Courses
Ghép nối dữ liệu bằng Pandas dành cho người dùng bảng tính
4 giờ
4.5K
Trước khi đọc một tệp CSV vào dataframe của pandas, bạn nên có đôi chút hiểu biết về nội dung dữ liệu. Do đó, nên duyệt nhanh tệp trước khi tải vào bộ nhớ: điều này sẽ giúp bạn hiểu rõ hơn cột nào cần thiết và cột nào có thể loại bỏ.
Giờ hãy viết một chút mã để nhập tệp bằng read_csv(). Sau đó, chúng ta sẽ bàn về những gì đang diễn ra và cách tùy chỉnh đầu ra nhận được khi đọc dữ liệu vào bộ nhớ.
# Tip: For faster performance on large files in pandas 2.0+, use the pyarrow engine
# airbnb_data = pd.read_csv("data/listings_austin.csv", engine="pyarrow")
import pandas as pd
# Read the CSV file
airbnb_data = pd.read_csv("data/listings_austin.csv")
# View the first 5 rows
airbnb_data.head()
Tất cả những gì diễn ra trong đoạn mã trên là chúng ta đã:
read_csv() để đọc dữ liệu vào bộ nhớ dưới dạng một dataframe của pandas.Nhưng hàm read_csv() còn làm được nhiều hơn thế.
Hành vi mặc định của pandas là thêm một chỉ mục ban đầu vào dataframe trả về từ tệp CSV đã được tải vào bộ nhớ. Tuy nhiên, bạn có thể chỉ định rõ cột nào sẽ làm chỉ mục cho hàm read_csv() bằng cách đặt tham số index_col.
Lưu ý giá trị bạn gán cho index_col có thể là tên chuỗi, chỉ số cột, hoặc một dãy tên chuỗi hay chỉ số cột. Gán một dãy cho tham số này sẽ tạo ra multiIndex (nhóm dữ liệu theo nhiều cấp).
Hãy đọc lại dữ liệu và đặt cột id làm chỉ mục.
# Setting the id column as the index
airbnb_data = pd.read_csv("data/listings_austin.csv", index_col="id")
# airbnb_data = pd.read_csv("data/listings_austin.csv", index_col=0)
# Preview first 5 rows
airbnb_data.head()
Nếu bạn chỉ muốn đọc một số cột cụ thể vào bộ nhớ vì không phải tất cả đều quan trọng thì sao? Đây là một tình huống thường gặp trong thực tế. Với hàm read_csv(), bạn có thể chỉ chọn các cột cần thiết sau khi tải tệp, nhưng điều này có nghĩa là bạn phải biết trước mình cần cột nào nếu muốn thực hiện thao tác này ngay trong hàm read_csv().
Nếu bạn biết các cột mình cần, thật may mắn; bạn có thể tiết kiệm thời gian và bộ nhớ bằng cách truyền một đối tượng dạng danh sách vào tham số usecols của hàm read_csv().
# Defining the columns to read
usecols = ["id", "name", "host_id", "neighbourhood", "room_type", "price", "minimum_nights"]
# Read data with subset of columns
airbnb_data = pd.read_csv("data/listings_austin.csv", index_col="id", usecols=usecols)
# Preview first 5 rows
airbnb_data.head()
Chúng ta mới chỉ lướt qua bề mặt các cách tùy chỉnh đầu ra của hàm read_csv(), đi sâu hơn chắc chắn sẽ quá tải thông tin. Vì vậy, bạn có thể dùng bảng sau như tài liệu tham khảo:
| Parameter | Description | Example usage | |
|---|---|---|---|
| filepath_or_buffer | Đường dẫn hoặc URL của tệp CSV cần đọc. | pd.read_csv("data/listings_austin.csv") | |
| sep | Ký tự phân tách. Mặc định là ,. | pd.read_csv("data.csv", sep=';') | |
| index_col | Cột đặt làm chỉ mục. Có thể là nhãn cột hoặc số nguyên. | pd.read_csv("data.csv", index_col="id") | |
| usecols | Trả về một tập con các cột. Nhận một danh sách tên cột hoặc chỉ số. | pd.read_csv("data.csv", usecols=["id", "name", "price"]) | |
| names | Danh sách tên cột sẽ dùng. Khi tệp không có hàng tiêu đề. | pd.read_csv("data.csv", names=["A", "B", "C"]) | |
| header | Số thứ tự hàng dùng làm tên cột. Mặc định là 0 (dòng đầu tiên). | pd.read_csv("data.csv", header=1) | |
| dtype | Kiểu dữ liệu cho toàn bộ dữ liệu hoặc từng cột. | pd.read_csv("data.csv", dtype={"id": int, "price": float}) | |
| na_values | Các chuỗi bổ sung nhận diện là NA/NaN. | pd.read_csv("data.csv", na_values=["NA", "N/A"]) | |
| parse_dates | Cố gắng phân tích định dạng ngày. Có thể là boolean hoặc danh sách tên cột. | pd.read_csv("data.csv", parse_dates=["date"]) | |
| engine | Bộ phân tích: 'c' (mặc định), 'python', hoặc 'pyarrow' (nhanh nhất, cần gói pyarrow). | pd.read_csv("data.csv", engine="pyarrow") | |
| skiprows | Các số dòng cần bỏ qua (đánh số từ 0) hoặc số dòng bỏ qua ở đầu tệp. | pd.read_csv("data.csv", skiprows=3) | |
| nrows | Số hàng cần đọc. Hữu ích khi xem nhanh các tệp lớn. | pd.read_csv("data.csv", nrows=100) |
Khi làm việc với các bộ dữ liệu lớn, tải toàn bộ tệp vào bộ nhớ một lần có thể không khả thi, đặc biệt trong môi trường hạn chế bộ nhớ. Hàm read_csv() cung cấp tham số chunksize tiện dụng, cho phép bạn đọc dữ liệu theo những phần nhỏ, dễ xử lý.
Bằng cách đặt tham số chunksize, read_csv() trả về một đối tượng có thể lặp, trong đó mỗi vòng lặp cung cấp một phần dữ liệu dưới dạng dataframe của pandas. Cách tiếp cận này đặc biệt hữu ích khi xử lý dữ liệu theo lô hoặc khi kích thước bộ dữ liệu vượt quá bộ nhớ khả dụng.
Đây là cách bạn có thể dùng tham số chunksize:
import pandas as pd
import os # Import the standard OS library
file_path = "data/large_dataset.csv"
output_file = "data/processed_large_dataset.csv"
chunk_size = 10000
# Process and write chunks
for chunk in pd.read_csv(file_path, chunksize=chunk_size):
# Example: Filter rows based on a condition
filtered_chunk = chunk[chunk['column_name'] > 50]
# Check if header is needed (only if file doesn't exist yet)
write_header = not os.path.exists(output_file)
# Append to a new CSV file
filtered_chunk.to_csv(output_file, mode='a', header=write_header, index=False)Nếu mục tiêu của bạn là thực hiện một phép tính trên toàn bộ tập dữ liệu, chẳng hạn tính tổng của một cột, bạn có thể tổng hợp kết quả khi lặp qua các phần:
total_sum = 0
for chunk in pd.read_csv(file_path, chunksize=chunk_size):
# Add the sum of the specific column for each chunk
total_sum += chunk['column_name'].sum()
print(f"Total sum of the column: {total_sum}")Bạn cũng có thể dùng chunksize để xử lý và lưu từng phần dữ liệu vào tệp mới một cách tuần tự:
# Output file path
output_file = "data/processed_large_dataset.csv"
# Process and write chunks
for chunk in pd.read_csv(file_path, chunksize=chunk_size):
# Example: Filter rows based on a condition
filtered_chunk = chunk[chunk['column_name'] > 50]
# Append to a new CSV file
filtered_chunk.to_csv(output_file, mode='a', header=not os.path.exists(output_file), index=False)Chúng ta sẽ còn thấy nhiều hơn về phương thức to_csv() ở các phần sau.
Tham số chunksize là không thể thiếu khi:
Khi bạn đã biết cách đọc tệp CSV từ bộ nhớ cục bộ vào bộ nhớ chương trình, việc đọc dữ liệu từ các nguồn khác trở nên rất dễ dàng. Về cơ bản vẫn là quy trình tương tự, chỉ khác là bạn không còn truyền đường dẫn tệp nữa.
Giả sử bạn muốn lấy dữ liệu từ một trang web cụ thể; làm sao để đọc nó vào bộ nhớ?
Tôi sẽ dùng bộ dữ liệu Iris từ kho UCI làm ví dụ:
# Webpage URL
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
# Define the column names
col_names = ["sepal_length_in_cm",
"sepal_width_in_cm",
"petal_length_in_cm",
"petal_width_in_cm",
"class"]
# Read data from URL
iris_data = pd.read_csv(url, names=col_names)
iris_data.head() 
Voila!
Chúng ta đã gán một danh sách chuỗi cho tham số names. Vì dữ liệu thô của Iris không có hàng tiêu đề, đối số này báo cho pandas dùng danh sách của chúng ta làm tên cột. (Lưu ý: Nếu tệp có hàng tiêu đề, bạn cũng cần dùng header=0 để yêu cầu pandas thay thế nó).
Đối tượng phổ biến nhất trong thư viện pandas, vượt trội hẳn, là đối tượng dataframe. Đây là cấu trúc dữ liệu gán nhãn 2 chiều gồm các hàng và cột có thể có kiểu dữ liệu khác nhau (ví dụ: float, số, phân loại, v.v.).
Về mặt khái niệm, bạn có thể hình dung dataframe của pandas như một bảng tính, bảng SQL hoặc từ điển các đối tượng series – tùy cái nào bạn quen thuộc hơn. Điều thú vị ở dataframe của pandas là nó đi kèm nhiều phương thức giúp bạn nhanh chóng làm quen với dữ liệu.
Bạn đã thấy một trong các phương thức đó: iris_data.head(), hiển thị n hàng đầu tiên (mặc định là 5). Phương thức “đối nghịch” với head() là tail(), hiển thị n hàng cuối (mặc định là 5) của đối tượng dataframe. Ví dụ:
iris_data.tail()
Bạn có thể nhanh chóng xem tên các cột bằng thuộc tính columns trên đối tượng dataframe của mình:
# Discover the column names
iris_data.columns
"""
Index(['sepal_length_in_cm', 'sepal_width_in_cm', 'petal_length_in_cm',
'petal_width_in_cm', 'class'],
dtype='object')
"""Một phương thức quan trọng khác bạn có thể dùng trên đối tượng dataframe là info(). Phương thức này in ra tóm tắt súc tích về dataframe, bao gồm thông tin về chỉ mục, kiểu dữ liệu, các cột, số giá trị không null và mức sử dụng bộ nhớ.
# Get summary information of the dataframe
iris_data.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal_length_in_cm 150 non-null float64
1 sepal_width_in_cm 150 non-null float64
2 petal_length_in_cm 150 non-null float64
3 petal_width_in_cm 150 non-null float64
4 class 150 non-null object
dtypes: float64(4), object(1)
memory usage: 6.0+ KB
"""DataFrame.describe() tạo ra các thống kê mô tả, bao gồm những thống kê tóm tắt xu hướng trung tâm, độ phân tán và hình dạng phân phối của tập dữ liệu. Nếu dữ liệu của bạn có giá trị khuyết, đừng lo; chúng không được đưa vào thống kê mô tả.
Hãy gọi phương thức describe trên bộ dữ liệu Iris:
# Get descriptive statistics
iris_data.describe()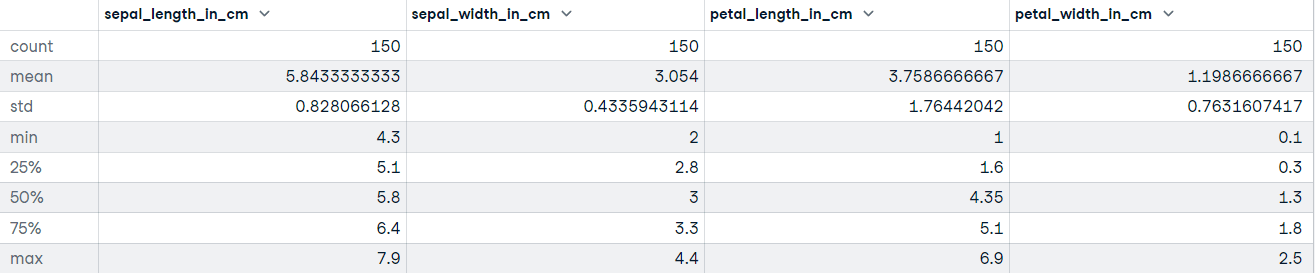
Một phương thức khác có sẵn cho các đối tượng dataframe của pandas là to_csv(). Khi bạn đã làm sạch và tiền xử lý dữ liệu, bước tiếp theo có thể là xuất dataframe ra tệp – việc này khá đơn giản:
# Export the file to the current working directory
iris_data.to_csv("cleaned_iris_data.csv")Chạy đoạn mã này sẽ tạo một tệp CSV trong thư mục làm việc hiện tại có tên cleaned_iris_data.csv.
Nhưng nếu bạn muốn dùng một ký tự phân tách khác để đánh dấu đầu và cuối của một đơn vị dữ liệu, hoặc bạn muốn chỉ định cách biểu diễn giá trị khuyết thì sao? Có thể bạn không muốn xuất tiêu đề cột vào tệp.
Vậy thì bạn có thể điều chỉnh các tham số của phương thức to_csv() để phù hợp với yêu cầu cho dữ liệu cần xuất.
Hãy xem một vài ví dụ về cách bạn có thể điều chỉnh đầu ra của to_csv():
# Change the delimiter to a tab
iris_data.to_csv("tab_separated_iris_data.csv", sep="\t")# Export data without the index
iris_data.to_csv("tab_separated_iris_data.csv", sep="\t", index=False)
# If you get UnicodeEncodeError use this...
# iris_data.to_csv("tab_separated_iris_data.csv", sep="\t", index=False, encoding='utf-8')““):# Replace missing values with "Unknown"
iris_data.to_csv("tab_separated_iris_data.csv", sep="\t", na_rep="Unknown")# Do not include headers when exporting the data
iris_data.to_csv("tab_separated_iris_data.csv", sep="\t", na_rep="Unknown", header=False)Đôi khi bạn có thể gặp lỗi mã hóa, đặc biệt nếu bạn làm việc trên các hệ thống không dùng UTF-8 làm mã hóa mặc định hoặc nếu dữ liệu chứa ký tự không phải ASCII. Để khắc phục, bạn có thể chỉ định mã hóa phù hợp bằng tham số encoding.
# Export data with a specified encoding
iris_data.to_csv("cleaned_iris_data.csv", encoding="utf-8")
Nếu hệ thống của bạn dùng mã hóa khác, như Windows-1252 (thường gặp trên hệ thống Windows), bạn có thể chỉ định rõ ràng:
# Export data using a different encoding
iris_data.to_csv("cleaned_iris_data.csv", encoding="cp1252")
Ví dụ với các tham số bổ sung:
# Handle missing values and encoding issues
iris_data.to_csv("cleaned_iris_data.csv", na_rep="Unknown", encoding="utf-8", index=False)Ví dụ trên đảm bảo tệp CSV xuất ra tương thích với nhiều hệ thống và ứng dụng.
| Parameter | Description | Example usage |
|---|---|---|
| path_or_buf | Đường dẫn tệp hoặc đối tượng, nếu để None thì kết quả sẽ được trả về dưới dạng chuỗi. | df.to_csv("output.csv") |
| sep | Chuỗi dài 1 ký tự. Ký tự phân tách trường cho tệp đầu ra. Mặc định là ','. | df.to_csv("output.csv", sep=';') |
| na_rep | Ký hiệu cho dữ liệu khuyết. | df.to_csv("output.csv", na_rep='Unknown') |
| float_format | Chuỗi định dạng cho số thực. | df.to_csv("output.csv", float_format='%.2f') |
| columns | Các cột sẽ ghi. Mặc định ghi tất cả các cột. | df.to_csv("output.csv", columns=["id", "name"]) |
| header | Ghi tên cột. Nếu đưa vào một danh sách chuỗi, danh sách đó sẽ được coi như bí danh cho tên cột. | df.to_csv("output.csv", header=False) |
| index | Ghi tên hàng (chỉ mục). Mặc định là True. | df.to_csv("output.csv", index=False) |
| mode | Chế độ ghi tệp của Python. Mặc định là 'w'. | df.to_csv("output.csv", mode='a') |
| encoding | Chuỗi biểu thị mã hóa dùng cho tệp đầu ra. | df.to_csv("output.csv", encoding='utf-8') |
Mặc dù pandas là thư viện mạnh mẽ và linh hoạt để làm việc với tệp CSV, nhưng không phải lựa chọn duy nhất trong Python. Tùy trường hợp sử dụng, các thư viện khác có thể phù hợp hơn cho những tác vụ cụ thể:
Module csv là một phần của thư viện chuẩn của Python và là lựa chọn gọn nhẹ để xử lý tệp CSV. Nó cung cấp chức năng cơ bản để đọc và ghi tệp CSV mà không cần cài đặt bổ sung. Ưu điểm của csv là:
Ví dụ:
import csv
# Reading a CSV file
with open("data/sample.csv", mode="r") as file:
reader = csv.reader(file)
for row in reader:
print(row)
# Writing to a CSV file
with open("data/output.csv", mode="w", newline="") as file:
writer = csv.writer(file)
writer.writerow(["Column1", "Column2"])
writer.writerow(["Value1", "Value2"])NumPy là thư viện tính toán số học trong Python cũng hỗ trợ xử lý CSV. Nó đặc biệt hữu ích khi làm việc với dữ liệu số hoặc khi hiệu năng là mối quan tâm. Các ưu điểm gồm:
Ví dụ:
import numpy as np
# Reading a CSV file into a NumPy array
data = np.loadtxt("data/sample.csv", delimiter=",", skiprows=1)
# Writing a NumPy array to a CSV file
np.savetxt("data/output.csv", data, delimiter=",")Mặc dù NumPy hiệu quả, nó không cung cấp các tính năng thao tác dữ liệu và khám phá phong phú như pandas.
Nếu bạn đang làm việc với những bộ dữ liệu rất lớn nơi pandas tỏ ra chậm hoặc hết bộ nhớ, Polars là “người kế nhiệm” hiện đại mà bạn nên biết. Đây là một thư viện DataFrame viết bằng Rust, được thiết kế cho hiệu năng cực nhanh và xử lý song song.
Như chúng tôi khám phá trong hướng dẫn Polars, các ưu điểm của Polars gồm:
Ví dụ: Cú pháp thường khá giống pandas, giúp bạn dễ dàng làm quen:
import polars as pl
# Read a CSV file (automatically uses multiple threads)
df = pl.read_csv("data/large_dataset.csv")
# View the first 5 rows
print(df.head())
# Write to a CSV file
df.write_csv("data/polars_output.csv")Hãy điểm lại những gì chúng ta đã học trong hướng dẫn này; bạn đã biết cách:
read_csv() từ thư viện pandas.read_csv() trả về.pandas.read_csv()to_csv().Trong hướng dẫn này, tôi chỉ tập trung vào việc nhập và xuất dữ liệu dưới góc nhìn của tệp CSV; giờ bạn đã có cảm nhận tốt về mức độ hữu ích của pandas khi nhập và xuất tệp CSV. CSV là một trong những định dạng lưu trữ dữ liệu phổ biến nhất, nhưng không phải duy nhất. Có nhiều định dạng tệp khác dùng trong khoa học dữ liệu, như parquet, JSON và Excel.
Có rất nhiều bộ dữ liệu hữu ích, chất lượng cao được lưu trữ trên web mà bạn có thể truy cập qua các API, chẳng hạn. Nếu bạn muốn hiểu chi tiết hơn cách nạp dữ liệu vào Python, khóa học Introduction to Importing Data in Python của DataCamp sẽ dạy bạn mọi thực hành tốt nhất.
Cũng có các hướng dẫn về cách nhập dữ liệu JSON và HTML vào pandas và một hướng dẫn toàn diện, thân thiện cho người mới bắt đầu về pandas. Nhớ xem qua để tìm hiểu sâu hơn về khung làm việc pandas.
Tìm hiểu thêm về Python và pandas
Courses
Courses
Courses