Cours
Pandas Joins for Spreadsheet Users
4 h
4.5K
Avant de lire un fichier CSV dans un dataframe pandas, vous devez avoir une idée du contenu des données. Il est donc recommandé de parcourir le fichier avant d'essayer de le charger dans la mémoire : vous saurez ainsi quelles colonnes sont nécessaires et lesquelles peuvent être supprimées.
Ecrivons un peu de code pour importer un fichier à l'aide de read_csv(). Nous pourrons alors parler de ce qui se passe et de la manière dont nous pouvons personnaliser les résultats que nous recevons lors de la lecture des données dans la mémoire.
import pandas as pd
# Read the CSV file
airbnb_data = pd.read_csv("data/listings_austin.csv")
# View the first 5 rows
airbnb_data.head()
Tout ce qui s'est passé dans le code ci-dessus, c'est que nous avons :
read_csv pour qu'il lise les données en mémoire sous la forme d'un cadre de données pandas.Mais la fonction read_csv() ne s'arrête pas là.
Le comportement par défaut de pandas est d'ajouter un index initial au dataframe renvoyé par le fichier CSV qu'il a chargé en mémoire. Toutefois, vous pouvez spécifier explicitement quelle colonne doit servir d'index à la fonction read_csv en définissant le paramètre index_col.
Notez que la valeur que vous attribuez à index_col peut prendre la forme d'un nom de chaîne, d'un index de colonne ou d'une séquence de noms de chaîne ou d'index de colonne. L'attribution d'une séquence au paramètre se traduira par un multi-index (regroupement de données sur plusieurs niveaux).
Lisons à nouveau les données et définissons la colonne id comme index.
# Setting the id column as the index
airbnb_data = pd.read_csv("data/listings_austin.csv", index_col="id")
# airbnb_data = pd.read_csv("data/listings_austing.csv", index_col=0)
# Preview first 5 rows
airbnb_data.head()
Que se passe-t-il si vous ne voulez lire que certaines colonnes en mémoire parce qu'elles ne sont pas toutes importantes ? Il s'agit d'un scénario courant qui se produit dans le monde réel. En utilisant la fonction read_csv, vous pouvez sélectionner uniquement les colonnes dont vous avez besoin après avoir chargé le fichier, mais cela signifie que vous devez connaître les colonnes dont vous avez besoin avant de charger les données si vous souhaitez effectuer cette opération à partir de la fonction read_csv.
Si vous connaissez les colonnes dont vous avez besoin, vous avez de la chance : vous pouvez gagner du temps et de la mémoire en passant un objet de type liste au paramètre usecols de la fonction read_csv.
# Defining the columns to read
usecols = ["id", "name", "host_id", "neighbourhood", "room_type", "price", "minimum_nights"]
# Read data with subset of columns
airbnb_data = pd.read_csv("data/listings_austin.csv", index_col="id", usecols=usecols)
# Preview first 5 rows
airbnb_data.head()
Nous avons à peine effleuré les différentes façons de personnaliser la sortie de la fonction read_csv, mais aller plus en profondeur serait certainement une surcharge d'informations.
Nous vous recommandons de mettre en signet l'aide-mémoire sur l'importation de données en Python et de consulter Introduction à l'importation de données en Python pour en savoir plus. Si c'est un peu trop facile, il y a aussi le cours interactif intermédiaire sur l'importation de données en Python.
Une fois que vous savez comment lire un fichier CSV du stockage local dans la mémoire, la lecture de données provenant d'autres sources est un jeu d'enfant. Il s'agit en fin de compte du même processus, sauf que vous ne passez plus un chemin d'accès au fichier.
Supposons que vous souhaitiez obtenir des données d'une page web spécifique ; comment les lire dans la mémoire ?
Nous utiliserons l'ensemble de données Iris du dépôt de l'UCI à titre d'exemple :
# Webpage URL
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
# Define the column names
col_names = ["sepal_length_in_cm",
"sepal_width_in_cm",
"petal_length_in_cm",
"petal_width_in_cm",
"class"]
# Read data from URL
iris_data = pd.read_csv(url, names=col_names)
iris_data.head() 
Voilà !
Vous avez peut-être remarqué que nous avons attribué une liste de chaînes de caractères au paramètre names de la fonction read_csv. Cela nous permet de renommer les en-têtes de colonne lors de la lecture des données en mémoire.
L'objet le plus courant de la bibliothèque pandas est, de loin, l'objet dataframe. Il s'agit d'une structure de données étiquetée bidimensionnelle composée de lignes et de colonnes qui peuvent être de différents types (par exemple, flottant, numérique, catégorique, etc.).
Conceptuellement, vous pouvez considérer un dataframe pandas comme une feuille de calcul, une table SQL ou un dictionnaire d'objets de série - selon ce qui vous est le plus familier. Ce qui est intéressant avec le dataframe pandas, c'est qu'il est livré avec de nombreuses méthodes qui vous permettent de vous familiariser avec vos données le plus rapidement possible.
Vous avez déjà vu l'une de ces méthodes : iris_data.head() qui affiche les n premières lignes (5 par défaut). La méthode "opposée" à head() est tail(), qui affiche les dernières n (5 par défaut) lignes de l'objet dataframe. Par exemple :
iris_data.tail()
Vous pouvez rapidement découvrir les noms des colonnes en utilisant l'attribut columns sur votre objet dataframe :
# Discover the column names
iris_data.columns
"""
Index(['sepal_length_in_cm', 'sepal_width_in_cm', 'petal_length_in_cm',
'petal_width_in_cm', 'class'],
dtype='object')
"""Une autre méthode importante que vous pouvez utiliser sur votre objet dataframe est info(). Cette méthode affiche un résumé concis du cadre de données, y compris des informations sur l'index, les types de données, les colonnes, les valeurs non nulles et l'utilisation de la mémoire.
# Get summary information of the dataframe
iris_data.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal_length_in_cm 150 non-null float64
1 sepal_width_in_cm 150 non-null float64
2 petal_length_in_cm 150 non-null float64
3 petal_width_in_cm 150 non-null float64
4 class 150 non-null object
dtypes: float64(4), object(1)
memory usage: 6.0+ KB
"""DataFrame.describe() génère des statistiques descriptives, y compris celles qui résument la tendance centrale, la dispersion et la forme de la distribution de l'ensemble de données. Si vos données comportent des valeurs manquantes, ne vous inquiétez pas ; elles ne sont pas incluses dans les statistiques descriptives.
Appelons la méthode describe sur l'ensemble de données Iris :
# Get descriptive statistics
iris_data.describe()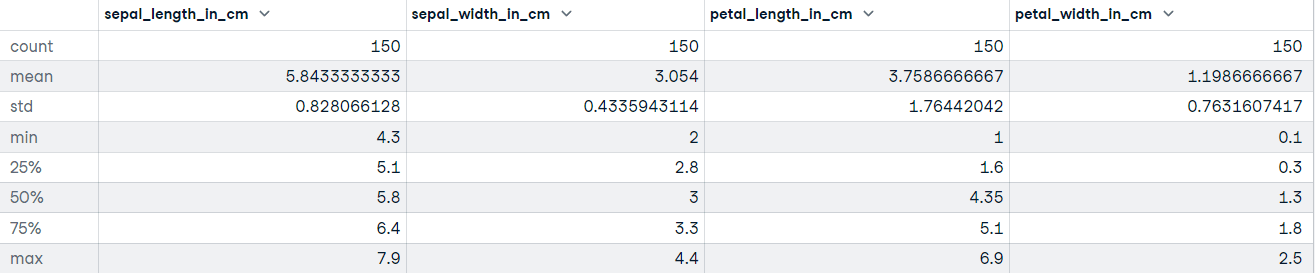
Une autre méthode disponible pour les objets pandas dataframe est to_csv(). Lorsque vous avez nettoyé et prétraité vos données, l'étape suivante peut consister à exporter le cadre de données vers un fichier - c'est assez simple :
# Export the file to the current working directory
iris_data.to_csv("cleaned_iris_data.csv")L'exécution de ce code créera un fichier CSV dans le répertoire de travail actuel appelé cleaned_iris_data.csv.
Mais qu'en est-il si vous souhaitez utiliser un délimiteur différent pour marquer le début et la fin d'une unité de données ou si vous voulez spécifier la manière dont vos valeurs manquantes doivent être représentées ? Peut-être ne souhaitez-vous pas que les en-têtes soient exportés dans le fichier.
Vous pouvez adapter les paramètres de la méthode to_csv() à vos besoins pour les données que vous souhaitez exporter.
Voyons quelques exemples de la manière dont vous pouvez ajuster la sortie de to_csv():
# Change the delimiter to a tab
iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t")# Export data without the index
iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t")
# If you get UnicodeEncodeError use this...
# iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t", index=False, encoding='utf-8')# Replace missing values with "Unknown"
iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t", na_rep="Unknown")# Do not include headers when exporting the data
iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t", na_rep="Unknown", header=False)Récapitulons ce que nous avons couvert dans ce tutoriel ; vous avez appris à.. :
read_csv() de la bibliothèque pandas.read_csv() doit renvoyer.pandas.read_csv()to_csv().Dans ce tutoriel, nous nous sommes concentrés uniquement sur l'importation et l'exportation de données à partir d'un fichier CSV ; vous avez maintenant une bonne idée de l'utilité de pandas lors de l'importation et de l'exportation de fichiers CSV. CSV est l'un des formats de stockage de données les plus courants, mais ce n'est pas le seul. Il existe d'autres formats de fichiers utilisés dans la science des données, tels que parquet, JSON et excel.
De nombreux ensembles de données utiles et de grande qualité sont hébergés sur le web, auxquels vous pouvez accéder par le biais d'API, par exemple. Si vous souhaitez comprendre comment charger des données en Python de manière plus détaillée, le cours Introduction à l'importation de données en Python de DataCamp vous enseignera toutes les meilleures pratiques.
Vous trouverez également des tutoriels sur l 'importation de données JSON et HTML dans pandas, ainsi qu'un guide ultime de pandas destiné aux débutants. Ne manquez pas de les consulter pour vous plonger plus profondément dans le cadre de travail pandas.
Nos programmes de certification vous aident à vous démarquer et à prouver aux employeurs potentiels que vos compétences sont adaptées à l'emploi.

En savoir plus sur Python et pandas
Cours
Cours
Cours
Tutoriel
Aditya Sharma
Tutoriel
Sejal Jaiswal
Tutoriel
Abid Ali Awan
Tutoriel
DataCamp Team
Tutoriel
DataCamp Team
Tutoriel
DataCamp Team