Corso
Join con pandas per chi usa i fogli di calcolo
4 h
4.5K
Prima di leggere un file CSV in un dataframe di pandas, è utile dare un’occhiata al contenuto dei dati. Per questo, è consigliabile scorrere velocemente il file prima di provare a caricarlo in memoria: ti darà un’idea più chiara di quali colonne servono e quali si possono scartare.
Ora, scriviamo un po’ di codice per importare un file usando read_csv(). Poi vedremo cosa succede e come possiamo personalizzare l’output che riceviamo durante la lettura dei dati in memoria.
# Tip: For faster performance on large files in pandas 2.0+, use the pyarrow engine
# airbnb_data = pd.read_csv("data/listings_austin.csv", engine="pyarrow")
import pandas as pd
# Read the CSV file
airbnb_data = pd.read_csv("data/listings_austin.csv")
# View the first 5 rows
airbnb_data.head()
Nel codice sopra abbiamo semplicemente:
read_csv() per leggere i dati in memoria come dataframe di pandas.Ma c’è molto di più nella funzione read_csv().
Il comportamento predefinito di pandas è aggiungere un indice iniziale al dataframe restituito dal file CSV caricato in memoria. Tuttavia, puoi specificare esplicitamente quale colonna usare come indice nella funzione read_csv() impostando il parametro index_col.
Nota che il valore assegnato a index_col può essere un nome di colonna (stringa), un indice di colonna oppure una sequenza di nomi o indici di colonna. Assegnare una sequenza al parametro produrrà un multiIndex (un raggruppamento dei dati su più livelli).
Rileggiamo i dati impostando la colonna id come indice.
# Impostare la colonna id come indice
airbnb_data = pd.read_csv("data/listings_austin.csv", index_col="id")
# airbnb_data = pd.read_csv("data/listings_austin.csv", index_col=0)
# Anteprima delle prime 5 righe
airbnb_data.head()
E se volessi leggere in memoria solo alcune colonne perché non tutte sono importanti? È uno scenario molto comune nel mondo reale. Usando la funzione read_csv(), puoi selezionare solo le colonne necessarie dopo aver caricato il file, ma questo significa che devi sapere quali colonne ti servono prima di caricare i dati se vuoi eseguire questa operazione direttamente con read_csv().
Se sai già quali colonne ti servono, sei fortunato: puoi risparmiare tempo e memoria passando un oggetto di tipo lista al parametro usecols della funzione read_csv().
# Definizione delle colonne da leggere
usecols = ["id", "name", "host_id", "neighbourhood", "room_type", "price", "minimum_nights"]
# Lettura dei dati con un sottoinsieme di colonne
airbnb_data = pd.read_csv("data/listings_austin.csv", index_col="id", usecols=usecols)
# Anteprima delle prime 5 righe
airbnb_data.head()
Abbiamo appena scalfito la superficie dei modi in cui personalizzare l’output della funzione read_csv(), ma entrare più a fondo sarebbe un sovraccarico di informazioni. Per questo, puoi usare come riferimento la tabella seguente:
| Parametro | Descrizione | Esempio d'uso | |
|---|---|---|---|
| filepath_or_buffer | Percorso o URL del file CSV da leggere. | pd.read_csv("data/listings_austin.csv") | |
| sep | Delimitatore da usare. Predefinito: ,. | pd.read_csv("data.csv", sep=';') | |
| index_col | Colonna/e da impostare come indice. Può essere un’etichetta o un intero. | pd.read_csv("data.csv", index_col="id") | |
| usecols | Restituisce un sottoinsieme di colonne. Accetta una lista di nomi o indici di colonna. | pd.read_csv("data.csv", usecols=["id", "name", "price"]) | |
| names | Elenco di nomi di colonna da usare. Se il file non contiene una riga di intestazione. | pd.read_csv("data.csv", names=["A", "B", "C"]) | |
| header | Numero/i di riga da usare come nomi di colonna. Predefinito: 0 (prima riga). | pd.read_csv("data.csv", header=1) | |
| dtype | Tipo di dato per l’insieme o per singole colonne. | pd.read_csv("data.csv", dtype={"id": int, "price": float}) | |
| na_values | Stringhe aggiuntive da riconoscere come NA/NaN. | pd.read_csv("data.csv", na_values=["NA", "N/A"]) | |
| parse_dates | Tenta di effettuare il parsing delle date. Può essere booleano o lista di nomi di colonna. | pd.read_csv("data.csv", parse_dates=["date"]) | |
| engine | Motore di parsing: 'c' (predefinito), 'python' o 'pyarrow' (il più veloce, richiede il pacchetto pyarrow). | pd.read_csv("data.csv", engine="pyarrow") | |
| skiprows | Numeri di riga da saltare (indicizzati da 0) o numero di righe da saltare all’inizio. | pd.read_csv("data.csv", skiprows=3) | |
| nrows | Numero di righe da leggere. Utile per l’anteprima di file grandi. | pd.read_csv("data.csv", nrows=100) |
Quando lavori con dataset molto grandi, caricare l’intero file in memoria in una volta sola può non essere fattibile, soprattutto in ambienti con memoria limitata. La funzione read_csv() offre il parametro chunksize, che ti consente di leggere i dati in blocchi più piccoli e gestibili.
Impostando il parametro chunksize, read_csv() restituisce un oggetto iterabile in cui ogni iterazione fornisce un blocco di dati come dataframe di pandas. Questo approccio è particolarmente utile per processare i dati a lotti o quando la dimensione del dataset supera la memoria disponibile.
Ecco come usare il parametro chunksize:
import pandas as pd
import os # Import the standard OS library
file_path = "data/large_dataset.csv"
output_file = "data/processed_large_dataset.csv"
chunk_size = 10000
# Process and write chunks
for chunk in pd.read_csv(file_path, chunksize=chunk_size):
# Example: Filter rows based on a condition
filtered_chunk = chunk[chunk['column_name'] > 50]
# Check if header is needed (only if file doesn't exist yet)
write_header = not os.path.exists(output_file)
# Append to a new CSV file
filtered_chunk.to_csv(output_file, mode='a', header=write_header, index=False)Se il tuo obiettivo è eseguire un’operazione su tutto il dataset, ad esempio calcolare la somma totale di una colonna, puoi aggregare i risultati mentre iteri sui blocchi:
total_sum = 0
for chunk in pd.read_csv(file_path, chunksize=chunk_size):
# Add the sum of the specific column for each chunk
total_sum += chunk['column_name'].sum()
print(f"Total sum of the column: {total_sum}")Puoi anche usare chunksize per processare e salvare progressivamente i blocchi di dati in un nuovo file:
# Output file path
output_file = "data/processed_large_dataset.csv"
# Process and write chunks
for chunk in pd.read_csv(file_path, chunksize=chunk_size):
# Example: Filter rows based on a condition
filtered_chunk = chunk[chunk['column_name'] > 50]
# Append to a new CSV file
filtered_chunk.to_csv(output_file, mode='a', header=not os.path.exists(output_file), index=False)Vedremo meglio il metodo to_csv() nelle prossime sezioni.
Il parametro chunksize è indispensabile quando:
Una volta che sai leggere un file CSV dallo storage locale in memoria, leggere dati da altre fonti è un gioco da ragazzi. Il processo è lo stesso: semplicemente non passi più un percorso di file.
Mettiamo che ci siano dei dati su una data pagina web che vuoi acquisire; come li leggeresti in memoria?
Userò come esempio il dataset Iris dal repository UCI:
# Webpage URL
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
# Define the column names
col_names = ["sepal_length_in_cm",
"sepal_width_in_cm",
"petal_length_in_cm",
"petal_width_in_cm",
"class"]
# Read data from URL
iris_data = pd.read_csv(url, names=col_names)
iris_data.head() 
Voilà!
Abbiamo assegnato una lista di stringhe al parametro names. Poiché i dati grezzi di Iris non hanno una riga di intestazione, questo argomento dice a pandas di usare la nostra lista come nomi delle colonne. (Nota: se il file avesse una riga di intestazione, dovresti anche usare header=0 per dire a pandas di sostituirla).
L’oggetto più comune nella libreria pandas è, di gran lunga, il dataframe. È una struttura dati etichettata a 2 dimensioni composta da righe e colonne che possono avere tipi di dati diversi (ad es. float, numerico, categoriale, ecc.).
A livello concettuale, puoi pensare a un dataframe di pandas come a un foglio di calcolo, una tabella SQL o un dizionario di serie – a seconda di ciò che ti è più familiare. La cosa interessante del dataframe di pandas è che offre molti metodi che ti permettono di conoscere i tuoi dati nel modo più rapido possibile.
Hai già visto uno di questi metodi: iris_data.head(), che mostra le prime n righe (per impostazione predefinita 5). Il metodo “opposto” a head() è tail(), che mostra le ultime n righe (5 di default) del dataframe. Per esempio:
iris_data.tail()
Puoi scoprire rapidamente i nomi delle colonne usando l’attributo columns sul tuo dataframe:
# Scopri i nomi delle colonne
iris_data.columns
"""
Index(['sepal_length_in_cm', 'sepal_width_in_cm', 'petal_length_in_cm',
'petal_width_in_cm', 'class'],
dtype='object')
"""Un altro metodo importante che puoi usare sul tuo dataframe è info(). Questo metodo stampa un riepilogo conciso del dataframe, incluse informazioni su indice, tipi di dato, colonne, valori non null e utilizzo di memoria.
# Ottieni un riepilogo del dataframe
iris_data.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal_length_in_cm 150 non-null float64
1 sepal_width_in_cm 150 non-null float64
2 petal_length_in_cm 150 non-null float64
3 petal_width_in_cm 150 non-null float64
4 class 150 non-null object
dtypes: float64(4), object(1)
memory usage: 6.0+ KB
"""DataFrame.describe() genera statistiche descrittive, incluse quelle che riassumono tendenza centrale, dispersione e forma della distribuzione del dataset. Se i tuoi dati hanno valori mancanti, non preoccuparti: non sono inclusi nelle statistiche descrittive.
Chiamiamo il metodo describe sul dataset Iris:
# Ottieni statistiche descrittive
iris_data.describe()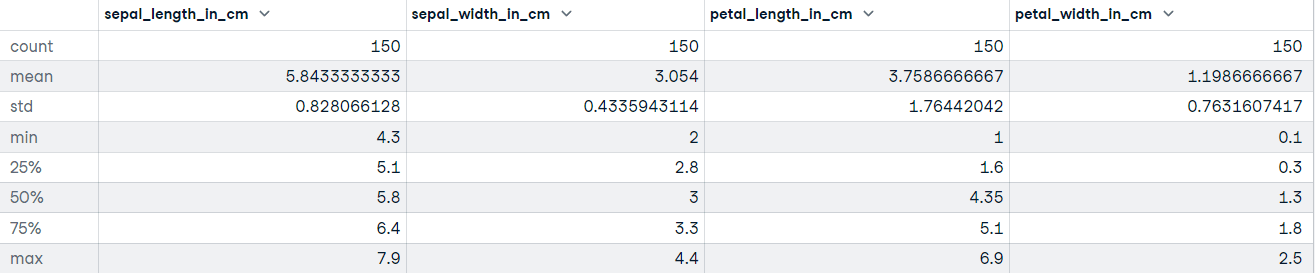
Un altro metodo disponibile per gli oggetti dataframe di pandas è to_csv(). Quando hai pulito e preprocessato i tuoi dati, il passo successivo può essere esportare il dataframe su file – è piuttosto semplice:
# Esporta il file nella directory di lavoro corrente
iris_data.to_csv("cleaned_iris_data.csv")Eseguire questo codice creerà un CSV nella directory di lavoro corrente chiamato cleaned_iris_data.csv.
Ma se volessi usare un delimitatore diverso per marcare l’inizio e la fine di un’unità di dato, o specificare come rappresentare i valori mancanti? Magari non vuoi esportare le intestazioni nel file.
Puoi regolare i parametri del metodo to_csv() per adattarli alle tue esigenze di esportazione.
Vediamo alcuni esempi di come puoi modificare l’output di to_csv():
# Cambia il delimitatore in tabulazione
iris_data.to_csv("tab_separated_iris_data.csv", sep="\t")# Esporta i dati senza l’indice
iris_data.to_csv("tab_separated_iris_data.csv", sep="\t", index=False)
# Se ottieni UnicodeEncodeError usa questo...
# iris_data.to_csv("tab_separated_iris_data.csv", sep="\t", index=False, encoding='utf-8')““):# Sostituisci i valori mancanti con "Unknown"
iris_data.to_csv("tab_separated_iris_data.csv", sep="\t", na_rep="Unknown")# Non includere le intestazioni durante l’esportazione
iris_data.to_csv("tab_separated_iris_data.csv", sep="\t", na_rep="Unknown", header=False)A volte potresti incontrare errori di codifica, specialmente se lavori su sistemi che non usano UTF-8 come codifica predefinita o se i tuoi dati contengono caratteri non ASCII. Per risolvere questi problemi, puoi specificare una codifica appropriata usando il parametro encoding.
# Esporta i dati con una codifica specifica
iris_data.to_csv("cleaned_iris_data.csv", encoding="utf-8")
Se il tuo sistema usa una codifica diversa, come Windows-1252 (comune sui sistemi Windows), puoi specificarla esplicitamente:
# Esporta i dati usando una codifica diversa
iris_data.to_csv("cleaned_iris_data.csv", encoding="cp1252")
Esempio con parametri aggiuntivi:
# Gestisci valori mancanti e problemi di codifica
iris_data.to_csv("cleaned_iris_data.csv", na_rep="Unknown", encoding="utf-8", index=False)L’esempio sopra garantisce che il file CSV esportato sia compatibile con vari sistemi e applicazioni.
| Parametro | Descrizione | Esempio d'uso |
|---|---|---|
| path_or_buf | Percorso file o oggetto; se None, il risultato viene restituito come stringa. | df.to_csv("output.csv") |
| sep | Stringa di lunghezza 1. Delimitatore dei campi per il file di output. Predefinito: ','. | df.to_csv("output.csv", sep=';') |
| na_rep | Rappresentazione dei dati mancanti. | df.to_csv("output.csv", na_rep='Unknown') |
| float_format | Stringa di formato per i numeri in virgola mobile. | df.to_csv("output.csv", float_format='%.2f') |
| columns | Colonne da scrivere. Per impostazione predefinita, scrive tutte le colonne. | df.to_csv("output.csv", columns=["id", "name"]) |
| header | Scrivere i nomi delle colonne. Se viene fornita una lista di stringhe, sarà usata come alias dei nomi delle colonne. | df.to_csv("output.csv", header=False) |
| index | Scrivere i nomi delle righe (indice). Predefinito: True. | df.to_csv("output.csv", index=False) |
| mode | Modalità di scrittura di Python. Predefinito: 'w'. | df.to_csv("output.csv", mode='a') |
| encoding | Stringa che rappresenta la codifica da usare nel file di output. | df.to_csv("output.csv", encoding='utf-8') |
Sebbene pandas sia una libreria potente e versatile per lavorare con file CSV, non è l’unica opzione disponibile in Python. A seconda del caso d’uso, altre librerie possono essere più adatte a compiti specifici:
Il modulo csv fa parte della libreria standard di Python ed è un’alternativa leggera per gestire i file CSV. Fornisce funzionalità di base per leggere e scrivere file CSV senza richiedere installazioni aggiuntive. I vantaggi di csv sono:
Esempio:
import csv
# Reading a CSV file
with open("data/sample.csv", mode="r") as file:
reader = csv.reader(file)
for row in reader:
print(row)
# Writing to a CSV file
with open("data/output.csv", mode="w", newline="") as file:
writer = csv.writer(file)
writer.writerow(["Column1", "Column2"])
writer.writerow(["Value1", "Value2"])NumPy è una libreria per il calcolo numerico in Python che supporta anche la gestione dei CSV. È particolarmente utile quando si lavora con dati numerici o quando le prestazioni sono una priorità. I vantaggi sono:
Esempio:
import numpy as np
# Reading a CSV file into a NumPy array
data = np.loadtxt("data/sample.csv", delimiter=",", skiprows=1)
# Writing a NumPy array to a CSV file
np.savetxt("data/output.csv", data, delimiter=",")Sebbene NumPy sia efficiente, non offre le ricche funzionalità di manipolazione ed esplorazione dei dati disponibili in pandas.
Se lavori con dataset molto grandi per cui pandas risulta lento o va in out-of-memory, Polars è il successore moderno che dovresti conoscere. È una libreria DataFrame scritta in Rust, progettata per prestazioni fulminee ed elaborazione parallela.
Come approfondiamo nella nostra guida a Polars, i vantaggi di Polars sono:
Esempio: La sintassi è spesso molto simile a pandas, quindi è facile da imparare:
import polars as pl
# Read a CSV file (automatically uses multiple threads)
df = pl.read_csv("data/large_dataset.csv")
# View the first 5 rows
print(df.head())
# Write to a CSV file
df.write_csv("data/polars_output.csv")Ricapitoliamo cosa abbiamo visto in questo tutorial: hai imparato a:
read_csv() della libreria pandas;read_csv() restituisca;pandas.read_csv();to_csv().In questo tutorial mi sono concentrato esclusivamente sull’importazione e l’esportazione di dati dal punto di vista di un file CSV; ora hai un’idea chiara di quanto sia utile pandas quando si importano ed esportano file CSV. Il CSV è uno dei formati di archiviazione dati più comuni, ma non è l’unico. Esistono vari altri formati usati nella data science, come parquet, JSON ed Excel.
In rete ci sono tantissimi dataset utili e di qualità, accessibili ad esempio tramite API. Se vuoi capire meglio come gestire il caricamento dei dati in Python, il corso Introduction to Importing Data in Python di DataCamp ti insegnerà tutte le best practice.
Ci sono anche tutorial su come importare dati JSON e HTML in pandas e una guida definitiva a pandas per principianti. Dagli un’occhiata per approfondire il framework di pandas.
Approfondisci Python e pandas
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

