Curso
Junções no pandas para usuários de planilhas
4 h
4.5K
Antes de ler um arquivo CSV em um dataframe do pandas, você deve ter alguma noção do que os dados contêm. Portanto, é recomendável que você examine o arquivo antes de tentar carregá-lo na memória: isso lhe dará mais informações sobre quais colunas são necessárias e quais podem ser descartadas.
Vamos escrever um código para importar um arquivo usando read_csv(). Em seguida, podemos falar sobre o que está acontecendo e como podemos personalizar a saída que recebemos ao ler os dados na memória.
import pandas as pd
# Read the CSV file
airbnb_data = pd.read_csv("data/listings_austin.csv")
# View the first 5 rows
airbnb_data.head()
Tudo o que foi feito no código acima é que temos:
read_csv para ler os dados na memória como um dataframe do pandas.Mas a função read_csv() é muito mais do que isso.
O comportamento padrão do pandas é adicionar um índice inicial ao dataframe retornado do arquivo CSV que foi carregado na memória. No entanto, você pode especificar explicitamente qual coluna deve ser usada como índice para a função read_csv definindo o parâmetro index_col.
Observe que o valor que você atribui a index_col pode ser fornecido como um nome de cadeia de caracteres, índice de coluna ou uma sequência de nomes de cadeia de caracteres ou índices de coluna. A atribuição de uma sequência ao parâmetro resultará em um multiIndex (um agrupamento de dados em vários níveis).
Vamos ler os dados novamente e definir a coluna id como o índice.
# Setting the id column as the index
airbnb_data = pd.read_csv("data/listings_austin.csv", index_col="id")
# airbnb_data = pd.read_csv("data/listings_austing.csv", index_col=0)
# Preview first 5 rows
airbnb_data.head()
E se você quiser ler apenas colunas específicas na memória porque nem todas são importantes? Esse é um cenário comum que ocorre no mundo real. Usando a função read_csv, você pode selecionar somente as colunas necessárias depois de carregar o arquivo, mas isso significa que você deve saber de quais colunas precisa antes de carregar os dados se quiser executar essa operação na função read_csv.
Se você conhece as colunas de que precisa, está com sorte; você pode economizar tempo e memória passando um objeto do tipo lista para o parâmetro usecols da função read_csv.
# Defining the columns to read
usecols = ["id", "name", "host_id", "neighbourhood", "room_type", "price", "minimum_nights"]
# Read data with subset of columns
airbnb_data = pd.read_csv("data/listings_austin.csv", index_col="id", usecols=usecols)
# Preview first 5 rows
airbnb_data.head()
Mal arranhamos a superfície das diferentes maneiras de personalizar a saída da função read_csv, mas aprofundar o assunto certamente seria uma sobrecarga de informações.
Recomendamos que você marque a folha de dicas de importação de dados em Python e consulte Introdução à importação de dados em Python para saber mais. Se isso for fácil demais, há também o curso interativo intermediário de importação de dados em Python.
Quando você souber como ler um arquivo CSV do armazenamento local para a memória, será muito fácil ler dados de outras fontes. Em última análise, é o mesmo processo, exceto que você não está mais passando um caminho de arquivo.
Digamos que haja dados que você queira de uma página da Web específica; como você os leria na memória?
Usaremos o conjunto de dados Iris do repositório da UCI como exemplo:
# Webpage URL
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
# Define the column names
col_names = ["sepal_length_in_cm",
"sepal_width_in_cm",
"petal_length_in_cm",
"petal_width_in_cm",
"class"]
# Read data from URL
iris_data = pd.read_csv(url, names=col_names)
iris_data.head() 
Voila!
Você deve ter notado que atribuímos uma lista de cadeias de caracteres ao parâmetro names na função read_csv. Isso serve apenas para que você possa renomear os cabeçalhos das colunas enquanto lê os dados na memória.
O objeto mais comum na biblioteca pandas é, de longe, o objeto dataframe. É uma estrutura de dados rotulada bidimensional que consiste em linhas e colunas que podem ser de diferentes tipos de dados (ou seja, flutuantes, numéricos, categóricos etc.).
Conceitualmente, você pode pensar em um dataframe do pandas como uma planilha, uma tabela SQL ou um dicionário de objetos de série - o que for mais familiar para você. O legal do dataframe do pandas é que ele vem com muitos métodos que facilitam que você se familiarize com seus dados o mais rápido possível.
Você já viu um desses métodos: iris_data.head() Você já viu um desses métodos: o método "n", que mostra as primeiras n (o padrão é 5) linhas. O método "oposto" de head() é tail(), que mostra as últimas n (5 por padrão) linhas do objeto de dataframe. Por exemplo:
iris_data.tail()
Você pode descobrir rapidamente os nomes das colunas usando o atributo columns em seu objeto de dataframe:
# Discover the column names
iris_data.columns
"""
Index(['sepal_length_in_cm', 'sepal_width_in_cm', 'petal_length_in_cm',
'petal_width_in_cm', 'class'],
dtype='object')
"""Outro método importante que você pode usar em seu objeto de dataframe é info(). Esse método imprime um resumo conciso do dataframe, incluindo informações sobre o índice, tipos de dados, colunas, valores não nulos e uso de memória.
# Get summary information of the dataframe
iris_data.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal_length_in_cm 150 non-null float64
1 sepal_width_in_cm 150 non-null float64
2 petal_length_in_cm 150 non-null float64
3 petal_width_in_cm 150 non-null float64
4 class 150 non-null object
dtypes: float64(4), object(1)
memory usage: 6.0+ KB
"""DataFrame.describe() gera estatísticas descritivas, incluindo aquelas que resumem a tendência central, a dispersão e a forma da distribuição do conjunto de dados. Se os seus dados tiverem valores ausentes, não se preocupe; eles não serão incluídos nas estatísticas descritivas.
Vamos chamar o método describe no conjunto de dados Iris:
# Get descriptive statistics
iris_data.describe()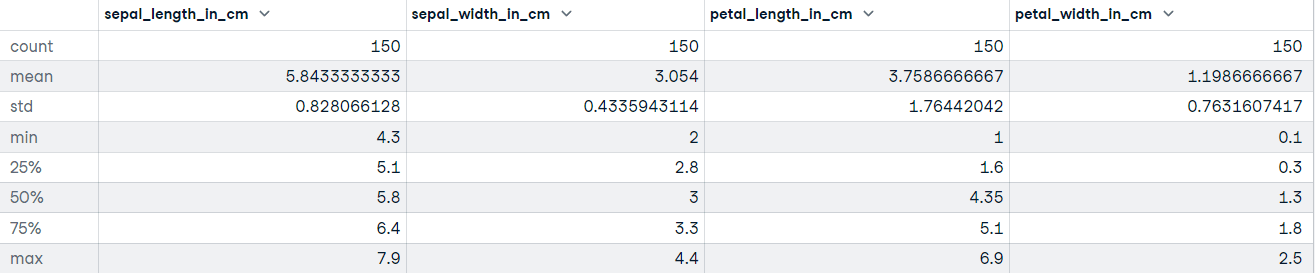
Outro método disponível para os objetos de dataframe do pandas é to_csv(). Quando você tiver limpado e pré-processado os dados, a próxima etapa poderá ser exportar o dataframe para um arquivo - isso é bastante simples:
# Export the file to the current working directory
iris_data.to_csv("cleaned_iris_data.csv")Ao executar esse código, você criará um CSV no diretório de trabalho atual chamado cleaned_iris_data.csv.
Mas e se você quiser usar um delimitador diferente para marcar o início e o fim de uma unidade de dados ou se quiser especificar como os valores ausentes devem ser representados? Talvez você não queira que os cabeçalhos sejam exportados para o arquivo.
Bem, você pode ajustar os parâmetros do método to_csv() para atender aos requisitos dos dados que deseja exportar.
Vamos dar uma olhada em alguns exemplos de como você pode ajustar a saída do to_csv():
# Change the delimiter to a tab
iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t")# Export data without the index
iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t")
# If you get UnicodeEncodeError use this...
# iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t", index=False, encoding='utf-8')# Replace missing values with "Unknown"
iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t", na_rep="Unknown")# Do not include headers when exporting the data
iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t", na_rep="Unknown", header=False)Vamos recapitular o que abordamos neste tutorial: você aprendeu como fazer:
read_csv() da biblioteca pandas.read_csv() retorne.pandas.read_csv()to_csv().Neste tutorial, nos concentramos apenas na importação e exportação de dados a partir da perspectiva de um arquivo CSV; agora você tem uma boa noção da utilidade do pandas ao importar e exportar arquivos CSV. O CSV é um dos formatos mais comuns de armazenamento de dados, mas não é o único. Há vários outros formatos de arquivo usados na ciência de dados, como parquet, JSON e Excel.
Muitos conjuntos de dados úteis e de alta qualidade estão hospedados na Web, que você pode acessar por meio de APIs, por exemplo. Se você quiser entender como lidar com o carregamento de dados em Python com mais detalhes, o curso Introdução à importação de dados em Python do DataCamp ensinará a você todas as práticas recomendadas.
Há também tutoriais sobre como importar dados JSON e HTML para o pandas e um guia definitivo para iniciantes sobre o pandas. Não deixe de dar uma olhada neles para se aprofundar na estrutura do pandas.
Saiba mais sobre Python e pandas
Curso
Curso
Curso
blog
Moez Ali
9 min
Tutorial
Karlijn Willems
Tutorial
Natassha Selvaraj
Tutorial
Vidhi Chugh
Tutorial
DataCamp Team
Tutorial
DataCamp Team

