
Corso
Progettazione di database
4 h
125.4K
Immagina questa scena: sono le 2:00 del mattino e il server del database della tua azienda è andato in crash. Mentre il team di incident response si affanna per ripristinare le operazioni, due domande dominano su tutte: "Quanto velocemente possiamo tornare online?" e "Quanti dati abbiamo perso?" Queste domande rappresentano le due metriche più critiche nella pianificazione del disaster recovery: Recovery Time Objective (RTO) e Recovery Point Objective (RPO).
Con un costo medio di una violazione dei dati che raggiunge i 10,22 milioni di dollari, secondo IBM, le organizzazioni devono disporre di solide strategie di disaster recovery. In questo tutorial ti guiderò attraverso i fondamentali di RTO e RPO, inclusi metodi di calcolo, strategie di implementazione, approcci di testing e applicazioni nei vari settori.
Se sei alle prime armi con database e cloud computing, ti consiglio uno dei nostri corsi fondamentali, in particolare Understanding Cloud Computing e Database Design.
Entrambe le metriche sono cruciali per la business continuity e la sicurezza dei dati. Sono indicatori chiave di performance che aiutano le organizzazioni a quantificare la tolleranza al rischio, allocare risorse e prendere decisioni informate sull'infrastruttura di recovery.
Il Recovery Time Objective (RTO) rappresenta la durata massima accettabile in cui un sistema può rimanere non disponibile in seguito a un evento dirompente. Risponde alla domanda: "Quanto rapidamente dobbiamo ripristinare le operazioni?"
Per esempio, se il tuo sistema di pagamento ha un RTO di due ore, devi ripristinare la piena funzionalità entro quel lasso di tempo.
Il Recovery Point Objective (RPO), invece, definisce la perdita di dati massima accettabile misurata nel tempo. Risponde alla domanda: "Quanti dati possiamo permetterci di perdere?"
Se il tuo database ha un RPO di 15 minuti, i backup devono acquisire i dati almeno ogni 15 minuti.
Pur avendo uno scopo simile, RTO e RPO misurano aspetti di recovery fondamentalmente diversi. L'RTO guarda in avanti, misurando il tempo dalla perturbazione fino al ripristino. L'RPO guarda indietro, misurando dalla perturbazione fino all'ultimo punto di ripristino accettabile.
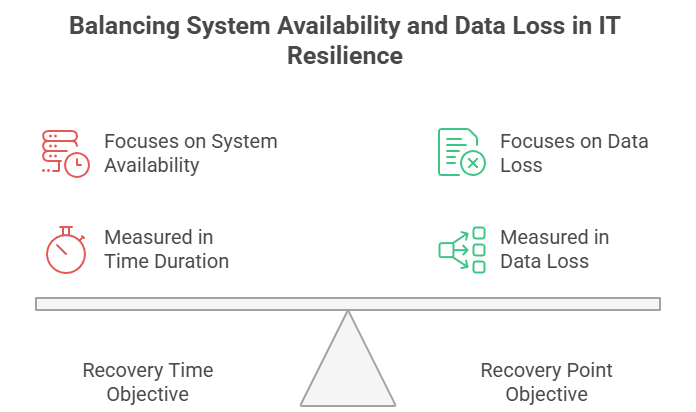
Anche la natura dell'impatto è diversa. L'RTO si concentra sulla disponibilità: obiettivi mancati significano tempi di inattività prolungati e perdita di produttività. L'RPO si concentra sull'integrità dei dati: obiettivi mancati comportano perdite di dati permanenti con potenziali conseguenze normative e finanziarie.
Gli investimenti infrastrutturali seguono schemi diversi. RTO aggressivi richiedono sistemi ad alta disponibilità e failover automatizzato. RPO stringenti esigono protezione continua dei dati e backup frequenti, oltre a capacità di storage sufficiente.
Importante: le due metriche sono indipendenti. Potresti avere un RTO di quattro ore con un RPO di un'ora, o un RTO di 30 minuti con un RPO di sei ore. Dipende interamente dai requisiti di business.
Ecco una tabella comparativa:
|
Aspetto |
RTO |
RPO |
|
Direzione temporale |
Prospettiva futura |
Prospettiva passata |
|
Focus principale |
Disponibilità del sistema |
Integrità dei dati |
|
Domanda chiave |
"Quanto velocemente dobbiamo ripristinare?" |
"Quanti dati possiamo perdere?" |
|
Priorità infrastrutturale |
Sistemi di failover, ridondanza |
Frequenza dei backup, replica |
|
Indipendenza |
Definito indipendentemente dall'RPO |
Definito indipendentemente dall'RTO |
Impostare obiettivi RTO e RPO adeguati richiede un approccio metodico che bilanci esigenze di business e capacità tecniche con i vincoli di costo. Il processo inizia comprendendo il profilo di rischio e le priorità specifiche della tua organizzazione.
La base per definire gli obiettivi parte da una Business Impact Analysis (BIA) completa, che valuta sistematicamente come le interruzioni influiscono sulla tua organizzazione.
Condurre una BIA implica intervistare gli stakeholder di ogni reparto per mappare le funzioni di business e le conseguenze dell'indisponibilità. Questo assicura che le priorità di recovery riflettano l'impatto reale sul business e non solo ipotesi IT.
I Service Level Agreement (SLA) influenzano significativamente la definizione degli obiettivi. Se hai promesso il 99,9% di uptime, il tuo RTO deve essere allineato a questo impegno per evitare penali economiche e perdita di clienti.
Le interruzioni influenzano le organizzazioni su quattro dimensioni:
Gli esiti della BIA guidano la prioritizzazione e un'allocazione delle risorse conveniente. I sistemi che generano ricavi, gestiscono transazioni dei clienti o soddisfano requisiti normativi richiedono obiettivi aggressivi. Sistemi di supporto come le directory dei dipendenti possono tollerare tempi di ripristino più lunghi.
Con le informazioni della BIA, sei pronto a tradurre l'impatto di business in obiettivi quantitativi.
Calcolare l'RTO richiede di comprendere la tolleranza del business e le capacità tecniche. Inizia identificando il Maximum Tolerable Period of Disruption (MTPD), il tempo massimo oltre il quale un processo non può rimanere indisponibile senza causare danni irreversibili. Imposta l'RTO al di sotto dell'MTPD per avere un margine di sicurezza.
Per calcolare l'RTO, segui questi passaggi:
Il calcolo dell'RPO si concentra sulle caratteristiche dei dati:
Un approccio a livelli offre una strategia conveniente:
Evita questi errori comuni:
Con questi calcoli completati, hai ora obiettivi concreti che guideranno le tue decisioni tecnologiche e di processo.
La giusta strategia di implementazione e le tue scelte tecnologiche possono fare la differenza tra il raggiungimento degli obiettivi e il fallimento quando si verifica un disastro.
Esploriamo le tecnologie core che abilitano il recovery, a partire dagli approcci fondamentali fino a soluzioni più sofisticate.
Le strategie di backup e ripristino costituiscono la base del disaster recovery. I backup completi creano copie integrali dei dati ma consumano molto storage. I backup incrementali catturano solo le modifiche dall'ultimo backup. I backup differenziali catturano le modifiche dall'ultimo backup completo.0
Per requisiti RPO aggressivi, combina backup completi giornalieri con incrementali orari.
Oltre i backup tradizionali, replica e protezione continua dei dati mantengono copie quasi in tempo reale.
La replica sincrona scrive contemporaneamente nelle sedi primaria e secondaria, ottenendo un RPO quasi zero ma introducendo latenza. Al contrario, la replica asincrona scrive prima sulla primaria e poi replica con un piccolo ritardo. La Continuous Data Protection (CDP) cattura ogni modifica, permettendo il ripristino a un punto nel tempo.

Oltre ai meccanismi di protezione dei dati, i siti di disaster recovery devono essere allineati ai requisiti di RTO.
I cold site forniscono infrastruttura di base ma richiedono da giorni a settimane per l'attivazione. I warm site includono hardware preinstallato e sincronizzazione giornaliera/settimanale per potersi attivare entro poche ore. I hot site, invece, mantengono repliche operative in tempo reale con failover nell'ordine dei minuti per applicazioni mission-critical.
Indipendentemente dall'approccio al sito di recovery scelto, gli strumenti di automazione e orchestrazione migliorano drasticamente RTO e RPO.
Gli strumenti di configuration management consentono una rapida ricostruzione dei server. Allo stesso modo, le piattaforme di orchestrazione del disaster recovery automatizzano le procedure di failover. Nel frattempo, la runbook automation assicura un recovery coerente durante gli incidenti.
Oltre agli approcci tradizionali on-premises, la tecnologia cloud ha trasformato il disaster recovery. Offre funzionalità un tempo disponibili solo per le aziende con budget enormi.
I servizi di disaster recovery basati sul cloud forniscono alternative flessibili e convenienti ai siti fisici di recovery. Il Disaster Recovery as a Service (DRaaS) di AWS, Azure e Google Cloud elimina l'esigenza di infrastrutture fisiche separate. Per un confronto tra i tre provider cloud più popolari, dai un'occhiata alla nostra guida AWS vs Azure vs GCP.
Inoltre, l'Infrastructure as Code (IaC) abilita un recovery rapido definendo l'intera infrastruttura in codice. Strumenti come Terraform o AWS CloudFormation ricreano ambienti completi in pochi minuti, riducendo drasticamente l'RTO.
Quando scegli soluzioni cloud, considera il modello di deployment. Il cloud pubblico offre flessibilità e bassi costi iniziali con prezzi pay-as-you-go. In alternativa, un cloud privato offre maggiore controllo e può essere necessario per la compliance, soprattutto in settori sensibili come finanza o sanità. Gli approcci ibridi combinano risorse on-premises e cloud per maggiore flessibilità.
Infine, i tipi di backup cloud più comuni includono
Comprendere le implicazioni finanziarie degli obiettivi RTO e RPO consente di prendere decisioni informate sugli investimenti in recovery. Ogni organizzazione affronta la sfida di bilanciare protezione e costi. Ecco come affrontare questo compromesso critico.
La relazione tra obiettivi di recovery e costi segue schemi prevedibili, ma ottimizzarla richiede pensiero strategico.
Esiste una relazione inversa tra obiettivi RTO/RPO e costi. Per esempio, ottenere un RTO di 15 minuti costa esponenzialmente di più rispetto a un RTO di 24 ore. Analogamente, raggiungere un RPO di 15 minuti richiede backup più frequenti e maggiore storage rispetto a un RPO di 24 ore. Un recovery quasi zero richiede sistemi ridondanti, replica continua e failover automatizzato.
Tuttavia, gli approcci a livelli ottimizzano gli investimenti. Invece di applicare obiettivi aggressivi a tutti i sistemi, alloca le risorse in base alla criticità.
Per esempio, una piattaforma e-commerce dovrebbe investire molto nella replica su hot site per evitare lunghi downtime (RTO minimo), usando invece solo backup cloud giornalieri per wiki interni (RPO medio). I risparmi derivanti da obiettivi ragionevoli sui sistemi meno critici finanziano una protezione robusta per i sistemi mission-critical.
Per metterlo in pratica, bilanciare criticità, rischio e costo richiede di quantificare i costi del downtime, valutare la probabilità degli scenari di disastro, stimare i costi degli approcci di recovery e identificare i punti di equilibrio ottimali.
Ad esempio, supponiamo che ogni ora di inattività costi alla tua azienda 50.000 $ di mancati ricavi e che ci sia una probabilità annua del 10% di un guasto di quattro ore. Il costo annuo atteso di quell'interruzione è 0,1 × 4 × 50.000 $ = 20.000 $.
Se investi 10.000 $ all'anno in una migliore infrastruttura e questo riduce l'interruzione a un'ora, il costo annuo atteso del downtime diventa 0,1 × 1 × 50.000 $ = 5.000 $. Il tuo costo annuo atteso totale è ora 5.000 $ (downtime) + 10.000 $ (investimento) = 15.000 $, inferiore ai 20.000 $ iniziali. In questo caso, non solo hai tutelato la reputazione della tua azienda, ma hai anche ridotto il costo atteso.
Stabilire obiettivi RTO e RPO è solo l'inizio. Test regolari assicurano che tu possa effettivamente raggiungerli quando si verifica un disastro. Senza validazione, i tuoi obiettivi di recovery restano solo ipotesi ottimistiche.
Il testing assume molte forme, ciascuna con diversi livelli di validazione e rischio. Consiglio un approccio a strati che progredisca da esercitazioni a basso rischio a test completi in produzione.
Le esercitazioni tabletop sono test basati sulla discussione: si ripercorrono scenari di disastro per individuare lacune nelle procedure e responsabilità poco chiare. Pur essendo preziose per validare la pianificazione, non testano le capacità tecniche reali.
Oltre le esercitazioni tabletop, le simulazioni di recovery eseguono operazioni di ripristino reali in ambienti di test isolati. Per esempio, ripristinano database su server separati o effettuano il failover di applicazioni non critiche. Questi test validano sistemi e procedure di backup senza rischiare i sistemi di produzione.
I test completi di disaster recovery offrono invece la massima fiducia, effettuando failover completi in produzione. Questi test possono comportare lo spegnimento del data center primario per verificare il funzionamento del sito di recovery. Pur essendo dirompenti, i test DR completi sono l'unico modo per validare davvero gli obiettivi RTO e RPO raggiungibili.
Indipendentemente dal metodo di test utilizzato, la validazione del Recovery Time Actual (RTA) e del Recovery Point Actual (RPA) durante i test mette in luce i gap con la realtà oggettiva. Se il tuo RTO è di quattro ore ma il ripristino richiede costantemente sei ore, devi migliorare le capacità o adeguare l'RTO.
Oltre agli stessi eventi di test, un monitoraggio continuo assicura che gli obiettivi restino raggiungibili. Tieni traccia di queste metriche chiave:
Le piattaforme moderne offrono dashboard che evidenziano queste metriche per un'identificazione proattiva dei problemi.
Il testing evidenzia i gap, ma il vero valore sta in ciò che fai con i risultati. È qui che il miglioramento continuo trasforma il disaster recovery da un piano statico a una capacità dinamica.
Dopo ogni test, conduci debrief strutturati su ciò che ha funzionato, ciò che non ha funzionato, le cause radice e le azioni specifiche. Monitora formalmente queste azioni con responsabili e scadenze.
Oltre ai miglioramenti post-test, rivedi gli obiettivi RTO e RPO almeno annualmente, o quando si verificano cambiamenti significativi nei processi di business, nella tecnologia, nelle normative o nel panorama del rischio. Rivaluta l'impatto sul business, valida le capacità attuali e identifica i requisiti cambiati.
Inoltre, l'evoluzione delle minacce richiede una corrispondente evoluzione. Il ransomware ha cambiato radicalmente le considerazioni sull'RPO. I backup tradizionali che sovrascrivono le versioni precedenti possono lasciare solo dati cifrati. La pianificazione moderna deve prevedere backup immutabili, retention più lunghe e identificazione di punti di ripristino puliti.
Analogamente, un maggiore scrutinio normativo influisce sia sul luogo di ripristino dei dati sia sulla rapidità di notifica delle violazioni.
Settori diversi hanno requisiti RTO e RPO differenti in base alle esigenze operative, al contesto normativo e alla tolleranza al rischio. Ecco come variano tipicamente gli obiettivi tra i diversi ambiti:
|
Settore |
RTO tipico |
RPO tipico |
Driver principali |
|
Servizi finanziari |
0-4 ore |
Minuti o secondi |
Regolamenti Basel III, SEC, integrità delle transazioni, impatto sui ricavi |
|
Sanità |
2-4 ore |
15 minuti-1 ora |
Compliance HIPAA, sicurezza dei pazienti, sistemi vitali |
|
E-commerce |
1-4 ore |
15-30 minuti |
Perdita diretta di ricavi, fiducia dei clienti, picchi di domanda |
|
Manifattura |
4-8 ore |
1-4 ore |
Dipendenze della supply chain, registri di produzione, modelli just-in-time |
Le istituzioni dei servizi finanziari affrontano i requisiti più rigorosi a causa dei regolamenti Basel III e SEC. Le piattaforme di trading azionario possono avere RTO di 15 minuti e RPO quasi zero per prevenire la perdita di transazioni.
Analogamente critiche, le organizzazioni sanitarie bilanciano la sicurezza dei pazienti con la compliance HIPAA. I sistemi di cartella clinica elettronica consentono workflow cartacei di emergenza evitando impatti significativi sull'assistenza.
Al contrario, le piattaforme e-commerce subiscono un impatto diretto sui ricavi durante le interruzioni. I retailer online che generano 10.000 $ al minuto devono minimizzare il downtime, soprattutto nei periodi di picco.
Nel frattempo, le operazioni manifatturiere devono fare i conti con dipendenze fisiche della supply chain. I sistemi di esecuzione della produzione devono prevenire massicce interruzioni di inventario mantenendo registri di produzione e dati di qualità.
In tutti questi settori, gli standard normativi influenzano significativamente gli obiettivi. PCI DSS interessa le organizzazioni che elaborano carte di credito. L'HIPAA impone la pianificazione di contingenza in sanità. L'FFIEC fornisce linee guida per le istituzioni finanziarie. Framework come il NIST Cybersecurity Framework e la ISO 22301 offrono approcci strutturati alla business continuity che incorporano RTO e RPO.
Recovery Time Objective e Recovery Point Objective sono metriche fondamentali del disaster recovery. L'RTO definisce quanto velocemente devi ripristinare i sistemi dopo un'interruzione, mentre l'RPO determina la perdita di dati accettabile. Insieme, traducono la business continuity in obiettivi concreti e misurabili per evitare grandi disastri.
I benefici di una pianificazione rigorosa vanno ben oltre la compliance: le organizzazioni con obiettivi ben definiti e ampiamente testati si riprendono più rapidamente dalle interruzioni, subiscono un impatto finanziario minore e mantengono la fiducia dei clienti. I test regolari fanno emergere i problemi prima che contino davvero.
In definitiva, usa RTO e RPO per una valutazione continua. Pianifica revisioni regolari, esegui test significativi, impara da ogni test e mantieni valutazioni oneste su quanto le capacità attuali soddisfino gli obiettivi dichiarati. Le organizzazioni che sopravvivono meglio ai disastri sono quelle che si sono preparate più a fondo in anticipo.
Se vuoi iniziare con un apprendimento pratico sulla piattaforma cloud più popolare, ti consiglio il nostro corso AWS Concepts.
Corsi correlati
Corso
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min

