Kurs
Elektronik Tablo Kullanıcıları için pandas Join'leri
4 sa
4.5K
Bir pandas dataframe’ine CSV dosyası okumadan önce, verinin ne içerdiğine dair bir fikir sahibi olmalısınız. Bu nedenle, veriyi belleğe yüklemeye çalışmadan önce dosyayı gözden geçirmeniz önerilir: Bu, hangi sütunların gerekli olduğu ve hangilerinin elenebileceği hakkında size daha fazla fikir verecektir.
Şimdi, read_csv() kullanarak bir dosyayı içe aktarmak için biraz kod yazalım. Ardından, neler olup bittiğini ve veriyi belleğe okurken aldığımız çıktıyı nasıl özelleştirebileceğimizi konuşabiliriz.
# Tip: pandas 2.0+ sürümlerinde büyük dosyalarda daha hızlı performans için pyarrow motorunu kullanın
# airbnb_data = pd.read_csv("data/listings_austin.csv", engine="pyarrow")
import pandas as pd
# CSV dosyasını oku
airbnb_data = pd.read_csv("data/listings_austin.csv")
# İlk 5 satırı görüntüle
airbnb_data.head()
Yukarıdaki kodda olanlar şunlardır:
read_csv()’e vererek veriyi belleğe bir pandas dataframe’i olarak okuttuk.Ancak read_csv() işlevinde bundan çok daha fazlası var.
pandas’ın varsayılan davranışı, belleğe yüklenen CSV dosyasından dönen dataframe’e başlangıçta bir indeks eklemektir. Ancak, index_col parametresini ayarlayarak read_csv() işlevine hangi sütunun indeks yapılacağını açıkça belirtebilirsiniz.
index_col’a atadığınız değerin bir dize adı, sütun indeksi veya dize adları ya da sütun indekslerinden oluşan bir dizi olabileceğini unutmayın. Parametreye bir dizi atamak, çok düzeyli bir gruplamayı (multiIndex) sonuç verecektir.
Veriyi yeniden okuyalım ve id sütununu indeks olarak ayarlayalım.
# id sütununu indeks olarak ayarlama
airbnb_data = pd.read_csv("data/listings_austin.csv", index_col="id")
# airbnb_data = pd.read_csv("data/listings_austin.csv", index_col=0)
# İlk 5 satıra göz atın
airbnb_data.head()
Ya sadece belirli sütunları belleğe okumak istiyorsanız çünkü hepsi önemli değil? Bu, gerçek dünyada sıkça karşılaşılan bir senaryodur. read_csv() işlevini kullanarak, dosyayı yükledikten sonra yalnızca ihtiyaç duyduğunuz sütunları seçebilirsiniz, ancak bu işlemi read_csv() işlevinin içinde yapmak istiyorsanız, veriyi yüklemeden önce hangi sütunlara ihtiyaç duyduğunuzu bilmeniz gerekir.
Eğer hangi sütunlara ihtiyacınız olduğunu biliyorsanız şanslısınız; read_csv() işlevinin usecols parametresine liste benzeri bir nesne geçirerek zamandan ve bellekten tasarruf edebilirsiniz.
# Okunacak sütunları tanımlama
usecols = ["id", "name", "host_id", "neighbourhood", "room_type", "price", "minimum_nights"]
# Sütunların bir alt kümesiyle veriyi oku
airbnb_data = pd.read_csv("data/listings_austin.csv", index_col="id", usecols=usecols)
# İlk 5 satıra göz atın
airbnb_data.head()
read_csv() işlevinin çıktısını özelleştirmenin farklı yollarına yalnızca yüzeysel olarak değindik, ancak daha derine inmek muhtemelen bilgi yüklemesi olurdu. Bunun için aşağıdaki tabloyu referans olarak kullanabilirsiniz:
| Parameter | Description | Example usage | |
|---|---|---|---|
| filepath_or_buffer | Okunacak CSV dosyasının yolu veya URL’si. | pd.read_csv("data/listings_austin.csv") | |
| sep | Kullanılacak ayraç. Varsayılan ,’dir. | pd.read_csv("data.csv", sep=';') | |
| index_col | İndeks olarak ayarlanacak sütun(lar). Bir sütun etiketi veya tamsayı olabilir. | pd.read_csv("data.csv", index_col="id") | |
| usecols | Sütunların bir alt kümesini döndür. Sütun adları veya indekslerinden oluşan liste benzeri bir yapı alır. | pd.read_csv("data.csv", usecols=["id", "name", "price"]) | |
| names | Kullanılacak sütun adlarının listesi. Dosyada bir başlık satırı yoksa kullanılır. | pd.read_csv("data.csv", names=["A", "B", "C"]) | |
| header | Sütun adları olarak kullanılacak satır numarası/numaraları. Varsayılan 0’dır (ilk satır). | pd.read_csv("data.csv", header=1) | |
| dtype | Veri veya sütunlar için veri türü. | pd.read_csv("data.csv", dtype={"id": int, "price": float}) | |
| na_values | NA/NaN olarak tanınacak ek dizeler. | pd.read_csv("data.csv", na_values=["NA", "N/A"]) | |
| parse_dates | Tarihleri ayrıştırmayı dener. Boolean ya da sütun adlarının listesi olabilir. | pd.read_csv("data.csv", parse_dates=["date"]) | |
| engine | Ayrıştırıcı motoru: 'c' (varsayılan), 'python' veya 'pyarrow' (en hızlısı, pyarrow paketi gerekir). | pd.read_csv("data.csv", engine="pyarrow") | |
| skiprows | Atlanacak satır numaraları (0-indeksli) veya başta atlanacak satır sayısı. | pd.read_csv("data.csv", skiprows=3) | |
| nrows | Okunacak satır sayısı. Büyük dosyaları önizlemek için kullanışlıdır. | pd.read_csv("data.csv", nrows=100) |
Büyük veri kümeleriyle çalışırken, tüm dosyayı bir kerede belleğe yüklemek, özellikle bellek kısıtlı ortamlarda mümkün olmayabilir. read_csv() işlevi, veriyi daha küçük ve yönetilebilir parçalar halinde okumanıza olanak tanıyan kullanışlı bir chunksize parametresi sunar.
chunksize parametresini ayarladığınızda, read_csv() her yinelemede bir veri parçasını bir pandas dataframe’i olarak sağlayan yinelenebilir bir nesne döndürür. Bu yaklaşım, veriyi partiler hâlinde işlerken veya veri kümesi boyutu mevcut belleği aştığında özellikle kullanışlıdır.
chunksize parametresini şu şekilde kullanabilirsiniz:
import pandas as pd
import os # Standart OS kütüphanesini içe aktarın
file_path = "data/large_dataset.csv"
output_file = "data/processed_large_dataset.csv"
chunk_size = 10000
# Parçaları işle ve yaz
for chunk in pd.read_csv(file_path, chunksize=chunk_size):
# Örnek: Bir koşula göre satırları filtrele
filtered_chunk = chunk[chunk['column_name'] > 50]
# Başlık gerekli mi kontrol et (yalnızca dosya henüz yoksa)
write_header = not os.path.exists(output_file)
# Yeni bir CSV dosyasına ekle
filtered_chunk.to_csv(output_file, mode='a', header=write_header, index=False)Amacınız tüm veri kümesi üzerinde bir işlem gerçekleştirmekse, örneğin bir sütunun toplamını hesaplamak gibi, parçalarda yineleme yaparken sonuçları birleştirebilirsiniz:
total_sum = 0
for chunk in pd.read_csv(file_path, chunksize=chunk_size):
# Her parça için belirli sütunun toplamını ekle
total_sum += chunk['column_name'].sum()
print(f"Total sum of the column: {total_sum}")Ayrıca chunksize kullanarak veri parçalarını artımlı olarak işleyip yeni bir dosyaya kaydedebilirsiniz:
# Çıktı dosyası yolu
output_file = "data/processed_large_dataset.csv"
# Parçaları işle ve yaz
for chunk in pd.read_csv(file_path, chunksize=chunk_size):
# Örnek: Bir koşula göre satırları filtrele
filtered_chunk = chunk[chunk['column_name'] > 50]
# Yeni bir CSV dosyasına ekle
filtered_chunk.to_csv(output_file, mode='a', header=not os.path.exists(output_file), index=False)to_csv() yöntemini ilerleyen bölümlerde daha çok göreceğiz.
chunksize parametresi vazgeçilmezdir:
Bir CSV dosyasını yerel depolamadan belleğe nasıl okuyacağınızı bildikten sonra, diğer kaynaklardan veri okumak çocuk oyuncağıdır. Sonuçta süreç aynıdır, yalnızca artık bir dosya yolu geçmiyorsunuz.
Diyelim ki belirli bir web sayfasında istediğiniz veri var; bunu belleğe nasıl okursunuz?
Örnek olarak UCI deposundaki Iris veri kümesini kullanacağım:
# Web sayfası URL’si
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
# Sütun adlarını tanımlayın
col_names = ["sepal_length_in_cm",
"sepal_width_in_cm",
"petal_length_in_cm",
"petal_width_in_cm",
"class"]
# URL'den veri oku
iris_data = pd.read_csv(url, names=col_names)
iris_data.head() 
İşte bu!
names parametresine bir dize listesini atadık. Ham Iris verisinde bir başlık satırı olmadığından, bu argüman pandas’a listemizi sütun adları olarak kullanmasını söyler. (Not: Dosyada bir başlık satırı olsaydı, pandas’ın onu değiştirmesi için header=0 kullanmanız da gerekirdi).
pandas kütüphanesindeki en yaygın nesne açık ara dataframe nesnesidir. Farklı veri türlerinden (ör. float, sayısal, kategorik vb.) oluşabilen satır ve sütunlardan oluşan 2 boyutlu etiketli bir veri yapısıdır.
Kavramsal olarak, bir pandas dataframe’ini bir elektronik tabloya, SQL tablosuna veya seriler sözlüğüne benzetebilirsiniz – hangisine daha aşinaysanız. pandas dataframe’inin güzel yanı, verinizi olabildiğince hızlı tanımanızı kolaylaştıran birçok yöntemle gelmesidir.
Bu yöntemlerden birini zaten gördünüz: Varsayılan olarak ilk n (5) satırı gösteren iris_data.head(). head()’in “zıttı” olan tail(), dataframe nesnesinin son n (varsayılan 5) satırını gösterir. Örneğin:
iris_data.tail()
Sütun adlarını hızlıca keşfetmek için dataframe nesnenizdeki columns özniteliğini kullanabilirsiniz:
# Sütun adlarını keşfedin
iris_data.columns
"""
Index(['sepal_length_in_cm', 'sepal_width_in_cm', 'petal_length_in_cm',
'petal_width_in_cm', 'class'],
dtype='object')
"""Dataframe nesnesi üzerinde kullanabileceğiniz bir diğer önemli yöntem info()’dur. Bu yöntem, indeks, veri türleri, sütunlar, null olmayan değerler ve bellek kullanımı hakkında kısa bir özet yazdırır.
# Dataframe’in özet bilgilerini alın
iris_data.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal_length_in_cm 150 non-null float64
1 sepal_width_in_cm 150 non-null float64
2 petal_length_in_cm 150 non-null float64
3 petal_width_in_cm 150 non-null float64
4 class 150 non-null object
dtypes: float64(4), object(1)
memory usage: 6.0+ KB
"""DataFrame.describe(), veri kümesinin dağılımının merkezi eğilimi, yayılımı ve şekline ilişkin özet istatistikleri üretir. Verinizde eksik değerler varsa endişelenmeyin; tanımlayıcı istatistiklere dahil edilmezler.
Hadi describe yöntemini Iris veri kümesi üzerinde çağıralım:
# Tanımlayıcı istatistikleri alın
iris_data.describe()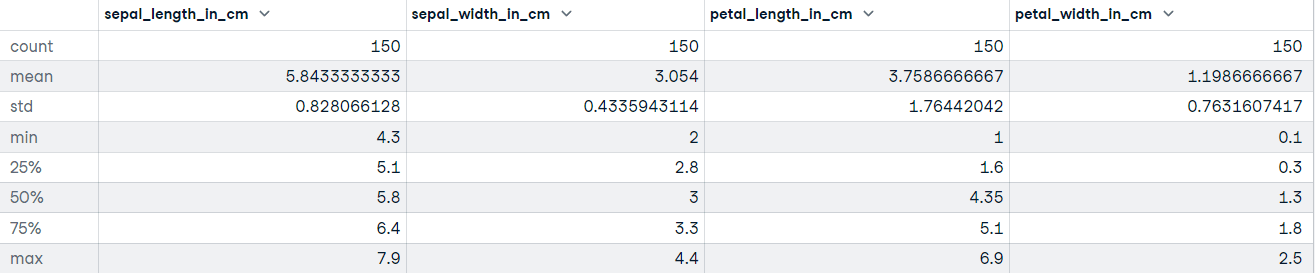
pandas dataframe nesnelerinde mevcut olan bir diğer yöntem to_csv()’dir. Verinizi temizleyip ön işleme tabi tuttuktan sonra, bir sonraki adım dataframe’i bir dosyaya aktarmak olabilir – bu oldukça basittir:
# Dosyayı mevcut çalışma dizinine aktarın
iris_data.to_csv("cleaned_iris_data.csv")Bu kodu çalıştırmak, mevcut çalışma dizininde cleaned_iris_data.csv adlı bir CSV oluşturacaktır.
Peki ya bir veri biriminin başlangıç ve bitişini işaretlemek için farklı bir ayraç kullanmak istiyorsanız veya eksik değerlerinizin nasıl temsil edileceğini belirtmek istiyorsanız? Belki de başlıkların dosyaya aktarılmasını istemiyorsunuz.
İyi haber, to_csv() yönteminin parametrelerini, aktarmak istediğiniz veri için gereksinimlerinize uyacak şekilde ayarlayabilirsiniz.
to_csv() çıktısını nasıl ayarlayabileceğinize ilişkin birkaç örneğe bakalım:
# Ayracı sekme olarak değiştirin
iris_data.to_csv("tab_separated_iris_data.csv", sep="\t")# Veriyi indeks olmadan aktarın
iris_data.to_csv("tab_separated_iris_data.csv", sep="\t", index=False)
# Eğer UnicodeEncodeError alırsanız şunu kullanın...
# iris_data.to_csv("tab_separated_iris_data.csv", sep="\t", index=False, encoding='utf-8')““’dır):# Eksik değerleri "Unknown" ile değiştirin
iris_data.to_csv("tab_separated_iris_data.csv", sep="\t", na_rep="Unknown")# Veriyi aktarırken başlıkları dahil etmeyin
iris_data.to_csv("tab_separated_iris_data.csv", sep="\t", na_rep="Unknown", header=False)Bazen, özellikle varsayılan olarak UTF-8 kullanmayan sistemlerde çalışıyorsanız veya veriniz ASCII dışı karakterler içeriyorsa, kodlama hatalarıyla karşılaşabilirsiniz. Bu sorunları çözmek için encoding parametresini kullanarak uygun bir kodlama belirtebilirsiniz.
# Belirli bir kodlama ile veriyi aktarın
iris_data.to_csv("cleaned_iris_data.csv", encoding="utf-8")
Sisteminiz Windows-1252 (Windows sistemlerinde yaygındır) gibi farklı bir kodlama kullanıyorsa, bunu açıkça belirtebilirsiniz:
# Farklı bir kodlama kullanarak veriyi aktarın
iris_data.to_csv("cleaned_iris_data.csv", encoding="cp1252")
Ek parametrelerle örnek:
# Eksik değerleri ve kodlama sorunlarını yönetin
iris_data.to_csv("cleaned_iris_data.csv", na_rep="Unknown", encoding="utf-8", index=False)Yukarıdaki örnek, dışa aktarılan CSV dosyanızın çeşitli sistem ve uygulamalarla uyumlu olmasını sağlar.
| Parameter | Description | Example usage |
|---|---|---|
| path_or_buf | Dosya yolu veya nesne, None verilirse sonuç bir dize olarak döndürülür. | df.to_csv("output.csv") |
| sep | Tek karakterlik dize. Çıktı dosyası için alan ayırıcı. Varsayılan ','. | df.to_csv("output.csv", sep=';') |
| na_rep | Eksik verilerin temsili. | df.to_csv("output.csv", na_rep='Unknown') |
| float_format | Ondalık sayılar için biçim dizesi. | df.to_csv("output.csv", float_format='%.2f') |
| columns | Yazılacak sütunlar. Varsayılan olarak tüm sütunlar yazılır. | df.to_csv("output.csv", columns=["id", "name"]) |
| header | Sütun adlarını yaz. Bir dize listesi verilirse, sütun adları için takma adlar olduğu varsayılır. | df.to_csv("output.csv", header=False) |
| index | Satır adlarını (indeksi) yaz. Varsayılan True’dur. | df.to_csv("output.csv", index=False) |
| mode | Python yazma modu. Varsayılan 'w'. | df.to_csv("output.csv", mode='a') |
| encoding | Çıktı dosyasında kullanılacak kodlamayı temsil eden bir dize. | df.to_csv("output.csv", encoding='utf-8') |
pandas, CSV dosyalarıyla çalışmak için güçlü ve çok yönlü bir kütüphane olsa da, Python’da tek seçenek değildir. Kullanım durumunuza bağlı olarak, belirli görevler için başka kütüphaneler daha uygun olabilir:
csv modülü Python’un standart kütüphanesinin bir parçasıdır ve CSV dosyalarını işlemek için hafif bir alternatiftir. Ek kurulum gerektirmeden CSV dosyalarını okumak ve yazmak için temel işlevler sağlar. csv’nin avantajları:
Örnek:
import csv
# Bir CSV dosyası okuma
with open("data/sample.csv", mode="r") as file:
reader = csv.reader(file)
for row in reader:
print(row)
# Bir CSV dosyasına yazma
with open("data/output.csv", mode="w", newline="") as file:
writer = csv.writer(file)
writer.writerow(["Column1", "Column2"])
writer.writerow(["Value1", "Value2"])NumPy, CSV işlemeyi de destekleyen bir sayısal hesaplama kütüphanesidir. Özellikle sayısal verilerle çalışırken veya performansın kritik olduğu durumlarda faydalıdır. Avantajları:
Örnek:
import numpy as np
# Bir CSV dosyasını NumPy dizisine okuma
data = np.loadtxt("data/sample.csv", delimiter=",", skiprows=1)
# Bir NumPy dizisini CSV dosyasına yazma
np.savetxt("data/output.csv", data, delimiter=",")NumPy verimlidir, ancak pandas’ın sunduğu zengin veri manipülasyonu ve keşif özelliklerini sağlamaz.
Eğer pandas’ın yavaş kaldığı veya belleğinizin tükendiği çok büyük veri kümeleriyle çalışıyorsanız, Polars bilmeniz gereken modern halefidir. Rust ile yazılmış olup, son derece hızlı performans ve paralel işlemeye yönelik tasarlanmış bir DataFrame kütüphanesidir.
Polars eğitimimizde incelediğimiz üzere, Polars’ın avantajları şunlardır:
Örnek: Söz dizimi çoğu zaman pandas’a oldukça benzerdir, bu da öğrenmeyi kolaylaştırır:
import polars as pl
# Bir CSV dosyasını oku (otomatik olarak birden çok iş parçacığı kullanır)
df = pl.read_csv("data/large_dataset.csv")
# İlk 5 satırı görüntüleyin
print(df.head())
# Bir CSV dosyasına yazın
df.write_csv("data/polars_output.csv")Bu eğitimde neler öğrendiğimizi özetleyelim; şunları öğrendiniz:
read_csv() işlevini kullanarak bir CSV dosyasını içe aktarmak.read_csv() işlevinin döndürmesini istediğiniz sütunları belirtmek.pandas.read_csv() ile bir URL’den veri okumak.to_csv() yönteminden çıkan dosyanın çıktısını özelleştirmek.Bu eğitimde yalnızca bir CSV dosyası perspektifinden veriyi içe ve dışa aktarmaya odaklandım; artık pandas’ın CSV dosyalarını içe ve dışa aktarırken ne kadar kullanışlı olduğuna dair iyi bir fikir edindiniz. CSV en yaygın veri depolama biçimlerinden biridir, ancak tek seçenek değildir. Veri biliminde parquet, JSON ve Excel gibi çeşitli başka dosya biçimleri de kullanılır.
Web’de API’ler aracılığıyla erişebileceğiniz çok sayıda faydalı, yüksek kaliteli veri kümesi barındırılmaktadır. Veriyi Python’a yüklemeyi daha ayrıntılı anlamak istiyorsanız, DataCamp’in Introduction to Importing Data in Python kursu size en iyi uygulamaların tamamını öğretecektir.
Ayrıca, JSON ve HTML verilerini pandas’a nasıl içe aktaracağınıza ve başlangıç seviyesine uygun kapsamlı bir pandas rehberine dair eğitimler de mevcut. pandas ekosistemine daha derinlemesine dalmak için mutlaka göz atın.
Python ve pandas hakkında daha fazla bilgi edinin
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
