Parameter | Deskripsi | Contoh penggunaan | |
|---|---|---|---|
| filepath_or_buffer | Path atau URL file CSV yang akan dibaca. | pd.read_csv("data/listings_austin.csv") | |
| sep | Pemisah yang digunakan. Default adalah ,. | pd.read_csv("data.csv", sep=';') | |
| index_col | Kolom yang dijadikan indeks. Dapat berupa label kolom atau bilangan bulat. | pd.read_csv("data.csv", index_col="id") | |
| usecols | Mengembalikan subset kolom. Menerima list-like dari nama atau indeks kolom. | pd.read_csv("data.csv", usecols=["id", "name", "price"]) | |
| names | Daftar nama kolom yang digunakan. Jika file tidak memiliki baris header. | pd.read_csv("data.csv", names=["A", "B", "C"]) | |
| header | Nomor baris yang digunakan sebagai nama kolom. Default adalah 0 (baris pertama). | pd.read_csv("data.csv", header=1) | |
| dtype | Tipe data untuk data atau kolom. | pd.read_csv("data.csv", dtype={"id": int, "price": float}) | |
| na_values | String tambahan yang dikenali sebagai NA/NaN. | pd.read_csv("data.csv", na_values=["NA", "N/A"]) | |
| parse_dates | Mencoba mengurai tanggal. Dapat berupa boolean atau daftar nama kolom. | pd.read_csv("data.csv", parse_dates=["date"]) | |
| engine | Mesin parser: 'c' (default), 'python', atau 'pyarrow' (tercepat, membutuhkan paket pyarrow). | pd.read_csv("data.csv", engine="pyarrow") | |
| skiprows | Nomor baris yang dilewati (0-indexed) atau jumlah baris yang dilewati di awal. | pd.read_csv("data.csv", skiprows=3) | |
| nrows | Jumlah baris yang dibaca. Berguna untuk meninjau file besar. | pd.read_csv("data.csv", nrows=100) |
Saat bekerja dengan dataset besar, memuat seluruh file ke memori sekaligus mungkin tidak memungkinkan, terutama di lingkungan dengan keterbatasan memori. Fungsi read_csv() menyediakan parameter chunksize yang praktis, memungkinkan Anda membaca data dalam potongan yang lebih kecil dan mudah dikelola.
Dengan menyetel parameter chunksize, read_csv() mengembalikan objek iterable di mana setiap iterasi menyediakan satu potongan data sebagai pandas dataframe. Pendekatan ini sangat berguna saat memproses data secara bertahap atau ketika ukuran dataset melebihi memori yang tersedia.
Berikut cara menggunakan parameter chunksize:
import pandas as pd
import os # Import the standard OS library
file_path = "data/large_dataset.csv"
output_file = "data/processed_large_dataset.csv"
chunk_size = 10000
# Process and write chunks
for chunk in pd.read_csv(file_path, chunksize=chunk_size):
# Example: Filter rows based on a condition
filtered_chunk = chunk[chunk['column_name'] > 50]
# Check if header is needed (only if file doesn't exist yet)
write_header = not os.path.exists(output_file)
# Append to a new CSV file
filtered_chunk.to_csv(output_file, mode='a', header=write_header, index=False)Jika tujuan Anda adalah melakukan operasi pada seluruh dataset, seperti menghitung total penjumlahan sebuah kolom, Anda dapat mengakumulasikan hasil saat mengiterasi setiap potongan:
total_sum = 0
for chunk in pd.read_csv(file_path, chunksize=chunk_size):
# Add the sum of the specific column for each chunk
total_sum += chunk['column_name'].sum()
print(f"Total sum of the column: {total_sum}")Anda juga dapat menggunakan chunksize untuk memproses dan menyimpan potongan data ke file baru secara bertahap:
# Output file path
output_file = "data/processed_large_dataset.csv"
# Process and write chunks
for chunk in pd.read_csv(file_path, chunksize=chunk_size):
# Example: Filter rows based on a condition
filtered_chunk = chunk[chunk['column_name'] > 50]
# Append to a new CSV file
filtered_chunk.to_csv(output_file, mode='a', header=not os.path.exists(output_file), index=False)Kita akan melihat lebih banyak tentang metode to_csv() di bagian selanjutnya.
Parameter chunksize sangat penting ketika:
Setelah Anda tahu cara membaca file CSV dari penyimpanan lokal ke memori, membaca data dari sumber lain menjadi mudah. Prosesnya pada dasarnya sama, hanya saja Anda tidak lagi memberikan path file.
Misalnya ada data dari halaman web tertentu yang Anda inginkan; bagaimana cara membacanya ke memori?
Saya akan menggunakan dataset Iris dari repositori UCI sebagai contoh:
# Webpage URL
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
# Define the column names
col_names = ["sepal_length_in_cm",
"sepal_width_in_cm",
"petal_length_in_cm",
"petal_width_in_cm",
"class"]
# Read data from URL
iris_data = pd.read_csv(url, names=col_names)
iris_data.head() 
Voila!
Kita menetapkan daftar string ke parameter names. Karena data mentah Iris tidak memiliki baris header, argumen ini memberi tahu pandas untuk menggunakan daftar kita sebagai nama kolom. (Catatan: Jika file tersebut memang memiliki baris header, Anda juga perlu menggunakan header=0 untuk memberi tahu pandas agar menggantinya).
Objek yang paling umum di pustaka pandas adalah objek dataframe. Ini adalah struktur data berlabel 2 dimensi yang terdiri atas baris dan kolom yang dapat memiliki tipe data berbeda (misalnya float, numerik, kategorikal, dll.).
Secara konseptual, Anda dapat menganggap pandas dataframe seperti spreadsheet, tabel SQL, atau kamus dari objek series – mana pun yang lebih Anda kenal. Hal menarik dari pandas dataframe adalah banyaknya metode yang memudahkan Anda mengenali data secepat mungkin.
Anda sudah melihat salah satu metodenya: iris_data.head(), yang menampilkan n baris pertama (default-nya 5). Metode “kebalikan” dari head() adalah tail(), yang menampilkan n baris terakhir (default 5) dari objek dataframe. Contohnya:
iris_data.tail()
Anda dapat dengan cepat melihat nama kolom menggunakan atribut columns pada objek dataframe Anda:
# Mengetahui nama kolom
iris_data.columns
"""
Index(['sepal_length_in_cm', 'sepal_width_in_cm', 'petal_length_in_cm',
'petal_width_in_cm', 'class'],
dtype='object')
"""Metode penting lainnya yang dapat Anda gunakan pada objek dataframe adalah info(). Metode ini mencetak ringkasan singkat dari dataframe, termasuk informasi tentang indeks, tipe data, kolom, nilai non-null, dan penggunaan memori.
# Mendapatkan ringkasan informasi dataframe
iris_data.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal_length_in_cm 150 non-null float64
1 sepal_width_in_cm 150 non-null float64
2 petal_length_in_cm 150 non-null float64
3 petal_width_in_cm 150 non-null float64
4 class 150 non-null object
dtypes: float64(4), object(1)
memory usage: 6.0+ KB
"""DataFrame.describe() menghasilkan statistik deskriptif, termasuk yang merangkum tendensi sentral, dispersi, dan bentuk distribusi dataset. Jika data Anda memiliki nilai hilang, jangan khawatir; nilai tersebut tidak disertakan dalam statistik deskriptif.
Mari panggil metode describe pada dataset Iris:
# Mendapatkan statistik deskriptif
iris_data.describe()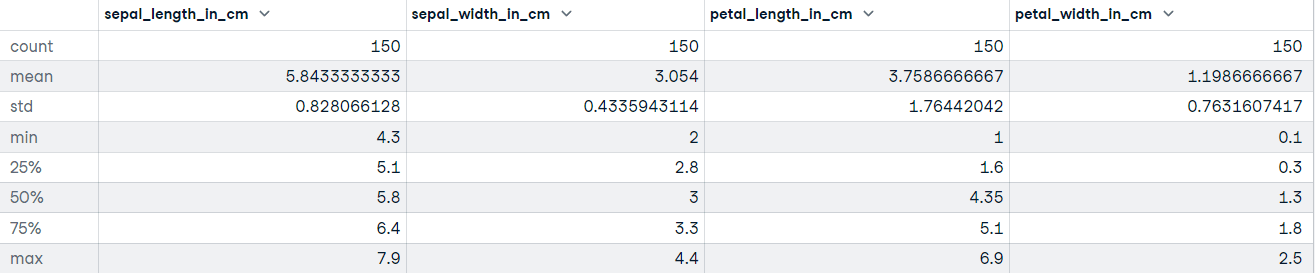
Metode lain yang tersedia pada objek pandas dataframe adalah to_csv(). Setelah Anda membersihkan dan memproses data, langkah berikutnya mungkin mengekspor dataframe ke file – ini cukup langsung:
# Ekspor file ke direktori kerja saat ini
iris_data.to_csv("cleaned_iris_data.csv")Menjalankan kode ini akan membuat file CSV di direktori kerja saat ini bernama cleaned_iris_data.csv.
Tetapi bagaimana jika Anda ingin menggunakan delimiter yang berbeda untuk menandai awal dan akhir satu unit data, atau ingin menentukan bagaimana nilai hilang direpresentasikan? Mungkin Anda tidak ingin header diekspor ke file.
Anda dapat menyesuaikan parameter metode to_csv() agar sesuai dengan kebutuhan data yang ingin Anda ekspor.
Mari lihat beberapa contoh bagaimana Anda dapat menyesuaikan keluaran to_csv():
# Ubah delimiter menjadi tab
iris_data.to_csv("tab_separated_iris_data.csv", sep="\t")# Ekspor data tanpa indeks
iris_data.to_csv("tab_separated_iris_data.csv", sep="\t", index=False)
# Jika Anda mendapat UnicodeEncodeError gunakan ini...
# iris_data.to_csv("tab_separated_iris_data.csv", sep="\t", index=False, encoding='utf-8')““):# Ganti nilai hilang dengan "Unknown"
iris_data.to_csv("tab_separated_iris_data.csv", sep="\t", na_rep="Unknown")# Jangan sertakan header saat mengekspor data
iris_data.to_csv("tab_separated_iris_data.csv", sep="\t", na_rep="Unknown", header=False)Terkadang, Anda mungkin menemui kesalahan encoding, terutama jika Anda bekerja pada sistem yang tidak menggunakan UTF-8 sebagai encoding default atau jika data Anda berisi karakter non-ASCII. Untuk mengatasinya, Anda dapat menentukan encoding yang sesuai menggunakan parameter encoding.
# Ekspor data dengan encoding tertentu
iris_data.to_csv("cleaned_iris_data.csv", encoding="utf-8")
Jika sistem Anda menggunakan encoding berbeda, seperti Windows-1252 (umum pada sistem Windows), Anda dapat menentukannya secara eksplisit:
# Ekspor data menggunakan encoding berbeda
iris_data.to_csv("cleaned_iris_data.csv", encoding="cp1252")
Contoh dengan parameter tambahan:
# Tangani nilai hilang dan masalah encoding
iris_data.to_csv("cleaned_iris_data.csv", na_rep="Unknown", encoding="utf-8", index=False)Contoh di atas memastikan file CSV yang Anda ekspor kompatibel dengan berbagai sistem dan aplikasi.
| Parameter | Deskripsi | Contoh penggunaan |
|---|---|---|
| path_or_buf | Path atau objek file, jika None diberikan, hasil dikembalikan sebagai string. | df.to_csv("output.csv") |
| sep | String sepanjang 1. Pemisah kolom untuk file keluaran. Default adalah ','. | df.to_csv("output.csv", sep=';') |
| na_rep | Representasi untuk data hilang. | df.to_csv("output.csv", na_rep='Unknown') |
| float_format | String format untuk bilangan pecahan. | df.to_csv("output.csv", float_format='%.2f') |
| columns | Kolom yang akan ditulis. Secara default, menulis semua kolom. | df.to_csv("output.csv", columns=["id", "name"]) |
| header | Menulis nama kolom. Jika diberikan daftar string, dianggap sebagai alias untuk nama kolom. | df.to_csv("output.csv", header=False) |
| index | Menulis nama baris (indeks). Default adalah True. | df.to_csv("output.csv", index=False) |
| mode | Mode tulis Python. Default adalah 'w'. | df.to_csv("output.csv", mode='a') |
| encoding | String yang merepresentasikan encoding yang digunakan pada file keluaran. | df.to_csv("output.csv", encoding='utf-8') |
Walaupun pandas adalah pustaka yang kuat dan serbaguna untuk bekerja dengan file CSV, ini bukan satu-satunya opsi di Python. Bergantung pada kasus penggunaan Anda, pustaka lain mungkin lebih cocok untuk tugas tertentu:
Modul csv adalah bagian dari pustaka standar Python dan merupakan alternatif ringan untuk menangani file CSV. Modul ini menyediakan fungsionalitas dasar untuk membaca dan menulis file CSV tanpa memerlukan instalasi tambahan. Keunggulan csv adalah:
Contoh:
import csv
# Reading a CSV file
with open("data/sample.csv", mode="r") as file:
reader = csv.reader(file)
for row in reader:
print(row)
# Writing to a CSV file
with open("data/output.csv", mode="w", newline="") as file:
writer = csv.writer(file)
writer.writerow(["Column1", "Column2"])
writer.writerow(["Value1", "Value2"])NumPy adalah pustaka komputasi numerik di Python yang juga mendukung pengelolaan CSV. Sangat berguna saat bekerja dengan data numerik atau ketika kinerja menjadi perhatian. Keunggulannya antara lain:
Contoh:
import numpy as np
# Reading a CSV file into a NumPy array
data = np.loadtxt("data/sample.csv", delimiter=",", skiprows=1)
# Writing a NumPy array to a CSV file
np.savetxt("data/output.csv", data, delimiter=",")Walaupun NumPy efisien, ia tidak menyediakan fitur manipulasi data dan eksplorasi yang kaya seperti yang tersedia di pandas.
Jika Anda bekerja dengan dataset yang sangat besar di mana pandas terasa lambat atau kehabisan memori, Polars adalah penerus modern yang patut Anda kenal. Ini adalah pustaka DataFrame yang ditulis dalam Rust dan dirancang untuk performa sangat cepat dan pemrosesan paralel.
Seperti yang kami jelaskan dalam tutorial Polars, keunggulan Polars adalah:
Contoh: Sintaksnya sering kali mirip dengan pandas, sehingga mudah dipelajari:
import polars as pl
# Read a CSV file (automatically uses multiple threads)
df = pl.read_csv("data/large_dataset.csv")
# View the first 5 rows
print(df.head())
# Write to a CSV file
df.write_csv("data/polars_output.csv")Mari kita rekap apa yang telah dibahas dalam tutorial ini; Anda telah belajar cara:
read_csv() dari pustaka pandas.read_csv().pandas.read_csv()to_csv().Dalam tutorial ini, saya hanya berfokus pada impor dan ekspor data dari sudut pandang file CSV; sekarang Anda memiliki gambaran yang baik tentang betapa bergunanya pandas saat mengimpor dan mengekspor file CSV. CSV adalah salah satu format penyimpanan data yang paling umum, tetapi bukan satu-satunya. Ada berbagai format file lain yang digunakan dalam data science, seperti parquet, JSON, dan Excel.
Banyak dataset berkualitas tinggi yang berguna dihosting di web, yang dapat Anda akses melalui API, misalnya. Jika Anda ingin memahami cara memuat data ke Python secara lebih mendetail, kursus DataCamp Introduction to Importing Data in Python akan mengajarkan semua praktik terbaiknya.
Ada juga tutorial tentang cara mengimpor data JSON dan HTML ke pandas dan panduan pamungkas pandas untuk pemula. Pastikan untuk memeriksanya untuk menyelami lebih dalam kerangka kerja pandas.
Pelajari lebih lanjut tentang Python dan pandas
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
