Kurs
Pandas-Joins für Spreadsheet-Nutzer
4 Std.
4.5K
Bevor du eine CSV-Datei in einen Pandas-Datenframe einliest, solltest du wissen, was die Daten enthalten. Es ist daher empfehlenswert, die Datei zu überfliegen, bevor du versuchst, sie in den Speicher zu laden: So kannst du besser erkennen, welche Spalten benötigt werden und welche du weglassen kannst.
Lass uns einen Code schreiben, um eine Datei mit read_csv() zu importieren. Dann können wir darüber reden, was vor sich geht und wie wir die Ausgabe anpassen können, die wir beim Lesen der Daten in den Speicher erhalten.
import pandas as pd
# Read the CSV file
airbnb_data = pd.read_csv("data/listings_austin.csv")
# View the first 5 rows
airbnb_data.head()
Alles, was im obigen Code passiert ist, ist, dass wir haben:
read_csv, um die Daten als Pandas Dataframe in den Speicher zu lesen.Aber die Funktion read_csv() hat noch viel mehr zu bieten.
Standardmäßig fügt Pandas dem Datenrahmen, der aus der in den Speicher geladenen CSV-Datei zurückgegeben wird, einen Anfangsindex hinzu. Du kannst jedoch explizit angeben, welche Spalte als Index für die Funktion read_csv dienen soll, indem du den Parameter index_col setzt.
Beachte, dass der Wert, den du index_col zuweist, entweder als String-Name, Spaltenindex oder als eine Folge von String-Namen oder Spaltenindizes angegeben werden kann. Wenn du dem Parameter eine Sequenz zuweist, entsteht ein MultiIndex (eine Gruppierung der Daten nach mehreren Ebenen).
Wir lesen die Daten erneut ein und setzen die Spalte id als Index.
# Setting the id column as the index
airbnb_data = pd.read_csv("data/listings_austin.csv", index_col="id")
# airbnb_data = pd.read_csv("data/listings_austing.csv", index_col=0)
# Preview first 5 rows
airbnb_data.head()
Was ist, wenn du nur bestimmte Spalten in den Speicher einlesen willst, weil nicht alle wichtig sind? Das ist ein häufiges Szenario, das in der realen Welt vorkommt. Mit der Funktion read_csv kannst du nur die Spalten auswählen, die du nach dem Laden der Datei benötigst. Das bedeutet jedoch, dass du vor dem Laden der Daten wissen musst, welche Spalten du benötigst, wenn du diesen Vorgang innerhalb der Funktion read_csv durchführen möchtest.
Wenn du die benötigten Spalten kennst, hast du Glück: Du kannst Zeit und Speicherplatz sparen, indem du ein listenähnliches Objekt an den Parameter usecols der Funktion read_csv übergibst.
# Defining the columns to read
usecols = ["id", "name", "host_id", "neighbourhood", "room_type", "price", "minimum_nights"]
# Read data with subset of columns
airbnb_data = pd.read_csv("data/listings_austin.csv", index_col="id", usecols=usecols)
# Preview first 5 rows
airbnb_data.head()
Wir haben kaum an der Oberfläche der verschiedenen Möglichkeiten gekratzt, die Ausgabe der read_csv-Funktion anzupassen, aber mehr in die Tiefe zu gehen, wäre sicherlich eine Informationsflut.
Wir empfehlen dir, den Spickzettel zum Importieren von Daten in Python als Lesezeichen zu speichern und die Einführung in das Importieren von Daten in Python zu lesen, um mehr zu erfahren. Wenn dir das zu einfach ist, gibt es auch den interaktiven Kurs Importieren von Daten in Python.
Sobald du weißt, wie du eine CSV-Datei aus dem lokalen Speicher in den Speicher einlesen kannst, ist das Lesen von Daten aus anderen Quellen ein Kinderspiel. Es ist letztlich derselbe Prozess, nur dass du keinen Dateipfad mehr übergibst.
Angenommen, du willst Daten von einer bestimmten Webseite haben. Wie würdest du sie in den Speicher einlesen?
Wir werden den Iris-Datensatz aus dem UCI-Repository als Beispiel verwenden:
# Webpage URL
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
# Define the column names
col_names = ["sepal_length_in_cm",
"sepal_width_in_cm",
"petal_length_in_cm",
"petal_width_in_cm",
"class"]
# Read data from URL
iris_data = pd.read_csv(url, names=col_names)
iris_data.head() 
Voila!
Du hast vielleicht bemerkt, dass wir dem Parameter names in der Funktion read_csv eine Liste von Strings zugewiesen haben. So können wir die Spaltenüberschriften umbenennen, während wir die Daten in den Speicher einlesen.
Das häufigste Objekt in der Pandas-Bibliothek ist mit Abstand das Dataframe-Objekt. Es handelt sich um eine zweidimensionale, beschriftete Datenstruktur, die aus Zeilen und Spalten besteht, die unterschiedliche Datentypen haben können (z. B. Fließkomma, numerisch, kategorisch usw.).
Vom Konzept her kannst du dir einen Pandas-Dataframe wie eine Tabellenkalkulation, eine SQL-Tabelle oder ein Wörterbuch mit Reihenobjekten vorstellen - je nachdem, womit du besser vertraut bist. Das Tolle am Pandas Dataframe ist, dass er mit vielen Methoden ausgestattet ist, die es dir leicht machen, dich so schnell wie möglich mit deinen Daten vertraut zu machen.
Eine dieser Methoden hast du bereits gesehen: iris_data.head() Sie zeigt die ersten n (Standard ist 5) Zeilen an. Die "entgegengesetzte" Methode von head() ist tail(), die die letzten n (standardmäßig 5) Zeilen des Datenrahmenobjekts anzeigt. Zum Beispiel:
iris_data.tail()
Du kannst die Spaltennamen schnell herausfinden, indem du das Attribut columns deines Datenrahmenobjekts verwendest:
# Discover the column names
iris_data.columns
"""
Index(['sepal_length_in_cm', 'sepal_width_in_cm', 'petal_length_in_cm',
'petal_width_in_cm', 'class'],
dtype='object')
"""Eine weitere wichtige Methode, die du für dein Dataframe-Objekt verwenden kannst, ist info(). Diese Methode gibt eine kurze Zusammenfassung des Datenrahmens aus, einschließlich Informationen über den Index, die Datentypen, die Spalten, die Nicht-Null-Werte und die Speichernutzung.
# Get summary information of the dataframe
iris_data.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal_length_in_cm 150 non-null float64
1 sepal_width_in_cm 150 non-null float64
2 petal_length_in_cm 150 non-null float64
3 petal_width_in_cm 150 non-null float64
4 class 150 non-null object
dtypes: float64(4), object(1)
memory usage: 6.0+ KB
"""DataFrame.describe() erstellt deskriptive Statistiken, die unter anderem die zentrale Tendenz, die Streuung und die Form der Verteilung des Datensatzes zusammenfassen. Wenn deine Daten fehlende Werte enthalten, musst du dir keine Sorgen machen: Sie werden in der deskriptiven Statistik nicht berücksichtigt.
Rufen wir die Methode describe für den Iris-Datensatz auf:
# Get descriptive statistics
iris_data.describe()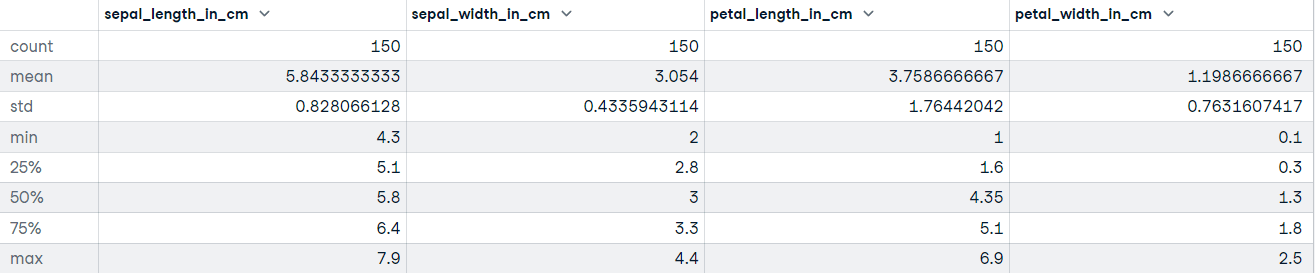
Eine weitere Methode, die für Pandas Dataframe-Objekte verfügbar ist, ist to_csv(). Wenn du deine Daten bereinigt und vorverarbeitet hast, kann der nächste Schritt darin bestehen, den Datenrahmen in eine Datei zu exportieren - das ist ziemlich einfach:
# Export the file to the current working directory
iris_data.to_csv("cleaned_iris_data.csv")Wenn du diesen Code ausführst, wird eine CSV-Datei im aktuellen Arbeitsverzeichnis mit dem Namen cleaned_iris_data.csv erstellt.
Aber was ist, wenn du ein anderes Trennzeichen verwenden möchtest, um den Anfang und das Ende einer Dateneinheit zu markieren, oder wenn du angeben möchtest, wie deine fehlenden Werte dargestellt werden sollen? Vielleicht willst du nicht, dass die Kopfzeilen in die Datei exportiert werden.
Du kannst die Parameter der Methode to_csv() an deine Anforderungen für die Daten, die du exportieren willst, anpassen.
Schauen wir uns ein paar Beispiele an, wie du die Ausgabe von to_csv() anpassen kannst:
# Change the delimiter to a tab
iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t")# Export data without the index
iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t")
# If you get UnicodeEncodeError use this...
# iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t", index=False, encoding='utf-8')# Replace missing values with "Unknown"
iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t", na_rep="Unknown")# Do not include headers when exporting the data
iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t", na_rep="Unknown", header=False)Fassen wir noch einmal zusammen, was wir in diesem Tutorium behandelt haben: Du hast gelernt, wie man
read_csv() aus der Pandas-Bibliothek.read_csv() zurückgeben soll.pandas.read_csv()to_csv() an.In diesem Tutorial haben wir uns ausschließlich auf den Import und Export von Daten aus der Perspektive einer CSV-Datei konzentriert; du hast jetzt ein gutes Gefühl dafür, wie nützlich Pandas beim Import und Export von CSV-Dateien ist. CSV ist eines der gebräuchlichsten Formate für die Datenspeicherung, aber es ist nicht das einzige. Es gibt verschiedene andere Dateiformate, die in der Datenwissenschaft verwendet werden, z.B. Parquet, JSON und Excel.
Im Internet gibt es viele nützliche, hochwertige Datensätze, auf die du zum Beispiel über APIs zugreifen kannst. Wenn du genauer wissen willst, wie du Daten in Python laden kannst, lernst du im DataCamp-Kurs Einführung in den Datenimport in Python die besten Methoden kennen.
Außerdem gibt es Tutorials zum Importieren von JSON- und HTML-Daten in Pandas und ein einsteigerfreundliches Tutorial zum ultimativen Pandas-Leitfaden. Schaue dir diese unbedingt an, um tiefer in das Pandas-Framework einzutauchen.
Unsere Zertifizierungsprogramme helfen dir, dich von anderen abzuheben und potenziellen Arbeitgebern zu beweisen, dass deine Fähigkeiten für den Job geeignet sind.

Erfahre mehr über Python und Pandas
Kurs
Kurs
Kurs
Tutorial
Sejal Jaiswal
Tutorial
Aditya Sharma
Tutorial
Matt Crabtree
Tutorial
Allan Ouko
Tutorial
Abid Ali Awan
Tutorial
DataCamp Team
