Cursus
Pandas-joins voor spreadsheetgebruikers
4 Hr
4.5K
Voordat je een CSV-bestand in een pandas-dataframe inleest, is het handig om alvast enig inzicht te hebben in wat de data bevat. Het is daarom aan te raden om het bestand eerst even te scannen voordat je het in het geheugen laadt: zo krijg je beter zicht op welke kolommen je nodig hebt en welke je kunt weglaten.
Laten we nu wat code schrijven om een bestand te importeren met read_csv(). Daarna bespreken we wat er gebeurt en hoe je de uitvoer kunt aanpassen terwijl je de data in het geheugen inleest.
# Tip: Voor snellere performance op grote bestanden in pandas 2.0+, gebruik de pyarrow-engine
# airbnb_data = pd.read_csv("data/listings_austin.csv", engine="pyarrow")
import pandas as pd
# Lees het CSV-bestand in
airbnb_data = pd.read_csv("data/listings_austin.csv")
# Bekijk de eerste 5 rijen
airbnb_data.head()
Wat we hierboven hebben gedaan is het volgende:
read_csv() om de data in te lezen als een pandas-dataframe.Maar er is nog veel meer mogelijk met de functie read_csv().
Standaard voegt pandas een initiële index toe aan het dataframe dat uit het ingelezen CSV-bestand wordt geretourneerd. Je kunt echter expliciet aangeven welke kolom als index moet worden gebruikt in de functie read_csv() door de parameter index_col in te stellen.
Let op: de waarde die je toewijst aan index_col kan een stringnaam, een kolomindex of een reeks van stringnamen of kolomindexen zijn. Als je een reeks doorgeeft, resulteert dit in een multiIndex (een groepering van data op meerdere niveaus).
Laten we de data opnieuw inlezen en de kolom id als index instellen.
# De kolom id als index instellen
airbnb_data = pd.read_csv("data/listings_austin.csv", index_col="id")
# airbnb_data = pd.read_csv("data/listings_austin.csv", index_col=0)
# Voorvertoning van de eerste 5 rijen
airbnb_data.head()
Wat als je alleen bepaalde kolommen in het geheugen wilt inlezen omdat niet alles relevant is? Dit komt in de praktijk vaak voor. Met de functie read_csv() kun je alleen de kolommen selecteren die je nodig hebt tijdens het inladen, maar dat betekent wel dat je van tevoren moet weten welke kolommen je nodig hebt als je dit vanuit read_csv() wilt doen.
Als je de benodigde kolommen kent, heb je geluk; je bespaart tijd en geheugen door een lijstachtig object door te geven aan de parameter usecols van de functie read_csv().
# De kolommen definiëren die we willen inlezen
usecols = ["id", "name", "host_id", "neighbourhood", "room_type", "price", "minimum_nights"]
# Data inlezen met een subset van kolommen
airbnb_data = pd.read_csv("data/listings_austin.csv", index_col="id", usecols=usecols)
# Voorvertoning van de eerste 5 rijen
airbnb_data.head()
We hebben nog maar een tipje van de sluier opgelicht van de manieren waarop je de uitvoer van read_csv() kunt aanpassen; dieper ingaan zou nu wat veel informatie in één keer zijn. Gebruik hiervoor onderstaande tabel als naslag:
| Parameter | Beschrijving | Voorbeeldgebruik | |
|---|---|---|---|
| filepath_or_buffer | Het pad of de URL van het te lezen CSV-bestand. | pd.read_csv("data/listings_austin.csv") | |
| sep | Te gebruiken scheidingsteken. Standaard is ,. | pd.read_csv("data.csv", sep=';') | |
| index_col | Kolom(men) die als index worden ingesteld. Kan een kolomlabel of een geheel getal zijn. | pd.read_csv("data.csv", index_col="id") | |
| usecols | Geeft een subset van de kolommen terug. Neemt een lijstachtige van kolomnamen of indexen. | pd.read_csv("data.csv", usecols=["id", "name", "price"]) | |
| names | Lijst met te gebruiken kolomnamen. Als het bestand geen koprij bevat. | pd.read_csv("data.csv", names=["A", "B", "C"]) | |
| header | Rijnummer(s) die als kolomnamen worden gebruikt. Standaard is 0 (eerste regel). | pd.read_csv("data.csv", header=1) | |
| dtype | Gegevenstype voor data of kolommen. | pd.read_csv("data.csv", dtype={"id": int, "price": float}) | |
| na_values | Extra strings die als NA/NaN worden herkend. | pd.read_csv("data.csv", na_values=["NA", "N/A"]) | |
| parse_dates | Poging om datums te parseren. Kan boolean zijn of lijst met kolomnamen. | pd.read_csv("data.csv", parse_dates=["date"]) | |
| engine | Parser-engine: 'c' (standaard), 'python' of 'pyarrow' (snelst, vereist pyarrow-pakket). | pd.read_csv("data.csv", engine="pyarrow") | |
| skiprows | Te negeren regelnummers (0-gebaseerd) of aantal regels om aan het begin over te slaan. | pd.read_csv("data.csv", skiprows=3) | |
| nrows | Aantal rijen om te lezen. Handig om grote bestanden te bekijken. | pd.read_csv("data.csv", nrows=100) |
Bij grote datasets is het soms niet haalbaar om het hele bestand in één keer in het geheugen te laden, zeker niet in omgevingen met beperkte geheugenruimte. De functie read_csv() biedt de handige parameter chunksize, waarmee je de data in kleinere, beheersbare brokken kunt inlezen.
Door de parameter chunksize in te stellen, retourneert read_csv() een iterabel object waarbij elke iteratie een brok data als een pandas-dataframe oplevert. Deze aanpak is vooral nuttig bij batchverwerking of wanneer de dataset groter is dan het beschikbare geheugen.
Zo gebruik je de parameter chunksize:
import pandas as pd
import os # Importeer de standaard OS-bibliotheek
file_path = "data/large_dataset.csv"
output_file = "data/processed_large_dataset.csv"
chunk_size = 10000
# Chunks verwerken en wegschrijven
for chunk in pd.read_csv(file_path, chunksize=chunk_size):
# Voorbeeld: Rijen filteren op basis van een voorwaarde
filtered_chunk = chunk[chunk['column_name'] > 50]
# Controleren of header nodig is (alleen als bestand nog niet bestaat)
write_header = not os.path.exists(output_file)
# Toevoegen aan een nieuw CSV-bestand
filtered_chunk.to_csv(output_file, mode='a', header=write_header, index=False)Als je een bewerking over de hele dataset wilt uitvoeren, zoals het totale sommetje van een kolom berekenen, kun je de resultaten aggregeren terwijl je door de chunks itereert:
total_sum = 0
for chunk in pd.read_csv(file_path, chunksize=chunk_size):
# Tel voor elke chunk de som van de specifieke kolom op
total_sum += chunk['column_name'].sum()
print(f"Total sum of the column: {total_sum}")Je kunt chunksize ook gebruiken om brokken data incrementeel te verwerken en op te slaan in een nieuw bestand:
# Pad naar uitvoerbestand
output_file = "data/processed_large_dataset.csv"
# Chunks verwerken en wegschrijven
for chunk in pd.read_csv(file_path, chunksize=chunk_size):
# Voorbeeld: Rijen filteren op basis van een voorwaarde
filtered_chunk = chunk[chunk['column_name'] > 50]
# Toevoegen aan een nieuw CSV-bestand
filtered_chunk.to_csv(output_file, mode='a', header=not os.path.exists(output_file), index=False)We komen later in dit artikel meer terug op de methode to_csv().
De parameter chunksize is onmisbaar wanneer je:
Als je eenmaal weet hoe je een CSV-bestand van lokale opslag in het geheugen leest, is data inlezen uit andere bronnen een fluitje van een cent. Het proces is in de basis hetzelfde, behalve dat je nu geen bestandspad doorgeeft.
Stel dat er data op een specifieke webpagina staat die je wilt hebben; hoe lees je die in het geheugen in?
Ik gebruik als voorbeeld de Iris-dataset uit de UCI-repository:
# Webpagina-URL
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
# Definieer de kolomnamen
col_names = ["sepal_length_in_cm",
"sepal_width_in_cm",
"petal_length_in_cm",
"petal_width_in_cm",
"class"]
# Data vanaf URL inlezen
iris_data = pd.read_csv(url, names=col_names)
iris_data.head() 
Voilà!
We hebben een lijst met strings toegewezen aan de parameter names. Omdat de ruwe Iris-data geen koprij bevat, vertelt dit argument pandas om onze lijst als kolomnamen te gebruiken. (Let op: Als het bestand wél een koprij had, dan moet je ook header=0 gebruiken om pandas te laten weten dat deze vervangen moet worden).
Het meest gebruikte object in de pandas-bibliotheek is zonder twijfel het dataframe-object. Het is een 2D-gelabelde datastructuur met rijen en kolommen die verschillende datatypes kunnen hebben (zoals float, numeriek, categorisch, enz.).
Je kunt een pandas-dataframe zien als een spreadsheet, een SQL-tabel of een dictionary van series-objecten – wat jij het meest herkenbaar vindt. Het mooie aan het pandas-dataframe is dat het veel methoden heeft die het makkelijk maken om je data snel te leren kennen.
Je hebt al een van die methoden gezien: iris_data.head(), die de eerste n rijen (standaard 5) laat zien. De “tegenhanger” van head() is tail(), die de laatste n rijen (standaard 5) van het dataframe toont. Bijvoorbeeld:
iris_data.tail()
Je kunt de kolomnamen snel achterhalen met het attribuut columns op je dataframe-object:
# Ontdek de kolomnamen
iris_data.columns
"""
Index(['sepal_length_in_cm', 'sepal_width_in_cm', 'petal_length_in_cm',
'petal_width_in_cm', 'class'],
dtype='object')
"""Een andere belangrijke methode op je dataframe is info(). Deze methode geeft een beknopt overzicht van het dataframe, inclusief informatie over de index, datatypes, kolommen, non-null waarden en geheugengebruik.
# Verkrijg samenvattende informatie over het dataframe
iris_data.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal_length_in_cm 150 non-null float64
1 sepal_width_in_cm 150 non-null float64
2 petal_length_in_cm 150 non-null float64
3 petal_width_in_cm 150 non-null float64
4 class 150 non-null object
dtypes: float64(4), object(1)
memory usage: 6.0+ KB
"""DataFrame.describe() genereert beschrijvende statistieken, waaronder samenvattingen van de centrale tendens, spreiding en vorm van de verdeling van je dataset. Als je data ontbrekende waarden heeft: geen zorgen, die worden niet meegenomen in de beschrijvende statistieken.
Laten we de describe-methode aanroepen op de Iris-dataset:
# Verkrijg beschrijvende statistieken
iris_data.describe()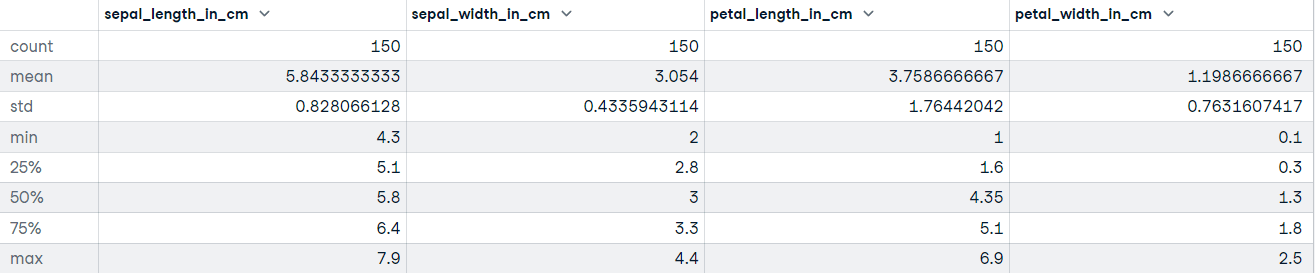
Een andere methode die beschikbaar is op pandas-dataframes is to_csv(). Wanneer je je data hebt opgeschoond en voorbewerkt, is de volgende stap vaak om het dataframe naar een bestand te exporteren – dat is vrij eenvoudig:
# Exporteer het bestand naar de huidige werkmap
iris_data.to_csv("cleaned_iris_data.csv")Het uitvoeren van deze code maakt een CSV in de huidige werkmap met de naam cleaned_iris_data.csv.
Maar wat als je een ander scheidingsteken wilt gebruiken om het begin en einde van een data-eenheid aan te geven, of wilt je aangeven hoe ontbrekende waarden moeten worden weergegeven? Misschien wil je de headers niet exporteren.
Je kunt de parameters van de methode to_csv() aanpassen aan je wensen voor de data die je wilt exporteren.
Bekijk een paar voorbeelden van hoe je de uitvoer van to_csv() kunt bijsturen:
# Verander het scheidingsteken in een tab
iris_data.to_csv("tab_separated_iris_data.csv", sep="\t")# Exporteer data zonder de index
iris_data.to_csv("tab_separated_iris_data.csv", sep="\t", index=False)
# Krijg je een UnicodeEncodeError? Gebruik dan dit...
# iris_data.to_csv("tab_separated_iris_data.csv", sep="\t", index=False, encoding='utf-8')““):# Vervang ontbrekende waarden door "Unknown"
iris_data.to_csv("tab_separated_iris_data.csv", sep="\t", na_rep="Unknown")# Headers niet meenemen bij het exporteren
iris_data.to_csv("tab_separated_iris_data.csv", sep="\t", na_rep="Unknown", header=False)Soms kun je te maken krijgen met encodingfouten, vooral als je werkt op systemen die niet standaard UTF-8 gebruiken of als je data niet-ASCII-tekens bevat. Om dit op te lossen kun je een geschikte encoding opgeven met de parameter encoding.
# Data exporteren met een specifieke encoding
iris_data.to_csv("cleaned_iris_data.csv", encoding="utf-8")
Als je systeem een andere encoding gebruikt, zoals Windows-1252 (vaak op Windows-systemen), kun je die expliciet opgeven:
# Data exporteren met een andere encoding
iris_data.to_csv("cleaned_iris_data.csv", encoding="cp1252")
Voorbeeld met extra parameters:
# Omgaan met ontbrekende waarden en encoding-issues
iris_data.to_csv("cleaned_iris_data.csv", na_rep="Unknown", encoding="utf-8", index=False)Het bovenstaande voorbeeld zorgt ervoor dat je geëxporteerde CSV-bestand compatibel is met verschillende systemen en applicaties.
| Parameter | Beschrijving | Voorbeeldgebruik |
|---|---|---|
| path_or_buf | Bestandspad of -object; als None is opgegeven, wordt het resultaat als string geretourneerd. | df.to_csv("output.csv") |
| sep | String van lengte 1. Scheidingsteken voor het uitvoerbestand. Standaard is ','. | df.to_csv("output.csv", sep=';') |
| na_rep | Weergave van ontbrekende data. | df.to_csv("output.csv", na_rep='Unknown') |
| float_format | Formaatstring voor drijvende-kommagetallen. | df.to_csv("output.csv", float_format='%.2f') |
| columns | Kolommen om te schrijven. Standaard worden alle kolommen weggeschreven. | df.to_csv("output.csv", columns=["id", "name"]) |
| header | Kolomnamen wegschrijven. Als een lijst met strings is opgegeven, worden deze als aliassen voor de kolomnamen gezien. | df.to_csv("output.csv", header=False) |
| index | Rijnamen (index) wegschrijven. Standaard True. | df.to_csv("output.csv", index=False) |
| mode | Python-schrijfmodus. Standaard 'w'. | df.to_csv("output.csv", mode='a') |
| encoding | Een string die de te gebruiken encoding in het uitvoerbestand weergeeft. | df.to_csv("output.csv", encoding='utf-8') |
Hoewel pandas een krachtige en veelzijdige library is voor het werken met CSV-bestanden, is het niet de enige optie in Python. Afhankelijk van je usecase kunnen andere libraries geschikter zijn voor specifieke taken:
De csv-module maakt deel uit van Python’s standaardbibliotheek en is een lichtgewicht alternatief voor het verwerken van CSV-bestanden. Het biedt basisfunctionaliteit voor lezen en schrijven zonder extra installaties. De voordelen van csv zijn:
Voorbeeld:
import csv
# Een CSV-bestand lezen
with open("data/sample.csv", mode="r") as file:
reader = csv.reader(file)
for row in reader:
print(row)
# Schrijven naar een CSV-bestand
with open("data/output.csv", mode="w", newline="") as file:
writer = csv.writer(file)
writer.writerow(["Column1", "Column2"])
writer.writerow(["Value1", "Value2"])NumPy is een library voor numerieke computing in Python die ook CSV ondersteunt. Het is vooral handig wanneer je met numerieke data werkt of wanneer performance belangrijk is. De voordelen zijn:
Voorbeeld:
import numpy as np
# Een CSV-bestand inlezen in een NumPy-array
data = np.loadtxt("data/sample.csv", delimiter=",", skiprows=1)
# Een NumPy-array naar een CSV-bestand schrijven
np.savetxt("data/output.csv", data, delimiter=",")Hoewel NumPy efficiënt is, biedt het niet de rijke datamanipulatie- en verkenningsfeatures die in pandas beschikbaar zijn.
Als je werkt met zeer grote datasets waarbij pandas traag aanvoelt of het geheugen opraakt, is Polars de moderne opvolger die je moet kennen. Het is een DataFrame-library, geschreven in Rust, ontworpen voor razendsnelle performance en parallelle verwerking.
Zoals we laten zien in onze Polars-tutorial, zijn de voordelen van Polars:
Voorbeeld: De syntaxis lijkt vaak sterk op die van pandas, waardoor het makkelijk op te pakken is:
import polars as pl
# Lees een CSV-bestand (gebruikt automatisch meerdere threads)
df = pl.read_csv("data/large_dataset.csv")
# Bekijk de eerste 5 rijen
print(df.head())
# Schrijf naar een CSV-bestand
df.write_csv("data/polars_output.csv")Laten we kort herhalen wat we in deze tutorial hebben behandeld; je leerde hoe je:
read_csv() uit de pandas-bibliotheek.read_csv() wilt laten teruggeven.pandas.read_csv()to_csv().In deze tutorial heb ik me uitsluitend gericht op het importeren en exporteren van data in de context van een CSV-bestand; je hebt nu een goed beeld van hoe nuttig pandas is bij het importeren en exporteren van CSV-bestanden. CSV is een van de meest gebruikte opslagformaten voor data, maar zeker niet de enige. Er zijn verschillende andere bestandsformaten in data science, zoals parquet, JSON en Excel.
Er zijn veel nuttige, hoogwaardige datasets op het web te vinden, die je bijvoorbeeld via API’s kunt benaderen. Wil je in meer detail begrijpen hoe je data in Python laadt, dan leert DataCamp’s cursus Introduction to Importing Data in Python je alle best practices.
Er zijn ook tutorials over hoe je JSON- en HTML-data in pandas importeert en een beginnersvriendelijke ultieme gids voor pandas. Bekijk die zeker om dieper in het pandas-framework te duiken.
Meer leren over Python en pandas
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
